一种基于人工智能语义分析的任务发布方法与流程
本发明涉及人工智能语义分析领域和办公自动化领域,尤其涉及一种基于人工智能语义分析的任务发布方法。
背景技术:
计算机作为信息科学的核心和载体,在越来越多的工作中扮演重要角色,很多企业基于工作流用现代化设备改变了传统低效的手工办公方式,但是,目前对于任务的发布等过程并没有一个智能化的解决方案,还是依赖于人员手动操作和输入,是一种低效的方式,对于工作效率的提升是不利的。
人工智能语义分析的发展为这一问题提供了解决方案,利用语义分析技术分析任务的内容,从而代替人来完成任务发布的过程,让人员更多关注的是任务本身和相互的沟通,而不是软件的使用。
技术实现要素:
本发明提供了一种基于人工智能语义分析的任务发布方法,为现有技术的不足提供智能化的解决方案。
本发明提供了如下技术方案:一种基于人工智能语义分析的任务发布方法,包括以下步骤:
(1)任务发布设置,包括任务发布者的权限级别和任务类别;
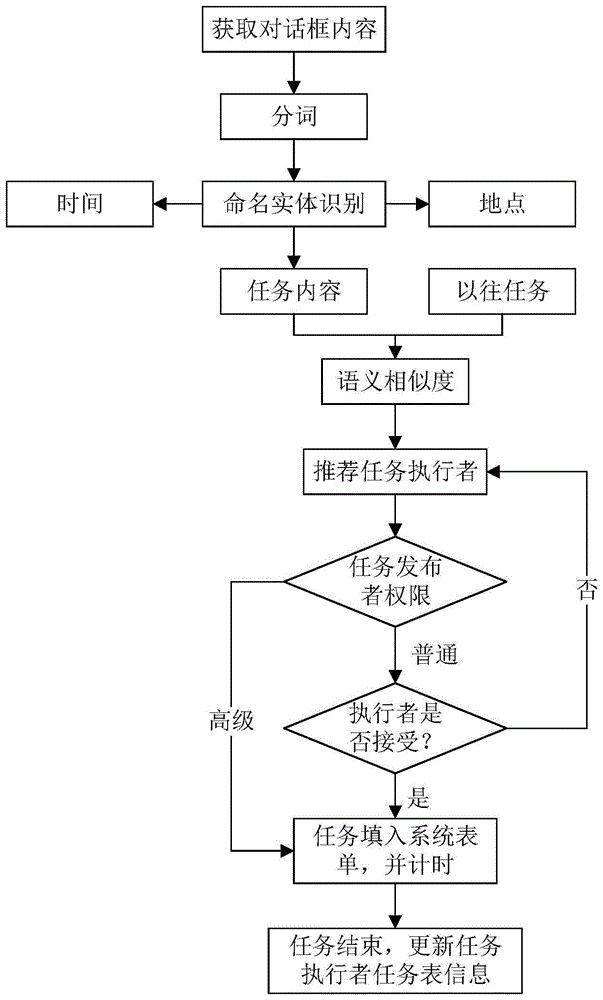
(2)任务内容处理:获取对话框中的聊天信息或任务框内容后,利用jieba分词工具结合构造词典进行分词,然后利用长短期记忆网络lstm结合注意力机制进行命名实体识别,从而获得任务执行者、时间、地点、任务主要内容等信息;
(3)推荐任务执行者:采用卷积神经网络、长短期记忆网络以及注意力机制相结合的方式,获取对话框中的聊天信息或任务框内容和各人员历史任务记录的相似度,从而实现任务执行者的推荐;其中,利用卷积神经网络获取局部信息,多方角度分析语句;利用长短期记忆网络过滤不重要信息,保留主要全局信息;利用注意力机制给需要关注的词赋予高权重,强调特定词对整个句子的重要性;所述历史任务记录包含:任务内容、任务时间安排、完成任务用时等;
(4)任务执行者查看内容并给予反馈,如果接受,则进入任务发布相应的任务程序,将任务信息填入任务表单;否则重新从推荐的任务执行者中挑选最合适的任务执行者;
(5)任务执行者提交任务后,进行任务执行者执行过的任务名称和执行时间等信息的更新,以作为之后任务发布时人员选择的参考因素。
进一步地,步骤(1)中,任务发布设置,包括任务发布者的权限级别和任务类别的定义,包括:
(1-1)任务发布者的权限级别分为高级和普通两种,高级发布者发布的任务不可拒绝,普通发布者发布的任务可拒绝;
(1-2)任务类别分为预存任务、临时任务和审批等,预存任务不可拒绝,临时任务和审批可拒绝。
进一步地,步骤(2)包括以下子步骤:
(2-1)对话框中的聊天信息或任务框内容进行语义分析,首先是分词,采用jieba分词算法,根据实际需求构造相应词典,记录领域中常用的组合词,得到专用于该领域的分词词典;同时,利用停用词表剔除无用词;
(2-2)分词之后进行命名实体识别,从而获取到任务执行者的名字、地点以及时间等信息,利用长短期记忆网络lstm结合注意力机制的方法实现;包括:
(2-2a)利用cbow和skip-gram算法训练得到的一个工具word2vec获取每一个词对应的向量,从而获得由若干单词组成的文本的向量化数值矩阵;
(2-2b)将矩阵输入到双向长短期记忆网络中,网络由三层神经网络构成,两个递归神经网络和一个全连接层,两个递归神经网络中,第一个从前向后计算向量,第二个从后向前计算向量。然后利用全连接层对结果进行集成,实现局部特征提取;
(2-2c)将双向长短期记忆网络终第一个递归神经网络的结果和数值矩阵一起输入到注意力机制中,注意力机制是每个输入的注意力值的概率分布,对需要关注的词赋予高权重,强调特定词对整个句子的重要性,并考虑更多的上下文信息;
(2-2d)将(2-2b)和(2-2c)所得结果相乘,使用softmax函数对命名实体识别的向量类型进行分类,从而得到结果。
进一步地,步骤(3)中,计算出对话框聊天信息或任务框内容和各人员历史任务记录的相似度后,按照相似度由大到小排序,推荐得到若干任务执行者,计算相似度包括如下步骤
(3-1a)利用word2vec得到对话框聊天信息或任务框内容中每个词的对应向量,从而获得任务的向量化数值矩阵n*k,n为词数,k为词向量维度;
(3-1b)利用卷积神经网络对(3-1a)得到的向量矩阵进行处理,卷积神经网络只有一个卷积层,用n个卷积滤波器得到n个长度为(n-k+1)的向量,组成大小为n*(n-k+1)的矩阵;
(3-1c)将(3-1a)和(3-1b)得到的矩阵分别输入到由一层递归神经网络组成的长短期记忆网络和注意力机制中,得到任务的最终表示向量;
(3-1d)对各人员的历史记录分别进行(3-1a)-(3-1c)的操作,得到各人员历史记录的表示向量;
(3-1e)利用曼哈顿距离分别计算(3-1c)和(3-1d)的各人员历史记录的相似度,曼哈顿距离为:
d=exp(-||a-b||
进一步地,步骤(4)包括:
(4-1)对于普通任务发布者,任务执行者会反馈其是否接受任务,如果接受,则直接在系统中推荐发布相应的任务;如果不接受,则重新从任务推荐者中挑选最合适的任务执行者;
(4-2)对于高级任务发布者,任务执行者不可拒绝,系统自动执行推荐发布任务程序。
(4-3)任务执行者接受任务后会收到系统工作任务提示表单,内容包含执行者、时间、任务内容,并纳入任务执行者任务库中,当任务时间到达,对任务执行者进行自动消息推送。
进一步地,步骤(5)中如果新发布的任务中存在与某人员的历史已执行任务中相似的任务,那类似新任务应推荐该任务执行人执行;
进一步地,如果任务类别为审批,只需要通过步骤(3)计算新的审批和数据库中审批的相似度,以确定该审批交由谁来处理后发送,审批人员审批之后将给任务发送者回复审批是否通过。
本发明的有益效果是:本发明利用人工智能语义分析,实现了智能化分析人员之间的聊天内容,识别如时间、人名、任务等信息,自动推荐、启动系统内部相关工作程序,从而提升工作、沟通效率。
附图说明
图1为人工智能语义分析的任务发布方法工作流程示意图;
图2为注意力机制工作流程示意图;
图3为进行语句相似度计算的卷积神经网络结合长短期记忆网络结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
本发明提供的一种基于人工智能语义分析的任务发布方法,如图1所示,包括以下步骤:
(1)任务发布设置,包括任务发布者的权限级别和任务类别;
(2)任务内容处理:获取对话框中的聊天信息或任务框内容后,利用jieba分词工具结合构造词典进行分词,然后利用长短期记忆网络lstm结合注意力机制进行命名实体识别,从而获得任务执行者、时间、地点、任务主要内容等信息;
(3)推荐任务执行者:采用卷积神经网络、长短期记忆网络以及注意力机制相结合的方式,获取对话框中的聊天信息或任务框内容和各人员历史任务记录的相似度,从而实现任务执行者的推荐;其中,利用卷积神经网络获取局部信息,多方角度分析语句;利用长短期记忆网络过滤不重要信息,保留主要全局信息;利用注意力机制给需要关注的词赋予高权重,强调特定词对整个句子的重要性;所述历史任务记录包含:任务内容、任务时间安排、完成任务用时等;
(4)任务执行者查看内容并给予反馈,如果接受,则进入任务发布相应的任务程序,将任务信息填入任务表单;否则重新从推荐的任务执行者中挑选最合适的任务执行者;
(5)任务执行者提交任务后,进行任务执行者执行过的任务名称和执行时间等信息的更新,以作为之后任务发布时人员选择的参考因素。
进一步地,所述步骤1中,任务发布设置,包括:
(1-1)任务发布者的权限级别分为高级和普通两种,高级发布者发布的任务不可拒绝,普通发布者发布的任务可拒绝;
(1-2)任务类别分为预存任务、临时任务和审批等,预存任务不可拒绝,临时任务和审批可拒绝。
步骤(2)中包括:
(2-1)对话框中的聊天信息或任务框内容进行语义分析,首先是分词,采用jieba分词算法,根据实际需求构造相应词典,记录领域中常用的组合词,得到专用于该领域的分词词典;同时,加入停用词表对常用的一些语气助词等对识别无用且干扰较大的词汇去除;
(2-2)分词之后进行命名实体识别,从而获取到任务执行者的名字、地点以及时间等信息,利用长短期记忆网络lstm结合注意力机制的方法实现,首先使用word2vec对文本进行向量化,将向量化的数值矩阵分别输入到双向lstm模型和注意力机制中进行计算,然后把两个结果相乘后,再使用softmax对命名实体识别的向量类型进行分类;包括:
(2-2a)利用cbow和skip-gram算法训练得到的一个工具word2vec获取每一个词对应的向量,从而获得由若干单词组成的文本的向量化数值矩阵;
(2-2b)将矩阵输入到双向长短期记忆网络中,网络由三层神经网络构成,两个长短期记忆网络和一个全连接层,两个长短期记忆网络中,第一个从前向后计算向量,第二个从后向前计算向量。然后利用全连接层对结果进行集成,实现局部特征提取;
具体地,长短期记忆网络的整体结构由三个单元组成,每一单元中包含输入门、遗忘门和输出门,网络的输入是x,输出是h,对于每一单元均有其输入和输出,计算公式如下,涉及到的参数wi,wc,wf,wo,ui,uc,uf,uo都是权重矩阵,bi,bc,bf,bo是偏置向量。
遗忘门计算公式为:
ft=σ(wfxt+ufht-1+bf)
完成的是从过去得到的信息中应该丢弃哪些无用信息,其输入为xt,并结合上一单元的输出ht-1,通过sigmoid函数σ后,输出0到1之间的一个数值作为单元状态ct-1,表示是否保留信息,1表示完全保留,0表示完全丢弃。
输入门计算公式为:
it=σ(wixt+uiht-1+bi)
决定哪些信息加入到本单元中,第一个公式表示的是需要更新的信息,第二个公式用tanh生成向量,是备选的需要更新的信息,将这两部分联合起来就是对单元的更新,公式如下:
ft*ct-1表示丢弃需要丢弃的信息,再加上新更新的信息
输出门计算公式为:
ot=σ(woxt+uoht-1+bo)
ht=ot*tanh(ct)
首先用sigmoid函数确定输出的部分,然后通过tanh函数处理单元状态,得到-1到1的一个值,与前者相乘得到最终输出。
(2-2c)将双向长短期记忆网络中第一个递归神经网络的结果和数值矩阵一起输入到注意力机制中,注意力机制是每个输入的注意力值的概率分布,对需要关注的词赋予高权重,强调特定词对整个句子的重要性,并考虑更多的上下文信息;
具体地,注意力是用在模型中的一种机制,其本身并不是模型,工作的步骤如图2,计算句中每个词和结果词的相似度,相似度高的权重高,然后将各个词得到的结果归一化,并分别乘以每个词的值,得到最终的注意力值。其含义可类比于人在观察时,并不是一次观察到整体,而是会注意到某个特定的部分,比如让孩子看画中的一条狗,如果下一次公园再次见到狗,他会特别注意狗这一特定的物体。在语义分析中,注意力相当于一种相似性度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大。
用在长短期记忆网络中,就是通过保留lstm对输入序列的中间结果,训练一个模型来对这些输入进行选择性的学习,并且在模型输出时将输出序列与输入进行关联,与输入类似的权重较大。
(2-2d)将(2-2b)和(2-2c)所得结果相乘,使用softmax函数对命名实体识别的向量类型进行分类,从而得到实体类别。
步骤(3)中,计算出对话框聊天信息或任务框内容和各人员历史任务记录的相似度后,按照相似度由大到小排序,推荐得到若干任务执行者,语句相似度的计算方法包括如下步骤:
(3-1a)利用word2vec得到对话框聊天信息或任务框内容中每个词的对应向量,从而获得任务的向量化数值矩阵n*k,n为词数,k为词向量维度;
(3-1b)利用卷积神经网络对(3-1a)得到的向量矩阵进行处理,卷积神经网络只有一个卷积层,用n个卷积滤波器得到n个长度为(n-k+1)的向量,组成大小为n*(n-k+1)的矩阵;
(3-1c)将(3-1a)和(3-1b)得到的矩阵分别输入到由一层递归神经网络组成的长短期记忆网络和注意力机制中,得到任务的最终表示向量;
(3-1d)对各人员的历史记录分别进行(3-1a)-(3-1c)的操作,得到各人员历史记录的表示向量;
(3-1e)利用曼哈顿距离分别计算(3-1c)和(3-1d)的各人员历史记录的相似度,曼哈顿距离为:
d=exp(-||a-b||
步骤(4)中,任务执行者查看内容并给予反馈,如果接受,则进入任务发布相应的任务程序;否则重新从任务推荐者中挑选,包括:
(4-1)对于普通任务发布者,任务执行者会反馈其是否接受任务,如果接受,则直接在系统中推荐发布相应的任务程序;如果不接受,则重新从任务推荐者中挑选;
(4-2)对于高级任务发布者,任务执行者不可拒绝,系统自动执行推荐发布任务程序。
(4-3)任务执行者接受任务后会收到系统工作任务提示表单,内容包含执行者、时间、任务内容,并纳入任务执行者任务库中,当任务时间到达,对任务执行者进行自动消息推送。
优选的,步骤(5)中,如果新发布的任务中存在与某人员的历史已执行任务中相似的任务,那类似新任务应推荐该任务执行人执行。
优选的,如果任务类别为审批,只需要通过步骤(3)计算新的审批和数据库中审批的相似度,以确定该审批交由谁来处理后发送,审批人员审批之后将给任务发送者回复审批是否通过。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!