一种基于智能感知的跨域计算任务调度方法及系统与流程
本发明属于任务调度领域,具体涉及集群级任务调度场景,特别是一种面向跨域计算环境的计算任务调度技术。
背景技术:
跨域计算环境由多个互相隔离的域组成,每个域包含一个或多个完整的存储和计算集群,可独立执行具体的计算任务。参与计算的主要数据所在的域称为数据域。在跨域计算环境中,总是将计算任务提交到数据域执行并不是最优的调度策略。当数据域剩余资源不足时,任务将进入等待队列,导致任务启动时间不可控。当数据域剩余资源紧张时,任务计算性能将受到影响,导致任务执行时间变长。将计算任务提交至其它低负载域时,过高的数据跨域迁移成本同样会导致任务启动时间大幅推迟。因此,需要一种全局性的任务调度技术,在综合考虑各域资源情况和数据迁移成本等影响因素的基础上,智能判定任务的最优执行域。
域能够执行具体的计算任务必须满足两个前提:1)该域必须满足计算任务对cpu和内存等资源的需求;2)该域必须存储参与计算的数据,必要时需要将数据从其他域迁移至本域。迁移数据的大小直接影响跨域迁移时间的长短,文件数据可通过汇总每个分片文件的大小得到其数据量,数据库数据可通过计算数据表宽度和记录数的乘积估算出其数据量。
技术实现要素:
本发明的目的是解决了跨域计算环境下各个域的资源利用率不均衡,以及域内资源不足导致任务执行失败或执行时间过长的问题,为实现在维持每个域的资源使用率相对均衡的基础上缩短计算任务的整体执行时间的调度目标,提出一种基于智能感知的跨域计算任务调度方法及系统,用于决定具体计算任务的最优执行域。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于智能感知的跨域计算任务调度方法,包括:
步骤1、基于标签数据训练决策树模型;
步骤2、基于相对时间复杂度估算计算任务的执行时间;
步骤3、基于资源历史记录和arima算法预测各域的资源变化趋势指标;
步骤4、使用资源状态接口获取各个域的资源实时状态指标;
步骤5、基于可用带宽估算数据迁移到各个域的迁移时间;
步骤6、基于决策树模型和综合指标决策任务最优执行域。
进一步的,步骤1所述决策树模型通过决策树算法训练得出,步骤如下:
1.1、构建初始标签数据,并划分为训练集和测试集;
1.2、将训练集输入到决策树训练算法中并设置训练参数,得出决策树模型;
1.3、将决策树模型和测试集输入到决策树评估算法中,得出决策树模型评估指标;1.4、当决策树模型评估指标不满足要求时:
a)调整训练参数,重复步骤1.2和1.3,直到指标满足要求为止;或者,
b)调整标签规则,重复步骤1.1、1.2和1.3,直到指标满足要求为止。
进一步的,步骤2所述估算方法包括:
2.1、选取一种基准算法,并拟合出该基准算法的时间复杂度曲线;
2.2、根据待估算任务相对于基准算法的时间复杂度,计算出任务预计执行时间t。
进一步的,步骤3所述算法具体包括:
3.1获取本域过去一段时间的资源历史数据;
3.2使用arima算法计算本域未来一段时间的资源预测数据;
3.3获取当前时刻t0和当前任务的预计执行时间t;
3.4从资源预测数据中截取[t0,t0+t]区间的数据,计算变化趋势指标;
3.5每个域重复3.1~3.4步骤,各自计算出本域的变化趋势指标。
进一步的,步骤4所述资源实时状态指标具体包括以下5个指标:
4.1集群cpu空闲率,用于描述集群cpu的总体使用情况;
4.2集群cpu核心总数,用于描述集群cpu的核心总体数量;
4.3集群剩余内存,用于描述集群各节点的内存剩余空间大小的总和;
4.4集群磁盘剩余空间,用于描述集群各节点的磁盘剩余空间大小的总和;
4.5跨域网络可用带宽,用于描述两个集群之间的网络带宽的使用情况。
本发明的另一方面,还提出了一种基于智能感知的跨域计算任务调度系统,包括:
模型训练模块,基于标签数据训练决策树模型;
任务执行时间评估器,基于相对时间复杂度估算计算任务的执行时间;
资源变化趋势预测器,基于资源历史记录和arima算法预测各域的资源变化趋势指标;
资源实时指标采集器,使用资源状态接口获取各个域的资源实时状态指标;
数据迁移时间评估器,基于可用带宽估算数据迁移到各个域的迁移时间;
任务最优执行域决策器,基于决策树模型和综合指标决策任务最优执行域。
进一步的,模型训练模块包括:
初始数据单元,用于构建初始标签数据,并划分为训练集和测试集;
模型单元,用于将训练集输入到决策树训练算法中并设置训练参数,得出决策树模型;
指标单元,用于将决策树模型和测试集输入到决策树评估算法中,得出决策树模型评估指标;
调整单元,用于当决策树模型评估指标不满足要求时调整训练参数,重复使用模型单元和指标单元,直到指标满足要求为止;或者,调整标签规则,重复使用初始数据单元、模型单元和指标单元,直到指标满足要求为止。
进一步的,任务执行时间评估器包括:
拟合单元,选取一种基准算法,并拟合出该基准算法的时间复杂度曲线;
计算单元,根据待估算任务相对于基准算法的时间复杂度,计算出任务预计执行时间t。
进一步的,资源变化趋势预测器具体包括:
数据获取单元,获取本域过去一段时间的资源历史数据;
数据计算单元,使用arima算法计算本域未来一段时间的资源预测数据;
时间获取单元,获取当前时刻t0和当前任务的预计执行时间t;
指标计算单元,从资源预测数据中截取[t0,t0+t]区间的数据,计算变化趋势指标;
每个域使用上述单元,各自计算出本域的变化趋势指标。
进一步的,资源实时指标采集器包括:
集群cpu空闲率单元,用于描述集群cpu的总体使用情况;
集群cpu核心总数单元,用于描述集群cpu的核心总体数量;
集群剩余内存单元,用于描述集群各节点的内存剩余空间大小的总和;
集群磁盘剩余空间单元,用于描述集群各节点的磁盘剩余空间大小的总和;
跨域网络可用带宽单元,用于描述两个集群之间的网络带宽的使用情况。
与现有技术相比,本发明的创新性体现在:
1)创造性地将趋势预测算法和决策树算法综合应用于跨域计算任务调度场景,避免了任务资源抢占现象,解决了调度决策正确率低的问题;
2)通过流式机器学习技术,克服了趋势预测算法和决策树算法的性能问题,大幅缩短了跨域计算任务调度整体时间。
本发明的价值体现在:1)满足计算任务运行的资源需求,确保每个任务在运行时有足够的资源;2)避免计算任务之间可能发生的资源抢占现象;3)将计算任务调度到离主要数据最近的地方执行;4)提升资源利用率,平衡各个域之间的负载情况;5)满足业务应用透明使用跨域资源的需求。
本发明可避免计算任务之间可能发生的资源抢占现象。通过引入arima算法,使得预测各个域的资源变化趋势成为可能,从而可以避免当前任务和周期性任务发生资源抢占现象。arima对过去时期的指标值进行加权平均得到当前的指标值,当过去时期指标呈现周期性时,当前时期指标也会出现相似性质。arima算法根据各个域的资源历史数据,预测出未来对应的变化趋势。历史数据的周期性越强,预测周期性任务的预计执行时段就越准确,避免资源抢占现象的概率就越高。
本发明可保证任务最优执行域初始决策正确率大于80%,并使之随着系统运行不断提高。通过引入决策树算法,解决了跨域计算这类复杂调度问题。为训练集打标签的过程,本质上是调整跨域迁移成本、各域的当前资源使用情况以及未来资源变化趋势这三方面指标的权重关系,其意义在于:可定制化初始标签训练集,从而定制化初始决策模型。定制化的初始决策模型最大程度上提升了初始决策正确率。随着调度算法不断执行,正负用例不断补充到训练集中,决策模型不断迭代,决策正确率也将不断提高。
本发明可提供高效的调度性能。通过引入流式机器学习技术,将arima算法和决策树算法改造为流式机器学习任务,实现了秒级响应,从而大幅提高了调度整体性能。
附图说明
图1是本发明实施例的步骤示意图;
图2是本发明实施例的资源预测曲线图;
图3是本发明实施例的调度执行过程示意图;
图4是本发明实施例的流式机器学习执行过程示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图对本发明的技术方案做进一步的详细说明:
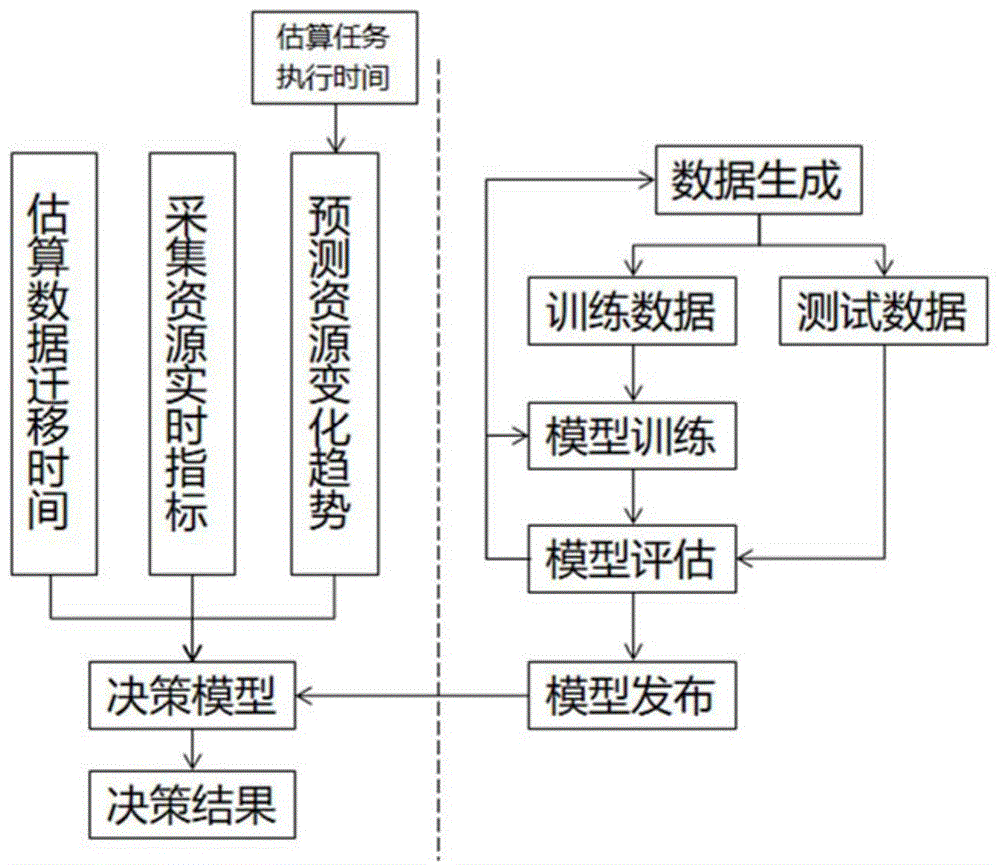
本发明在综合考虑数据跨域迁移成本、各域的当前资源使用情况以及未来资源变化趋势三方面因素基础上,实现了任务最优执行域的智能判定功能,主要包含以下步骤(如图1所示):
步骤1、基于标签数据训练决策树模型;
步骤2、基于相对时间复杂度估算计算任务的执行时间;
步骤3、基于资源历史记录和arima算法预测各域的资源变化趋势指标;
步骤4、使用资源状态接口获取各个域的资源实时状态指标;
步骤5、基于可用带宽估算数据迁移到各个域的迁移时间;
步骤6、基于决策树模型和综合指标决策任务最优执行域。
其中,步骤1独立于其它步骤,一旦通过步骤1生成了满足要求的决策树模型,步骤1就不再需要执行。此后,每次调度只执行步骤2至步骤6,便可获得任务最优执行域的唯一标识。
1、基于标签数据训练决策树模型
决策树模型用于为待决策数据产生正确标签,即任务最优执行域的唯一标识。决策树模型通过决策树算法训练得出,步骤如下:
1)构建初始标签数据,并划分为训练集和测试集;
2)将训练集输入到决策树训练算法中并设置训练参数,得出决策树模型;
3)将决策树模型和测试集输入到决策树评估算法中,得出决策树模型评估指标;
4)当决策树模型评估指标不满足要求时:
a)调整训练参数,重复步骤2和3,直到指标满足要求为止。或者,
b)调整标签规则,重复步骤1、2和3,直到指标满足要求为止。
标签数据包含标签和特征两个部分,标签代表任务最优执行域的唯一标识,特征代表影响决策结果的各项因素,包括数据跨域迁移成本、各域的当前资源使用情况以及未来资源变化趋势三方面因素。标签数据的结构如下所示:
(d,f)
其中,d代表标签,f代表特征并可以进一步表示为:
(cd0,rd0,md0),…,(cdi,rdi,mdi),…,(cdn,rdn,mdn)
其中,c代表资源变化趋势指标,r代表资源实时状态指标,m代表数据跨域迁移时间。di代表第i域,i∈[0,n],d0代表数据域。因此,cd0代表数据域的资源变化趋势指标,rd0数据域的资源实时状态指标,md0代表数据迁移到数据域的时间且md0=0。类似地,cdi代表第i域的资源变化趋势指标,rdi代表第i域的资源实时状态指标,mdi代表数据迁移到第i域的时间。
包含n条数据的初始标签数据集合可以表示为:
(di,fi)|i∈[0,n]
随机抽取出其中的0.7n条数据作为训练集,剩余的0.3n条数据作为测试集。
训练好的决策树模型f用于根据特征f计算任务最优执行域的唯一标识d,f表示如下:
d=f(f)
2、基于相对时间复杂度估算计算任务的执行时间
计算任务的执行时间很难直接计算出来,因此这里提出一种基于相对时间复杂度的间接估算方法。首先,选取一种基准算法,例如terasort,并拟合出该基准算法的时间复杂度曲线。然后,根据待估算任务相对于基准算法的时间复杂度,计算出任务预计执行时间t,计算公式如下:
t=c·s·log(s)·r+b
其中,s代表参与计算数据的大小,r代表任务的相对时间复杂度,c代表基准算法系数常量,b代表固定时间消耗常量。s和r作为变量由外部调用者传入。相对时间复杂度r可以通过在不同数据量抽样点下根据任务的执行时间与基准算法的执行时间的关系而确定。
3、基于资源历史记录和arima算法预测各域的资源变化趋势指标
如果资源历史曲线的变化呈现出明显的周期性,则表明该域存在周期性长任务。通过历史记录访问接口获取资源历史数据后,借助arima算法可预测出该域未来的资源变化曲线。当资源历史曲线呈现显著周期性变化时,资源预测曲线同样会呈现出相似的周期性,因此可以预测出未来周期性任务的执行时间段,从而避免当前任务和周期性任务发生资源抢占现象。历史数据的周期性越强,周期性任务的预计执行时段预测地就越准确,避免资源抢占现象发生的概率就越高。
具体算法如下:
1)获取本域过去一段时间(比如,过去一周)的资源历史数据;
2)使用arima算法计算本域未来一段时间(比如,未来一天)的资源预测数据;
3)获取当前时刻t0和当前任务的预计执行时间t;
4)从资源预测数据中截取[t0,t0+t]区间的数据,计算变化趋势指标;
5)每个域重复1~4步骤,各自计算出本域的变化趋势指标。
各个域的变化趋势指标汇总后成为本次待决策数据的一部分。假设某个域的资源预测曲线如图2所示,虽然该域当前剩余资源较为充足,但是考虑到未来t时间内资源会被周期性任务占用,因此该域可能不是当前任务的最优执行域。
4、使用资源状态接口获取各个域的资源实时状态指标
资源实时状态指标用于评估域的资源实时状态,各个域的资源实时状态指标汇总后成为本次待决策数据的一部分。资源实时状态指标具体包括以下5个指标:
1)集群cpu空闲率。用于描述集群cpu的总体使用情况;
2)集群cpu核心总数。用于描述集群cpu的核心总体数量;
3)集群剩余内存。用于描述集群各节点的内存剩余空间大小的总和;
4)集群磁盘剩余空间。用于描述集群各节点的磁盘剩余空间大小的总和;
5)跨域网络可用带宽。用于描述两个集群之间的网络带宽的使用情况。
5、基于可用带宽估算出数据迁移到各个域的迁移时间
两个域之间可用带宽不足,直接影响数据跨域迁移时间,从而影响任务最优执行域的最终决策结果。数据迁移到各个域的迁移时间汇总后成为本次待决策数据的一部分。数据跨域迁移时间m主要由数据在域间的传输时间和文件磁盘io时间构成。计算公式如下:
其中,s代表迁移数据的大小,n代表可用带宽,c代表网络性能波动常数,i代表分布式文件系统写性能常数,o代表分布式文件系统读性能常数。s和n作为变量由调用者传入。
6、基于决策树模型和综合指标决策任务最优执行域
在获取之前步骤的各项指标后,依据步骤1训练的决策树模型,决策出任务最优执行域的唯一标识。
待决策数据由各个域的资源变化趋势指标(步骤3)、各个域的资源实时状态指标(步骤4)和数据迁移到各个域的迁移时间(步骤5)组成。以域为单位对各项指标进行重组,最终形成特征f,即:
(cd0,rd0,md0),…,(cdi,rdi,mdi),…,(cdn,rdn,mdn)
然后根据决策树模型f计算任务最优执行域的唯一标识d,即:
d=f(f)。
本发明所述的系统由以下5个组件协作完成:
1)任务执行时间评估器:负责评估计算任务的执行时间;
2)数据迁移时间评估器:负责评估数据跨域迁移时间;
3)资源实时指标采集器:负责采集各个域的资源实时状态指标;
4)资源变化趋势预测器:负责快速预测各个域未来一段时间的资源变化趋势指标;
5)任务最优执行域决策器:负责快速决策计算任务的最优执行域。
调度执行过程如下(如图3所示):
1)调用任务执行时间评估器,输入数据量和相对时间复杂度,获取任务执行时间t;
2)调用各个域的资源变化趋势预测器,输入任务预计执行时间t,获得各个域在t时间内的资源变化趋势指标cdi;
3)调用各个域的资源实时指标采集器,获取各个域的资源实时指标rdi;
4)调用数据迁移时间评估器,输入各个域的资源实时指标rdi和数据量,获取数据迁移到各个域的迁移时间mdi;
5)调用任务最优执行域决策器,输入根据各个域的资源变化趋势指标cdi、各个域的资源实时指标rdi和数据迁移到各个域的迁移时间mdi整合后的待决策数据(cd0,rd0,md0),…,(cdi,rdi,mdi),…,(cdn,rdn,mdn),获得任务最优执行域的唯一标识d。
这里以一个具体的例子阐述本发明的具体实施方式。以两个域的环境(假设为a域和b域)为例,基于智能感知的跨域计算任务调度技术实施过程如下:
1)调用任务执行时间评估器,获取任务预计执行时间t;
2)调用a域的资源变化趋势预测器,获取a域在任务预计执行时间t内的资源变化趋势指标ca;
3)调用b域的资源变化趋势预测器,获取b域在任务预计执行时间t内的资源变化趋势指标cb;
4)调用a域的资源实时指标采集器,获取a域的资源实时状态指标ra;
5)调用b域的资源实时指标采集器,获取b域的资源实时状态指标rb;
6)调用数据迁移时间评估器,获取数据跨域迁移时间ma和mb;
7)汇总并重组所有指标,获得待决策数据(ca,ra,ma),(cb,rb,mb),然后输入最优执行域决策器,最终获得任务最优执行域唯一标识d。
其中,资源变化趋势预测器和任务最优执行域决策器都采用流式机器学习技术进行了性能优化,实现了秒级响应。无论是arima算法,还是决策树算法,作为离线计算任务执行的响应时间为分钟级别,严重影响调度整体性能。将arima算法和决策树算法改造为流式机器学习任务并在后台执行,不仅节省了算法的启动时间,而且实现了对单个请求的快速响应。
以下以任务最优执行域决策器为例,说明流式机器学习的执行过程(如图4所示):
1)任务最优执行域决策算法(流式机器学习任务)启动并加载决策树模型,然后进入挂起状态;
2)任务最优执行域决策接口接收调用者的请求并转发至请求队列;
3)任务最优执行域决策算法被激活,获取请求并依据决策树模型进行计算,并将结果发至响应队列,然后继续进入挂起状态;
4)任务最优执行域决策接口从响应队列获取决策结果并返回给调用者,完成本次决策过程,并不断重复执行步骤2至步骤4;
当发来结束命令时,任务最优执行域决策算法被唤醒,释放资源后结束流式机器学习任务。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!