多类图像分割方法与流程
本发明涉及图像分割。更具体地,本发明涉及一种用于同步多类分割医学图像中的不同解剖结构的方法,诸如分割胸部射线照片中的肺部、心脏和锁骨。
背景技术:
本发明涉及不同解剖结构的同步多类分割。例如,多类分割可以被用来分割医学图像中的不同解剖结构,诸如胸部射线照片中的肺部、心脏和锁骨。可以设想其他应用,诸如分割病变(例如,由于肺结核所致的病变)、分割肋骨等。一般而言,本发明旨在多类分割医学图像中具有清晰边界的结构。
作为这样的分割过程的结果,可以检测心脏、肺野、门(hila)结构、锁骨等的大小、方位和面积的变化。这可以给出有关比如tbc和癌症的现有状况的线索,或者有助于计算机辅助检测和医疗诊断的另外步骤。因此,射线照片的语义分割(即,器官或结构的定位)一直是活跃的研究领域。个体解剖的复杂精细(intricacy)——比如像肺野、锁骨和心脏等中枢器官的形状和大小中的高人际变化,与年龄、大小和性别有关,由于器官重叠所致的器官边界模糊以及由移动和图像模态内在因素引起的伪影——仅仅是准确的器官分割仍然是一项固有的挑战性任务的几个原因。
已广泛地描述和使用了经典的算法方法。算法方法的空间可以被粗略地划分成基于规则、基于形状和基于图形的方法、像素分类和统计方法。每个方法框架都具有其自身的一套优点,例如:通过限制成预定义的规则集或可变形的形状,基于规则和形状的方法将产生解剖学上可靠的解决方案。
虽然概念上超过50年,神经网络(nn)作为深度学习的抽象基础正经历着复兴。通过利用图形处理单元(gpu)来更深地理解训练和数值行为以及急剧增加易处理的计算方案,已经允许这类方法变为实际上的标准,或者至少是若干个机器学习分支中的重要竞争者。
下面聚焦于卷积神经网络(cnn),它是计算机视觉任务中经常被成功使用的nn的子类。
这样的cnn的原型设置包括被点缀有数据缩减和池化层的卷积滤波器的组合。驱动思想在于模仿人类的视觉认知,从这个意义上说,完整的图片是从低级特征(例如,边缘和圆)中导出的,而这些特征进而又通过在每个连续层中进行重组而产生更独特的特征,并且最终产生期望的目标。在该方面,与经典方法的主要区别在于,深度学习通常避免对纯导出集使用具体的、手动设计的特征,从而更能够描述对象的不同方面。
关于医学图像的分割,已经研究了若干种这样的设置。通常,cnn被用于分类任务,即,将输入图像分配给可计数的类标签的集合。复杂的是,医学图像渴望该类标签的空间关系。如上所述,该语义分割通常在大量训练数据上建立。这样的深度数据集对于医学领域来说并不是典型的,从而使得大多数当前方法不可行,因此需要精心定制的策略。
首次尝试要追溯到15年前。tsujii等人的“automatedsegmentationofanatomicalregionsinchestradiographsusinganadaptive-sizedhybridneuralnetwork”(《医学物理学》,第25卷,第998-1007页,1998年)使用nn进行肺野分割,从而产生了约86%的准确度。aece等人的“segmentationofbonestructureinx-rayimagesusingconvolutionalneuralnetwork”(《电气与计算机工程的进展》,第13卷,第1期,第87-94页,2013年2月)使用cnn作为二元分类器,从而以完全自动化的方式将胸部射线照片划分到两个{骨,非骨}集合中。无需将nn视为独立的解决方案,如t.a.ngo和g.carneiro的“lungsegmentationinchestradiographsusingdistanceregularizedlevelsetanddeep-structuredlearningandinference”(在图像处理中,icip,2015年ieee国际会议上,2015年9月,第2140-2143页)证明的。该组将正则化水平集合与深度学习方法进行组合,并且在jsrt上产生0.948-0.985的重叠得分。
虽然cxr分割尚未被广泛覆盖,但是已经探索了不同的模式,比如超声、ct和mrt。[g.carneiro,j.c.nascimento和a.freitas,“thesegmentationoftheleftventricleoftheheartfromultrasounddatausingdeeplearningarchitecturesandderivative-basedsearchmethods”,《ieee成像处理汇刊》,第21卷,第3期,第968-982页,2012年3月;m.havaei,a.davy,d.warde-farley,a.biard,a.courville,y.bengio,c.pal,p.-m.jodoin和h.larochelle,“braintumorsegmentationwithdeepneuralnetworks”,《医学图像分析》,2016年;p.petersen,m.nielsen,p.diao,n.karssemeijer和m.lillholm,使用深度学习进行乳房组织分割和乳腺摄影风险评分。施普林格科学+商业媒体b.v.,2014年,第88-94页;b.gaonkar,d.hovda,n.martin和l.macyszyn,“deeplearninginthesmallsamplesizesetting;cascadedfeedforwardneuralnetworksformedicalimagesegmentation”,第978521-978521-8页,2016年]。在j.long,e.shelhamer和t.darrell的“fullyconvolutionalnetworksforsemanticsegmentation”(在ieee计算机视觉与模式识别会议记录中,2015年,第3431-3440页)中解决了对与全局结构相一致的局部特征的需求,并且定义了全卷积网(fullyconvolutionalnet)。这种类型的网络允许任意大小的输入和输出。从输入层开始,每个连续层输出三维矩阵,该矩阵的值对应于处理层的路径连接的区域(field)。这些区域分别被卷积、池化或一般地非线性变换,从而产生一个收缩系列的层。与层融合结合,即,所选层之间的捷径(shortcut),该设置实现了非线性、局部到全局的特征表示,并且允许像素级分类。通过使这个网络类适应连续的上采样层(即,扩大卷积的视场),ronneberger等人的“u-net:convolutionalnetworksforbiomedicalimagesegmentation”(在国际医学图像计算和计算机辅助干预会议中,施普林格,2015年,第234-241页)可以指导特征提取的分辨率,从而控制特征的局部到全局的关系。
本发明的一个方面是,使该方法适合于胸部射线照片,即,用于器官级数据集。
另外的方面是,适配该系统使得它可以成功地应用于不平衡数据集的多标签分割,并且它可以通过合理的计算量来提供非常好的分割结果。
技术实现要素:
通过具有在权利要求1中阐述的具体特征的方法来获得上面提到的方面。
在从属权利要求中阐述了本发明的优选实施例的具体特征。
本发明具有优于现有技术的以下优点:
本发明的方法对于多标签同步分割胸部射线照片中的解剖器官(特别是锁骨、肺部和心脏区域)是非常足够的。
在本发明的具体实施例中,介绍了许多具体的网络架构,这些架构能够仅在给定数据上、在不具有附加的数据增加的情况下良好地实行。
这些架构胜过在公开可用的jsrt数据集上的现有技术算法和原始u-net。
这些架构全部是多类的,并且同时分割肺部、锁骨和心脏。
此外,这些架构在具有高度不平衡的数据表示(诸如与心脏和肺野相比,在胸部射线照片中表示不足的锁骨)的数据集上有效地实行。
为了解决数据表示不平衡的问题,为网络训练程序引入了两种具体的加权损失函数。
本发明的另外的优点和实施例将从以下描述和附图中变得显而易见。
附图说明
图1a-d示出了网络架构的不同实施例,
图2示出了针对不同图像分辨率的执行时间,
图3是在根据本发明的方法中使用的架构的不同实施例对比现有技术方法的比较,
图4是针对用于像素级交叉熵损失函数的不同验证拆分的invertnet架构的比较,
图5是针对用于负骰子(dice)损失函数的不同验证拆分的invertnet架构的比较。
具体实施方式
与大多数深度学习相关的管线一样,本方法包括以下主要步骤:数据准备和归一化、设计模型架构、模型训练和测试经训练的模型。在胸部射线照片的情况下,输入包括2d图像的集合(下面被叫做j)和对应的多通道真值(ground-truth)掩膜。该模型被建立、初始化并进一步训练。训练结束后,固定所学模型权重和正则化层,并且在测试图像的集合上对模型进行验证。
多类方法
该输入包括2d图像的集合
我们首先将
用以下方式训练网络:网络以小批量
因此,对于i的每个像素,其语义类
其估计网络结果与期望真值的偏差(误差)。然后该误差被反向传播以更新网络参数。整个程序继续,直到满足定义的给定停止准则为止。
在测试时间下,看不见的图像
基础设置
由ronnenberger等人的“u-net:convolutionalnetworksforbiomedicalimagesegmentation”(在国际医学图像计算和计算机辅助干预会议上,施普林格,2015年,第234-241页)最初提出的u-net状架构包括收缩和扩展部分。在收缩部分中,通过连续应用卷积层和池化层的对来提取高级抽象特征。在扩展部分中,上采样特征分别与来自收缩部分的特征合并。网络的输出是多通道分割掩膜,其中每个通道具有与输入图像相同的大小。
已经证明了将原始u-net架构用于对电子显微堆叠中的神经元结构进行细胞跟踪和分割的优异性能。然而,对于其他主题特定的任务,当数据高度不平衡时或者在数据增加不合理时的情况下,由于不同的数据表示,需要进行附加的修改。关于医学图像中的数据不平衡的问题是由于关注的解剖器官的大小不同而发生的。例如,在jsrt数据集真值掩膜中,相应地60%的像素属于背景,29%属于肺部,2%属于锁骨,以及9%属于心脏,因此多于锁骨地强调肺部和心脏区域。
用于胸部射线照片的u-net模型的改善
在原始架构之上,对在正则化、训练和架构方面具有多种修改的网络进行分析和评估。在每个类别中,详细考虑了网络模型的许多可能的改善,并且基于评估结果,提出了许多模型,它们被定制以有效地训练和实行医学cxr图像上的多类分割。为了避免工作中所使用的数据增加,由ronnenberger等人的“u-net:convolutionalnetworksforbiomedicalimagesegmentation”(在国际医学图像计算和计算机辅助干预会议上,施普林格,2015年,第234-241页)提出了通过使用不同的更积极的正则化来不同地稍微交替该模型。在此之上,提出了若干种架构来进一步改善分割结果。除了不同的模型正则化和架构修改之外,还提出了不同的训练损失函数策略来处理高度不平衡的数据表示的问题。
架构修改
在大多数情况下,获取更多的训练数据对于任何学习算法都是有益的。然而,在医学成像中得到附加的数据并不总是可行的。
ronnenberger等人的“u-net:convolutionalnetworksforbiomedicalimagesegmentation”(在国际医学图像计算和计算机辅助干预会议上,施普林格,2015年,第234-241页)使用弹性变形进行数据增加,以便使模型正则化。然而,在胸部射线照片的情况下,弹性变形是不合理的,因为它们会使诸如肺部、心脏和锁骨之类的刚性器官(rigidorgan)在解剖学上看起来不正确,然后可能通过使网络学习特征对应于不切实际的结构而使训练混淆。
原始版本的u-net中的特征映射和层的数量很大,这导致了系统中有数千万个参数,而这使训练减速并且不一定降低泛化误差。在没有任何正则化的情况下,训练这样大的网络就可能在数据上过拟合。尤其是在没有太多训练数据可用的情况下。在cxr数据上,尤其是对于诸如锁骨之类的较小或较薄的细长解剖器官而言,由于它们在cxr图像中更加变化的形状表示,过拟合是一个问题。在网络架构较深并且训练数据的可用性有限的情况下,降低算法的泛化测试误差的另一种可能性是更积极的正则化。
全丢弃(all-dropout):简单的全正则化架构
丢弃层[29]是现代深度网络架构中的常见实践。此外,其已由bouthillier等人[30]示出,它同时也可以起到数据增加的作用。因此,我们提出了一种在网络中的每个卷积层之后具有丢弃层的架构。我们使用高斯丢弃,其相当于添加具有零均值的高斯分布式随机变量,并且标准差等于神经单元的激活(activation)。根据srivastava等人的“dropout:asimplewaytopreventneuralnetworksfromoverfitting”(《机器学习研究杂志》,第15卷,第1期,第1929-1958页,2014年),它可能甚至比使用伯努利分布的经典方法还要好。此外,由于在胸部射线照片采集期间发生的噪声,添加这样的噪声对于胸部射线照片而言是更自然的选择[31]。在下面,该架构被称为全丢弃。
b)j-net:改善较低分辨率的准确性
较小的对象很难分割,尤其是在图像分辨率低的情况下。在这种情况下,原始u-net架构的四个池化层对于这样的对象来说可能是致命的。为了在较低分辨率上处理该问题,提出了一种在下面被叫做j-net的架构。在这种架构中,全丢弃之前是四个卷积层和两个池化层。然后在这种情况下,输入层分辨率在每个维度中应该是在正常输入层处的分辨率的四倍。
c)invertednet:利用较少参数来改善准确性
处理模型过拟合的一种方式是减小参数的数量。通过下述各项提出对全丢弃的修改:a)利用(1,1)池化来实行第一池化层的延迟子采样,以及b)改变网络中的特征映射的数量。在该架构中,我们提出从大量特征映射开始,并且在每个池化层之后将其减小到1/2,然后在每个上采样层之后往回增加到两倍。
在这种情况下,网络在早期的层处学习许多不同的结构变化,并且在之后的层处学习较少的高级特征。这在诸如锁骨之类的更刚性的解剖器官的情况下似乎更合理,因为它们的形状不会变化过大,因此不需要学习过多高度抽象的特征。由于特征映射的数量相对于原始u-net架构进行改变的方式,该架构被叫做invertednet。
全卷积(all-convolutional)网络:用于分割的学习池化
j.t.springenberg,a.dosovitskiy,t.brox和m.riedmiller的“strivingforsimplicity:theallconvolutionalnet”(arxiv预印本arxiv:1412.6806,2014年)示出了使池化层被具有较高步幅的卷积层替换、或者完全去除池化层产生了相似的结果或者甚至改善了结果,因此使得网络是全卷积的。
该修改在网络中引入了新参数,但是可以将其视为针对网络的每个部分的池化的学习,而不仅仅是将池化参数固定成常量值。这样的池化学习可能有助于使网络更好地学习较小且较薄的细长对象的特征。受到j.t.springenberg,a.dosovitskiy,t.brox和m.riedmiller的工作“strivingforsimplicity:theallconvolutionalnet”(arxiv预印本arxiv:1412.6806,2014年)的进一步激励,我们考虑它们的第二种配置。在该配置中,每个池化层被其中过滤器大小等于所替换池化层的池化大小的卷积层替换。全丢弃架构被对应地修改。这种架构被进一步叫做全卷积的。
训练策略:
如已经提到的,关注的解剖器官的大小中的较大差异可能引入数据表示不平衡的问题。在这样的情况下,以像素级高度不同的量来表示类,因此针对稀疏表示的类的损失有时可能不被注意。
因此,诸如交叉熵或负骰子函数之类的经典损失公式会低估用非常小的量所表示的类。
通过引入加权距离函数,在本发明中解决了与像素表示不平衡相关的问题。
令c是全部真值类的集合,并且n是所使用的训练集的分区。对于
其中
对于距离函数
最小化。
结果,稀疏表示的类(例如,锁骨)在有利于大的真值掩膜(例如,肺野)的情况下不再是表示不足的。
对于d,我们挑选并评估了所谓的加权像素级交叉熵和加权负骰子损失函数。
在我们的情况下,加权骰子损失函数将在每个通道的最终输出特征映射处计算的s形激活取作输入。s形激活被定义为:
其中
给定图像i,令
是下述像素的集合:其中模型确定它们不属于背景,并且
然后可以将用于训练图像i的负骰子系数的距离函数d定义为:
其中
加权像素级交叉熵将在每个通道的最终输出特征映射处所计算的softmax激活取作输入。softmax
将比较两个损失函数的性能。
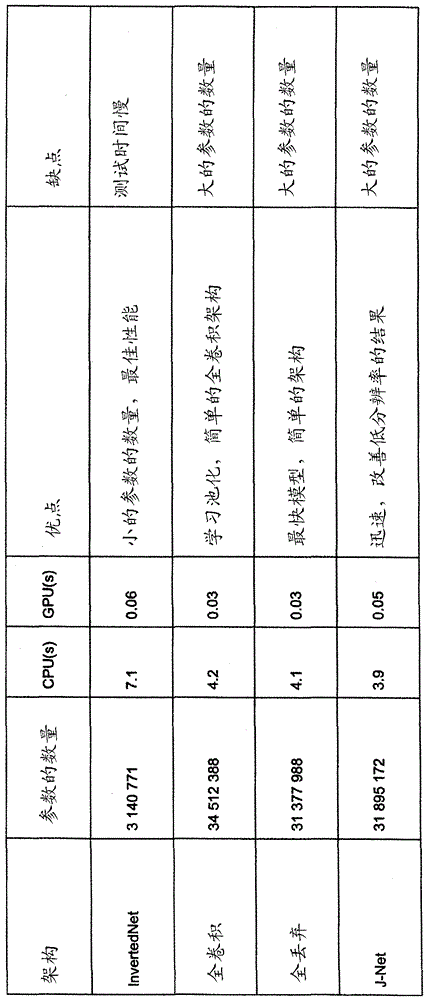
提出的网络架构
在图1中示出了网络架构的不同实施例。
详细提出的模型如下:
•全丢弃:修改版的u-net架构[ronneberger等人的“u-net:convolutionalnetworksforbiomedicalimagesegmentation”(在国际医学图像计算与计算机辅助干预会议中,施普林格,2015年,第234-241页)],其中在每个卷积层之后放置了丢弃层。在图1a处示出。
•invertednet:类似于全丢弃,其中第一池化层的延迟子采样和网络中的特征映射的数量相对于原始u-net发生反转。参见图1b。
•全卷积:类似于全丢弃,其中池化层被其中过滤器大小等于对应的池化层的池化大小的新的卷积层替换。参见图1c。
•j-net:类似于全丢弃,其中具有先前的四个卷积层和两个池化层以及较大分辨率的输入。在图1d处示出。
在全部架构中为全部卷积层使用填充卷积。因此,输出通道将具有与输入图像相同的大小,除了j-net架构之外,在j-net架构中输入尺寸是输出的四倍。全部提出的架构都包含卷积层和丢弃层。在全部架构中,除了在全卷积架构中的第三卷积层(其中该层扮演着它所替换的池化层的角色)之外,全部卷积层的后面都是丢弃层。
在全部模型中,我们在全部卷积隐藏层处使用了整流线性单元函数[r.h.hahnloser等人d“digitalselectionandanalogueamplificationcoexistinacortex-inspiredsiliconcircuit”(《自然》,第405卷,第6789期,第947-951页,200[33])]。
为了减小参数的数量并且加速训练,代替最后的密集层,使用了卷积层,其中特征映射的数量等于在加权骰子函数的情况下所考虑的类的数量,并且在加权像素级交叉熵函数的情况下具有一个或多个背景。为了在网络输出处使值落到[0,1]范围,在输出层处将s形函数用作激活。
试验
jsrt数据集
为训练和评估二者使用了jsrt数据集——j.shiraishi,s.katsuragawa,j.ikezoe,t.matsumoto,t.kobayashi,k.-i.komatsu,m.matsui,h.fujita,y.kodera和k.doi的“developmentofadigitalimagedatabaseforchestradiographswithandwithoutalungnodule;receiveroperatingcharacteristicanalysisofradiologists'detectionofpulmonarynodules”(《美国伦琴技术杂志》,第174卷,第1期,第71-74页,2000年)。该数据集包括247个pa胸部射线照片,它们具有2048×2048的分辨率、0.175mm像素大小和12位深度。
ginneken等人的“segmentationofanatomicalstructuresinchestradiographsusingsupervisedmethods:acomparativestudyonapublicdatabase”(《医学图像分析》,第10卷,第19-40页,2006年)介绍了以1024×1024分辨率的具有左右肺野、心脏、左右锁骨的参考器官边界的scr数据库。
训练模型
使用跨整个训练数据集的均值和标准差对数据进行归一化。它首先通过减去均值进行零居中,然后通过使用其标准差进行缩放来进行附加地归一化。然后将其划分成训练集和测试集。全部模型都在具有以下图像分辨率的图像上进行训练,该分辨率为128×128、256×256和512×512。通过局部平均算法将原始图像和掩膜向下采样到这些分辨率。为了使该论文可与现有技术方法相比较,我们工作中的大多数结果都对应于256×256图像分辨率。
在全部试验中,在全部卷积隐藏层处使用了整流线性单元函数——r.h.hahnloser等人的“digitalselectionandanalogueamplificationcoexistinacortex-inspiredsiliconcircuit”(《自然》,第405卷,第6789期,第947-951页,200]。它是现代网络架构中最常见且表现最佳的激活函数。
为了减小参数的数量并且加速训练,最后,代替使用密集层,我们使用卷积层,其中在加权骰子的情况下,特征映射的数量等于所考虑的类的数量,并且在加权像素级交叉熵函数的情况下具有一个或多个背景。为了在网络输出处使值落到[0,1]范围,我们在输出层处将s形函数用作激活。
为了优化模型,我们使用自适应矩估计方法(adam)——d.kingma和j.ba的“adam:amethodforstochasticoptimization”(arxiv预印本arxiv:1412-6980,2014年),因为其为每个参数采用自适应学习率方法。其存储过去的平方梯度和过去的梯度二者的衰减平均值。我们没有对这些方法实行过广泛的评估,但是初始的训练运行示出了在训练收敛方面,adam比其他现有算法表现得好得多。我们还改变了不同的初始学习率,以便找到最稳定的收敛,并且
性能度量
为了评估架构并且与现有技术的工作进行比较,我们使用了以下性能度量:
骰子相似系数:
雅尔卡相似系数:
其中在两个系数
对称平均绝对表面距离:
其中
结果
分割性能
在图3中示出了针对不同分辨率的六种所提出的架构的评估结果。此外,添加了由vanginneken等人的“segmentationofanatomicalstructuresinchestradiographsusingsupervisedmethods,acomparativestudyonapublicdatabase”(《医学图像分析》,第10卷,第19-40页,2006年)介绍的三个分辨率的原始u-net架构以及最佳表现方法和人类观察者以供比较。
将所有结果细分为五个块。
第一个块仅包含人类观察者结果。
第二个块包含由vanginneken等人的“segmentationofanatomicalstructuresinchestradiographsusingsupervisedmethods,acomparativestudyonapublicdatabase”(《医学图像分析》,第10卷,第19-40页,2006年)提出的原始u-net架构和方法的结果。
第三、第四和第五个块包含原始u-net以及针对三个不同分辨率所提出的架构的结果。用粗体描绘了每个块的最佳结果。
肺部分割的得分并没有显著变化。全部方法都能够示出良好的性能。虽然我们的架构没有胜过人类观察和混合投票(hybridvoting)方法,但是我们的一个模型达到了相同的雅尔卡得分,并且全部提出的架构以及原始u-net根据对称的表面距离获得了更准确的对象轮廓。全部提出的架构在全部器官上的全部方法当中都达到了最佳的对称距离到表面得分,这证明卷积网络在提取对应于对象边界的特征方面非常有效。即使在相当低的对比差异的情况下,例如在心脏与肺部之间或者在锁骨与肺部之间的边界上。
锁骨分割对于我们全部的架构来说都是一个更具挑战性的任务。而这并不奇怪,因为锁骨比心脏和肺部小得多,并且它们的形状从一次扫描到另一次扫描的变化更为明显。所有提出的方法都不能胜过人类观察者。不过,由“segmentationofanatomicalstructuresinchestradiographsusingsupervisedmethods,acomparativestudyonapublicdatabase”(《医学图像分析》,第10卷,第19-40页,2006年)提出的自动方法已经表现得好得多。在雅尔卡重叠得分中,所提出的最佳架构胜过混合投票几乎8%。我们全部的架构在全部图像分辨率上都比原始u-net架构表现得更好。
此外,对于较小的对象(诸如锁骨),较高分辨率的结果要好得多。除了invertednet架构,其由于子样本池化延迟和卷积层中的小的滤波器大小而示出不良的性能。不过,在较低的分辨率上已证明invertednet在锁骨分割方面性能最佳,其中超过原始u-net多于7%,并且分别超过其他两个网络5%和6%。总之,由于网络收缩部分中的多个池化层,在较低分辨率上,锁骨对于原始u-net、全卷积和全丢弃而言更具挑战性。多个池化层使得诸如锁骨之类的对象变得较小,从而使它们之间的边界平滑。在这种情况下,网络提取的特征变得不那么富有表现力。
心脏分割对于invertednet架构来说是一项具有挑战性的任务。原始u-net甚至稍微胜出,而u-net反过来被提出的其他架构超越。另外两个提出的架构全卷积和全丢弃在该任务上稍微超过了人类观察者。
整体最佳架构invertednet的性能已经通过将输入数据若干次划分成训练集和测试集进行了评估。
图4示出了利用像素级交叉熵损失函数训练的invertednet的测试结果。如理论上预期的,当向网络给出更多训练数据时,整体得分得到了改善。另一方面,训练集和测试集中的样本数量之间的差异越来越大,这导致在数据上的稍微过拟合,从而增加了最终的泛化误差。但是对于负骰子损失函数来说,情况并非如此,其中训练样本的数量明显增加会给出更好的结果。图5中示出了针对负骰子损失函数的不同测试拆分的评估结果。
关于原始u-net的性能以及在训练期间的每个时期下的测试集上提出的模型,原始u-net的得分通常在开始时比其他网络增长得更迅速,但然后达到稳定水平并振荡,直到训练程序结束为止。其他更好的正则化架构虽然起步较慢,但是最终达到更高或类似的得分。invertednet在开始时启动缓慢但最终达到最佳结果。
定时性能
本发明的方法是用于胸部射线照片的非常迅速的分割方法。其可以每天处理数千张图像,这在每天检查数百甚至有时数千人的大临床环境中尤其有益。
- 还没有人留言评论。精彩留言会获得点赞!