基于自然标注的微博情绪分类方法与流程
本发明涉及自然语言处理、微博情绪分析技术领域,具体地说,是一种利用自然标注的微博情绪分析方法。
背景技术:
随着互联网技术与应用的火速发展,qq、微信、微博渐渐成为了人们进行社会交互的首要选择,网络用户群体变得更加庞大与复杂,网络社交渐渐变成人们日常生活中的一个重要部分。在这个互联网时代,因为网络有其特殊的便捷性和匿名性,故人们往往更愿意在网上吐露心声,用网络为载体发出自己声音,表达自己的情绪。
微博情绪的分类是在微博数据上做情绪分析的研究,涉及到社交媒体的数据处理、文本分类技术、文本情感分析等。一般微博情绪分类方法主要采用两种方式:一种是基于机器学习的方法,另一种是基于情绪知识规则库和情绪词典的方法。其中,基于机器学习方法的研究更受到关注。但是,用人工的方式收集足够多的训练数据集的代价是十分昂贵的,因此很难保证情绪分类器的效果。
技术实现要素:
本发明的目的在于提供一种基于自然标注的微博情绪分类方法。
实现本发明目的的技术解决方案为:一种基于自然标注的微博情绪分类方法,包括以下步骤:
步骤1,对微博文本数据进行预处理;
步骤2,依据微博文本,从种子词和表情符号两方面构建情绪对应表,并对微博文本进行情绪的自然标注;
步骤3,构建基于自然标注的朴素贝叶斯模型,将标注好的微博文本进行向量表示之后送入朴素贝叶斯模型进行分类。
本发明与现有技术相比,其显著优点:本发明和现有的人工标注构建微博情绪语料库的方式相比,能够得到更多训练数据集并节省大量的人工耗费,更好的对微博情绪文本进行分类,自然标注的方法可以大大减少人工标注带来的开销。
附图说明
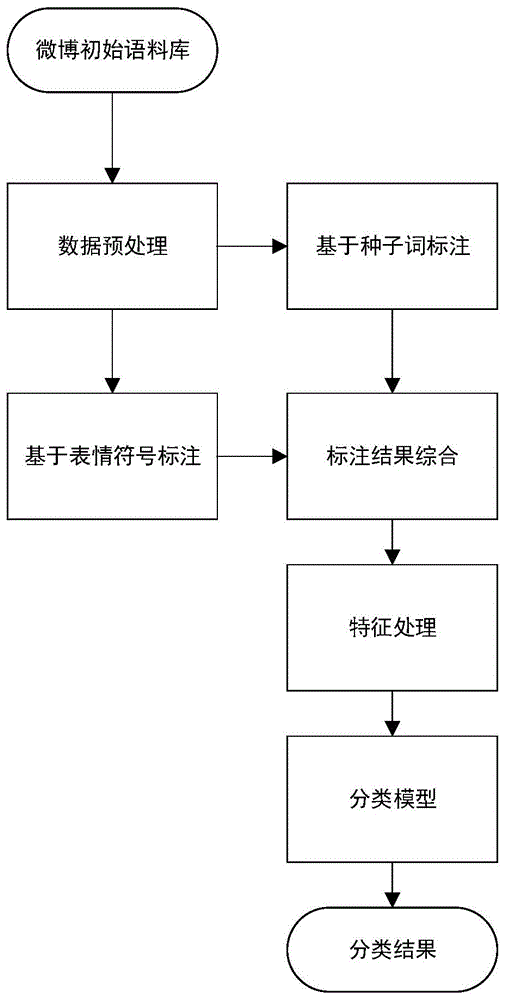
图1为微博情绪分类方法流程图。
图2为微博数据预处理流程图。
具体实施方式
本发明一种基于自然标注的微博情绪分类方法,包括以下步骤:
步骤1的微博数据预处理方法,预处理整体流程如图2所示,具体为:
a)对微博语料库进行过滤工作,去除重复和转发的微博。
b)删除微博文本中含有的url和话题性标签内容。
c)对于中文文本,先进行分词,可以采用现有的开源工具。
d)中文分词之后去除停用词,停用词指去除之后对可使用网络开源的词表资源。
e)抽取出微博中带表情符号的微博文本。
步骤2的微博情绪的自然标注,具体为:
a)构建七类种子词情绪类别表。
b)构建七类表情符号情绪类别表。
c)对预处理后的微博文本进行基于种子词的情绪标注。
如果用weibo表示微博语料库,sentance表示一条微博语料库文本,labelseedword表示此条微博的种子词标注,emword表示种子词。由上述规则可以得到如下算法:
d)对预处理后的微博文本进行基于表情符号的情绪标注。
如果用weibo表示微博语料库,sentance表示一条微博语料库文本,labelemticon表示此条微博的表情符号标注,emcons表示表情符号。可以得到如下算法:
e)对种子词和表情符号两种标注进行一个综合性的情绪标注,得到单一情绪标注的微博语料库。
如果用labelseedword表示此条微博的种子词标注,labelemticon表示此条微博的表情符号的标注,labelcom表示此条微博的综合的标注,则由上述规则可得到如下算法:
步骤3的利用基于自然标注的微博语料库,来构建一个朴素贝叶斯模型模型,具体为:
a)对微博语料库数据进行特征处理。
b)将特征处理后的矩阵送入朴素贝叶斯模型进行情绪分类。
下面结合说明书附图与实施例对本发明作进一步说明。
基于自然标注的微博情绪分类方法,用于对微博情绪进行分类。主要分为三个阶段,如图1所示。
本发明所采用的具体实施步骤如下:
1)200万条原始微博数据的预处理方法,预处理整体流程如图2所示,具体为:
a)对微博语料库进行过滤工作,去除重复和转发的微博。
b)删除微博文本中含有的url和话题性标签内容。
c)对于中文文本,先进行分词,可以采用现有的开源工具。
d)中文分词之后去除停用词,停用词指去除之后对可使用网络开源的词表资源。
e)抽取出微博中带表情符号的微博文本。
2)微博情绪的自然标注,具体为:
a)针对微博数据,构建一个包含27466个常用词汇的种子词的微博情绪类别表。如表1所示:
表1种子词情绪类别表
b)针对微博数据构建微博表情符号情感类别表,如表2所示:
表2表情符号情绪类别表
c)对微博数据进行基于种子词的标注,如果用weibo表示微博语料库,sentance表示一条微博语料库文本,labelseedword表示此条微博的种子词标注,emword表示种子词。由上述规则可以得到如下算法:
d)对微博数据如果用weibo表示微博语料库,sentance表示一条微博语料库文本,labelemticon表示此条微博的表情符号标注,emcons表示表情符号。可以得到如下算法:
e)如果用labelseedword表示此条微博的种子词标注,labelemticon表示此条微博的表情符号的标注,labelcom表示此条微博的综合的标注,则由上述规则可得到如下算法:
其中,muti-emotion指的是多类情绪的情况,该算法的最终是得到单一情绪的标注,因此有多种情绪的文本得标记出来,并排除掉。
最终构建了一个规模为83303条的自然标注的微博语料库,其情绪标注类别为七类,分别是:happiness(幸福)、like(喜欢)、surprise(惊讶)、fear(焦虑)、sadness(哀伤)、anger(愤怒)和disgust(厌恶)。具体如表3所示:
表3.6基于自然标注微博语料库
3)利用之前构建的规模为83303条的自然标注的微博语料库,来构建的朴素贝叶斯模型模型,具体为:
a)对微博语料库数据进行特征处理。具体为:
使用词袋模型对标注好的微博语料库进行特征提取,词袋模型为bagofwords,简称bow。词袋模型不考虑文本中词语的出现顺序,也不考虑词语和前后词语之间的连接,仅仅只考虑所有词的权重,每个词都被当作一个独立的特征来看待。而权重则与词在文本中出现的频率有关。
在对测试数据分词并向量化后,使用tf-idf算法进行预处理,得到文本中各个词的tf-idf权重值。tf-idf是termfrequency-inversedocumentfrequency的缩写,即“词频-逆文本频率”。是一种词的权重计算的重要方法之一。它由两部分组成,tf和idf,tf为词频,idf为逆文档频率,其反映了一个词在所以文本中出现的频率。其计算公式如下:
tf-idf(x)=tf(x)×idf(x),(4.2)其中,n代表微博语料库中文本的总数,n(x)代表语料库中包含词x的文本总数。tf(x)为词x在当前文本中的词频。
b)将特征处理后的矩阵送入朴素贝叶斯模型进行情绪分类。具体为:
x为一个特征向量,将其维度设为n。由朴素假设,其特征条件独立,于是得:
分别估计出特征xi在每个类别ck上的条件概率就可以了。类别y的先验概率p(y=ck)可以通过训练集计算出,同样通过训练集上的统计,可以得出对应每一类上的,条件独立的特征对应的条件概率向量。
学习(参数估计):训练集={(x1,y1),(x2,y2),(x3,y3),…,(xm,ym)}包含条训练数据,xi是n维向量,yi∈{c1,c2,...ck}属于k类的一类则有(i(y)为指示函数):
设n维特征的第j维有l个取值,则某维特征的某个取值ajl,在给定某分类ck下的条件概率为:
分类:分类通过学习步骤得到的概率,对于给定的未知类别实例a,就可以依据上述概率计算,得到实例a属于各类别的后验概率p(y=ck|a),进而得到所属类别。
则类别y为分类器预测都得到的类别。
综上所述,相较于传统的人工的方式构建微博情绪语料库,本发明利用微博中的种子词和表情符号两个特征,建立一种自然标注微博情绪的规则,构建一个自然标注的微博语料库;将标注好的微博语料库送入基于机器学习方法的模型中,最终达到情绪分类目的。
- 还没有人留言评论。精彩留言会获得点赞!