一种支持交换共享的临床数据单元生成方法和装置与流程
本发明涉及一种支持交换共享的临床数据单元生成方法和装置,属于临床数据交换共享技术领域。
背景技术:
目前临床数据使用面临着收集效率低、数据的真实性和安全性无法保证、数据筛查分析整理缺乏有效的装置和方法等诸多问题,这是因为传统的统一资源定位符url是一种地址驱动的方式,侧重数据地址空间,语义描述能力较弱,缺失内容空间,难以支持知识萃取、内容治理、版权保护、可信认证等。
近年来,中国工程院院士李幼平先生提出了“统一内容定位”的思想。统一内容标签ucl(uniformcontentlocator)是一种在统一资源定位符url基础上发展起来的多维度全方位描述信息资源的标准化矢量特征的内容元数据。
若将ucl这种数据标准用于临床数据,形成一种支持交换共享的数据单元,可以有效解决上述数据问题。因此设计一种针对临床医疗数据领域,基于ucl标准的数据单元,使之能够全方位描述临床内容的语用信息、语义信息和管理信息,兼顾数据的使用者、所有者和数管理者,满足交换共享,是一项迫切且意义重大的工作。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种支持交换共享的临床数据单元生成方法和装置,通过统一数据采集模块和数据清理转换模块来完成数据的获取和清洗,借助疾病知识库构建管理模块来进行数据的知识提取,并最终通过统一内容标签管理模块按照临床ucl标准生成支持交换共享的临床数据单元,实现全面描述临床数据内容,方便医生对患者进行分类,更加准确和有效地了解患者病情,同时让科研单位能够更加便捷的查找筛选,定位目标人群。
本发明通过以下技术方案实现,包括统一数据采集模块、数据清理转换模块、疾病知识库构建管理模块,统一内容标签管理模块;
所述统一数据采集模块,用于获取结构化、半结构化和非结构化的医疗临床数据;
所述数据清理转换模块,是对采集的医疗数据进行转换和清洗,生成标准化的数据,同时构建患者主索引empi(enterprisemasterpatientindex),形成以患者单次就诊为单元的标准医疗数据;
所述疾病知识库构建管理模块是通过人工智能和大数据技术,并结合专家经验,形成医疗疾病知识体系数据库;从而提供了疾病诊断、症状表现、实验室检验、检查、治疗等信息以及之间的关系,为临床数据摘要特征提取提供指导;
所述统一内容标签管理模块包括特征提取模块、结构化处理模块、标签封装模块,首先采用自然语言处理技术对半结构化和非结构化的数据进行处理,转换成结构化的数据;再根据临床疾病知识库构建管理模块获取的知识,区分不同的疾病类型,对临床医疗就诊数据完成关键信息提取、转换和编码;需要说明的是,若没有建设临床疾病知识库,按最小单元封装;按照临床ucl标准格式进行数据封装,最终生成支持交换共享的临床数据单元。
所述的特征提取模块将患者的就诊数据送入所述知识库进行检索,根据诊断信息匹配疾病危险因素,匹配疾病、症状、检查、检验等实体以及之间的关系,输出当前患者需要关注的疾病特征指标及其风险因素,特征提取模块在知识库的辅助下,完成对患者基本信息、门急诊/住院就诊信息、实验室检验报告、医学影像检查报告、门诊/住院收费明细、电子病历、诊断明细报告、手术明细报告、门诊处方明细和住院医嘱明细的特征提取。需要说明的是,若没有建设临床疾病知识库,按最小单元封装:主诉中的症状,个人史、家族史、婚育史,检查中的名称和诊断,以及其他结构化字段。
所述的结构化处理模块采用自然语言处理技术对半结构化和非结构化医疗数据进行处理,通过分词、实体识别、实体映射等技术手段将其转换成结构化和标准的临床医疗数据;
进一步,在结构化处理中,还需要将一些非结构化的特征,提取转换成基于三元组通用表示方式,包括:<实体1,关系,实体2>和<实体,属性,属性值>。
其中按照实体类型分类,可以分为疾病名称(disease),如i型糖尿病;病因(reason),疾病的成因、危险因素及机制。比如“糖尿病是由于胰岛素抵抗导致”,胰岛素抵抗是属于病因;临床表现(symptom),包括症状、体征,病人直接表现出来的和需要医生进行查体得出来的判断。如"头晕""便血"等;检查方法(test),包括实验室检查方法,影像学检查方法,辅助试验,对于疾病有诊断及鉴别意义的项目等,如甘油三酯;检查指标值(test_value),指标的具体数值,阴性阳性,有无,增减,高低等,如”>11.3mmol/l”;药品名称(drug),包括常规用药及化疗用药,比如胰岛素;用药频率(frequency),包括用药的频率和症状的频率,比如一天两次;用药剂量(amount),比如500mg/d;用药方法(method):比如早晚,餐前餐后,口服,静脉注射,吸入等;非药治疗(treatment),在医院环境下进行的非药物性治疗,包括放疗,中医治疗方法等,比如推拿、按摩、针灸、理疗,不包括饮食、运动、营养等;手术(operation),包括手术名称,如代谢手术等;不良反应(sideeff),用药后的不良反应;部位(anatomy),包括解剖部位和生物组织,比如人体各个部位和器官,胰岛细胞;程度(level),包括病情严重程度,治疗后缓解程度等;持续时间(duration),包括症状持续时间,用药持续时间,如“头晕一周”的“一周”,一共15种实体类型。
其中按照实体类别关系分类,按三元组形式化表示可以分为:<检查方法,test_disease,疾病>、<临床表现,symptom_disease,疾病>、<非药治疗,treatment_disease,疾病>、<药品名称,drug_disease,疾病>、<部位,anatomy_disease,疾病>、<用药频率,frequency_drug,药品名称>、<持续时间,duration_drug,药品名称>、<用药剂量,amount_drug,药品名称>、<用药方法,method_drug,药品名称>、<不良反应,sideeff_drug,药品名称>等10种实体类型关系。
所述的标签封装模块,定义符合ucl标准规范格式的临床数据单元,其内容包括语用信息、语义信息和管理信息;其中语用信息主要针对临床数据的使用者,包括科研结构、医疗相关企业等,是面向数据使用者的内容导航,包括:患者的性别、出生日期、出生地、宗教、职业、医保、empi、就诊唯一标识、就诊时间、就诊名称、就诊年龄、医疗机构标识;而语义信息主要是面向数据提供者,主要体现医生治疗行为和意图,包括:摘要、患者基本信息、门急诊/住院就诊信息、实验室检验报告、医学影像检查报告、门诊/住院收费明细、电子病历、诊断明细报告、手术明细报告、门诊处方明细和住院医嘱明细、数据质量、评价;管理信息主要是为数据内容提供管理的依据,面向的是数据的管理和监督方,包括:版权、出处、安全和签名,支持可信度认证和溯源。
统一数据采集模块负责采集患者门急诊及住院的临床数据,内容包括患者基本信息、门急诊/住院就诊信息、实验室检验报告、医学影像检查报告、门诊/住院收费明细、电子病历、诊断明细报告、手术明细报告、门诊处方明细和住院医嘱明细。
通过数据库接口、网络服务接口、hl7接口获取医院的院内数据,包括患者性别、出生日期、出生地、宗教、职业、医保信息;
通过适配器接口,获取到诊断信息,包括就诊唯一标识、就诊时间、就诊名称、就诊地、就诊年龄、医疗机构标识、诊断编码、诊断时间、病症描述等信息;
通过适配器接口,获取到实验室检验数据,收集报告名称、检验项目编码、检验项目名称、检验单名称、检验指标名称、检验指标结果、检验时间、计量单位和异常提示信息;
通过适配器接口,获取电子病历的主诉、现病史、既往史、家族史、个人史等信息和日常病程、首次病程、术后首次病程信息;
通过适配器接口,获取到手术数据,收集手术名称、手术级别、手术日期和电子申请单编码信息;
通过适配器接口,获取到检查数据,收集检查项目名称、检查描述、检查大类型、检查客观结果、检查主管结果和检查时间信息;
通过适配器接口,获取到用药数据,收集药品名称、用药方式、药品分类、药物单位、药物剂量、药品规格和药物频次信息;
通过适配器接口,获取到费用数据,收集总费用、西药费、手术费、治疗费和住院费信息。
数据清理转换模块是对非标准化数据,进行数据格式转换、异常剔除、缺失值填充、类型统一等处理,通过一系列的标准化数据处理手段,得到标准化的临床数据。需要进一步说明的是,empi是患者在多个医疗系统中的唯一标识,因此需要在清洗转换过程中,针对每一个病人建立唯一患者主索引。通过本模块一系统所述的处理,能够形成以患者一次就诊为单元的标准医疗数据。
疾病知识库构建管理模块是覆盖疾病、药物库、检验、检查库等临床医学体系的临床医学数据库,基于所述数据和资料,构建以症状、处置、检查、检验、用药为实体,以时间、大小、状态、态度为属性,生成以疾病与并发症,疾病与症状,症状与症状,疾病与检查,症状与检查,疾病与用药为边的疾病知识关系图谱。
本发明包括与统一数据采集模块连接的数据清理转换模块,数据清理转换模块与疾病知识库构建管理模块分别与统一内容标签管理模块连接;
统一内容标签管理模块包括特征提取模块、结构化处理模块、标签封装模块。
本发明的优点在于,提供了一种支持交换共享的临床数据单元生成方法和装置,能够将采集的临床医疗数据通过转换、清洗和编码形成以患者一次就诊为单元的标准医疗数据,结合疾病知识库提供的疾病特征的定义,从标准的医疗数据中提取患者的疾病和治疗过程特征信息,最后根据本发明定义的临床ucl数据结构,生成支持交换共享且符合ucl标准的临床数据单元。
附图说明
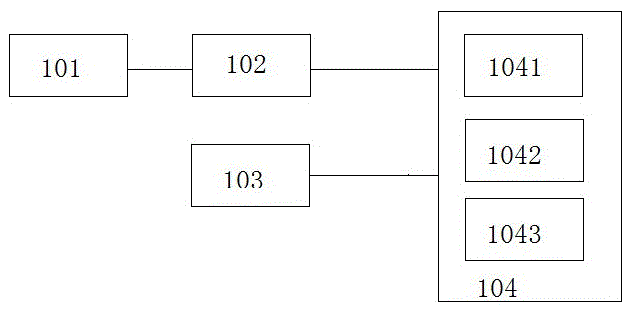
图1为本发明结构示意图。
具体实施方式
下面将结合本发明实施例中的附图1对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种基于ucl标准的数据摘要生成方法和装置,包括:统一数据采集模块、数据清理转换、疾病知识库构建管理,统一内容标签管理模块。
所述统一数据采集模块101,用于获取结构化、半结构化和非结构化的医疗机构病例数据。
所述数据清理转换模块102,是对数据进行转换和清洗,生成标准化的数据,同时构建患者主索引empi(enterprisemasterpatientindex),最终形成以患者一次就诊为单元的标准医疗数据。
所述疾病知识库构建管理模块103是结合专家经验,基于所述数据和资料,构建以症状、处置、检查、检验、用药为实体,以时间、大小、状态为属性,生成以疾病与并发症,疾病与症状,症状与症状,疾病与检查,症状与检查,疾病与用药为边的疾病知识关系图谱。
所述统一内容标签管理模块104结合疾病知识库提供的疾病特征的定义,从标准的医疗数据中提取患者的疾病和治疗过程特征信息,采用自然语言处理技术对半结构化和非结构化的数据进行处理,转成成结构化的数据,将结构化的数据进行统一编码;最后根据本发明定义的临床ucl数据结构,生成符合ucl标准的临床数据单元。
本实施例中,数据采集模块101块包含以下步骤:
具体来说,通过数据库接口、网络服务接口、hl7接口来获取到医院的院内数据,包括患者患者的性别、出生日期、出生地、宗教、职业、医保等信息。
通过适配器接口,获取到诊断信息,包括就诊唯一标识、就诊时间、就诊名称、就诊地、就诊年龄、医疗机构标识、诊断编码、诊断时间、病症描述等信息。
通过适配器接口,获取到实验室检验数据,收集报告名称、检验项目编码、检验项目名称、检验单名称、检验指标名称、检验指标结果、检验时间、计量单位和异常提示等信息;
通过适配器接口,获取电子病历的主诉、现病史、既往史、家族史、个人史等信息和日常病程、首次病程、术后首次病程等信息。
通过适配器接口,获取到手术数据,收集手术名称、手术级别、手术日期和电子申请单编码等信息。
通过适配器接口,获取到检查数据,收集检查项目名称、检查描述、检查大类型、检查客观结果、检查主管结果和检查时间等信息。
通过适配器接口,获取到用药数据,收集药品名称、用药方式、药品分类、药物单位、药物剂量、药品规格和药物频次等信息。
通过适配器接口,获取到费用数据,收集总费用、西药费、手术费、治疗费和住院费等信息。
本实施例中,数据转换清理模块102块包含以下步骤:
将获取到的临床数据进行数据清理、转换、标准化,形成结构化数据,并且采用例如均值填充、离群点判断、噪声监测、回归、分箱等清洗算法进行针对性的数据深度清洗,解决原始数据的不规范和不规则等问题,例如进行本模块的处理,可以获取到标准的诊断名称和对应的诊断编码。
需要进一步说明的是,empi是患者在多个医疗系统中的唯一标识,因此需要在清洗转换过程中,针对每一个病人建立唯一患者主索引。索引的生成规则是:按姓名+身份证号+卡号+地址+联系号码+联系人+入院日期字段对同名病人进行判断,若是同一病人,取这个病人首次入院时的住院号作为此病人的标识,生成empi。
本实施例中,疾病知识库构建管理模块103包含以下步骤:
疾病知识库是在专科医联体下基于海量个性化数据而产生,海量数据下的基于概率的关联性推理,包括:汇聚疾病专科医联体下共享的医疗机构临时病历数据,以及专家共识、临床指南、临床路径等权威资料;构建疾脏病专科知识库,该知识库以疾病核心,以症状、处置、检查、检验、用药等为实体,以时间、大小、状态等为属性,以疾病与并发症,疾病与症状,症状与症状,疾病与检查,症状与检查,疾病与用药等为边的即病知识关系图谱。
需要说明的是,为了有效地解决传统知识库指标固化,灵活性欠佳的问题,本文所述知识库必须是可扩展、可编辑和可配置的,能够支持定时更新,通过专家定义的形式,持续和及时地融入专家智慧,保障知识库的权威性。
本实施例中,统一内容标签管理104块包含以下步骤:
1041结合疾病知识库提供的疾病特征的定义,从标准的医疗数据中提取患者的疾病和治疗过程特征信息。
1042采用自然语言处理技术完成数据的结构化的处理。
1043根据本发明定义的临床ucl数据结构,生成符合ucl标准的临床数据单元。
在步骤1041中,将标准的就诊数据送入知识库进行检索,根据诊断信息,匹配疾病危险因素,接着匹配疾病、症状、检查、检验等重要指标,不仅包含指标的异常项,还包含需要关注的正常项。需要说明的是,为了保证处理效率,可以批量一次性查询获取所有知识内容,避免逐条查询造成的性能问题。
具体来说,以肾脏病人一次就诊记录为例,针对知识库建立的疾病与症状、检验指标、检查指标等数据间的网络图谱,将数据灌入到知识库后,知识库检测到慢性肾脏病的诊断,则根据知识库中慢性肾脏病的定义:是指肾脏损伤或gfr<60ml/min·1.73m2持续3个月。(1)肾脏损伤(肾脏结构或功能异常)≥3个月,可以有或无gfr下降,关注下列异常:病理学检查异常;肾损伤的指标阳性:包括血、尿成分异常或影像学检查异常;(2)gfr<60ml/min·1.73m2≥3个月,有或无肾脏损伤证据。从而获知此次就诊记录需要关注病理学检查异常,血清中肌酐、钾、钙、磷、二氧化碳指标异常,尿液中指标异常、影像报告中肾检查异常。此外还需要关注历史肌酐检验指标数据,以及计算gfr值需要的性别、年龄、体重等信息。
需要说明的是,若没有建设临床疾病知识库,按最小单元提取并进行后续封装,最小单元包括,主诉中的症状,个人史、家族史、婚育史,检查中的名称和诊断,以及其他结构化字段。
在步骤1042中,对于例如主述、现病史这类包含大量文字描述的非结构化数据,采用自然语言处理技术,包括分词、实体识别、实体映射等一系列技术手段,利用大数据计算平台提供的运算能力,将文本数据转换为结构化的词汇和词组。对于半结构化例如json和xml格式的数据,会自动识别格式类型,并将其转换是结构化格式。
具体的,通过获取到的医院内的患者数据,提取包括患者年龄、职业、性别、居住地、收入情况等信息。
获取个人史信息,结构化提取是否吸烟,吸烟时长,吸烟次数等信息;结构化提取是否饮酒,饮酒时长,饮酒次数等信息。
获取既往史信息,结构化提取是否有高血压病史,服用高血压药物、服用时长信息,结构化提取是否有糖尿病病史,服用糖尿病药物、服用时长等信息,结构化提取是否有高血脂病史,服用糖尿病药物、服用时长等信息,结构化提取是否有肾移植史信息,从现病史中获取到中草药信息。
获取现病史信息,结构化提取有无肝炎、有无结核、有无伤寒等病史,结构化提取是否有手术、是否有输血,结构化提取是否有药物过敏、是否预防接种信息。结构化提取是否有肾移植史。
获取家族史信息,结构化家族内患有高血压、糖尿病、冠心病的亲属。
获取到实验室检验数据,收集检验指标白蛋白尿指标值、收集血液中肌酐指标值、收集血液中二氧化碳指标值、收集血液中磷指标值、收集血液中血红蛋白具体指标值、收集血液中钾指标值、收集血液中钙具体指标值,收集尿液中尿沉渣是否异常。
采用标准dicom协议,收集影像图片,解析图片中检查信息。
例如,特征提取模块依据疾病知识库对就诊记录进行特征提取,将得到如下结构的数据:
患者基本信息包括性别、出生日期、出生地、职业、宗教、empi;
门急诊/住院就诊信息包括:就诊类型、入院/就诊时间、出院时间、入院/就诊科室、出院科室、医保、职业、就诊流水号、医疗机构代码、婚姻状况、支付方式;
实验室检验报告包括检查日期、样本、检验项编码、结果、异常标志;
门诊/住院收费明细包括总费用、西药费、手术费、治疗费和住院费等;
门诊处方明细和住院医嘱明细包括功能类别、药品名称、用药方式、药品分类、药物单位、药物剂量、药品规格和药物频次等;
诊断明细报告包括就诊断时间、诊断类别和诊断编码;
医学影像检查报告包括编号10010、检查日期2015/10/20、报告单:超声计算机图文报告、检查客观描述:<双肾,血流分布,正常><双肾,形态,规则><双肾,表面,光滑><侧输尿管,明显扩张,未见>;
手术明细报告收集包括手术名称:腹膜透析置管术、手术步骤:<ns,剂量,100ml><可回收液体,剂量,50ml><切口,大小,0.5×0.5cm><术中出血,约,10ml>、手术级别:中、手术日期:2015-07-02、伤口愈合级别:ⅰ/甲,进一步的,对于手术步骤进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示;
电子病历包括主诉、现病史、既往史、家族史、个人史等信息以及日常病程、首次病程、术后首次病程等。
进一步的,对于主诉进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<头晕,时间,2年><恶心,时间,2年><呕吐,时间,2年>
进一步的,对于现病史进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<头昏,时间,2年><恶心,时间,1年><呕吐,时间,1年>
<慢性肾功能不全,分期,ckd5期><高血压,分期,3级><高血压,分型,极高危>
<环磷酰胺,剂量,1g><右侧腰肋部,表现,疼痛><小便量,约,1000ml>
进一步的,对于既往史进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<肾结石病史,时间,10余年><膀胱结石病史,时间,10余年><高血压病史,时间,5年><放疗,次数,25次>
进一步的,对于家族史进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<家族性遗传病,有无,无><家族性传染病史,有无,无>
<高血压家族史,有无,无><糖尿病家族史,有无,无>
进一步的,对于个人史进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<吸烟史,有无,无><饮酒史,有无,无>
进一步的,对于体格检查进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<体温,大小,36.3℃><脉搏,大小,96次/分><心率,大小,20次/分><血压,大小,194/107mmhg>
<右眼睑,表现,重度下垂><左眼睑,表现,轻度下垂>
进一步的,对于日常病程进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<发热,有无,无>、<食物过敏史,有无,无>、<接触过敏史,有无,无>、<荨麻疹,位于,头部>、<荨麻疹,位于,面部>、<荨麻疹,位于,头颈>、<荨麻疹,位于,躯干>
进一步的,对于首次病程进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<侧输尿管,明显扩张,未见>、
<头昏,时间,2年><恶心,时间,1年><呕吐,时间,1年>
<慢性肾功能不全,分期,ckd5期><高血压,分期,3级><高血压,分型,极高危>
<抗炎,予以,强的松><环磷酰胺,剂量,1g><右侧腰肋部,表现,疼痛><小便量,约,1000ml>
进一步的,对于术后首次病程进行关键信息提取,通过使用自然语言处理技术,结合疾病知识库,将信息转换成三元组形式表示如下:
<伤口渗血,有无,无>、<伤口渗液,有无,无>、<血氧饱和度,值,97%>
在步骤1043中将对特征选值进行编码,并且按照定义的临床ucl格式进行数据封装。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!