矛盾语句识别方法和系统及条款逻辑鉴别方法和系统与流程
本发明属于人工智能领域,尤其涉及一种矛盾语句识别方法和系统及条款逻辑鉴别方法和系统。
背景技术:
一直以来,推断都是人工智能领域的核心研究话题之一,同时自然语言推断作为自然语言处理方向的一个重要研究分支,其是问答系统、信息检索、自动摘要等任务的研究基础,在众多业务场景下都有着广泛的应用空间。自然语言推断中的一个核心问题是给定两组文本(premise(前提)&hypothesis(假设)),判断两者之间在语义层面是否存在矛盾关系。
由于语言表达的多样性、语义理解的困惑度,特别是中文中存在大量多义词、同义词,使得自然语言推断的难度比预想的要高,推断的精度也有很大的上升空间。
另外,针对产品相关条款的逻辑关系通常由人工鉴别,缺乏智能手段,消耗较多的人工成本,鉴别的准确率也有待提高。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中自然语言推断的难度较高,推断的精度也有很大的上升空间的缺陷,提供一种矛盾语句识别方法和系统及条款逻辑鉴别方法和系统。
本发明是通过以下技术方案解决上述技术问题的:
一种基于深度学习的矛盾语句识别方法,所述矛盾语句识别方法包括:
基于bilstm(长短时记忆网络)-attention(注意力)机制,构建矛盾语句识别模型,所述模型用于预测两个文本相矛盾的概率;
将相比较的两个文本分别转化为矩阵,作为所述模型的输入;
经过所述模型的计算,得到相比较的两个文本相矛盾的概率。
较佳地,所述构建的步骤包括:
获取原始训练文本数据,所述原始训练文本数据包括premise文本和hypothesis文本;
将premise文本和hypothesis文本按照每个字的字向量转化为矩阵,将所述矩阵作为bilstm单元的输入,以得到premise文本和hypothesis文本对应的初步语义表示,分别为:premise文本对应的bilstm输出向量序列
对hypothesis文本对应的初步语义表示沿步长维度进行最大池化处理,以提取最重要的语义表示作为hypothesis文本的最终语义表示
将q和
得到attention向量a:a=tanh(watt1·c+watt2·q);
将attention向量用于推断矛盾关系的二分类深度神经网络模型,得到所述二分类深度神经网络模型的预测值
根据premise文本和hypothesis文本关系的真实值y和所述预测值
使用优化算法对loss极小化,多次迭代训练得到最终模型。
较佳地,通过以下步骤计算premise文本对应的bilstm输出向量序列
计算premise文本对应的正向输出向量序列和反向输出向量序列;
将premise文本对应的正向输出向量序列和反向输出向量序列沿最后一个维度合并得到premise文本对应的bilstm输出向量序列
通过以下步骤计算hypothesis文本对应的bilstm输出向量序列
计算hypothesis文本对应的正向输出向量序列和反向输出向量序列;
将hypothesis文本对应的正向输出向量序列和反向输出向量序列沿最后一个维度合并得到hypothesis文本对应的bilstm输出向量序列
较佳地,所述构建的步骤还包括:对所述原始训练文本数据进行预处理;
所述矛盾语句识别方法还包括:对相比较的两个文本进行预处理;
所述预处理至少包括去噪、字的分割及字典的编码。
一种基于深度学习的条款逻辑鉴别方法,所述条款逻辑鉴别方法包括:
将相比较的两个条款文本分别转化为矩阵,作为利用如上所述的矛盾语句识别方法构建的矛盾语句识别模型的输入;
经过所述模型的计算,得到相比较的两个条款文本相矛盾的概率。
一种基于深度学习的矛盾语句识别系统,所述矛盾语句识别系统包括:
模型构建模块,用于基于bilstm-attention机制,构建矛盾语句识别模型,所述模型用于预测两个文本相矛盾的概率;
模型输入模块,用于将相比较的两个文本分别转化为矩阵,作为所述模型的输入;
模型输出模块,用于经过所述模型的计算,得到相比较的两个文本相矛盾的概率。
较佳地,所述模型构建模块用于:
获取原始训练文本数据,所述原始训练文本数据包括premise文本和hypothesis文本;
将premise文本和hypothesis文本按照每个字的字向量转化为矩阵,将所述矩阵作为bilstm单元的输入,以得到premise文本和hypothesis文本对应的初步语义表示,分别为:premise文本对应的bilstm输出向量序列
对hypothesis文本对应的初步语义表示沿步长维度进行最大池化处理,以提取最重要的语义表示作为hypothesis文本的最终语义表示
将q和
得到attention向量a:a=tanh(watt1·c+watt2·q);
将attention向量用于推断矛盾关系的二分类深度神经网络模型,得到所述二分类深度神经网络模型的预测值
根据premise文本和hypothesis文本关系的真实值y和所述预测值
使用优化算法对loss极小化,多次迭代训练得到最终模型。
较佳地,所述模型构建模块还用于:
计算premise文本对应的正向输出向量序列和反向输出向量序列;
将premise文本对应的正向输出向量序列和反向输出向量序列沿最后一个维度合并得到premise文本对应的bilstm输出向量序列
所述模型构建模块还用于:
计算hypothesis文本对应的正向输出向量序列和反向输出向量序列;
将hypothesis文本对应的正向输出向量序列和反向输出向量序列沿最后一个维度合并得到hypothesis文本对应的bilstm输出向量序列
较佳地,所述模型构建模块还用于对所述原始训练文本数据进行预处理;
所述模型输入模块还用于对相比较的两个文本进行预处理;
所述预处理至少包括去噪、字的分割及字典的编码。
一种基于深度学习的条款逻辑鉴别系统,所述条款逻辑鉴别系统包括:
条款输入模块,用于将相比较的两个条款文本分别转化为矩阵,作为利用如上所述的矛盾语句识别系统构建的矛盾语句识别模型的输入;
概率输出模块,用于经过所述模型的计算,得到相比较的两个条款文本相矛盾的概率。在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
本发明的积极进步效果在于:本发明使用深度学习技术解决自然语言推断问题,可以降低特征提取的人工成本,大幅提升推断的准确率。
附图说明
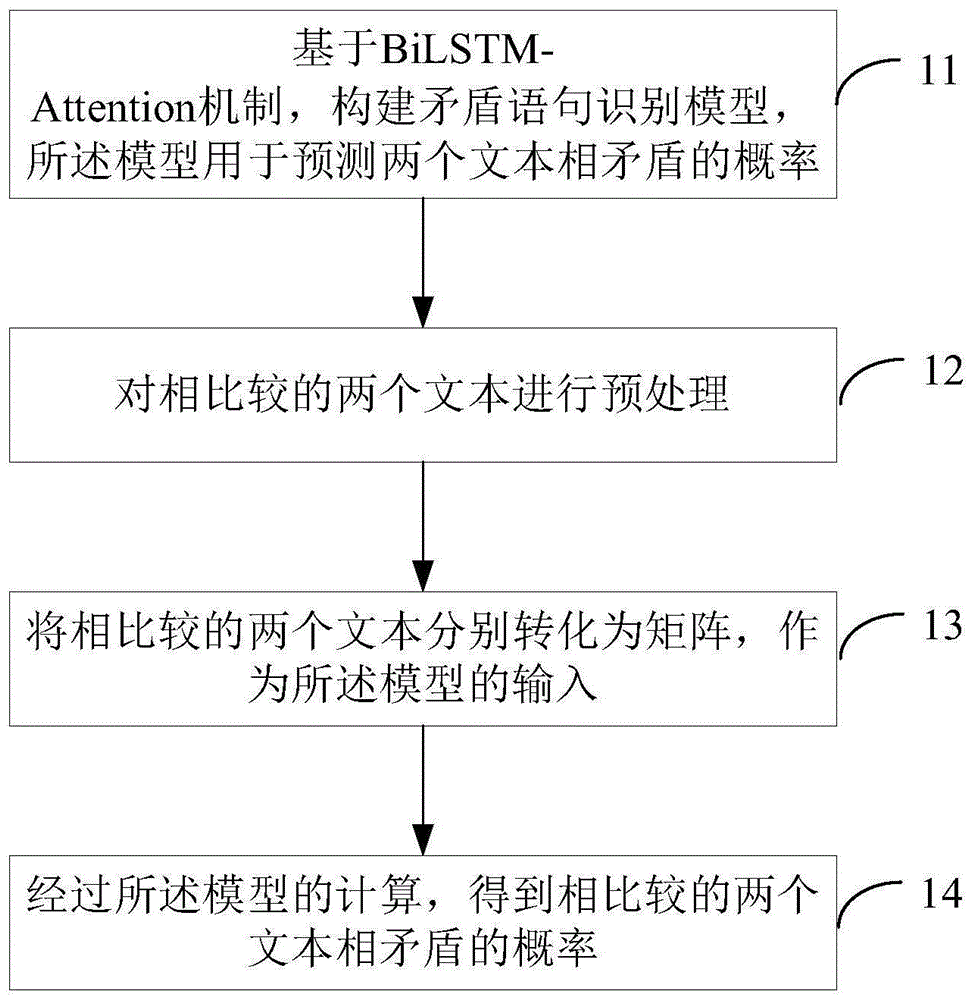
图1为本发明实施例1的一种基于深度学习的矛盾语句识别方法的流程图。
图2为本发明实施例3的一种基于深度学习的矛盾语句识别系统的示意框图。
图3为本发明实施例4一种基于深度学习的条款逻辑鉴别系统的示意框图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
图1示出了本实施例的一种基于深度学习的矛盾语句识别方法。所述矛盾语句识别方法包括:
步骤11:基于bilstm-attention机制,构建矛盾语句识别模型,所述模型用于预测两个文本相矛盾的概率。
步骤12:对相比较的两个文本进行预处理。
步骤13:将相比较的两个文本分别转化为矩阵,作为所述模型的输入。
步骤14:经过所述模型的计算,得到相比较的两个文本相矛盾的概率。
本实施例中,步骤11可以具体包括:
(1)获取原始训练文本数据,对所述原始训练文本数据进行预处理;
其中,所述原始训练文本数据包括premise文本和hypothesis文本,所述预处理至少包括去噪、字的分割及字典的编码。
(2)将premise文本和hypothesis文本按照每个字(本实施例中的字可以理解为字符,含义相同)的字向量转化为矩阵,将所述矩阵作为bilstm单元的输入,以得到premise文本和hypothesis文本对应的初步语义表示,分别为:premise文本对应的bilstm输出向量序列
其中,将premise文本按照每个字的字向量转化为矩阵的具体过程如下:
(2-1)将premise文本中的每个字转化为固定长度为n(如n=100)的字向量;
(2-2)将参与训练的文本中字的最大数目设定为m(如m=100),若premise文本中字的实际数目少于m,则不足部分用<pad>字符补充完整,若premise文本中字的实际数目超过m,则将m之外的字进行删除;
(2-3)根据文本中每个字的字向量将premise文本转化为m×n的矩阵,作为输入[x1,x2,…,xm]。
参考premise文本的转化过程(2-1)~(2-3),可将hypothesis文本按照每个字的字向量同样转化为m×n的矩阵,具体过程不再赘述。
将premise文本转化的矩阵作为bilstm单元的输入,以得到premise文本对应的初步语义表示:premise文本对应的bilstm输出向量序列
(2-4)设定当前时刻遗忘门单元和输入门单元的输出分别为ft和it,当前时刻cell(细胞)状态的更新值为
ft=σ(wf[xt,ht-1]+bf)
it=σ(wi[xt,ht-1]+bi)
其中,xt为当前时刻的输入,ht-1为前一时刻隐藏层的状态,wf、wi和wc为遗忘门单元、输入门单元和cell更新状态的权值矩阵,bf、bi和bc分别为遗忘门单元、输入门单元和cell更新状态的偏置向量,σ为sigmoid激活函数,tanh为双曲正切函数;
(2-5)通过公式
(2-6)根据以下公式得出各个隐藏节点的输出ht,将ht依次连接,构成m维的向量序列[h1,h2,…,hm]:
ot=σ(wo[xt,ht-1]+bo)
ht=ot*tanh(ct)
其中,wo为输出门单元的权值矩阵,bo为输出门单元的偏置向量,ot为输出门单元的输出;
(2-7)对premise文本正向经过步骤(2-4)~(2-6)处理,得到premise文本对应的正向输出向量序列
(2-8)将premise文本对应的正向输出向量序列
参考过程(2-4)~(2-8),对hypothesis文本正向经过步骤(2-4)~(2-6)处理,得到hypothesis文本对应的正向输出向量序列
(3)对hypothesis文本对应的初步语义表示
(4)将q和
得到attention向量a:a=tanh(watt1·c+watt2·q)。
(5)将attention向量a用于推断矛盾关系的二分类深度神经网络模型,得到所述二分类深度神经网络模型的预测值
(6)根据premise文本和hypothesis文本关系的真实值y和所述预测值
(7)使用adam(adaptivemomentestimation)优化算法对loss极小化,多次迭代训练得到最终模型。
本实施例通过上述步骤,在对hypothesis文本的语义进行提取时利用最大池化操作将其整合为一个单独的向量,然后与premise文本中的每个字向量进行匹配,在保证推断精度的同时大大减小了模型的训练成本。
在步骤12中,对相比较的两个文本进行预处理与步骤(1)中的预处理相同;在步骤13中,参考premise文本的转化过程(2-1)~(2-3),可将相比较的两个文本分别按照每个字的字向量转化为m×n的矩阵,具体过程不再赘述;在步骤14中,通过所述概率可以进一步判断相比较的两个文本是否矛盾,例如,如果所述概率超过50%,则通常可以认为相比较的两个文本相矛盾,如果所述概率未超过50%,则通常可以认为相比较的两个文本不矛盾。
实施例2
本实施例提供一种基于深度学习的条款逻辑鉴别方法。所述条款逻辑鉴别方法包括:
将相比较的两个条款文本分别转化为矩阵,作为利用实施例1的矛盾语句识别方法构建的矛盾语句识别模型的输入;
经过所述模型的计算,得到相比较的两个条款文本相矛盾的概率。
当然在将相比较的两个条款文本分别转化为矩阵之前,本实施例的条款逻辑鉴别方法可以参考实施例1的步骤12对相比较的两个条款文本进行预处理。
本实施例的条款逻辑鉴别方法可以应用于旅游产品相关条款逻辑关系的智能鉴别,比如预订限制、预订说明、产品说明等部分包含的条款内容,目的是保证公司旅游产品相关条款的合理性与逻辑性,进而做到充分保障消费者的权益,为客户提供最满意的服务。当然本实施例并不局限于此,所述条款逻辑鉴别方法同样还可以应用于其他服务类产品或实体产品,甚至是某些制度、规则条款等场景,以达到减少人工核查的人力成本,提高鉴别的准确性的效果,对于存在矛盾的条款可以有针对性的修订和完善。
实施例3
图2示出了本实施例的一种基于深度学习的矛盾语句识别系统。所述矛盾语句识别系统包括:
模型构建模块21,用于基于bilstm-attention机制,构建矛盾语句识别模型,所述模型用于预测两个文本相矛盾的概率。
模型输入模块22,用于对相比较的两个文本进行预处理,将相比较的两个文本分别转化为矩阵,作为所述模型的输入。
模型输出模块23,用于经过所述模型的计算,得到相比较的两个文本相矛盾的概率。
本实施例中,所述模型输入模块22可以具体用于:
(1)获取原始训练文本数据,对所述原始训练文本数据进行预处理;
其中,所述原始训练文本数据包括premise文本和hypothesis文本,所述预处理至少包括去噪、字的分割及字典的编码。
(2)将premise文本和hypothesis文本按照每个字(本实施例中的字可以理解为字符,含义相同)的字向量转化为矩阵,将所述矩阵作为bilstm单元的输入,以得到premise文本和hypothesis文本对应的初步语义表示,分别为:premise文本对应的bilstm输出向量序列
其中,将premise文本按照每个字的字向量转化为矩阵的具体过程如下:
(2-1)将premise文本中的每个字转化为固定长度为n(如n=100)的字向量;
(2-2)将参与训练的文本中字的最大数目设定为m(如m=100),若premise文本中字的实际数目少于m,则不足部分用<pad>字符补充完整,若premise文本中字的实际数目超过m,则将m之外的字进行删除;
(2-3)根据文本中每个字的字向量将premise文本转化为m×n的矩阵,作为输入[x1,x2,…,xm]。
参考premise文本的转化过程(2-1)~(2-3),可将hypothesis文本按照每个字的字向量同样转化为m×n的矩阵,具体过程不再赘述。
将premise文本转化的矩阵作为bilstm单元的输入,以得到premise文本对应的初步语义表示:premise文本对应的bilstm输出向量序列
(2-4)设定当前时刻遗忘门单元和输入门单元的输出分别为ft和it,当前时刻cell(细胞)状态的更新值为
ft=σ(wf[xt,ht-1]+bf)
it=σ(wi[xt,ht-1]+bi)
其中,xt为当前时刻的输入,ht-1为前一时刻隐藏层的状态,wf、wi和wc为遗忘门单元、输入门单元和cell更新状态的权值矩阵,bf、bi和bc分别为遗忘门单元、输入门单元和cell更新状态的偏置向量,σ为sigmoid激活函数,tanh为双曲正切函数;
(2-5)通过公式
(2-6)根据以下公式得出各个隐藏节点的输出ht,将ht依次连接,构成m维的向量序列[h1,h2,…,hm]:
ot=σ(wo[xt,ht-1]+bo)
ht=ot*tanh(ct)
其中,wo为输出门单元的权值矩阵,bo为输出门单元的偏置向量,ot为输出门单元的输出;
(2-7)对premise文本正向经过(2-4)~(2-6)处理,得到premise文本对应的正向输出向量序列
(2-8)将premise文本对应的正向输出向量序列
参考过程(2-4)~(2-8),对hypothesis文本正向经过步骤(2-4)~(2-6)处理,得到hypothesis文本对应的正向输出向量序列
(3)对hypothesis文本对应的初步语义表示
(4)将q和
得到attention向量a:a=tanh(watt1·c+watt2·q)。
(5)将attention向量a用于推断矛盾关系的二分类深度神经网络模型,得到所述二分类深度神经网络模型的预测值
(6)根据premise文本和hypothesis文本关系的真实值y和所述预测值
(7)使用adam(adaptivemomentestimation)优化算法对loss极小化,多次迭代训练得到最终模型。
本实施例中,所述模型构建模块21在对hypothesis文本的语义进行提取时利用最大池化操作将其整合为一个单独的向量,然后与premise文本中的每个字向量进行匹配,在保证推断精度的同时大大减小了模型的训练成本。
所述模型输入模块22对相比较的两个文本进行预处理与所述模型构建模块21中的预处理相同,参考premise文本的转化过程(2-1)~(2-3),可将相比较的两个文本分别按照每个字的字向量转化为m×n的矩阵,具体过程不再赘述;所述模型输出模块23通过所述概率可以进一步判断相比较的两个文本是否矛盾,例如,如果所述概率超过50%,则通常可以认为相比较的两个文本相矛盾,如果所述概率未超过50%,则通常可以认为相比较的两个文本不矛盾。
实施例4
图3示出了本实施例的一种基于深度学习的条款逻辑鉴别系统。所述条款逻辑鉴别系统包括:
条款输入模块31,用于将相比较的两个条款文本分别转化为矩阵,作为利用实施例3的矛盾语句识别系统构建的矛盾语句识别模型的输入;
概率输出模块32,用于经过所述模型的计算,得到相比较的两个条款文本相矛盾的概率。
当然在将相比较的两个条款文本分别转化为矩阵之前,所述条款输入模块可以参考实施例3的所述模型输入模块22对相比较的两个条款文本进行预处理。
本实施例的条款逻辑鉴别系统可以应用于旅游产品相关条款逻辑关系的智能鉴别,比如预订限制、预订说明、产品说明等部分包含的条款内容,目的是保证公司旅游产品相关条款的合理性与逻辑性,进而做到充分保障消费者的权益,为客户提供最满意的服务。当然本实施例并不局限于此,所述条款逻辑鉴别系统同样还可以应用于其他服务类产品或实体产品,甚至是某些制度、规则条款等场景,以达到减少人工核查的人力成本,提高鉴别的准确性的效果,对于存在矛盾的条款可以有针对性的修订和完善。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!