一种基于深度学习的负面网络舆情指数的计算方法及系统与流程
一种基于深度学习的负面网络舆情指数的计算方法及系统,用于计算负面网络舆情指数,属于文本分析和自然语言处理技术领域。
背景技术:
舆情是“舆论情况”的简称,是指在一定的社会空间内,围绕中介性社会事件的发生、发展和变化,作为主体的民众对作为客体的社会管理者、企业、个人及其他各类组织及其它信息的取向产生和持有的社会态度。它是较多群众关于社会中各种现象、问题所表达的信念、态度、意见和情绪等等表现的总和。
网络舆情是社会舆情在互联网空间的映射,是社会舆情的直接反映。传统的社会舆情存在于民间,存在于大众的思想观念和日常的街头巷尾的议论之中,前者难以捕捉,后者稍纵即逝,舆情的获取只能通过社会明察暗访、民意调查等方式进行,获取效率低下,样本少而且容易流于偏颇,耗费巨大。而随着互联网的发展,大众往往以信息化的方式发表各自看法,网络舆情可以采用网络自动抓取等技术手段方便获取,效率高而且信息保真(没有人为加工),覆盖面全。
负面网络舆情指数是对负面网络舆情的量化指标。
专利号为:zl201510355005.0的一种负面舆情指数的计算方法及系统,,包括步骤s1,对待分类文本进行基于情感词典的正负面分类和基于model模型的svm分类,分别得到分类结果1和分类结果2;步骤s2,若所述分类结果1与所述分类结果2的值都为负面,则认为待分类文本为负面,继续执行步骤s3;若所述分类结果1与所述分类结果2的值不都为负面,则认为待分类文本为非负面,计算结束;步骤s3,将待分类文本分别与用户标注负面词典和训练集关键词典匹配,分别得到负面指标1和负面指标2;步骤s4,将所述分类结果1、所述负面指标1和所述负面指标2进行线性组合,得到待分类文本的负面舆情指数。本发明计算出的负面舆情指数准确率高,计算语料范围广且能够实时计算。但存在以下不足之处采用有监督的机器学习技术,需要大量的人工标注数据指导模型训练后,识别负面舆情后计算负面指数。大量的人工标注数据,费时费力成本高。并且有监督的负面预期模型不能通用,如金融领域的模型,不能直接用于其它领域,需要重新标注和重新训练,不仅金融领域如此,其它领域之间也不能通用。
技术实现要素:
针对上述研究的问题,本发明的目的在于提供一种基于深度学习的负面网络舆情指数的计算方法及系统,解决现有技术中,采用有监督的机器学习技术,需要大量的人工标注数据指导模型训练,且不通用的问题。
为了达到上述目的,本发明采用如下技术方案:
一种基于深度学习的负面网络舆情指数的计算方法,其特征在于,如下步骤:
步骤1、获取包含关键字的舆情文章;
步骤2、获取大量文章并进行处理,得到训练集,将训练集用于训练mlstm模型,得到负面舆情识别模型;
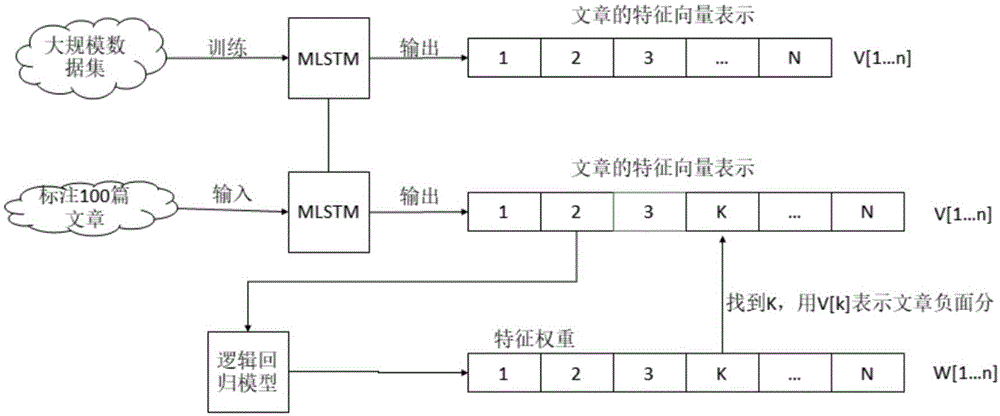
步骤3、对少量文章进行标注,同时基于负面舆情识别模型得到每篇文章的特征向量后,训练逻辑回归分类器得到绝对值最大的权重|w|对应的维度k;
步骤4、基于负面舆情识别模型计算舆情文章的特征向量,再根据特征向量的维度k所对应的负面舆情分值得到关键字的最终负面舆情指数。
进一步,所述步骤1的具体步骤为:
步骤1.1、给出要计算负面舆情指数的关键字;
步骤1.2、通过网络爬虫,抓取网站的文章标题和正文;
步骤1.3、从已抓取文章标题和正文,过滤出包含关键字的文章,作为包含关键字的舆情文章。
进一步,所述步骤2的具体步骤为:
步骤2.1、获取大量文章,过滤其标点符号和特殊字符后,作为训练集,其中,文章为含关键字的文章或/和不含关键字的文章;
步骤2.2、对训练集中的所有字符进行one-hot编码后,构建映射字典;
步骤2.3、根据映射字典,将训练集的每篇文章中的字符替换为one-hot编码,作为mlstm模型输入,训练mlstm模型,得到训练好的mlstm模型,训练好的mlstm模型即为负面舆情识别模型。
进一步,所述步骤3的具体步骤为:
步骤3.1、从步骤2所获取的文章中抽取少量文章,对于每篇文章,根据映射字典,将文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到每篇文章的特征向量x[1…n],同时标注文章正面或负面,以y表示,将x,y作为正负面分类器的训练集;
步骤3.2、基于步骤3.1得到的训练集训练逻辑回归分类器,得到逻辑回归分类器参数,即特征向量x[1…n]对应的权重w[1…n];
步骤3.3、遍历步骤3.1抽取的所有文章的权重w[1…n],找到绝对值最大的权重|w|对应的维度k,则文章的负面舆情分值为x[k]。
进一步,所述步骤4的具体步骤为:
步骤4.1、分别计算每篇舆情文章的负面分值,计算方式为:对于每篇舆情文章,过滤标点符号和特殊字符后,根据映射字典,将舆情文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到舆情文章的特征向量x[1…n],其中x[k]为该篇舆情文章的负面舆情分值;
步骤4.2、求所有舆情文章的负面舆情分值x[k]的平均值,得到关键字的最终负面舆情指数。
一种基于深度学习的负面网络舆情指数的计算系统,其特征在于,包括:
网络舆情监测模块:获取包含关键字的舆情文章和大量文章;
负面舆情识别模块:对获取的大量文章进行处理,得到训练集,将训练集用于训练mlstm模型,得到负面舆情识别模型;
对少量文章进行标注,同时基于负面舆情识别模型得到每篇文章的特征向量后,训练逻辑回归分类器得到绝对值最大的权重|w|对应的维度k;
负面舆情指数计算模块:基于负面舆情识别模型计算舆情文章的特征向量,再根据特征向量的维度k所对应的负面舆情分值得到关键字的最终负面舆情指数。
进一步,所述网络舆情监测模块的实现方式包括如下步骤:
接收要计算负面舆情指数的关键字;
通过网络爬虫,抓取网站的文章标题和正文;
从已抓取文章标题和正文,过滤出包含关键字的文章,作为包含关键字的舆情文章或包含关键字的文章;或
接收要抓取训练所用的文章指令,通过网络爬虫抓取大量的文章,其中,文章为含关键字的文章或/和不含关键字的文章。
进一步,所述负面舆情识别模块得到负面舆情识别模型的具体步骤为包括:
对获取的大量文章,过滤其标点符号和特殊字符后,作为训练集;
对训练集中的所有字符进行one-hot编码后,构建映射字典;
根据映射字典,将训练集的每篇文章中的字符替换为one-hot编码,作为mlstm模型输入,训练mlstm模型,得到训练好的mlstm模型,训练好的mlstm模型即为负面舆情识别模型。
进一步,所述负面舆情识别模块得到维度k的具体步骤包括:
从大量文章中抽取少量文章,对于每篇文章,根据映射字典,将文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到每篇文章的特征向量x[1…n],同时标注文章正面或负面,以y表示,将x,y作为正负面分类器的训练集;
基于训练集训练逻辑回归分类器,得到逻辑回归分类器参数,即特征向量x[1…n]对应的权重w[1…n];
遍历抽取的所有文章的权重w[1…n],找到绝对值最大的权重|w|对应的维度k,则文章的负面舆情分值为x[k]。
进一步,所述负面舆情指数计算模块实现的具体步骤包括:
分别计算每篇舆情文章的负面分值,计算方式为:对于每篇舆情文章,过滤标点符号和特殊字符后,根据映射字典,将舆情文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到舆情文章的特征向量x[1…n],其中x[k]为该篇舆情文章的负面舆情分值;
求所有舆情文章的负面舆情分值x[k]的平均值,得到关键字的最终的负面舆情指数。
本发明同现有技术相比,其有益效果表现在:
一、本发明采用无监督的深度学习技术,无需负面词典,通过少量标注即可识别负面舆情并计算负面指数,可节约大量人工标注成本;
二、本发明通用性强,跨领域效果好,应用到不同领域,只要使用不同领域的未标注数据重新训练即可,不需要重新人工标注数据,迁移到其它领域省时省力,不需要重新人工标注数据是因为迁移前的标注数据确定了k后就不需要标注数据了;
三、而无监督的模型,可直接用未标注的数据训练模型,省时省力成本低。并且应用到不同领域,只要使用不同领域的未标注数据重新训练即可,不需要重新标注。
附图说明
图1为本发明得到负面舆情识别模型和维度k的示意图;
图2为本发明实施例中求得负面舆情指数的示意图。
具体实施方式
下面将结合附图及具体实施方式对本发明作进一步的描述。
本发明中所针对的“舆情”是指“网络舆情”。
一种基于深度学习的负面网络舆情指数的计算方法,步骤如下:
步骤1、获取包含关键字的舆情文章;具体步骤为:
步骤1.1、给出要计算负面舆情指数的关键字;
步骤1.2、通过网络爬虫,抓取网站的文章标题和正文;
步骤1.3、从已抓取文章标题和正文,过滤出包含关键字的文章,作为包含关键字的舆情文章。
步骤2、获取大量文章并进行处理,得到训练集,将训练集用于训练mlstm模型,得到负面舆情识别模型;具体步骤为:
步骤2.1、获取大量文章,过滤其标点符号和特殊字符后,作为训练集,其中,文章为含关键字的文章或/和不含关键字的文章;
步骤2.2、对训练集中的所有字符进行one-hot编码后,构建映射字典;
步骤2.3、根据映射字典,将训练集的每篇文章中的字符替换为one-hot编码,作为mlstm模型输入,训练mlstm模型,得到训练好的mlstm模型,训练好的mlstm模型即为负面舆情识别模型。
步骤3、对少量文章进行标注,同时基于负面舆情识别模型得到每篇文章的特征向量后,训练逻辑回归分类器得到绝对值最大的权重|w|对应的维度k;具体步骤为:
步骤3.1、从步骤2所获取的文章中抽取少量文章,对于每篇文章,根据映射字典,将文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到每篇文章的特征向量x[1…n],同时标注文章正面或负面,以y表示,将x,y作为正负面分类器的训练集;
步骤3.2、基于步骤3.1得到的训练集训练逻辑回归分类器,得到逻辑回归分类器参数,即特征向量x[1…n]对应的权重w[1…n];
步骤3.3、遍历步骤3.1抽取的所有文章的权重w[1…n],找到绝对值最大的权重|w|对应的维度k,则文章的负面舆情分值为x[k]。
步骤4、基于负面舆情识别模型计算舆情文章的特征向量,再根据特征向量的维度k所对应的负面舆情分值得到关键字的最终负面舆情指数。具体步骤为:
步骤4.1、分别计算每篇舆情文章的负面分值,计算方式为:对于每篇舆情文章,过滤标点符号和特殊字符后,根据映射字典,将舆情文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到舆情文章的特征向量x[1…n],其中x[k]为该篇舆情文章的负面舆情分值;
步骤4.2、求所有舆情文章的负面舆情分值x[k]的平均值,得到关键字的最终负面舆情指数。
一种基于深度学习的负面网络舆情指数的计算系统,包括:
网络舆情监测模块:获取包含关键字的舆情文章和大量文章;实现方式包括如下步骤:
接收要计算负面舆情指数的关键字;
通过网络爬虫,抓取网站的文章标题和正文;
从已抓取文章标题和正文,过滤出包含关键字的文章,作为包含关键字的舆情文章或包含关键字的文章;或
接收要抓取训练所用的文章指令,通过网络爬虫抓取大量的文章,其中,文章为含关键字的文章或/和不含关键字的文章。
负面舆情识别模块:对获取的大量文章进行处理,得到训练集,将训练集用于训练mlstm模型,得到负面舆情识别模型;
对少量文章进行标注,同时基于负面舆情识别模型得到每篇文章的特征向量后,训练逻辑回归分类器得到绝对值最大的权重|w|对应的维度k;
具体步骤为包括:
对获取的大量文章,过滤其标点符号和特殊字符后,作为训练集;
对训练集中的所有字符进行one-hot编码后,构建映射字典;
根据映射字典,将训练集的每篇文章中的字符替换为one-hot编码,作为mlstm模型输入,训练mlstm模型,得到训练好的mlstm模型,训练好的mlstm模型即为负面舆情识别模型;
从大量文章中抽取少量文章,对于每篇文章,根据映射字典,将文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到每篇文章的特征向量x[1…n],同时标注文章正面或负面,以y表示,将x,y作为正负面分类器的训练集;
基于训练集训练逻辑回归分类器,得到逻辑回归分类器参数,即特征向量x[1…n]对应的权重w[1…n];
遍历抽取的所有文章的权重w[1…n],找到绝对值最大的权重|w|对应的维度k,则文章的负面舆情分值为x[k]。
负面舆情指数计算模块:基于负面舆情识别模型计算舆情文章的特征向量,再根据特征向量的维度k所对应的负面舆情分值得到关键字的最终负面舆情指数。
实现的具体步骤包括:
分别计算每篇舆情文章的负面分值,计算方式为:对于每篇舆情文章,过滤标点符号和特殊字符后,根据映射字典,将舆情文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到舆情文章的特征向量x[1…n],其中x[k]为该篇舆情文章的负面舆情分值;
求所有舆情文章的负面舆情分值x[k]的平均值,得到关键字的最终的负面舆情指数。
实施例
给出要计算负面舆情指数的关键字,比如“新网银行”。
从新闻网站、贴吧、微博、微信公众号等网站,通过网络爬虫,抓取文章标题和正文。
从已抓取文章的标题和正文,过滤出包含关键字“新网银行”的文章,作为与“新网银行”相关的舆情文章。
按照收集舆情文章的方式收集不包含关键字的文章,收集过去5-10年的文章,过滤标点符号和特殊字符,作为训练集。
对训练集中的字符,进行one-hot编码,构建映射字典。
根据映射字典,将训练集中的字符替换为one-hot编码,作为mlstm模型输入,开始训练模型。
模型训练完成后,得训练好的mlstm模型,训练好的mlstm模型即为负面舆情识别模型。
从收集的不包含关键字的文章中抽取100篇文章,对于每篇文章,根据映射字典,将文章中的字符转换为one-hot编码,输入负面舆情识别模型进行转换,得到每篇文章的特征向量x[1…n],同时标注文章正面或负面,以y表示,将x,y作为正负面分类器的训练集。
基于分类器的训练集训练逻辑回归分类器,得到逻辑回归分类器参数,其中特征向量x[1…n]对应的权重w[1…n]。
遍历抽取的所有文章的权重w[1…n],找到绝对值最大的|w|对应的维度k,则文章的负面舆情分值为x[k]。
对于“新网银行”相关舆情的每一篇舆情文章,分别计算每篇舆情文章的负面分。计算方式为:对于每篇舆情文章,过滤标点符号和特殊字符后,根据映射字典,将舆情文章中的字符转换为one-hot编码,输入训练好的mlstm模型进行转换,得到舆情文章的特征向量x[1…n],其中x[k]为该篇舆情文章的负面舆情分值,k为1…n中绝对值最大的|w|对应的维度。
求所有舆情文章的负面舆情分值x[k]的平均值,得到关键字的最终的负面舆情指数。
以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!