一种便捷式高吞吐量大数据采集方法及系统与流程
本发明涉及数据采集领域,具体地说是一种便捷式高吞吐量大数据采集方法及系统。
背景技术:
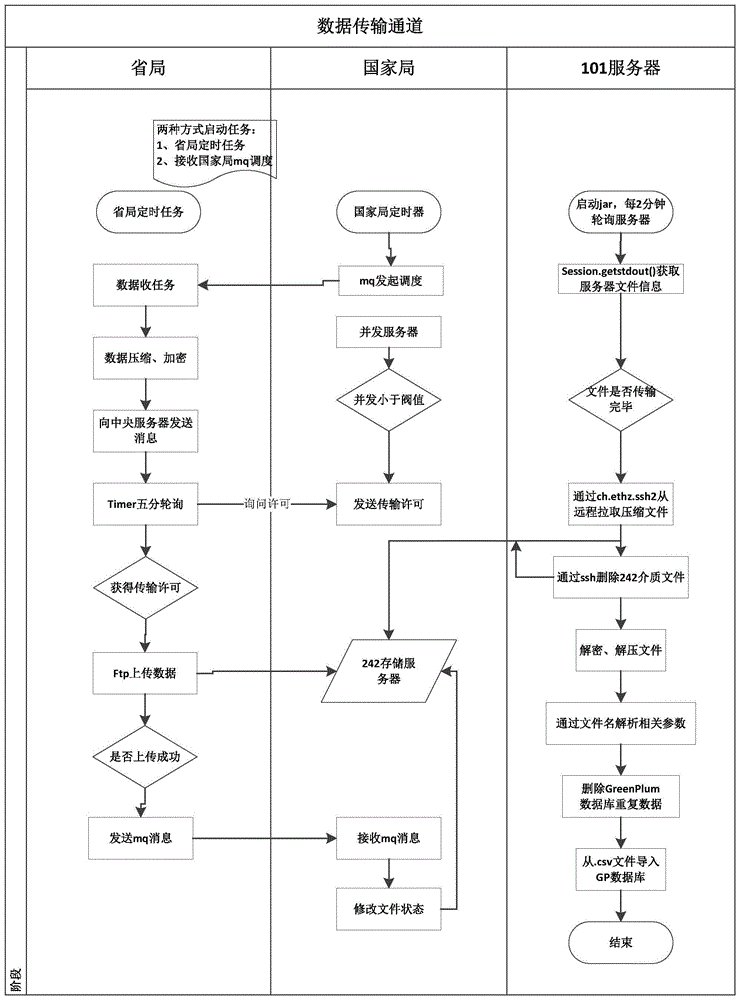
:信息是决策的核心依据,及时有效的将数据采集数据处理就显得格外重要。因为数据的分散以及结构的不一致,导致传动的数据收集方式十分的费时费力。故如何能够瞬间将不同数据库不同数据结构的数据进行收集并处理是目前急需解决的技术问题;为解决上述技术问题,人们开始关注企业数据集成研究。尝试着对不同系统中的数据进行再加工,从而形成一个集成的,面向分析处理的环境,以便能够从这些海量的信息中挖掘规律,提取知识,辅助决策。现有技术常用单线程轮询数据库的方式抽取数据,但是采用单线程轮询数据库中的每一个表,可能会存在某些表由于数据量过于庞大,导致时间消耗过大,抽取数据效率较低。专利号为cn106330963a专利文献公开了一种跨网络多节点的日志采集方法,节点日志发送至总部,应用服务器需要将每日节点日志发送到总部,采用外网传输方式,服务器每日定时执行shell脚本,对服务器上的日志文件进行压缩等处理,发送到总部服务器;日志数据从总部外网发送至总部内网,将日志数据从总部外网发送至总部内网,需要提供日志摆渡程序,将日志存储到内网数据库;数据库中日志数据恢复为原始日志文件,总部内网数据库中的日志数据,恢复为原始日志文件,再通过日志管理工具logstash发送到大数据平台。但是该技术方案不能实现瞬间将不同数据库不同数据结构的数据进行收集并处理。技术实现要素:本发明的技术任务是提供一种便捷式高吞吐量大数据采集方法及系统,来解决如何能够瞬间将不同数据库不同数据结构的数据进行收集并处理的问题。本发明的技术任务是按以下方式实现的,一种便捷式高吞吐量大数据采集方法,该方法是由中央服务器发送指令,各集群服务器启动logstash,通过datatrains的etcd组件读取配置参数,自动生成响应的配置文件,logstash读取配置文件,按照配置文件收集各种数据库数据,整理后以消息的形式通过kafka发送给各服务器,kafka与logstash配合在消费端按照相应的格式将收集的数据暂存;中央服务器调用相关组件,处理收集过来的相关数据;具体步骤如下:s1、服务器端根据不同的业务需求生成不同的参数消息包,通过定时任务或手动操作发送参数消息包;s2、消费端在接收到服务器端发送来的消息包后进行解析,获取相应参数;再依照参数进行数据收集,并通过dtp传输通道完成数据收集;s3、将收集的数据写入.csv文件,并对.csv文件进行压缩、加密操作,生产数据收集压缩包;s4、消费端将数据收集压缩包通过ftp或sftp方式上传到服务器端(两种传输方式主要是考虑到系统兼容性问题);s5、服务器端对数据收集压缩包进行数据的解密、解压操作,得到解压后的.csv文件;s6、判断解压后的.csv文件是普通表还是大表:①、若是普通表,则进行正常的数据插入删除;②、若是大表,则采用gpload进行数据插入。作为优选,所述步骤s6中采用gpload进行数据插入,具体方法如下:(1)、java操控本地的linux服务器的shell指令,java.lang.runtime类封装了运行时的环境;(2)、每个java应用程序都有一个runtime类实例,使java应用程序能够与其运行的环境相连接;(3)、通过getruntime方法获取当前runtime运行时对象的引用;(4)、得到一个当前的runtime对象的引用,便可调用runtime对象的方法控制java虚拟机的状态和行为。作为优选,所述步骤s2中数据收集过程中抽取数据是通过select查询分页轮询完成;数据收集过程中采用多线程轮询数据库中的每一个表。更优地,所述数据收集过程中抽取数据时,将数据库中每一个表根据索引的命中规则进行拆解sql,经过索引命中规则处理提高数据的抽取效率。更优地,所述多线程选择的方法具体如下:(1)、传输控制参数:线程和分页大小控制了系统的稳定性,线程数不小于2;(2)、开启线程个数:线程个数决定抽取数据占用的系统资源,包括db连接个数以及系统io资源,线程个数的范围为:1<thread_num<10;(3)、查询分页大小:分页大小决定占用堆的大小、io资源,爆堆多是由于占用堆的大小、io资源这两个参数控制造成的,分页大小的范围为:10000<page<100000;(4)、运维人员根据需求主动调节相应服务器的性能参数。更优地,所述占用堆达到最大堆的容量限制后产生内存泄露(memoryleak)或内存溢出(memoryoverflow)的溢出,具体判定方法如下:①、若是内存泄露,则通过工具查看泄露对象到gcroots的引用链,找到泄漏对象是通过怎样的路径与gcroots相关并导致垃圾回收器无法自动回收垃圾;②、若是内存溢出,则内存中的对象确实都还必须活着,那就应当检查虚拟机的堆参数(-xmx和xms),与机器物理内存对比是否可以调大,从代码上检查是否存在某些对象生命周期过长,持有状态时间过长的情况,尝试减少程序运行期的内存消耗。更优地,所述中央服务器调用相关组件,处理收集过来的相关数据,具体步骤如下:(ⅰ)、启动jar,每2分钟轮询242服务器;(ⅱ)、session.getstdout()获取服务器文件信息;(ⅲ)、判断文件是否传输完毕:①、若传输完毕,则通过ch.ethz.ssh2从远程拉取压缩文件;(ⅳ)、通过ssh删除242介质文件;(ⅴ)、解密解压文件;(ⅵ)、通过文件名解析相关参数;(ⅶ)、删除greenplum数据库重复数据;(ⅷ)、从.csv文件导入gp数据库;(ⅸ)、结束。一种便捷式高吞吐量大数据采集系统,该系统包括服务器端和消费端;服务器端用于根据不同的业务需求生成不同的参数消息包,通过定时任务或手动操作发送参数消息包以及对数据收集压缩包进行数据的解密、解压操作,得到解压后的.csv文件;消费端用于在接收到服务器端发送来的消息包后进行解析,获取相应参数,再依照参数进行数据收集,并通过dtp传输通道完成数据收集,将收集的数据写入.csv文件,并对.csv文件进行压缩、加密操作,生产数据收集压缩包以及将数据收集压缩包通过ftp或sftp方式上传到服务器端(两种传输方式主要是考虑到系统兼容性问题)。本发明的一种便捷式高吞吐量大数据采集方法及系统具有以下优点:(一)、本发明是利用开源中间件和数据收集技术,远程管理多台服务器集群,实现中央服务器控制多台分布式服务器协同处理各种数据源的数据收集以及传送;各服务器协同完成一作业任务,中央服务器获取相关服务器运行信息并实时控制监控各服务器,利用开源中间件技术远程控制各服务器并各服务器的数据进行抽取、清洗、转换和存储,再压缩加密放入数据收集库中,实现便捷快速的抽取关系型数据库的数据且按照需要的格式进行输出;(二)、本发明中央服务控制流程的发起,可批量也可以定点运行,通过kafka等一些开源组件达到便携和高效并存的目的,实现便捷式高吞吐量的数据采集;(三)、作业方便性:通过datatrains的etcd组件读取配置参数,自动生成响应的配置文件;logstash读取配置文件,收集发送数据全自动完成;(四)、作业展现:通过理论和实践测试得出kafka集群在大数据量情况下的性能优势,如下表所示:kafka在大数据量的情况下耗时传输环境差异性总耗时(小时)sql查询总耗时(小时)kafka堆积(峰值)数据量kfka单例10.51.53000以内节点1(3.3g)kafka集群13.50.53000以内节点2(3.3g)kafka集群12.71.43000以内节点3(6.1g)(五)、作业启停:定时任务循环执行;(六)、本发明通过kafka与logstash配合在消费端按照相应的格式,将数据暂存,中央服务器调用相关组件,处理收集过来的相关数据,使数据的收集变的非软件开发人员也可以轻易操作,大大降低了数据收集的成本和时间。附图说明下面结合附图对本发明进一步说明。附图1为本发明的流程框图;附图2为实施例4的结构示意图。具体实施方式参照说明书附图和具体实施例对本发明的一种便捷式高吞吐量大数据采集方法及系统作以下详细地说明。实施例1:本发明的一种便捷式高吞吐量大数据采集方法,该方法是由中央服务器发送指令,各集群服务器启动logstash,通过datatrains的etcd组件读取配置参数,自动生成响应的配置文件,logstash读取配置文件,按照配置文件收集各种数据库数据,整理后以消息的形式通过kafka发送给各服务器,kafka与logstash配合在消费端按照相应的格式将收集的数据暂存;中央服务器调用相关组件,处理收集过来的相关数据;具体步骤如下:s1、服务器端根据不同的业务需求生成不同的参数消息包,通过定时任务或手动操作发送参数消息包;s2、消费端在接收到服务器端发送来的消息包后进行解析,获取相应参数;再依照参数进行数据收集,并通过dtp传输通道完成数据收集;数据收集过程中抽取数据是通过select查询分页轮询完成;数据收集过程中采用多线程轮询数据库中的每一个表。数据收集过程中抽取数据时,将数据库中每一个表根据索引的命中规则进行拆解sql,经过索引命中规则处理提高数据的抽取效率。多线程选择的方法具体如下:(1)、传输控制参数:线程和分页大小控制了系统的稳定性,线程数不小于2;(2)、开启线程个数:线程个数决定抽取数据占用的系统资源,包括db连接个数以及系统io资源,线程个数的范围为:1<thread_num<10;(3)、查询分页大小:分页大小决定占用堆的大小、io资源,爆堆多是由于占用堆的大小、io资源这两个参数控制造成的,分页大小的范围为:10000<page<100000;占用堆达到最大堆的容量限制后产生内存泄露(memoryleak)或内存溢出(memoryoverflow)的溢出,具体判定方法如下:①、若是内存泄露,则通过工具查看泄露对象到gcroots的引用链,找到泄漏对象是通过怎样的路径与gcroots相关并导致垃圾回收器无法自动回收垃圾;②、若是内存溢出,则内存中的对象确实都还必须活着,那就应当检查虚拟机的堆参数(-xmx和xms),与机器物理内存对比是否可以调大,从代码上检查是否存在某些对象生命周期过长,持有状态时间过长的情况,尝试减少程序运行期的内存消耗。(4)、运维人员根据需求主动调节相应服务器的性能参数。s3、将收集的数据写入.csv文件,并对.csv文件进行压缩、加密操作,生产数据收集压缩包;s4、消费端将数据收集压缩包通过ftp或sftp方式上传到服务器端(两种传输方式主要是考虑到系统兼容性问题);s5、服务器端对数据收集压缩包进行数据的解密、解压操作,得到解压后的.csv文件;s6、判断解压后的.csv文件是普通表还是大表:①、若是普通表,则进行正常的数据插入删除;②、若是大表,则采用gpload进行数据插入,采用gpload进行数据插入,具体方法如下:(1)、java操控本地的linux服务器的shell指令,java.lang.runtime类封装了运行时的环境;(2)、每个java应用程序都有一个runtime类实例,使java应用程序能够与其运行的环境相连接;(3)、通过getruntime方法获取当前runtime运行时对象的引用;(4)、得到一个当前的runtime对象的引用,便可调用runtime对象的方法控制java虚拟机的状态和行为;利用gpload实现数据插入方案的代码:实施例2:如附图1所示,以省局、国家局和101服务器为例。其中,启动任务的方式有两种:①、省局定时任务;②、接收国家局mq调度。省局启动数据采集任务的具体步骤如下:(1)、省局通过定时任务或者接收国家局mq调度,启动数据收集任务;(2)、数据压缩、加密;(3)、向中央服务器发送消息;(4)、timer五分钟轮询并向国家局询问传输许可;(5)、是否获得国家局传输许可:①、若获得传输许可,则ftp上传数据到国家局的242存储服务器;(6)、判断是否上传成功:①、若上传成功,则发送mp消息到国家局,国家局接收mp消息后,修改文件状态并将文件状态反馈给242存储服务器。101服务器处理数据的具体步骤如下:(ⅰ)、启动jar,每2分钟轮询242服务器;(ⅱ)、session.getstdout()获取服务器文件信息;(ⅲ)、判断文件是否传输完毕:①、若传输完毕,则通过ch.ethz.ssh2从远程拉取压缩文件;(ⅳ)、通过ssh删除242介质文件并反馈给国家局的242存储服务器(ⅴ)、解密解压文件;(ⅵ)、通过文件名解析相关参数;(ⅶ)、删除greenplum数据库重复数据;(ⅷ)、从.csv文件导入gp数据库;(ⅸ)、结束。实施例3:本发明的捷式高吞吐量大数据采集系统,该系统包括服务器端和消费端;服务器端用于根据不同的业务需求生成不同的参数消息包,通过定时任务或手动操作发送参数消息包以及对数据收集压缩包进行数据的解密、解压操作,得到解压后的.csv文件;消费端用于在接收到服务器端发送来的消息包后进行解析,获取相应参数,再依照参数进行数据收集,并通过dtp传输通道完成数据收集,将收集的数据写入.csv文件,并对.csv文件进行压缩、加密操作,生产数据收集压缩包以及将数据收集压缩包通过ftp或sftp方式上传到服务器端(两种传输方式主要是考虑到系统兼容性问题)。实施例4:以信息中心、商业公司、工业公司为例:如附图2所示,信息中心包括行业监管平台、营销大数据平台和greenplum数据库。商业公司包括营销平台和db2/oracle数据库。工业公司包括分析指挥平台和greenplum数据库。商业公司到信息中心的数据传输步骤如下:(1)、轮询db2/oracle数据库;(2)、logstash读取配置文件,收集数据,得到数据文件-1;(3)、将数据文件-1通过推送模块加密压缩后推送到传输通道;(4)、信息中心接收到传输通道传送的数据;(5)、读取模块解密解压数据等到数据文件-1;(6)、将数据文件-1存储到greenplum数据库。信息中心到工业公司的数据传输步骤如下:(1)、轮询信息中心的greenplum数据库;(2)、logstash读取配置文件,收集发送数据,得到数据文件-2;(3)、数据文件-2通过推送模块加密压缩后推送到传输通道;(4)、工业公司接收到传输通道传送的数据;(5)、读取模块解密解压数据等到数据文件-2;(6)、将数据文件-2存储到工业公司greenplum数据库。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1