一种基于生物医学文献的知识问答系统及方法与流程
本发明涉及知识工程领域、自然语言处理领域以及计算机网络信息技术领域,具体涉及一种基于生物医学文献的知识问答系统及方法。
背景技术:
随着物质生活水平的提高,人们对身体健康的关注与日俱增,但多数情况下人们并不能去医院及时了解自己的健康症状,一方面是因为去医院需要花费很多时间、精力,另一方面由于时间限制,人们在就医的过程中不能完整的描述自己的症状,往往会遗漏一些有关症状的重要信息,因此人们迫切希望可以通过某种便捷途径及时了解自己的健康状况。
随着网络上医学文献的增多,人们自助利用医学文献寻求帮助成为一种可能,但人们通过医学文献资源寻求答案的过程较为繁琐,这个过程主要分为三步“find,read,learn”:第一步,find,即先从海量的医学文献中查找到相关的文献,目前已存在这种功能的网站,如pubmed;第二步,read,即用户系统阅读文献内容,找到与自己查询相关的段落;第三步,learn,即理解阅读相关段落,学习自己所需要的答案。
然而这个过程不仅对普通大众,甚至对相关医学工作人员来讲都是个极大地挑战。因此,为了满足更多用户需求,本申请设计了一种通过对生物医学文献进行处理并回答用户问题的生物医学问答系统,本系统可以使第一、二步的工作自动进行,从而节约用户时间。
自从1999年trec(textretrievalconference)举办的问答系统比赛开始,很多学者就开始致力于研究开放领域的qa系统,但针对医学特定领域的qa系统研究却相当有限。medqa[9]自动分析了大量电子文档,以便根据特定的问题生成简短一致的答案,其答案信息来自各种已发表的医学文献以及在线的医学资源。此外,瑞士有honqa系统,它是由瑞士一家非盈利机构hon(healthonthenetfoundation)运营,该系统从该机构认证的所有网站来获取医学文献,这样保证了医学信息的质量和可靠性。另外,askhermes帮助医生从文献中提取和表达多媒体信息,通过自动检索、提取、分析和整合来自多个来源的信息(包括医学文献和其他在线信息资源)以制定答案,从而据此回答相关临床问题。
eagli系统从medline摘要中提取答案并返回geneontology(go)概念列表并使用基于字典的分类器将go概念分别分配给medline摘要,该系统根据统计学原理进行排名:相关文档涉及的概念中次数越多的概念即相关性越强的概念。
上述研究虽然对医学知识问答发展产生了一定的促进作用,但也存在一些不足之处,如eagli系统将从医学文献中提取的医学概念作为答案,但医学概念并不能很好的回答用户的问题,并且可能会使没有医学专业背景的用户产生困惑。另外,还有一些研究侧重于答案提取和答案生成,致力于生成自然语言描述从而提高可读性。上述方法普遍忽略了答案的准确性和严谨性。然而在医学领域,错误信息很容易造成误诊,错误答案远比没有答案更容易对用户健康产生威胁。因此,在医学问答质量保证体系中数据质量是关键影响因素,medline的文献显然比在线资源更可靠。针对上述情况,本专利通过生物医学文献资源结合各种查询处理和检索方法,从而保证文本信息的正确性。
技术实现要素:
本发明的目的在于开发了一种基于生物医学文献的知识问答系统及方法,解决在生物医学领域具有挑战性的基于自然语言描述的生物问答系统,其主要是通过对生物医学文献进行处理从而回答用户问题的生物医学问答系统,传统问答系统要解决的是如何挖掘问题和候选答案之间的qa关系,而生物医学领域除此之外还具有其特殊性,即生物医学问答系统的错误答案很容易造成用户的误诊,从而威胁用户健康,因此,本申请提出一个通过对生物医学文献进行处理从而回答用户问题的生物医学问答系统,最大程度地保证答案信息的准确性。
为实现上述目的本发明提供如下技术方案:
一种基于生物医学文献的知识问答系统,所述系统通过融合信息检索和自然语言处理方法,挖掘生物医学自然语言问题和生物医学文献之间的qa关系,从而构建以生物医学文献片段来回答用户的生物医学问题;
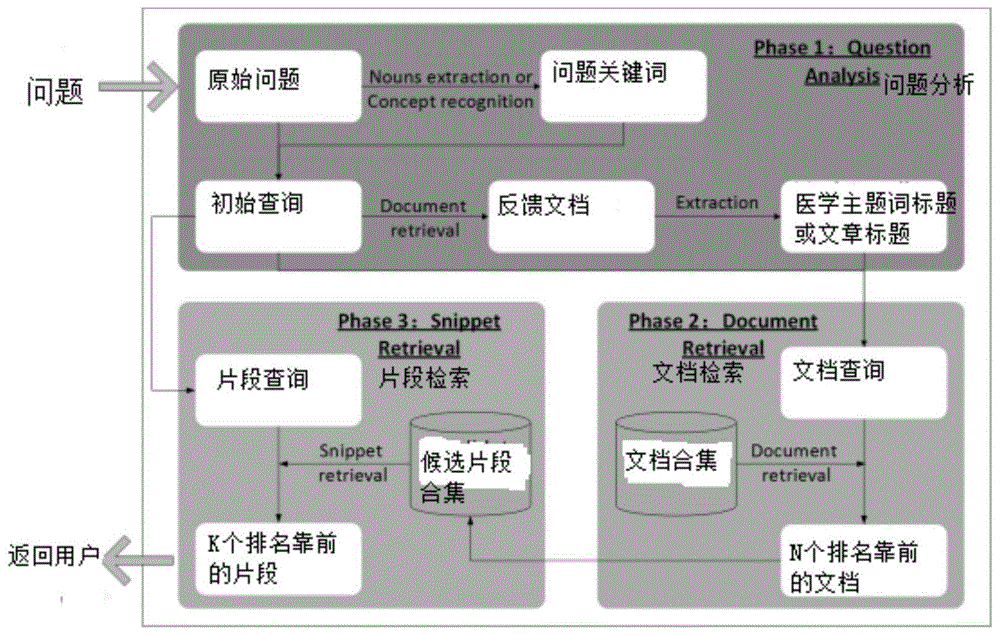
进一步地,所述系统包括问题分析模块、文档检索模块和片段检索模块,所述问题分析模块通过所述文档检索模块与所述片段检索模块连接所述问题分析模块;
问题分析模块,所述问题分析模块通过初步信息检索和自然语言处理,对自然语言描述的原始用户问题进行分析,获得适配度最高的查询问题;
文档检索模块,所述文档检索模块通过融合不同的文档检索模型获得文档最佳检索模型,并将问题分析模块的结果代入文档最佳检索模型,对医学文档进行检索,获得若干相关度依次递减的文档;
片段检索模块,所述片段检索模块根据文档检索模块检索的结果,将若干文档的标题和摘要分割成句子合集,作为“候选片段”合集,通过对不同的片段检索模型融合,获得片段最佳检索模型,将问题分析模块的结果代入片段最佳检索模型,从“候选片段”合集中获取回答医学问题的句子;
进一步地,所述问题分析模块中,所述初步信息检索通过组合查询精炼和查询扩展技术,对自然语言处理后的原始用户问题进行初步检索;
进一步地,所述问题分析模块中,自然语言处理包括提取文本名词、扩展文本近义词和伪相关反馈扩展相关主题词;
进一步地,所述文档检索模块中,不同的文档检索模型包括基于语序的检索模型sdm和基于域的检索模型fsdm,通过对不同的文档检索模型进行前期训练,设计出不同的权重,最终获的文档最佳检索模型,其相关文件的最终评分函数为:
score(q,d)=λ1scoresdm(q,d)+λ2scorefsdm(q′,d)+λ3scoresdm(q″,d)
其中d为医学文档,λ1,λ2,λ3为权重参数,q为将原始查询去停用词后的查询词汇,q′从原始查询中提取的名词关键词,q″是通过伪相关反馈从最相关的若干篇文档的标题中获取到的扩展查询词汇;
scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分;
scorefsdm(q′,d)为使用fsdm检索模型得到的查询q′和文档d之间的相关度得分;
scoresdm(q″,d)为使用sdm检索模型得到的查询q″和文档d之间的相关度得分;
进一步地,所述片段检索模块中,不同的片段检索模型包括基于语序的检索模型sdm和基于词频统计分配权重的检索模型pdfr和tf-idf模型,不同的片段检索模型配备不同的查询语句,通过前期训练,设计不同的权重,从而获得片段最佳检索模型,其相关文件的最终评分函数为:
score(q,d)=(1-λ4-λ5)scoresdm(q,d)+λ4scoretf-idf(q,d)+λ5scorepdfr(q,d);
其中d是医学文档,λ4,λ5为权重参数,q是将原始查询去停用词后的查询词汇;
scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分;
scoretf-idf(q,d)为使用tf-idf检索模型得到的查询q和文档d之间的相关度得分;
scorepdfr(q,d)为使用pdfr检索模型得到的查询q和文档d之间的相关度得分;
进一步地,一种基于生物医学文献的知识问答方法,所述方法包括如下步骤:
s1:问题分析,利用自然语言处理技术分析理解用户问题并生成查询;
s2:文档检索,融合检索模型并查找与用户问题相关性最强的医学文献;
s3:片段检索,根据短文本查询的特点融合检索模型并查找与用户问题相关性最强的片段;
进一步地,所述步骤s1具体包括如下步骤:
s11:获取用户查询问题,利用自然语言处理技术分析理解用户问题,通过名词提取或概念识别,获取问题关键词;
s12:进入初始查询或第一轮查询,通过问题查询、文档检索形成反馈文档;
s13:对反馈文档进行提取并形成医学主题词标题或文章标题;
进一步地,所述步骤s3具体包括如下步骤:
s31:选取若干个排名靠前的文档,形成候选片段合集;
s32:对候选片段合集进行片段检索,根据短文本查询的特点,利用融合sdm、pdfr和tf-idf模型得到的检索方法查找与用户问题最相关的片段;
s32:选取排名靠前的若干个片段返回给用户;
进一步地,在所述步骤s31中,片段检索模型中放弃使用伪相关查询文本扩展方法,根据查询项不同的重要性来分配查询项的权重,融合基于语序的检索模型sdm、基于词频统计分配权重的检索模型pdfr和模型tf-idf作为附加查询加权模型,优化查询项权重,根据模型tf-idf、基于语序的检索模型sdm和基于词频统计分配权重的检索模型pdfr得到的片段检索的结果评分函数为:
score(q,d)=(1-λ4-λ5)scoresdm(q,d)+λ4scoretf-idf(q,d)+λ5scorepdfr(q,d)式(2)
其中d代表医学文档,λ4,λ5分别为第四权重参数和第五权重参数,q是将原始查询去停用词后的查询词汇,scoretf-idf(q,d)为使用tf-idf检索模型得到的查询q和文档d之间的相关度得分,scorepdfr(q,d)为使用pdfr检索模型得到的查询q和文档d之间的相关度得分。
本发明的有益效果如下:
1、本发明采用了提取文本名词、扩展文本近义词和伪相关反馈扩展相关主题词等查询处理方式,融合了sdm,fsdm和pdfr检索方法,基于查询约简模型,查询扩展模型,顺序依赖模型(sdm),域顺序依赖模型(fsdm)优化查询项的权重,不仅对全局进行检索,还对不同文本域分配不同的权重进行检索,有效地提高了文档检索效果;
2、本发明在片段检索中放弃使用伪相关查询文本扩展方法,控制查询长度,根据查询项不同的重要性分配查询项的权重,引入pdfr或tf-idf模型作为附加查询加权模型,优化了查询项权重;
3、本发明在文档检索中根据文档结构因素,每个域都有其特定意义以及不同的重要程度,采用了基于域的检索方法fsdm,对不同的域赋予不同的权重,与不区分域进行检索的sdm方法相比提高了文档的检索效果;
4、在片段检索中本发明根据短文本的特点采用基于词频的方法(tf-idf,pdfr),强化了词频统计方法,确保了查询的精炼性,提高了片段检索的效果。
附图说明
图1为本发明生物医学问答系统的系统框架结构示意图;
图2为本发明文档检测效果与bioasqtask5b其他参赛队效果对比;
图3为本发明片段检测效果与bioasqtask5b其他参赛队效果对比;
图4为本发明各种方法在bioasqtask4b数据集上的文档检测效果对比;
图5为本发明各种方法在bioasqtask4b数据集上的片段检测效果对比。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细描述。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分,对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
下面结合附图和具体实施例对本发明作进一步说明,但不作为对本发明的限定。下面结合附图对本发明的实施例进行详细说明:
如图1-图5所示,本发明提供了一种基于生物医学文献的知识问答系统,所述系统通过融合信息检索和自然语言处理方法,挖掘生物医学自然语言问题和生物医学文献之间的qa关系,从而构建以生物医学文献片段来回答用户的生物医学问题,所述系统包括问题分析模块、文档检索模块和片段检索模块,所述问题分析模块通过所述文档检索模块与所述片段检索模块连接;
问题分析模块,所述问题分析模块通过初步信息检索和自然语言处理,对自然语言描述的原始用户问题进行分析,获得适配度最高的查询问题;
文档检索模块,所述文档检索模块通过融合不同的文档检索模型获得文档最佳检索模型,并将问题分析模块的结果代入文档最佳检索模型,对医学文档进行检索,获得若干相关度依次递减的文档;
片段检索模块,所述片段检索模块根据文档检索模块检索的结果,将若干文档的标题和摘要分割成句子合集,作为“候选片段”合集,通过对不同的片段检索模型融合,获得片段最佳检索模型,将问题分析模块的结果代入片段最佳检索模型,从“候选片段”合集中获取回答医学问题的句子。
所述问题分析模块中,所述初步信息检索通过组合查询精炼和查询扩展技术,对自然语言处理后的原始用户问题进行初步检索,自然语言处理包括提取文本名词、扩展文本近义词和伪相关反馈扩展相关主题词。
所述文档检索模块中,不同的文档检索模型包括基于语序的检索模型sdm和基于域的检索模型fsdm,通过对不同的文档检索模型进行前期训练,设计出不同的权重,最终获的文档最佳检索模型,其相关文件的最终评分函数为:
score(q,d)=λ1scoresdm(q,d)+λ2scorefsdm(q′,d)+λ3scoresdm(q″,d)
其中d为医学文档,λ1,λ2,λ3为权重参数,q为将原始查询去停用词后的查询词汇,q′从原始查询中提取的名词关键词,q″是通过伪相关反馈从最相关的若干篇文档的标题中获取到的扩展查询词汇;
scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分;
scorefsdm(q′,d)为使用fsdm检索模型得到的查询q′和文档d之间的相关度得分;
scoresdm(q″,d)为使用sdm检索模型得到的查询q″和文档d之间的相关度得分。
所述片段检索模块中,不同的片段检索模型包括基于语序的检索模型sdm和基于词频统计分配权重的检索模型pdfr和tf-idf模型,不同的片段检索模型配备不同的查询语句,通过前期训练,设计不同的权重,从而获得片段最佳检索模型,其相关文件的最终评分函数为:score(q,d)=(1-λ4-λ5)scoresdm(q,d)+λ4scoretf-idf(q,d)+λ5scorepdfr(q,d);
其中d是医学文档,λ4,λ5为权重参数,q是将原始查询去停用词后的查询词汇;
scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分;
scoretf-idf(q,d)为使用tf-idf检索模型得到的查询q和文档d之间的相关度得分;
scorepdfr(q,d)为使用pdfr检索模型得到的查询q和文档d之间的相关度得分。
一种基于生物医学文献的知识问答方法,所述方法包括:
s1:问题分析,利用自然语言处理技术分析理解用户问题并生成查询;
s2:文档检索,融合检索模型并查找与用户问题相关性最强的医学文献;
s3:片段检索,根据短文本查询的特点融合检索模型并查找与用户问题相关性最强的片段。
所述步骤s1具体包括如下步骤:
s11:获取用户查询问题,利用自然语言处理技术分析理解用户问题,通过名词提取或概念识别,获取问题关键词;
s12:进入初始查询或第一轮查询,通过问题查询、文档检索形成反馈文档;
s13:对反馈文档进行提取并形成医学主题词标题或文章标题。
所述步骤s3具体包括如下步骤:
s31:选取若干个排名靠前的文档,形成候选片段合集;
s32:对候选片段合集进行片段检索,根据短文本查询的特点,利用融合sdm、pdfr和tf-idf模型得到的检索方法查找与用户问题最相关的片段;
s32:选取排名靠前的若干个片段返回给用户。
在所述步骤s31中,片段检索模型中放弃使用伪相关查询文本扩展方法,根据查询项不同的重要性来分配查询项的权重,融合基于语序的检索模型sdm、基于词频统计分配权重的检索模型pdfr和模型tf-idf作为附加查询加权模型,优化查询项权重,根据模型tf-idf、基于语序的检索模型sdm和基于词频统计分配权重的检索模型pdfr得到的片段检索的结果评分函数为:
score(q,d)=(1-λ4-λ5)scoresdm(q,d)+λ4scoretf-idf(q,d)+λ5scorepdfr(q,d)式(2)
其中d代表医学文档,λ4,λ5分别为第四权重参数和第五权重参数,q是将原始查询去停用词后的查询词汇,scoretf-idf(q,d)为使用tf-idf检索模型得到的查询q和文档d之间的相关度得分,scorepdfr(q,d)为使用pdfr检索模型得到的查询q和文档d之间的相关度得分。
本发明所述系统分为三个部分,分别为问题分析模块,文档检索模块和片段检索模块。
问题分析阶段,利用自然语言处理技术分析理解用户的问题,并生成查询;
文档检索模块,融合多种检索技术查找与用户问题最相关的医学文献;
片段检索模块根据短文本查询的特点融入新的检索方法查找与用户问题最相关的片段。
(1)本发明使用的数据集
在实施例中,本发明使用的是bioasq比赛提供的数据集,该数据集包括英文医学文献和由欧洲各研究团队的生物医学专家团队标注的英文的问题以及其标准答案。这些医学文献是由美国国家医学图书馆(nlm)制作维护的来自medline,生命科学期刊和在线书籍的生物医学文献,数量超过2600万册,并以xml文档格式展示。bioasq比赛每年有五批测试数据集,用作评估taskb比赛中参与团队系统的效果,每批测试数据集包含100个生物医学问题。
(2)实验描述
首先,本发明通过美国国立卫生研究院(nih)的ftp服务下载2017年2月更新的medline整个数据库,其中包含26,759,010个文献。
这些文档以xml文件表示,其中包含各种信息,包括期刊信息,标题内容,作者,摘要,关键词,类似文章和评论。本发明分析文献内容后选择以下字段来表示文档:articletitle,abstracttext,title,medlineta,nameofsubstance,descriptorname,qualifiername,keyword和isoabbreviation。
将这些字段的内容提取出来表示文档,并使用开源搜索引擎galago建立索引。
其次,本发明进行了一系列工作来提取用户查询的关键字。在查询中很多特殊符号与查询本身意义相关度不大,因此本发明在第一步中先过滤掉符号。另外,像“what”或“are”这样的单词在自然语言问题中很常见,并不适合提供给搜索引擎,因此根据停用词列表删除它们。同时,还将查询词汇进行大小写转换等规范化处理。此外,本发明使用stanford-postagger软件包从查询中识别名词,使用metamap识别查询术语中的生物医学概念。
接着,本发明使用galago工具包中的batch-search命令进行初始排序,以获得排名靠前的t篇相关文档,并且提取这些文档的标题,并将标题进行处理后添加到之前第一轮的查询中从而生成新的查询,该查询将用于第二轮的文档检索以获得最终相关文档。在文档检索中,本发明使用了不同的搜索模型,如查询似然(ql)模型,序列依赖模型(sdm),基于域的顺序依赖模型(fsdm),并且最终评分函数如式(1)所示。
score(q,d)=λ1scoresdm(q,d)+λ2scorefsdm(q′,d)+λ3scoresdm(q″,d)式(1)
其中d是医学文档,λ1,λ2,λ3为权重参数,q是将原始查询去停用词后的查询词汇,q′从原始查询中提取的名词关键词,q″是通过伪相关反馈从最相关的n篇文档的标题中获取到的扩展查询词汇。scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分,scorefsdm(q′,d)为使用fsdm检索模型得到的查询q′和文档d之间的相关度得分,scoresdm(q″,d)为使用sdm检索模型得到的查询q″和文档d之间的相关度得分。
最后,上一步中排名靠前的n个文档的标题和摘要被分割成句子,这些句子将被用作片段检索的语料库。与文档检索不同,片段检索中的候选文本都是以非结构化形式表示,这使得一些基于域的排序模型更难以利用(例如fsdm)。此外,由实验表明,当查询相比于片段过长时,片段检索的性能会下降,因此本申请中对查询的长度进行控制。此外,伪相关反馈方法通常提供大量的扩展查询术语,也会影响短文本的搜索性能,因此在片段检索中放弃使用伪相关查询文本扩展方法。同时,随着查询的长度减小,每个单词的重要性差异变大,因此有必要根据查询项不同的重要性来分配查询项的权重。因此引入pdfr或tf-idf(termfrequency-inversedocumentfrequency)模型作为附加查询加权模型,以优化查询术语的最合适权重。所以在构建片段检索的结果评分函数中,根据tf-idf、顺序依赖模型(sdm)和pdfr来优化查询项权重在片段检索中,本发明使用查询似然(ql)模型,序列依赖模型(sdm),tf-idf模型,pdfr模型,并且最终评分函数如式(2)所示。
score(q,d)=(1-λ4-λ5)scoresdm(q,d)+λ4scoretf-idf(q,d)+λ5scorepdfr(q,d)式(2)
其中d是医学文档,λ4,λ5为权重参数,q是将原始查询去停用词后的查询词汇,scoresdm(q,d)为使用sdm检索模型得到的查询q和文档d之间的相关度得分,scoretf-idf(q,d)为使用tf-idf检索模型得到的查询q和文档d之间的相关度得分,scorepdfr(q,d)为使用pdfr检索模型得到的查询q和文档d之间的相关度得分。
(3)实验结果
本发明首先在bioasqtask4b文档检索和片段检索上单独验证每个方法组件的有效性。然后,本发明以不同的方式组合每种方法并调整参数以达到最佳的组合效果。最后,本发明比较了各种组合的有效性,并分别在图4和图5中展示了它们的性能比较。
从图4可以看出,除了单独使用提取名词作为查询项的方法(nn)之外,所有检索模型都比基础模型效果好。并且不同方法的所有组合都比单独的方法效果好。整体而言,通过sdm+nn+fsdm+mesh+prf(mesh)模型可获得最佳性能,与第4批次的基础模型结果相比,最大提升效果可达到21.4%。
而从图5可知,sdm+prf,sdm+nn和sdm+nn+prf方法的性能相较于基本模型都没有很大提高,但sdm+pdfr和sdm+tf-idf方法有很大的提升效果。
此外,本发明还参加了bioasq5b的知识问答比赛,所提交的结果相较于其他参赛团队有很大的优势,结果如图2和图3所示。从中可以看出,与其他团队的最佳结果相比,本发明的方法具有良好的效果和稳定性,并且在片段检索中提升效果分别为10.4%,30.4%,82.5%,55.5%,35.9%。
总体而言,本发明提出的生物医学问答系统设计了一个有效的框架,可以挖掘生物医学问题与生物医学文献片段之间的相关性,从而使用简短的片段语句回答生物医学问题。在qa系统中,如何从大量的文档中找出最相关的片段仍是最大的挑战。如果直接将文档进行切分成片段从而进行检索,工作量则会非常大,而效果也不好。目前最有效的方法,仍是先检索出最相关的文档,然后将文档进行分割在进行检索,从而可以提高检索效果。但这里仍面临的问题是,文档检索的效果将直接影响片段的检索效果,因此首先需要保证的就是文档检索的效果。而从图2中可看到,本申请的文档检索效果相较其他检索的方法有一定的优势。
在文档检索中,查询处理扮演了一个相当重要的角色。本申请所述系统融合了多种查询处理方法,包括查询主题词抽取以及查询词汇扩展等方法。本发明先提取查询主题关键词,然后,将查询主题词汇进行扩展,得到相同概念的更多不同表述,与此同时保留原始查询词汇,最后将这三种查询进行加权,从而获得最优的检索效果。从图4可以看出,通过将查询精炼(nn)和查询扩展(prf,w2v)可以有效的提高检索效果相较于原始查询。
除此之外,在文档检索中也不能忽视文档的结构。因为医学文献都是结构化文档,而每个域都有其特定意义以及不同的重要程度,因此需要对不同的域赋予不同的权重从而提高文档的检索效果。而从图4中也可看出,基于域的检索方法fsdm相较于不区分域进行检索的sdm方法确实有很大提升效果。
最后,本申请对短文本和长文本进行检索的方法也不完全一致。在片段检索中,文档检索的中的最优方法并不一定有效,因此需要根据短文本的特点,确保查询的精炼性,并强化词频统计方法的重要性,从而可以提高片段检索的效果。可以从图5看出,相较于其他小组基于词频的方法(tf-idf,pdfr)都取得了很好的效果。
- 还没有人留言评论。精彩留言会获得点赞!