一种火车票余票查询方法与流程
本发明属于火车票查询
技术领域:
,具体涉及一种火车票余票查询方法。
背景技术:
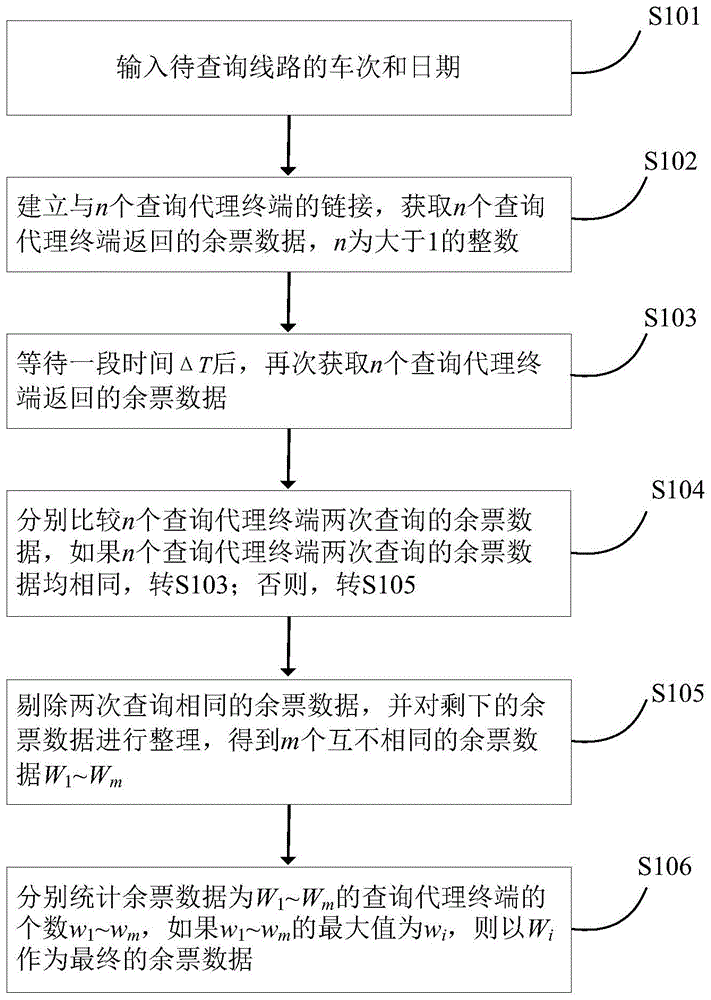
:随着经济的飞速发展,人口流动越来越频繁。从东到西,由南到北,打工流、学生流、探亲流均大大增加了运输的繁忙程度。铁路作为最廉价、最安全的出行方式,备受人们的青睐,这就使购票难的问题越来越严重。尤其是逢年过节、春运、暑运期间情形更是紧迫。不管是网上购票,还是去火车站售票口买票,人们一般都是先要查询余票数量,好做到心中有数。然而,火车票(12306)查询吞吐量巨大,为了缓解服务器压力,服务端会启用数据缓存。火车票查询服务终端属于矩阵式设计,各地访问的终端不一致(比如,湖北电信访问12306响应终端位于襄阳电信机房、北京访问12306响应终端位于北京联通机房),服务器之间缓存数据会有一定差异,造成请求返回的车票数量存在信息错误(缓存脏数据)。春运期间这种现象尤为严重,极大地影响了用户购票体验。技术实现要素:为了解决现有技术中存在的上述问题,本发明提出一种火车票余票查询方法。为实现上述目的,本发明采用如下技术方案:一种火车票余票查询方法,包括以下步骤:步骤1,输入待查询线路的车次和日期;步骤2,建立与n个查询代理终端的链接,获取n个查询代理终端返回的余票数据,n为大于1的整数;步骤3,等待一段时间δt后,再次获取n个查询代理终端返回的余票数据;步骤4,分别比较n个查询代理终端两次查询的余票数据,如果n个查询代理终端两次查询的余票数据均相同,转步骤3;否则,转步骤5;步骤5,剔除两次查询相同的余票数据,并对剩下的余票数据进行整理,得到m个互不相同的余票数据w1~wm;步骤6,分别统计余票数据为w1~wm的查询代理终端的个数w1~wm,如果w1~wm的最大值为wi,则以wi作为最终的余票数据。进一步地,所述δt=2秒。进一步地,如果w1~wm的最大值的数量多于一个,转步骤3。与现有技术相比,本发明具有以下有益效果:本发明通过建立多个查询代理终端,比较所述多个查询代理终端相隔一段时间的两次查询结果,剔除两次查询结果相同的数据,以剩余数据中出现频率最高的数据作为最终的余票数据,在一定程度上消除了缓存脏数据的影响,提高了查询火车票余票数量的准确度。附图说明图1为本发明实施例一种火车票余票查询方法的流程图。具体实施方式下面结合附图对本发明作进一步详细说明。本发明实施例一种火车票余票查询方法的流程图如图1所示,所述方法包括:s101、输入待查询线路的车次和日期;s102、建立与n个查询代理终端的链接,获取n个查询代理终端返回的余票数据,n为大于1的整数;s103、等待一段时间δt后,再次获取n个查询代理终端返回的余票数据;s104、分别比较n个查询代理终端两次查询的余票数据,如果n个查询代理终端两次查询的余票数据均相同,转s103;否则,转s105;s105、剔除两次查询相同的余票数据,并对剩下的余票数据进行整理,得到m个互不相同的余票数据w1~wm;s106、分别统计余票数据为w1~wm的查询代理终端的个数w1~wm,如果w1~wm的最大值为wi,则以wi作为最终的余票数据。在本实施例中,步骤s101用于输入要查询的车次和出行日期,如2018年12月31日从北京到上海的高铁g133。在本实施例中,步骤s102用于建立代理服务器与n个查询代理终端的链接,并获取n个查询代理终端返回的余票数据。目前,全国各地的(如北京、上海、广州等)的代理查询终端多如牛毛,通过互联网很容易建立起与多个查询代理终端,由查询服务器统一调度,发起查询任务,各地终端查询后将结果返回查询服务汇总。对于本实施例的技术方案来说,n的值越大,余票查询结果越准确;但n的值太大会降低查询速度。因此,n的取值应折衷考虑。余票数据是按照座位等级分别给出的余票数量,如一般快车的座位等级包括软卧、硬卧、硬座和无座,高铁的座位等级包括特等座、一等座、二等座和无座。可用数组表示余票数据。值得说明的是,不同地域、不同网络请求12306火车票查询服务,最终服务终端不一样,比如湖北电信访问12306响应终端位于襄阳电信机房,北京访问12306响应终端位于北京联通机房,由于不同的服务器数据同步会有差异,因此,不同查询代理终端即使对相同日期和车次的线路同时进行的查询,得到的余票数据也可能不同。在本实施例中,步骤s103用于在第一次查询后再过一段时间δt,第二次获取n个查询代理终端返回的余票数据。间隔一段时间查询的目的是使两次查询的余票数据发生变化,为后面的统计分析做准备。两次查询结果发生变化的原因主要有两个:一是余票数据确实发生了变化,如等待期间被买走、被退票、12306突然放票;二是有的终端通知缓存刷新。等待时间的δt的选取主要考虑两个因素:δt太小,查询到票量变化概率变小;δt过大,影响查询速度以及数据的实时性。一般根据经验或通过反复试验确定。在本实施例中,步骤s104用于比较n个查询代理终端两次查询的余票数据是否相同,如果n个查询代理终端两次查询的余票数据均相同,说明所有余票数据都有可能是缓存脏数据,因此需要重新获取数据,即转步骤s103等待δt后进行第三次查询,直到两次查询的余票数据不完全相同。两次查询的余票数据完全相同的发生概率很低,连续出现两次的概率更低,因此即使偶尔出现,一般也不需要等待太长时间。因此,一般不需要进行第三次查询。如果两次查询的余票数据不完全相同,则转下一步s105。在本实施例中,步骤s105用于去掉两次查询相同的余票数据,对剩下的余票数据进行整理,得到m个互不相同的余票数据w1~wm。比如,如果查询代理终端a两次查询得到的余票数据相同,就去掉来自查询代理终端a的余票数据。这样处理的目的是为了消除缓存脏数据(将两次查询得到的余票数据相同看作是由缓存脏数据所致)。对剩下的余票数据进行整理,如果不同的查询代理终端得到的余票数据相同,只保留1个,这样就可以得到m个互不相同的余票数据w1~wm。在本实施例中,步骤s106用于通过分别统计余票数据w1~wm所属的查询代理终端的个数w1~wm,并求出w1~wm的最大值为wi,进而得到最终的余票数据wi。例如,如果w1~wm的最大值为w5,则以w5作为最终的余票数据。这种处理方法的原理是:出现频率越大的余票数据越接近真实值。比如,如果一共6个查询代理终端得到的余票数量分别为1,2,4,4,4,2,那么真实的余票数量最可能是4。作为一种可选实施例,所述δt=2秒。本实施例给出了两次查询之间时间间隔δt的一种具体选取方案。选取δt=2秒,只是一种较佳的实施方式,可以为他人选取时间间隔δt提供参考,并不排斥其它可行的取值方案。作为一种可选实施例,如果w1~wm的最大值的数量多于一个,转s103。本实施例给出了w1~wm的最大值不只一个时的处理方案。比如,如果w1~wm的最大值为w5=w8=5,由于w5≠w8,不好确定以w5和w8哪一个值作为最终的余票数据更合理。本实施例的处理方法是返回步骤s103,等待δt后重新获取新的余票数据,重复执行s103~s106。这种事件发生的概率也不高,连续出现两次的概率更低,因此即使偶尔出现,一般也不需要等待太长时间。为了便于理解本发明的技术方案,下面给出一个应用实例。查询2018年12月31时北京到上海的高铁g133的余票信息。选取5个查询代理终端dl1~dl5。dl1~dl5两次查询的余票数据分别如表1、2所示。表1第一次查询的余票数据(单位:张)特等座一等座二等座无座dl11316200dl21316200dl31316200dl41316200dl51316200表2第二次查询的余票数据(单位:张)特等座一等座二等座无座dl11314200dl21314200dl31316200dl41314200dl51315200由表1、2可知,只有dl3两次查询的余票数据相同,均为13/16/20/0。剔除13/16/20/0并整理后得到2个不同的余票数据:w1=13/14/20/0,w2=13/15/20/0。3个查询代理终端dl1、dl2和dl4的余票数据为w1,所以w1=3,1个查询代理终端dl5的余票数据为w2,所以w2=1。因为max(w1,w2)=max(3,1)=3=w1,所以w1=13/14/20/0为最终的余票数据,即特等座13张,一等座14张,二等座20张,无座0张。上述仅对本发明中的几种具体实施例加以说明,但并不能作为本发明的保护范围,凡是依据本发明中的设计精神所做出的等效变化或修饰或等比例放大或缩小等,均应认为落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1