一种基于浏览器插件的分布式网络爬虫方法及系统与流程
一种基于浏览器插件的分布式网络爬虫方法及系统,用于基于浏览器插件的分布式网络爬虫,属于网络爬虫技术领域。
背景技术:
网络爬虫是指一种按照一定的规则,自动地抓取互联网网页的程序或者脚本。
静态网页是指由html+css构成,html代码中包含所有网页信息。
动态网页是指由html+css+js构成,需要执行jsajax请求,完成数据加载渲染,才能获取所有同页信息。
发明名称为:一种基于浏览器内核的网络爬虫系统,申请号为201611005039.8的案件,是基于浏览器内核的网络爬虫系统,包括浏览器引擎模块、网络通信模块、策略模块,用于进行页面分析并发现其他页面的url。本发明使用动态分析技术,通过内置的浏览器内核,去动态的加载页面依赖的资源,并执行javascript脚本,对dom节点进行动态的操作如模拟鼠标点击、双击、回车等事件,以发现新的页面,弥补了传统爬虫的不足。本申请的优点是,不需要实现模拟器来渲染动态网页。缺点是,(1)需要修改浏览器内核代码,对开发人员要求高,开发速度慢成本高;(2)单机爬虫,抓取速度慢。
发明名称为:一种分布式网络爬虫系统,专利号:201310274951.3的案件包括:管理门户、中心节点服务器、分布式子节点服务器;管理门户是爬虫系统对管理员提供的web接口,能够查看中心节点服务器和分布式子节点服务器的日志,设置添加主题,更新某个主题的url种子,配置主题的抓取频率参量,控制爬虫的状态;中心节点服务器和分布式子节点服务器爬虫是系统的主体,完成主题操作、数据抽取器的学习、页面分析以及目标页面的存储。本发明实现了一个爬虫容纳不同主题的抓取,提高了抓取网页的速度和质量不能满足了用户要求。该类爬虫的优点是实现了分布式架构,提升了抓取性能。缺点是需要实现网页模拟器,才能抓取动态网页,模拟器需要模拟执行html、js、css代码,并兼容不同版本,工作量大实现难度高。
技术实现要素:
针对上述研究的问题,本发明的目的在于提供一种基于浏览器插件的分布式网络爬虫方法及系统,解决现在技术中,基于浏览器内核的网络爬虫时,(1)需要修改浏览器内核代码,对开发人员要求高,且开发速度慢成本高,(2)采用单机爬虫,抓取速度慢;分布式网络爬虫需要实现网页模拟器,才能抓取动态网页,模拟器需要模拟执行html、js、css代码,并兼容不同版本,工作量大,实现难度高的问题。
为了达到上述目的,本发明采用如下技术方案:
一种基于浏览器插件的分布式网络爬虫方法,其特征在于:
步骤1、多个浏览器插件同时发起请求,调用抓取网页url的接口,通过抓取网页url的接口,获取各url;
步骤2、获取各url后,通过对应的浏览器插件调用浏览器加载网页信息,得到各网页最终源代码;
步骤3、根据各网页最终源代码,得到各当前网页包含的所有待抓取url;
步骤4、解析出各网页最终源代码保存至网页信息数据库、并解析各出当前网页包含的所有待抓取url中新增的待抓取url保存至待抓取网页队列。
进一步,所述步骤1的具体步骤为:
步骤1.1、多个浏览器插件同时发起http请求,调用抓取网页url的接口;
步骤1.2、接收端收到各浏览器插件的http请求,根据每个http请求的先后顺序从待抓取网页队列中取出一个url,如果待抓取队列不为空,则根据先进先出的原则,取出url返回给浏览器插件,如果为空,则返回空;
步骤1.3、若浏览器插件接收到的结果不为空,执行步骤2,否则等待0-5秒后,跳转至步骤1.1轮询获取待抓取网页url。
进一步,所述步骤2的具体步骤为:
步骤2.1、接收到返回的url的浏览器插件根据url调用浏览器发起加载网页初始源代码的网络请求;
步骤2.2、浏览器获取网页初始源代码后,执行网页初始源代码中的html、css、js代码,得到网页中间源代码;
步骤2.3、浏览器执行网页中间源代码中的动态js代码,发起ajax请求,获取网页数据;
步骤2.4、浏览器获取网页数据后,根据网页中间源代码中的js代码逻辑,将网页数据插入到网页中间源代码中后,渲染得到各网页最终源代码。
进一步,所述步骤3的具体步骤为:
步骤3.1、若浏览器渲染得到网页最终源代码,则触发加载网页信息完成事件;
步骤3.2、浏览器插件监听到浏览器加载网页信息完成事件,浏览器插件通过调用浏览器获取网页源代码接口,得到各网页最终源代码;
步骤3.3、根据各网页最终源代码得到所对应的各当前网页包含的所有待抓取url。
进一步,所述步骤4的具体步骤为:
步骤4.1、解析出各网页最终源代码,保存至网页信息数据库,完成当前网页抓取;
步骤4.2、解析出各当前网页包含的所有待抓取url,去掉之前已出现过的网页url,将新增的待抓取url保存至待抓取网页队列。
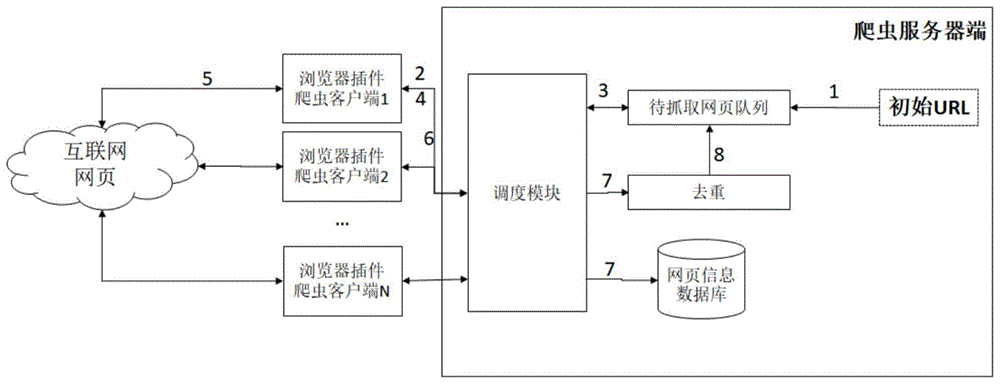
一种基于浏览器插件的分布式网络爬虫系统,其特征在于:包括多个浏览器插件客户端和一个服务器端;
多个浏览器插件客户端:用于通过浏览器插件同时向服务器端发起请求,调用抓取网页url的接口;
和获取各url后,通过对应的浏览器插件调用浏览器加载网页信息,得到各网页最终源代码,根据各网页最终源代码,得到各当前网页包含的所有待抓取url;
服务器端:用于存储待抓取网页队列;
和接收到请求后,为多个浏览器插件客户端提供待抓取网页队列中的待抓取url;
和接收各网页最终源代码和各当前网页包含的所有待抓取url,解析出网页最终源代码保存至网页信息数据库、解析出当前网页包含的所有待抓取url中新增的待抓取url保存至待抓取网页队列。
进一步,所述待抓取网页队列加入了种子网页。
进一步,多个浏览器插件客户端的具体实现阶段为:
请求阶段:
多个浏览器插件同时向服务器端发起http请求,调用抓取网页url的接口;
各浏览器插件接收http请求后服务器端的返回结果,若返回结果不为空,对应的浏览器插件进入获取成功阶段,否则返回结果为空的浏览器插件等待0-5秒后轮询请求;
获取成功阶段:
各浏览器插件根据对应的url调用浏览器,发起加载网页初始源代码的网络请求;浏览器获取网页初始源代码后,执行网页初始源代码中的html、css、js代码,得到网页中间源代码;
浏览器执行网页中间源代码中的动态js代码,发起ajax请求,获取网页数据;
浏览器获取网页数据后,根据网页中间源代码中的js代码逻辑,将网页数据插入到网页中间源代码中后,渲染得到各网页最终源代码;
若浏览器渲染得到网页最终源代码,则触发加载网页信息完成事件;
浏览器插件监听到浏览器加载网页信息完成事件,浏览器插件通过调用浏览器获取网页源代码接口,得到各网页最终源代码;
根据各网页最终源代码得到所对应的各当前网页包含的所有待抓取url;
发送阶段:
将各网页最终源代码和所对应的各当前网页包含的所有待抓取url上传至服务器端。
进一步,多个服务器端的具体实现阶段为:
接收请求阶段:
收到各浏览器插件客户端的http请求,根据每个http请求的先后顺序从待抓取网页队列中取出一个url,如果待抓取队列不为空,则根据先进先出的原则,取出url返回给浏览器插件客户端,如果为空,则返回空;
接收解析阶段:
解析出各网页最终源代码,保存至网页信息数据库,完成当前网页抓取;
且解析出各当前网页包含的所有待抓取url,去掉之前已出现过的网页url,将新增的待抓取url保存至待抓取网页队列。
本发明同现有技术相比,其有益效果表现在:
一、本发明是中心化的分布式架构,由一个服务器端节点和多个浏览器插件客户端(即基于浏览器插件的客户端)节点构成,服务器端主要负责任务调度,浏览器插件客户端负责网页爬取和解析,因多个客户端节点同时抓取,相对单机爬虫,可扩展性强,能极大的提升爬虫系统的抓取能力;
二、本发明是浏览器渲染网页的过程:网页初始源代码->网页中间源代码->网页最终源代码;解决了传统的爬虫程序,需要模拟器来完成网页的渲染过程,模拟器需要模拟执行html、js、css代码,并兼容不同版本,工作量大实现难度高,而本发明的浏览器插件通过浏览器渲染网页,直接可以得到渲染后的网页最终源代码,不需要实现模拟器,即可利用浏览器强大功能(如js引擎渲染能力、高效网页解析性能)抓取动态网页,开发成本低速度快;
三、本发明的分布式爬虫,通过多个浏览器插件客户端和服务端的调度程序协同工作,可以大幅提升系统的抓取能力。
附图说明
图1为本发明的框架示意图。
具体实施方式
下面将结合附图及具体实施方式对本发明作进一步的描述。
为了解决现在技术中,基于浏览器内核的网络爬虫时,(1)需要修改浏览器内核代码,对开发人员要求高,且开发速度慢成本高,(2)采用单机爬虫,抓取速度慢;分布式网络爬虫需要实现网页模拟器,才能抓取动态网页,模拟器需要模拟执行html、js、css代码,并兼容不同版本,工作量大,实现难度高的问题。本发明提供了一种方法和系统,具体为:
一种基于浏览器插件的分布式网络爬虫方法的具体步骤为:
步骤1、多个浏览器插件同时发起请求,调用抓取网页url的接口,通过抓取网页url的接口,获取各url;具体步骤为:
步骤1.1、多个浏览器插件同时发起http请求,调用抓取网页url的接口;
步骤1.2、接收端收到各浏览器插件的http请求,根据每个http请求的先后顺序从待抓取网页队列中取出一个url,如果待抓取队列不为空,则根据先进先出的原则,取出url返回给浏览器插件,如果为空,则返回空;
步骤1.3、若浏览器插件接收到的结果不为空,执行步骤2,否则等待0-5秒后,优选0.1秒,跳转至步骤1.1轮询获取待抓取网页url。
步骤2、获取各url后,通过对应的浏览器插件调用浏览器加载网页信息,得到各网页最终源代码;具体步骤为:
步骤2.1、接收到返回的url的浏览器插件根据url调用浏览器发起加载网页初始源代码的网络请求;
步骤2.2、浏览器获取网页初始源代码后,执行网页初始源代码中的html、css、js代码,得到网页中间源代码;
步骤2.3、浏览器执行网页中间源代码中的动态js代码,发起ajax请求,获取网页数据;
步骤2.4、浏览器获取网页数据后,根据网页中间源代码中的js代码逻辑,将网页数据插入到网页中间源代码中后,渲染得到各网页最终源代码。
步骤3、根据各网页最终源代码,得到各当前网页包含的所有待抓取url;具体步骤为:
步骤3.1、若浏览器渲染得到网页最终源代码,则触发加载网页信息完成事件;
步骤3.2、浏览器插件监听到浏览器加载网页信息完成事件,浏览器插件通过调用浏览器获取网页源代码接口,得到各网页最终源代码;
步骤3.3、根据各网页最终源代码得到所对应的各当前网页包含的所有待抓取url。
步骤4、解析出各网页最终源代码保存至网页信息数据库、并解析各出当前网页包含的所有待抓取url中新增的待抓取url保存至待抓取网页队列。具体步骤为:
步骤4.1、解析出各网页最终源代码,保存至网页信息数据库,完成当前网页抓取;
步骤4.2、解析出各当前网页包含的所有待抓取url,去掉之前已出现过的网页url,将新增的待抓取url保存至待抓取网页队列。
一种基于浏览器插件的分布式网络爬虫系统,包括多个浏览器插件客户端和一个服务器端;
多个浏览器插件客户端:用于通过浏览器插件同时向服务器端发起请求,调用抓取网页url的接口;
和获取各url后,通过对应的浏览器插件调用浏览器加载网页信息,得到各网页最终源代码,根据各网页最终源代码,得到各当前网页包含的所有待抓取url;
多个浏览器插件客户端的具体实现阶段为:
请求阶段:
多个浏览器插件同时向服务器端发起http请求,调用抓取网页url的接口;
各浏览器插件接收http请求后服务器端的返回结果,若返回结果不为空,对应的浏览器插件进入获取成功阶段,否则返回结果为空的浏览器插件等待0-5秒后轮询请求,优选0.1秒是最佳时间;
获取成功阶段:
各浏览器插件根据对应的url调用浏览器,发起加载网页初始源代码的网络请求;浏览器获取网页初始源代码后,执行网页初始源代码中的html、css、js代码,得到网页中间源代码;
浏览器执行网页中间源代码中的动态js代码,发起ajax请求,获取网页数据;
浏览器获取网页数据后,根据网页中间源代码中的js代码逻辑,将网页数据插入到网页中间源代码中后,渲染得到各网页最终源代码;
若浏览器渲染得到网页最终源代码,则触发加载网页信息完成事件;
浏览器插件监听到浏览器加载网页信息完成事件,浏览器插件通过调用浏览器获取网页源代码接口,得到各网页最终源代码;
根据各网页最终源代码得到所对应的各当前网页包含的所有待抓取url;
发送阶段:
将各网页最终源代码和所对应的各当前网页包含的所有待抓取url上传至服务器端。
服务器端:用于存储待抓取网页队列;
和接收到请求后,为多个浏览器插件客户端提供待抓取网页队列中的待抓取url;
和接收各网页最终源代码和各当前网页包含的所有待抓取url,解析出网页最终源代码保存至网页信息数据库、解析出当前网页包含的所有待抓取url中新增的待抓取url保存至待抓取网页队列。
所述待抓取网页队列加入了种子网页。
多个服务器端的具体实现阶段为:
接收请求阶段:
收到各浏览器插件客户端的http请求,根据每个http请求的先后顺序从待抓取网页队列中取出一个url,如果待抓取队列不为空,则根据先进先出的原则,取出url返回给浏览器插件客户端,如果为空,则返回空;
接收解析阶段:
解析出各网页最终源代码,保存至网页信息数据库,完成当前网页抓取;
且解析出各当前网页包含的所有待抓取url,去掉之前已出现过的网页url,将新增的待抓取url保存至待抓取网页队列。
实施例
将种子网页(如新浪滚动新闻,https://news.sina.com.cn/roll等)加入服务端待抓取网页队列,多个浏览器插件客户端同时向服务器端发起http请求,调用抓取网页url的接口;服务器端调度程序,先后收到各浏览器插件客户端的http请求,因服务器是单机的,收到的http请求即有先后顺序,后续处理也会依先后顺序返回结果,根据每个请求的先后顺序从待抓取网页队列中取出一个url,如果待抓取队列不为空,则根据先进先出的原则,取出url返回给浏览器插件客户端(第一个url为新浪滚动新闻https://news.sina.com.cn/roll,其它依次获取,后续用取出的这个url进行说明),如果为空,则返回空;浏览器插件客户端收到服务器端返回结果,如果返回结果不为空,对应的浏览器插件调用浏览器打开新标签(新标签指新的浏览器网页标签)接口,在浏览器打开新url(如新浪滚动新闻https://news.sina.com.cn/roll),如果返回结果为空,则等待0.1秒后,对应的浏览器插件客户端重新向服务器端发送请求。
获取新的url后(如获取新浪滚动新闻https://news.sina.com.cn/roll),浏览器插件调用浏览器发起加载网络请求网页初始源代码,浏览器获取网页初始源代码后(如新浪滚动新闻的初始源代码,不包含具体每条新闻的url),执行网页初始源代码中的html、css、js代码,得到网页中间源代码;浏览器执行网页中间源代码中的动态js代码,发起ajax请求,获取网页数据;浏览器获取网页数据后,根据网页中间源代码中的js代码逻辑,将数据插入到网页中间源代码中,渲染得到网页最终源代码(如新浪滚动新闻最终源代码,包含了具体每条新闻的url)。
浏览器渲染得到网页最终源代码后,触发网页加载完成事件,各浏览器插件客户端监听浏览器网页加载完成事件,当浏览器出发网页加载完成事件时,浏览器插件收到浏览器通知,调起浏览器插件的网页处理程序,各浏览器插件客户端的网页处理程序通过调用浏览器获取网页源代码接口,得到网页最终源代码,各浏览器插件客户端的网页处理程序,调用服务器端提供的上传数据接口,上传两部分数据至服务器端:一是网页最终源代码,二是当前网页包含的所有待抓取url(如新浪滚动新闻包含的所有待抓取url,为具体每条新闻的url和其它链接)。
服务器端调度程序接收到各浏览器插件客户端上传的两部分数据,解析出网页最终源代码,保存至网页信息数据库,完成当前网页抓取,并解析各当前网页包含的所有待抓取url,通过去重程序去重后,将新增的待抓取url保存至待抓取网页队列(如新浪滚动新闻页面中具体每条新闻的url和其它链接)。
以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!