数据打标方法、计算机装置及计算机可读存储介质与流程
本发明涉及数据处理领域,尤其涉及一种数据打标方法、计算机装置及计算机可读存储介质。
背景技术:
近年来,大数据、神经网络技术迅速发展,基于大数据与神经网络的深度学习也迅速应用于很多领域。由于神经网络技术对图像数据有强大的特征提取能力,将深度学习用于人脸识别迅速成为热点研究方向,而且随着大数据的深度学习,可持续优化与提升人脸识别的能力。显而易见,数据是人脸识别深度学习的重要基础。
然而,在现有技术中,存在人脸识别算法的准确率较低、鲁棒性较低、以及漏检率较高的问题。
技术实现要素:
为了解决以上的技术问题,本发明实施例一方面提供了一种数据打标方法,所述数据打标方法包括:
获取包含多个人物的视频;
对所述包含多个人物的视频进行切图处理,以得到每个人物的预设数量的头部或脸部图片;
将每个人物的预设数量的头部或脸部图片中具有预设佩戴物、预设光线特征、预设天气特征中的至少一者的头部或脸部图片筛选出来,并对筛选出的一个或者多个头部或脸部图片进行打标签操作。
进一步地,在所述数据打标方法中,所述预设佩戴物包括眼镜、墨镜或者帽子,所述预设光线特征包括强光特征或者弱光特征,所述预设天气特征包括下雨的天气或者下雪的天气。
进一步地,所述数据打标方法还包括:
将每个人物的预设数量的头部或脸部图片中具有预设佩戴物并且所述预设佩戴物遮挡住头部或脸部的比例大于或等于30%的任何头部或脸部图片删除;
将多个人物的所有头部或脸部图片中重复的任何头部或脸部图片删除;以及
将多个人物的所有头部或脸部图片中具有打伞特征的任何头部或脸部图片删除中的至少一者。
进一步地,在所述数据打标方法中,所述将每个人物的预设数量的头部或脸部图片中具有预设佩戴物、预设光线特征、预设天气特征中的至少一者的头部或脸部图片筛选出来的步骤包括:
将每个人物的预设数量的头部或脸部图片中具有带眼镜、带墨镜、带帽子、强光、弱光或者下雨天特征的头部或脸部图片筛选出来。
进一步地,所述数据打标方法还包括:
将每个人物的预设数量的头部或脸部图片保存到一个单独文件夹中。
进一步地,所述数据打标方法还包括:
将多个单独文件夹中的多个人物的所有头部或脸部图片进行去重处理,以将具有重复图片的任何一个单独文件夹删除。
进一步地,在所述数据打标方法中,每个人物的预设数量的脸部图片至少包括正脸图片和侧脸图片,所述侧脸图片是以正脸图片为参照的-30度至+30度范围内。
进一步地,在所述数据打标方法中,所述预设数量大于或等于6并且小于20;或者
所述预设数量等于6。
本发明实施例另一方面提供了一种计算机装置,所述计算机装置包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现上面描述的所述数据打标方法的步骤。
本发明实施例又一方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上面描述的所述数据打标方法的步骤。
本发明实施例提供了上述数据打标方法、计算机装置和计算机可读存储介质,所述数据打标方法能提升人脸识别算法的准确率、提高其鲁棒性、降低漏检率等。
附图说明
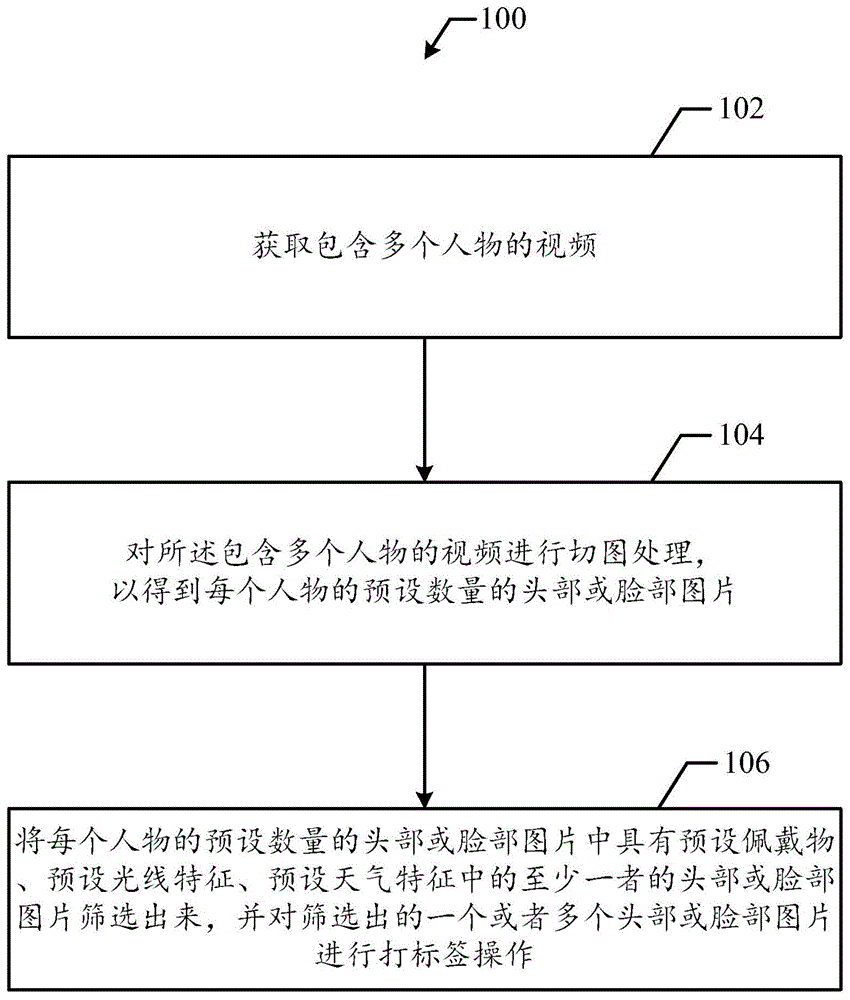
图1是根据本发明实施例的数据打标方法100的流程图。
图2是根据本发明实施例的图片删除方法200的流程图。
具体实施方式
为了更为合理的建立人脸识别算法训练数据库,本专利在长期的数据挖掘、数据标注经验基础之上,总结出了一种方法,对应的优势是从数据集上着手建立复杂场景下的数据子集,完善数据集以适应机器学习的特殊规律,从而能提升人脸识别算法的准确率、提高其鲁棒性、降低漏检率等。为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
图1是根据本发明实施例的数据打标方法100的流程图。数据打标方法100包括步骤102、104和106。
步骤102:获取包含多个人物的视频。
步骤104:对所述包含多个人物的视频进行切图处理,以得到每个人物的预设数量的头部或脸部图片。其中,脸部也可以理解成面部。
步骤106:将每个人物的预设数量的头部或脸部图片中具有预设佩戴物、预设光线特征、预设天气特征中的至少一者的头部或脸部图片筛选出来,并对筛选出的一个或者多个头部或脸部图片进行打标签操作。
其中,在一个非限定的例子中,每个人物的预设数量的头部或脸部图片的格式都为jpeg文件。
在本发明的一个实施例中,所述预设数量大于或等于6并且小于20。在本发明的一个具体实施例中,所述预设数量等于6。
在本发明的一个实施例中,所述预设佩戴物包括眼镜、帽子、围巾或者首饰等,所述预设光线特征包括强光特征或者弱光特征,所述预设天气特征包括下雨的天气、下雪的天气、晴天、多云或者阴天等。其中,首饰可以包括耳环、项链等。
在本发明的一个具体实施例中,步骤106中的将每个人物的预设数量的头部或脸部图片中具有预设佩戴物、预设光线特征、预设天气特征中的至少一者的头部或脸部图片筛选出来的步骤包括:将每个人物的预设数量的头部或脸部图片中具有带眼镜、带墨镜、带帽子、强光、弱光或者下雨天特征的头部或脸部图片筛选出来。
具体地,在本发明实施例中,每个人物的预设数量的脸部图片至少包括正脸图片和侧脸图片,所述侧脸图片是以正脸图片为参照的-30度至+30度范围内。
进一步地,所述数据打标方法100还包括:将每个人物的预设数量的头部或脸部图片保存到一个单独文件夹中。如此,由于在数据打标方法100中具有多个人物,因此最终可以分别得到多个人物的多个单独文件夹,每个单独文件夹具有对应人物的预设数量的头部或脸部图片。
进一步地,所述数据打标方法100还包括:将多个单独文件夹中的多个人物的所有头部或脸部图片进行去重处理,以将具有重复图片的任何一个单独文件夹删除。
在图1所示图片打标方法100的基础上,图2是本发明实施例的图片删除方法200的流程图。请参阅图2,所述图片删除方法200包括步骤202、步骤204和步骤206中的至少一者。
步骤202:针对多个人物,将每个人物的预设数量的头部或脸部图片中具有预设佩戴物并且所述预设佩戴物遮挡住头部或脸部的比例大于或等于30%的任何头部或脸部图片删除。
步骤204:将多个人物的所有头部或脸部图片中重复的任何头部或脸部图片删除。
步骤206:将多个人物的所有头部或脸部图片中具有打伞特征的任何头部或脸部图片删除。
进一步地,在本发明的一个实施例中,所述图片删除方法200还包括将每个人物的预设数量的头部或脸部图片中具有强光或弱光特征并且所述强光或弱光特征导致头部或脸部不可见的头部或脸部图片删除,和/或将每个人物的预设数量的头部或脸部图片中具有雨滴特征并且所述雨滴特征导致头部或脸部不可见的头部或脸部图片删除。
通过执行图片删除方法200的步骤202、步骤204和步骤206中的至少一者,可以保证图片数据的质量,从而保证数据打标操作的高质量。
本发明实施例提供了一种人脸识别算法训练数据库建立的方法,用于人脸识别算法/深度学习的训练数据生产/建立。该方法相比其他常见的方法,有较大的改进效果,首先从流程上借鉴了质量管理的先进经验,在过程中消除数据的质量隐患;其次,对数据进行有效的分类,以涵盖绝大数的应用场景,从而提升算法/深度学习的适应性;第三,结合了机器学习的认知规律,有针对性地建立数据集,弥补算法/深度学习的某些“短板”,提高人脸识别算法/深度学习的准确性、鲁棒性。
以下部分以一个具体的应用场景或举例对本发明的数据打标方法100进行说明。
在所述数据打标方法100中,涉及到一种人脸识别算法训练数据库建立的方法,包括如下步骤:
步骤1:数据获取。
步骤2:数据处理,涉及图像/图片的筛选以及数据标注。
步骤3:数据检查,一方面开展基本的质量检查,另一方面开展去重处理。
步骤4:成品归类,将成品分门别类存储,添加合适的数据标签。
其具体步骤为:
在数据获取阶段,利用脚本对获取的视频进行切图处理,生成一系列包含人脸的图片,同时也考虑到任务的复杂性和其他特殊目的,保留了人工切图这一环节,便于灵活处理各种需求。
数据处理阶段,为了保证图片的有效性,特意安排一个环节,对第一阶段生产的图片进行初步筛选。接着,针对图片开始数据的标注,这一个环节涉及较多的规则。
数据检查阶段,特意设计了一套质检规则,确保标注数据的质量。另外,还设计了去重的环节,利用脚本对标注的数据进行分析、去重,同时配备人力对去重进行监督和核查。
成品归类阶段,将经过检查的数据根据规则,形成不同的数据类,便于数据库的管理和查询。
在一个具体的应用实例中,图1所示数据打标方法100包括:
1.数据获取:数据集直接影响基于该数据集训练后的算法的性能,尤其是在人脸识别领域,数据集特性尤为重要。典型地,东方人的人脸特点与西方人的人脸特点不同,用基于西方人的人脸构建的数据集去训练算法如何能在识别东方人人脸的实际运用中获得好的“成绩”?针对摄像头下人脸识别的应用,获取对应条件下摄像头的视频,并基于这些视频,生产数据集,再用这些数据集去训练算法,那么算法的性能将显著提高。基于上述思想,有选择地获取视频来源,是关键性的第一步。
紧接着,将视频转换成图片,方法或途径有两种,第一种是计算机切图,即编写脚本,识别视频中有人脸后,进行自动切图。第二种是人工切图,即利用视频处理软件,手动对视频进行切图处理。第一种切图的具体规则如下,首先将视频分割成视频片段,每一个片段大约有10分钟,脚本自动将这10分钟的视频切图处理后放入同一个文件夹;其次,设置一个过滤规则,将具备以下任何一个特征的文件夹删除,第一个特征是文件夹内有50张以上的图片,第二个特征是文件夹内少于6张图片;最后,一个人一个文件夹,不同的人切完的图放入不同的文件夹。
计算机切图与人工切图相比,后者的灵活性、选择性更大,后者可根据不同的要求或需求灵活开展视频转换成图片的工作,便于弥补脚本切图的某些程序性盲点,例如脚本切图的原则是人脸检测,但特殊条件下的人脸检测并非是100%,有可能导致某些条件下的人脸在切图阶段就已经无法检测到,更无法被制作成数据集,也无法有效训练算法识别此类条件下的人脸。
2.数据处理:经过切图处理后的图片并非都是符合要求的图片,必须要在数据处理阶段进行图像初步筛选,对应的规则或要求如下:(1)每个人人脸采集必须大于6张小于20张;(2)一个人不能重复出现在两个文件夹下;(3)人脸采集中必须包含正脸、侧脸(6张中至少存在两张图片角度明显变化),其中侧脸是以正脸为参照±30°,侧脸角度是以脸部中心线为基础左右、上下偏转;(4)正脸,正对着摄像头角度无明显变化,五官清晰可见无马赛克,图片中的人脸必须在肩部以上;(5)尺寸要求:>60*60;(6)经常在对应摄像头下活动的人不能采集人脸,以免数据重复。
经过筛选的图片将进入打标/数据标注环节,标注时在文件夹中选择合理的图片,删除不合理的图片即可。实际上,此时的标注规则与前述的图像初步筛选规则一致,只是在标注时更加严格,必须每一条要求都满足,而且要将非同一个人的图片删除,还要删除同一个人重复的图片,保证最后的图片之间不重复。
接着,是难度逐渐提高的标注工作,按不同的实际场景,将数据集进行分类,分别建立以下数据子集,如带眼镜的人、带墨镜的人、带帽子的人、强光环境下的人、弱光环境下的人(夜晚)、下雨天的人,附带的要求是戴帽子的人要求不能遮挡人的脸部,除鸭舌帽、丝绒帽等紧贴头部帽子外,其他帽子直接忽略,必须满足>70%脸部表征要求,而打伞的人可直接忽略。标注之后的文件按两层目录保存,第一层批次号,第二层人脸对应的文件夹(即每一组脸对应一个文件夹)。
3.数据检查:数据质量是数据标注的核心之一,只有高质量的数据,才能训练出高质量的算法。质检时的标准其实就是数据处理阶段的各种要求,对出现质量问题的图片,一律按删除处理,若单独文件夹整体不满足规则,需将文件夹都删除,严格保证最后的质量,避免数据不良影响算法。
经过质量检查后的数据将进行人脸去重处理,其目的是剔除同一个人识别成其他人以及相似的人识别成一个人两种情况,首先用去重的脚本处理数据,将存在问题的数据找到,然后利用人工判别是否存在“重合”问题,最后对数据进行处理,删除“问题”数据。
4.成品归类:随着数据量的增加,数据库不断增容,尤其是考虑到后续数据库扩容至海量数据时,数据的更新、数据的查询、数据的管理将愈加复杂,因此,在建库初始,考虑未来的变化,对成品进行归类,基本要求是方便地更新任意字段的值,保证能不断给数据添加标签,还要方便字段的扩展,以应对数据种类增加对数据管理与查询便利性的要求。
同理,依据图1所示切图的不同途径,对于手工切图,最后形成的成品,也单独归类。
本发明实施例另一方面提供了一种计算机装置,所述计算机装置包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现上面描述的所述数据打标方法100的步骤。
本发明实施例又一方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上面描述的所述数据打标方法100的步骤。
综上所述,在长期的数据挖掘、数据标注经验基础之上,总结出了一种方法,一方面在流程设计上汲取质量管理的过程控制理念,保证数据生产的质量。另一方面,汲取机器学习的内在规律,从数据集上着手建立复杂场景下的数据子集,完善数据集以及数据生产上的某些“盲点”,从而能提升人脸识别算法的准确率、提高其鲁棒性、降低漏检率等。而且,还汲取了数据管理方面的经验,能应对复杂海量数据的管理。
本领域技术人员应理解,以上实施例仅是示例性实施例,在不背离本发明的精神和范围的情况下,可以进行多种变化、替换以及改变。
- 还没有人留言评论。精彩留言会获得点赞!