一种基于深度学习的违法停车自动审核方法与流程
本发明涉及交通违法审核系统中违法停车自动审核自动审核技术领域,特别涉及一种用于深度学习对于违法停车智能审核方法。
背景技术:
机动车违法停车会影响城市形象,影响市道路与交通环境,随意停放车辆会影响其他车辆的正常行驶,并有可能会导致交通事故,影响交通安全,因此违法停车一直都是交警队重点关注的。违停抓拍是其中的一种有效整治手段,但是抓拍图片需要符合一定的规则要求,方能作为有效的违停证据,因此违停抓拍图片的审核是十分重要的。
目前的审核方式是纯人工审核,这种审核方式效率低,且浪费警力,并且主观性较强,因此如何提升审核效率以及准确率是急需解决的问题。
技术实现要素:
本发明的目的是:提出一种基于深度学习方法进行违法停车智能审核系统,对于抓拍违停图片进行智能审核,从而提升审核效率以及准确率。
本发明解决其技术问题所采用的技术方案是:
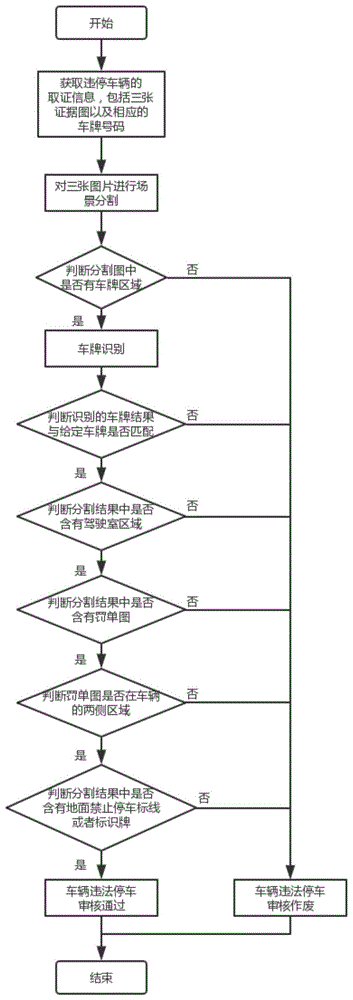
1.基于深度学习方法进行违法停车智能审核系统,包括如下步骤:
s1、获取一组(三张)待审核违法停车的图片以及车牌号信息;
s2、利用场景图片训练分割模型,并利用训练好的分割模型对三张图片进行场景分割,得到分割后的区域;
s3、判断分割后是否含有车牌区域,若含有,则进行车牌识别;
s4、判断上述车牌识别的结果与s1中的车牌号信息是否匹配;
s5、判断分割结果中是否包含驾驶室区域;
s6、判断分割结果中是否包含罚单区域;
s7、判断罚单图片是否位于车辆的两侧车窗;
s8、判断分割结果中是否包含地面禁止停车标线或者标识牌;
s9、给出待审核图片是否违法停车的最终审核结果;
所述对三张图片进行场景分割所用的分割模型的训练步骤如下:
s21、收集待分割场景的数据集,并对数据集进行标注,标注时需要进行检测训练与分割训练标签的标注,并且检测与分割数据标注比例为10:1;
检测训练需要标注的是各个区域的包围框(bbox),分割训练需要标注的
是各个区域的轮廓(counters),具体参见图3;
s22、设计分割与检测的网络结构,保证两个任务模型具有公共的的基网络部分,例如vgg16;
s23、首先利用标注好的检测数据(s21中的“10”这一部分)训练检测网络;
检测网络的训练目的是回归目标的类别和其位置,用位置损失与类别损失综合起来表征最终的目标损失函数。
s24、在训练好检测网络的基础上进行网络参数迁移,分割与检测网络使用同样的基网络结构,并且将检测网络的基网络参数保留下来进行分割网络参数的初始化,分割网络训练时,首先锁死检测与分割网络的公共部分,对于分割特有的网络部分进行训练,待训练至收敛时候,放开锁死部分的网络参数进行学习,直至最终收敛。分割网络的训练是对图像中的每个像素进行分类,利用softmax损失函数,计算标注的目标图像以及网络输出的卷积图之间的损失。
所述场景分割模型训练过程中的损失权重调整如下:
训练数据中的各个类别不均衡的情况,对于数量较少的类别调整其权重值,加大网络训练时的权重占比。例如在标注过程中,背景:车牌:罚单的像素比大概符合80:5:1的比例分布,为了网络在学习的过程中,对于占比较小的类别也能分割出好的效果,在训练分割网络时,需要对上述三个类别的损失权重进行调整,设置相应类别的损失权重为0.1:0.5:1,这样设置可以保证网络学习到各个类别的特征,同时又能够保证网络学习到不同类别的数据分布情况。
所述步骤s3包括以下步骤:
s31、利用s2中训练好的分割网络进行车牌区域的分割;
s32、对分割到的车牌区域进行车牌识别;
s33、获取车牌识别的结果,并与违章车牌作对比,判断车牌是否匹配,进而确定是否需要进行后续步骤的判断。
所述所述步骤s8判断结果包括如下步骤:
s81、利用s2中训练好的分割模型对图片进行分割,获取路面标线信息以及标识牌等信息;
s82、根据s81中获取到的标识信息判定此区域是否属于禁止停车区域;
s83、进而确定最终判别结果。
本发明的有益效果是:本发明主要应用于交通违法审核系统中违法停车自动审核中,本发明能够根据事先制定的审核规则进行智能审核,由于网络训练时接受了不同亮度与不同场景下的训练数据,因此网络的分割与识别结果对于黑天以及模糊的图片具有很好的鲁棒性,与人工审核相比,算法在特殊情况下表现出更好的效果,并且审核时间大大缩短,整个流程在1秒以内即可完成;
附图说明
图1是本发明的违法停车智能审核系统流程图。
图2是本发明所获取的证据图示意图。
图3是本方法检测标注示意图
图4是本发明分割标注示意图
具体实施方式
以下结合附图,对本发明做进一步说明。
本发明主要基于场景分割模块、车牌识别模块以及规则判定模块。
场景分割模块主要涉及到分割模型的训练,首先需要收集场景数据集进行数据标注,由于分割的标注难度较大,消耗人力物力,因此本发明采用了迁移学习的方式进行场景分割模型的训练:
首先对获取到的图片进行类别均衡扩增;
然后对于扩增后的图片按照比例10:1进行划分,将“10”这部分数据进行检测标注,即只需标注物体的包围框,“1”这一部分进行分割数据集的标注,即需要标注出物体的轮廓;
设计分割与检测的网络结构,保证两个任务模型具有公共的的基网络部分;
首先利用标注好的检测数据训练检测网络;
在训练好检测网络的基础上进行网络参数迁移,分割与检测网络使用同样的基网络结构,并且将检测网络的基网络参数保留下来进行分割网络参数的初始化,分割网络训练时,首先锁死检测与分割网络的公共部分,对于分割特有的网络部分进行训练,待训练至收敛时候,放开锁死部分的网络参数进行学习,直至最终收敛。使用此种训练方法对分割模型进行训练与使用常规方法训练相比,在达到相同的训练结果的情况下,可以减少标注工作量为原来的1/10;
对于训练数据中的各个类别不均衡的情况,调整数量较少的类别所占的损失权重值,加大网络训练时的权重占比。例如在标注过程中,背景:车牌:罚单的像素比大概符合80:5:1的比例分布,为了网络在学习的过程中,对于占比较小的类别也能分割出好的效果,在训练分割网络时,需要对上述三个类别的损失权重进行调整,设置相应类别的损失权重为0.1:0.5:1,这样设置可以保证网络学习到各个类别的特征,同时又能够保证网络学习到不同类别的数据分布情况;
车牌识别模块主要涉及到车牌识别网络的训练,车牌识别网络相对于人工进行车牌认定的优势在于,其对于夜间以及不清晰车牌的识别速度以及识别效果要优于人工过程:
首先收集各种场景的车牌数据进行标注;
然后对于数据进行亮度增益(模拟夜间环境)以及模糊化(模拟拍摄图片模糊场景);
然后利用处理之后的数据对lstm+ctc的车牌识别网络进行训练;
规则判定模块主要根据国标进行是否违法停车的判断,根据前面步骤中获取到的车牌信息、驾驶室信息以及地面表现和违停标识等信息进行综合判断,最终给出是否违法的结果。
以上显示和描述了本方案的基本原理和主要特征和本方案的优点。本行业的技术人员应该了解,本方案不受上述实施例的限制,上述实施例和说明书中描述的只是说明本方案的原理,在不脱离本方案精神和范围的前提下,本方案还会有各种变化和改进,这些变化和改进都落入要求保护的本方案范围内。本方案要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!