用于神经网络处理的具有矩阵-向量相乘区块的硬件节点的制作方法
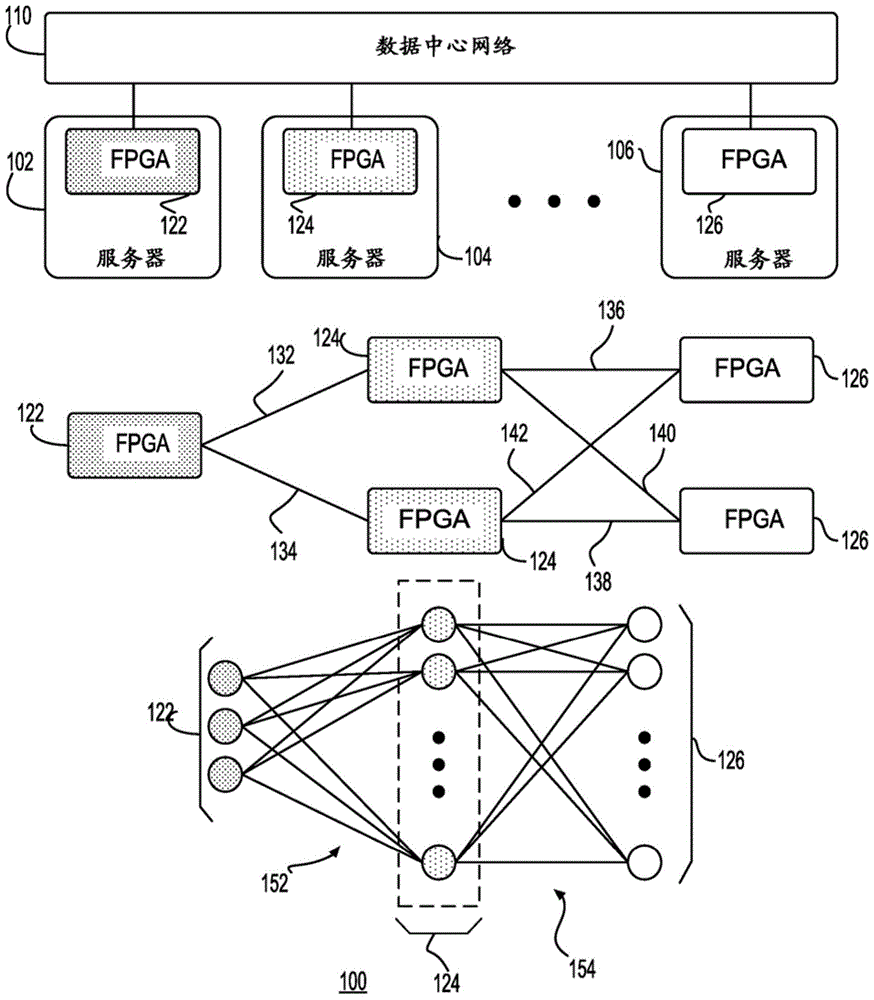
神经网络技术用于执行复杂的任务,诸如阅读理解、语言翻译或语音识别。虽然神经网络可以执行这种任务,但使用通用cpu或通用gpu进行部署是很昂贵的。另外,虽然gpu相对于cpu提供了增加的吞吐量,但它们具有较差的延时。技术实现要素:在一个示例中,本公开涉及一种用于评估系统中的神经网络模型的方法,系统包括经由网络互连的多个节点,其中每个节点包括多个区块(tile)。方法可以包括经由入口树接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8整数。方法还可以包括:将n乘m系数矩阵的第一行存储在第一片上存储器中,并且将n乘m系数矩阵的第二行存储在第二片上存储器中,该第一片上存储器被并入多个区块中的第一区块内,该第二片上存储器被并入多个区块中的第二区块内。方法还可以包括:使用第一计算单元来处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量,该第一计算单元被并入多个区块中的第一区块内。方法还可以包括:使用第二计算单元来处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量,该第二计算单元被并入多个区块中的第二区块内。在另一示例中,本公开涉及包括多个区块的硬件节点。硬件节点还可以包括入口树,该入口树被配置成接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8的整数。硬件节点还可以包括被并入多个区块中的第一区块内的第一片上存储器,其被配置成存储n乘m系数矩阵的第一行。硬件节点还可以包括被并入多个区块中的第二区块内的第二片上存储器,其被配置成存储n乘m系数矩阵的第二行。硬件节点还可以包括被并入多个区块中的第一区块内的第一计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量。硬件节点还可以包括被并入多个区块中的第二区块内的第二计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量。在又一示例中,本公开涉及包括多个区块的硬件节点。硬件节点还可以包括入口树,入口树被配置成接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8的整数,并且其中入口树包括第一入口树寄存器,其扇出到第二入口树寄存器和第三入口树寄存器。硬件节点还可以包括被并入多个区块中的第一区块内的第一片上存储器,其被配置成存储n乘m系数矩阵的第一行。硬件节点还可以包括被并入多个区块中的第二区块内的第二片上存储器,其被配置成存储n乘m系数矩阵的第二行。硬件节点还可以包括被并入多个区块中的第一区块内的第一计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量。硬件节点还可以包括被并入多个区块中的第二区块内的第二计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量。提供本
发明内容是为了以简化的形式介绍一些构思,这些构思将在下面的具体实施方式中进一步描述。本
发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。附图说明本公开通过示例的方式说明,并且不限于附图,其中相同的附图标记指示类似的元件。附图中的元件是为了简单和清楚起见而图示的,并且不一定按比例绘制。图1是根据一个示例的包括经由数据中心网络互连的节点的系统的框图;图2是根据一个示例的包括分布式节点的系统的框图;图3是根据一个示例的硬件节点的框图;图4是根据一个示例的神经功能单元的框图;图5a和图5b示出了根据另一示例的神经功能单元的框图;图6示出了根据一个示例的用于执行神经网络处理的硬件节点(例如,fpga)的框图;图7示出了根据一个示例的用于执行神经网络处理的区块布置的框图;图8示出了根据一个示例的处理元件的框图;图9示出了包括区块矩阵的节点的示例实施方式;图10示出了根据一个示例的多功能单元的框图;图11示出了根据一个示例的神经网络评估的数据流图;图12示出了根据一个示例的神经功能单元对指令链的示例处理;图13示出了根据一个示例的用于神经网络评估的数据流图;图14示出了根据一个示例的如何使用硬件节点(例如,fpga)处理指令链的图;以及图15示出了根据一个示例的用于评估神经网络的方法的流程图。具体实施方式本公开中公开的示例涉及使用用于实现基于神经网络的处理的系统、方法和组件。某些示例涉及深度神经网络(dnn)。dnn可以是用于深度学习的任何合适的神经网络。本公开中的附加示例涉及作为用于实现dnn或类似神经网络的节点的一部分而被包括的功能单元。可以使用现场可编程门阵列(fpga)、专用集成电路(asic)、可擦除和/或复杂可编程逻辑器件(pld)、可编程阵列逻辑(pal)器件和通用阵列逻辑(gal)的部分或组合来实现节点。图像文件可以用于配置或重新配置诸如fpga的节点。可以经由网络链路或本地链路(例如,pcie)从主机cpu递送图像文件或类似的文件或程序。被包括在图像文件中的信息可以用于编程节点的硬件块(例如,fpga的逻辑块和可重新配置的互连)以实现期望的功能性。期望的功能性可以被实现以支持可以经由计算、联网和存储资源的组合(诸如经由数据中心或用于递送服务的其他基础设施)提供的任何服务。在一个示例中,本公开涉及dnn,其包括多个节点(例如,fpga)或这样的节点的组,这样的节点经由低延时网络彼此耦合。利用数百到数千个这种节点(例如,fpga)的聚合平台可以有利地提供:(1)显著减少的、采用跨数十万节点的并行性的训练时间,(2)实现新的训练场景,诸如对实时数据的原位在线学习,以及(3)前所未有的尺度的训练模型,同时利用跨度数十万台服务器的超尺度数据中心中的、灵活且可互换的同类fpga资源。在一个示例中,可以通过采用非常规的数据表示来获得这种优点,非常规的数据可以利用诸如fpga的节点的架构。所描述的各方面还可以在云计算环境中实现。云计算可以指用于实现对可配置计算资源的共享池的按需网络访问的模型。例如,可以在市场中采用云计算来提供对可配置计算资源的共享池的普遍且方便的按需访问。可配置计算资源的共享池可以经由虚拟化而被快速提供,并且以低管理工作量或低服务提供方交互而被发布,并且然后相应地被缩放。云计算模型可以包括各种特性,诸如,例如按需自助服务、广泛网络访问、资源池化、快速弹性、测量服务等。云计算模型可以用于暴露各种服务模型,诸如,例如硬件即服务(“haas”)、软件即服务(“saas”)、平台即服务(“paas”)和基础设施即服务(“iaas”)。还可以使用不同的部署模型,诸如私有云、社区云、公共云、混合云等,来部署云计算模型。可以使用本公开中描述的系统和节点来实现机器学习服务,诸如基于递归神经网络(rnn)、长短期存储器(lstm)神经网络或门控递归单元(gru)的机器学习服务。在一个示例中,可以将与服务相关的内容或其他信息(诸如单词、句子、图像、视频或其他这种内容/信息)转换成向量表示。向量表示可以对应于诸如rnn、lstm或gru的技术。可以在服务初始化之前离线训练深度学习模型,并且然后可以使用本公开中描述的系统和节点来部署深度学习模型。节点可以是硬件可编程逻辑器件,其可以被专门定制为执行在诸如dnn的神经网络的上下文中发生的操作类型。在一个示例中,神经网络模型的状态和用于控制模型的参数可以被固定到包括分布式硬件平台的节点的片上存储器。可以在服务启动时将神经网络模型固定(例如,预加载)到片上存储器,并且可以不改变片上存储器的内容,除非模型要求改变或者另一事件需要用模型重新加载片上存储器。因此,在该示例中,与其他布置不同,可以不从与硬件平台相关联的dram来访问神经网络模型,而是将其直接加载到硬件节点的片上存储器(例如,sram)中。跨分布式可编程逻辑块集(例如,fpga资源)来固定模型可以允许节点(例如,fpga)以全容量操作,并且这可以有利地改善与服务相关联的吞吐量和延时。作为示例,即使来自服务的单个请求也可以使得分布式节点集以全容量操作,并且从而以非常低的延时递送由服务的用户请求的结果。在一个示例中,神经网络模型可以包括许多层,并且每个层可以被编码为权重的矩阵或向量,权重的矩阵或向量以经由神经网络的离线训练获得的系数或常数的形式表示。节点中的可编程硬件逻辑块可以处理矩阵或向量以执行各种运算,包括针对输入向量的相乘、相加和其他运算,该输入向量表示与服务有关的编码信息。在一个示例中,可以通过使用诸如图划分(partitioning)的技术来跨多个节点地划分和固定权重的矩阵或向量。作为该过程的一部分,大型神经网络可以被转换为中间表示(例如,图),并且然后中间表示可以被切分为较小的表示(例如,子图),并且与每个子图相对应的权重矩阵中的每个权重矩阵可以被固定到节点的片上存储器。在一个示例中,可以将模型转换为固定大小的矩阵和向量。以这种方式,节点的资源可以并行地对固定大小的矩阵和向量进行运算。以lstm为例,lstm网络可以包括一系列重复的rnn层或其他类型的层。lstm网络的每个层可以在给定的时间步长消耗输入,该输入例如是来自先前的时间步长的、层的状态,并且可以产生新的一组输出或状态。在使用lstm的情况下,单个内容组块(chunk)可以被编码成单个向量或多个向量。作为示例,单词或单词的组合(例如,短语、语句或段落)可以被编码为单个向量。每个组块可以被编码到lstm网络的单独层(例如,特定时间步长)中。可以使用一组等式来描述lstm层,例如下面的等式:it=σ(wxixt+whiht-1+wcict-1+bift=σ(wxfxt+whfht-1+wcfct-1+bf)ct=ftct-1ittanh(wxcxt+whcht-1+bc)ot=σ(wxoxt+whoht-1+wcoct+bo)ht=ottanh(ct)在该示例中,在每个lstm层内部,可以使用向量运算(例如,点积、内积或向量加法)和非线性函数(例如,sigmoid、双曲线和正切)的组合来处理输入和隐藏状态。在某些情况下,大多数的计算密集的运算可能来自点积,其可以使用密集的矩阵-向量和矩阵-矩阵乘法例程来实现。在一个示例中,向量运算和非线性函数的处理可以并行执行。图1是根据一个示例的包括经由数据中心网络110互连的节点的系统100的框图。例如,如图1中所示,多个节点102、104和106可以经由数据中心网络耦合。这样的节点可以被实例化并且用于使诸如lstm网络的神经网络的多个层并行化。在一个示例中,每个节点可以被实现为服务器并且还可以包括至少一个硬件节点(例如,fpga)。因此,节点102可以包括fpga122,节点104可以包括fpga124,并且节点106可以包括fpga126。fpga可以经由基于光传输层协议的系统互连。在一个示例中,fpga122的第一实例可以经由传输链路132与fpga124的第一实例耦合,并且fpga122的第一实例还可以经由传输链路134与fpga124的第二实例耦合。fpga124的第一实例可以经由传输链路136与fpga126的第一实例耦合,并且fpga124的第一实例还可以经由传输链路140与fpga126的第一实例耦合。类似地,fpga124的第二实例可以经由传输链路142与fpga126的第一实例耦合,并且fpga124的第二实例还可以经由传输链路138与fpga126的第二实例耦合。光传输层协议可以为fpga提供经由数据中心网络110彼此传送或接收分组或其他这种数据的能力。fpga也可以以其他配置互连。例如,fpga122的若干实例可以经由多个传输链路152耦合到fpga124的若干实例。类似地,fpga124的若干实例可以经由传输链路154耦合到fpga126的若干实例。虽然图1示出了包括fpga的节点的特定数目和布置,但是可以存在更多或更少数目的、被不同地布置的节点。图2是根据一个示例的包括分布式节点的系统200的框图。在该示例中,多个节点可以被实现为数据中心中的服务器机架。这些服务器中的每个服务器可以耦合到架顶式(tor)交换机。虽然未被示出,但是其他机架也可以具有类似的配置。每个服务器可以包括至少一个节点或多个节点。每个节点可以包括服务器(例如,服务器204、服务器206或服务器208),并且每个服务器可以耦合到tor交换机(例如,tor交换机210)。服务器204可以包括主机组件,主机组件包括cpu,诸如cpu214和cpu216,cpu可以经由本地链路(例如,pcie)220耦合到硬件节点(例如fpga218)。每个硬件节点也可以通过网络接口控制器222(例如,用于跨数据中心的网络基础设施进行通信)的方式进行耦合。图2中所示的系统可以允许节点对从tor交换机或其他交换机接收(和/或发送到tor交换机或其他交换机)的消息执行处理。使用该示例系统,各个节点可以直接向彼此发送包括分组的消息,并且因此这可以允许跨多个fpga对甚至单个神经网络的划分,而不会引起不可接受的延时。对于通信,节点可以使用包括例如rdma的轻量型协议。虽然图2示出了以特定方式布置的系统的特定数目的组件,但是可以存在更多或更少数目的、被不同地布置的组件。还可以通过跨多个节点拆分神经权重来在神经网络的层内执行并行化。作为示例,单个rnn模型(例如,包括lstm权重矩阵)可以被划分并且跨多个节点被固定。在该示例的实施方式中,rnn模型可以跨多个fpga中的每个fpga的存储器(例如,bram)分布。在该示例配置中,多级管线中的每个单独的fpga可以将lstm权重矩阵的一部分存储在快速片上存储器(例如,bram)中。这可以有利地得到高吞吐量和低延迟系统。在服务启动时,lstm权重矩阵可以被分解成特定大小的矩阵(例如,n乘m矩阵,其中n和m中的每个是等于或大于8的整数),并且然后被加载到fpga的片上存储器中。运行时管理层可以实现fpga的分配、调度和管理。在一个示例中,每个节点可以被实现为基于一个或多个fpga的附接有haas的、聚焦于lstm的向量处理器。每个节点可以被设计为运行神经网络评估,作为附接有pcie的fpga或作为fpga的haas池的一部分。图3是根据一个示例的硬件节点300的框图。每个硬件节点300可以包括用于从其他节点接收消息的输入消息处理器(imp)310和用于处理去往其他节点或组件的传出消息的输出消息处理器(omp)340。每个节点还可以包括控制/标量处理器(csp)320和神经功能单元(nfu)330。虽然未被示出,但是由节点接收的接收消息可以被存储在至少两个不同的队列中:(1)imp到csp辅助队列和(2)imp到nfu数据队列。虽然未被示出,但是传出消息可以被存储在至少两个不同的队列中:(1)csp到imp辅助队列和(2)nfu到omp数据队列。在该示例中,节点可以接受片外消息,片外消息包含诸如控制和标量数据的辅助信息和有效载荷数据(例如,向量、矩阵或其他张量数据结构)。辅助信息可以包括对有效载荷执行计算密集型运算的请求,并且然后以输出消息的形式返回结果。在该示例中,传入消息由轻量型输入消息处理器(imp)310处置,其将辅助信息发送给控制/标量处理器(csp)320(其可以是基于nios的控制处理器),并且将有效载荷数据(例如,输入张量)发送给神经功能单元(nfu)330,其可以被实施为矩阵-向量处理器。作为示例,csp320然后可以解释该请求,并且基于其固件,可以向nfu330发送一系列指令。在一定的处理延时之后,nfu可以产生请求的结果,其可以在轻量型输出消息处理器(omp)340中与由csp320产生的辅助数据组合,并且然后被发送到片外。csp固件可以向nfu330提供指令。示例指令的另外的细节作为指令集架构(isa)的一部分被讨论。还可以执行针对csp320的固件的运行时重新加载。因此,在该示例中,架构主要是事件驱动的。输入消息可以从许多来源(包括通过网络)到达。imp可以检查消息队列的头部,并且它可以使需要被执行的任何指令出列并且将其馈送通过系统。虽然图3示出了以特定方式布置的示例节点的特定数目的组件,但是可以存在更多或更少数目的、被不同地布置的组件。在一个示例中,nfu可以被实现为矩阵-向量处理器,其被设计为向上缩放到大部分的fpga的资源。在该示例中,nfu的主要硬件加速目标是:通过应用数千个乘法加法器,用其矩阵-向量单元(mvu)以高吞吐量和低延时执行矩阵-向量乘法。nfu可以接收系数矩阵(例如,常数),并且可以用于将这些系数与动态输入向量数据相乘。因此,代替将系数存储在对应于cpu/gpu的dram中,系数可以在服务启动时被预加载到对应于nfu的片上存储器(例如,fpga的块随机存取存储器(bram))中。在一个示例中,除非正在被使用的神经网络模型被修改或服务被重新启动,否则系数一旦被加载就可能永远不会被重新加载。换言之,作为该示例的一部分,模型可以以分布式方式被划分并且被固定到多个节点(例如,fpga)的片上存储器,这些节点以它们可以直接向彼此传送消息或分组而不依赖cpu资源的帮助的方式来连接。在一个示例中,mvu可以是完全管线化的,并且可以能够在o(n)时间内执行o(n2)复杂度的矩阵-向量乘法,其性能为每秒4000-18000亿的定点运算。虽然矩阵-向量乘法可以表示评估lstm层所需的绝大多数的定点运算,但评估还可以包含各种偏置向量的向量减缩、超越以及相加。nfu还可以实现经管线化的多功能单元(mfu),以在o(n)时间内处置这些o(n)复杂度的向量函数。这些mfu可以被组织成链式架构,其中mvu将数据传递给第一mfu,第一mfu将数据传递给第二mfu,等等。在nfu的一个示例实施方式中,可以使用1mvu和5个mfu。基于观察到在向量和矩阵-向量运算花费大约相同的时间量来计算的架构中,向量函数可能潜在地支配lstm评估时间,链式架构可以允许nfu采用单个矩阵-向量乘法和若干向量函数之间的大规模管线并行性。nfu的存储器子系统也可以被配置成支持高吞吐量。作为示例,存储器子系统可以支持高达1.8tb/s的矩阵值吞吐量,以及支持同时加载6个向量和存储6个向量。图4示出了nfu400的示例实施方式。nfu400可以包括用于接收输入数据的输入队列(iq)410和用于输出输出数据的输出队列(oq)420。因此,nfu400可以通过其输入队列(iq)410引入外部向量和矩阵数据,并且通过其输出队列(oq)420发出向量数据。nfu400可以包括全局向量寄存器文件(gvrf)430,其用于提供集中位置,该集中位置可以用于存储向量数据。nfu400可以包括矩阵-向量单元(mvu)440和5个多功能(mfu)(例如,mfu#0450、mfu#1460、mfu#2470、mfu#3480和mfu#4490,如图4中所示)。mvu440可以包括矩阵寄存器文件442,以用于存储可以在开始服务时被预加载的矩阵,该服务被节点支持。每个mfu还可以包括本地向量寄存器文件(lvrf)453,以用于存储针对对应的mfu的本地向量数据(例如,lvrf452、lvrf462、lvrf472、lvrf482和lvrf492)。指令可以由nfu400按顺序执行。一系列指令可以被配置成使得管线(包括例如一个mvu440和5个mfu)并行地执行指令链。作为示例,输入向量数据可以使用mvu440使用矩阵运算而被相乘,并且然后可以通过管线而被传递给输出队列420。经由图4中的两个虚线路径和一个实线路径,示出了nfu400中的各种数据流可能性。稍后将提供链接指令的进一步的细节和示例。示例nfu400可以对向量和矩阵进行运算。向量是1d标量元素集,矩阵是2d标量元素集。可以使用下面的表1中的参数来设置元素、向量和矩阵的大小。表1某些参数(例如,如表1中所示)可以用于在设计时或之后配置nfu400。在一个示例中,可以使用四个参数来配置nfu400。第一参数可以是矩阵和向量元素的数据类型,尤其是单个元素的宽度(elem_width)。作为示例,在一个示例中,8位定点数据类型、16位定点数据类型、27位定点数据类型和32位浮点数据类型可以是数据类型集。nfu400中的每个数据总线的宽度可以被配置为elem_width*lanes位;每个向量可以使用存储器中的elem_width*hwvec_elems位;并且每个矩阵可以使用存储器中的elem_width*hwvec_elems*hwvec_elems位。第二参数可以是硬件向量大小(hwvec_elems)。在一个示例中,被存储在nfu400内的所有向量可以具有等于hwvec_elems的固定数目的元素,并且所有向量指令可以接受hwvec_elems个元素作为输入和/或产生hwvec_elems个元素作为输出。另外,所有矩阵可以具有等于hwvec_elems的固定数目的元素。许多应用可以具有其自己的算法维度,该算法维度可能与硬件向量大小不同。在这种情况下,程序员(或编译器)可以使用诸如矩阵分块的技术将高级别运算映射到硬件向量大小。作为示例,下面的表2示出了具有500×500矩阵大小和500元素向量大小的应用;但是,nfu400的硬件向量大小为250。表2中所示的函数可以用于解决这种差异。表2第三参数可以是向量通道的数目(lanes),其描述了应当在每个mfu内并行运算多少元素。作为示例,假设存在hwvec_elems个区块,其中每个区块具有lanes个乘法加法器,则矩阵-向量单元(mvu)440内的并行运算的数目可以被定义为lanes*hwvec_elems。区块还被描述为与示例矩阵-向量单元(mvu)440相对应的描述的一部分。另外,对于lanes*elem_width位的总宽度,每个nfu数据总线(包括顶级别端口)可以每个周期携带lanes个向量元素。在一个示例中,lanes是hwvec_elems的整数因子以避免位填充,因为向量在lanes大小的组块中被运算并且它需要hwvec_elems/lanes周期来处理向量。第四参数可以是矩阵寄存器文件的大小(nrf_size),其在与nfu相对应的片上存储器(例如,快速片上bram(参见后面的描述))中存储给定数目的hwvec_elems×hwvec_elems矩阵。在一个示例中,节点上的存储器资源需求(例如,fpga上的bram资源的数目)可以通过下面的一组公式导出(注意,ceil(x,y)将x舍入到最接近的y的倍数):bramwidth=ceil(lanes*data_width,40)关于存储器子系统,nfu400可以将其内部存储装置跨三种主要类型的存储器分布。首先,矩阵寄存器文件可以用于在一系列快速片上随机存取存储器(例如,fpga中的bram)中存储mrf_sizehwvec_elems×hwvecs_elems矩阵。这些bram可以分布在整个矩阵向量单元中,并且每个bram可以每个周期提供lanes个矩阵元素,以获得hwvec_elems*lanes*elem_width位/周期的总片上矩阵吞吐量。在该示例中,可能需要o(hwvec_elems2)个周期来将矩阵存储到矩阵寄存器文件中;因为这种矩阵存储可以在预加载步骤中被执行,并且然后针对许多矩阵-向量乘法被分摊。接下来,如图4中所示,全局向量寄存器文件(gvrf)430可以用作集中位置,程序员可以使用该集中位置来存储向量数据。gvrf的一个示例配置可以存储32个向量,并且可以在每个周期读取lanes个向量元素,同时还可以在每个周期写入lanes个向量元素。另外,nfu中的每个多功能单元可以具有其自己的本地向量寄存器文件(lvrf),其也可以在每个周期读取和写入lanes个向量元素。因此,在具有5个mfu的示例nfu中,总向量存储器带宽是12个单独的向量的、每个周期的6*lanes读取和6*lanes写入。该向量存储器架构被配置成支持将若干向量函数链接在一起,若干向量函数中一个向量函数可以从gvrf读取,若干向量函数中的每个向量函数可以读取和写入一个lvrf,并且若干向量函数中的一个向量函数可以写回gvrf。nfu的矩阵-向量单元(mvu)440可以执行管线化的高吞吐量低延时矩阵-向量乘法。在一个示例中,mvu440使用lanes*hwvec_elems个乘法器和加法器来实现该目标,并且其吞吐量可以被测量为每秒2*lanes*hwvec_elems*fmax个运算。在一个示例中,与依赖于向量批处理的通常的高吞吐量矩阵-向量乘法器不同,mvu440一次接受一个向量到其管线中。图5a和图5b示出了根据另一示例的神经功能单元(nfu)500的框图。nfu500可以包括输入队列单元510、全局向量寄存器文件(vrf)520、矩阵向量相乘530和n个多功能单元(mfu)。作为示例,nfu500可以包括mfu0540、mfu1560和mfun-1580.在该示例中,这些组件中的每个组件可以以管线方式连接。nfu500还可以包括多路复用器和解多路复用器的布置,其可以用于控制通过nfu500的向量、指令或其他数据的路由。例如,nfu500可以包括多路复用器mux0504、mux1506、mux2510和mux544,并且它还可以包括解多路复用器demux502、demux508、demux512、demux514和demux516。作为示例,解多路复用器demux502可以从输入队列单元510接收指令或数据,并且将其耦合到多路复用器mux0504或多路复用器mux1506。这些备选耦合可以通过向解多路复用器提供控制信号来实现。控制信号可以由与nfu500相关联的解码器生成。每个mfu可以包括局部向量寄存器文件(localvrf)542、加法块(+)546、乘法块(x)548、双曲正切函数块(tanh)550、sigmoid块(sigm)552和无运算(nop)块554,以及存储器管理功能性。虽然图5示出了以特定方式布置的特定数目的nfu500的组件,但是可以存在以不同方式布置的、更多或更少数目的组件。图6示出了根据一个示例的用于执行神经网络处理的硬件节点(例如,fpga)600的框图。硬件节点600可以包括存储器元件(例如,块ram)610的列和处理逻辑块(例如,数字信号处理器(dsp))622的列。可以配置小的bram和dsp的集以创建处理区块,例如,处理区块630。在图6的示例中,每个区块(例如,处理区块630)可以包括bram632、634、636、638和640,其可以如图6所示地那样布置。每个处理区块630还可以包括处理逻辑块(例如,数字信号处理器(dsp))642、644、646、648、650和652,其可以如图6所示地那样布置。处理逻辑块可以用于将输入向量与一行权重相乘。可以使用加法器660将处理逻辑块的输出相加。因此,在该示例中,每个区块可以执行逐点点积运算。虽然图6示出了以特定方式布置的特定数目的硬件节点600的组件,但是可以存在更多或更少数目的、被不同地布置的组件。图7示出了根据一个示例的用于执行神经网络处理的区块布置700的框图。如图7中所示,在该示例中,通过树广播将这些向量馈送到hwvec_elems个处理元件的阵列(例如,在图7中被称为区块)。因此,作为示例,经由向量入口702接收的向量可以被存储在图7中所示的入口树寄存器(reg)710中。接下来,向量可以扇出到两个或更多个寄存器(例如,入口树寄存器712和入口树寄存器714)。可以使用附加参数(fanout)来描述入口树中从每个节点扇出的连接的数目。处理元件(例如,区块722、724、726和728)可以处理向量,并且每个区块可以向出口移位寄存器(reg)(例如,出口移位寄存器742和出口移位寄存器744)提供输出。来自mvu的输出可以被移位出通过向量出口块750。处理元件(例如,区块)可以在每个周期执行lanes个乘法和lanes个加法。mvu每个周期可以接受lanes个输入向量元素,并且在管线延时之后,每个周期发出对应的输出向量的lanes个元素。针对单个输入向量的延迟可以被定义为logfanout(hwvec_elems)+2*hwvec_elems/lanes,因为它需要logfanout(hwvec_elems)个周期来使数据渗透通过入口树,hwvec_elems/lanes个周期来计算输出,以及hwvec_elems/lanes个周期来发出向量通过出口管线。每个处理元件(例如,区块)可以存储mrf_size矩阵中的一行,并且使用其处理元件来计算向量和所选择的矩阵的单个行的点积。图8示出了根据一个示例的处理元件800的框图。在该示例中,处理元件可以被实现为针对向量的通用矩阵相乘(gemv)区块810。每个处理元件800可以从入口树接收输入数据(例如,如图5中所示)并且将数据输出到出口管线(例如,如图7中所示)。每个处理元件可以包括用于存储向量数据的块ram(例如,用于矩阵行1的bram820)。在该示例中,每个处理元件(例如,gemv区块)可以包括bram,该bram可以存储矩阵的行1并且处理该行中的向量数据。在一个示例中,处理元件可以使用处理块(例如,用于矩阵行1的pe830)来计算向量数据和任何输入数据(例如,经由路径“来自入口树的输入数据”接收)之间的点积。可以经由路径“去往出口管线的输出数据”提供输出数据以用于进一步的处理。虽然图8示出了以特定方式布置的特定数目的gemv区块810的组件,但是可以存在更多或更少数目的、被不同地布置的组件。图9示出了包括区块矩阵的节点900的示例实施方式。在该示例实施方式中,使用具有252个区块的节点900处理252×252数据矩阵910。示例节点900可以经由输入队列920接收数据,输入队列920可以使用总线922耦合到广播块930。在该示例中,总线922的总线宽度可以是192位。广播块930可以经由各个总线耦合到sram块,以允许将经预训练的神经网络模型快速加载到节点900中。作为示例,图9示出了区块0940、区块1950和区块251960。区块0940可以经由192位总线932耦合到广播块930。区块1950可以经由192位总线934耦合到广播块930。区块251960可以经由192位总线936耦合到广播块930。每个区块可以包括对应的sram和点积单元。作为示例,区块0940可以包括sram942和点积单元944,它们可以使用192位总线946彼此耦合。区块1950可以包括sram952和点积单元954,它们可以使用192位总线956彼此耦合。区块251960可以包括sram962和点积单元964,它们可以使用192位总线966彼此耦合。每个sram可以存储权重矩阵的一行,其可以基于图9中所示的寻址方案而被存储。每个点积单元可以被实现为12输入点积单元。在服务启动时,经预训练的神经网络模型权重可以被流传输到fpga的片上存储器(例如,图9中的sram)中并被固定成特定的布置,从而允许计算单元以非常高的吞吐量生成输出。在一个示例中,矩阵的每行可以表示一个神经元,并且该行中的每个列条目可以表示附接到该神经元的突触权重。以矩阵形式被存储的系数(例如,表示神经元)可以被预加载到与硬件节点相关联的sram或其他存储器中。在神经元不适合单个硬件节点(例如,fpga)的情况下,可以将一部分神经元加载到第二硬件节点中,依此类推。在一个示例中,可以使用图划分技术来分布神经权重矩阵。使得表示神经权重矩阵的图可以被拆分成子图,然后可以将子图固定到不同的硬件节点的存储器中,不同的硬件节点可以使用轻量型传输协议或其他类型的协议彼此通信。硬件节点可以彼此直接通信,例如,使用经由图1和图2描述的架构和系统。广播块930可以包括如之前关于图5所讨论的入口树。该示例示出了使用对固定大小的矩阵和向量进行运算的fpga构建的架构。在该示例中,被支持的本机大小为252乘252方阵。在这些设计的其他参数化的实例中,可以使用其他形状和大小的矩阵。在该示例中,存在24个方阵,其可以被存储到片上存储器(例如,sram)中。因此,在该示例中,存在252个区块的阵列,并且每个区块是计算单元。每个sram可以在每个时钟周期从广播块接收192位,并且输出192位到12输入点积单元。这转换为以每个元素16位、在每个周期馈送12个元素。作为示例,对应于地址0(addr0)的sram的行被配置成存储元素0-0到0-11,其是前12个元素。在addr1存储另外12个元素,依此类推。该示例示出了在每个时钟周期馈送一行的多个元素的一种封装策略。在该示例中,sram仅使用21行(地址0到地址20),这足以存储整个方阵。在该示例中,可以将多达24个252乘252方阵封装到对应于节点900的片上存储器中。根据权重的数值精度,可以封装更少或更多的矩阵。作为示例,8位模式可以用于封装多达48个与16位模式相同大小的矩阵。实际上,还可以支持其他排列。12-输入点积单元执行计算,因此,在该示例中,节点900包括向量乘法-加法树。作为示例,为了执行点积运算,可以在该行的每个元素与向量的每个元素之间执行逐元素对相乘,然后将其累加成一个累加变量。在图9中所示的示例中,区块中的每个区块负责计算矩阵的一行。在每个时钟周期,可以一次处理该矩阵中的12个元素。该示例对应于16位整数算术(例如,每个权重由16位表示),并且因此每个sram条目是512×192位。可以使用其他位大小,包括例如1位、2位、4位或8位,以表示对应于神经网络模式的权重。图10示出了根据一个示例的多功能单元(mfu)1000的框图,其对应于例如之前关于图4描述的nfu。关于nfu的多功能单元(mfu),它们可以基于本地和/或外部数据执行若干向量函数。示例mfu实施方式可以支持逐点加法、乘法、sigmoid和双曲正切函数,以及传递和存储器管理功能性。在一个示例中,每个mfu可以以如下方式配置:mfu可以处置的每个指令类型所需的每个运算器(例如,用于执行运算的硬件块)被提供在每个mfu中,并且每个运算器沿着多个mfu的链接的路径被复制(例如,如图4中所示)。以这种方式链接的指令(稍后解释)可以被灵活地形成,而不必在链中规定或提供指令的位置。可以使用查找表来实现sigmoid和双曲正切。在一个示例中,对于所选择的函数,单个mfu可以在每个周期执行一定数目的运算(例如,由前面描述的lanes参数指定的运算),同时分别为加法/乘法和sigmoid/正切添加1到2个周期的延时。在该示例中,mfu1000可以包括被配置成执行不同运算的硬件块。每个硬件块可以对值或操作数执行运算,该值或操作数从若干源(包括例如先前的mfu、mvu或gvrf)接收。中间值可以被存储在本地向量寄存器文件(lvrf)1010中。作为示例,一个硬件块1020可以执行加法运算。另一硬件块1030可以执行相乘运算。另一块1040可以执行正切(例如,tanh)运算。另一块1050可以执行sigmoid(sigm)运算。又一块1060可以不执行运算(nop)。各种硬件块的输出可以被提供给多路复用器1060。基于来自各种队列控制器或其他控制逻辑的一个控制信号或多个控制信号,多路复用器(mux)可以提供输出,该输出可以耦合到管线中的下一mfu,或耦合到输出队列。在一个示例中,控制信号可以是从对应于神经功能单元(nfu)的指令解码器接收的信号。mux的输出还可以耦合到lvrf1010,以用于存储与示例mfu执行的各种运算相对应的中间值。在一个示例中,可以与管线相邻的控制处理器可以具有指令的队列,并且它可以将指令动态地写入nfu的各种组件的相关队列中。在执行指令时,它们可以扇出到独立的控制队列中,并且它们可以确定激活nfu的哪个部分。nfu的组件中的每个组件可以访问控制队列的头部,并且相应地执行例如相加、相乘、正切、sigmoid或nop运算。控制队列可以不出列,直到所有向量已经穿过,并且然后控制队列可以传递到下一组件。虽然图10示出了以特定方式布置的特定数目的mfu1000的组件,但是可以存在更多或更少数目的、被不同地布置的组件。作为示例,mfu1000可以包括用于执行其他运算的附加硬件块,其他运算诸如是softmax运算、整流线性单元(relu)运算、激活块运算等。就与包括nfu的节点相关的一个示例指令集架构(isa)而言,指令可以总是以程序顺序执行。另外,所有指令可以作用于本机大小hwvec_elems的向量和/或矩阵。isa可以用于暴露分布式存储器系统和nfu管线中可用的大规模管线并行性。在一个示例中,可以通过将两个或更多个指令明确地标识为链的成员来利用该并行性。示例链可以使用矩阵-向量相乘、向量-向量相加和向量sigmoid的指令来配置跨度mvu和两个mfu的管线,以并行执行所有三个指令。在一个示例中,指令可以在以下情况下时具有作为链的资格:一系列相关指令;至多一个输入和至多一个输出需要全局存储器;所有其他参量仅依赖于中间值和本地存储器的内容,并且nfu的每个功能单元以管线顺序被使用并且最多被使用一次。在一个示例中,程序可以被编译或构造成尝试将尽可能多的指令链接在一起以最大化性能。可以通过在第一指令的目的地参量中断言forward标志,并且通过在第二指令中断言接收标志代替源地址参量,来将一对指令链接在一起。链继续,直到指令没有断言forward,或者nfu中的所有功能单元已经在链中被使用。因此,在该示例中,以下是非法的:在一个指令中断言forward并且然后在下一指令中不断言接收(反之亦然)。指令可以通过它们的资源要求而被映射到nfu的功能单元。例如,矩阵-向量相乘只能在矩阵-向量单元(mvu)中进行,而向量-向量相加只能在多功能单元(mfu)中进行。在该示例中,指令链必须以图4中所示的从左到右的管线顺序(输入队列(iq)、mvu、然后是每个mfu、然后输出队列(oq))使用nfu的功能单元。但是,在一个示例中,链可以从iq、mvu或第一个mfu开始。最后,在该示例中,需要mfu的链中的第一指令将被映射到mfu0,下一指令将使用mfu1等。在该示例中,这很重要,因为由mfu指令使用的本地存储器由链中的该指令的深度来隐式设置,以用于存储和加载。大多数指令可以采用相同的一般的一组参量:源、目的地和可选的第二源。可能还存在可以具体标识目标mfu的一些存储器管理指令,但是通常,从指令在链中的位置推断出将执行指令的mfu。每个源和目的地参量可以使用下面表3中的强类型中的一个。例如,dst参量意味着指令的输出可以被转发、全局存储或本地存储,而gdst参量只能被全局存储。在该示例中,只有采用gsrc的指令可以被附加到链中,并且只有提供dst的指令可以将数据在链中传递下去。通常,大多数指令可以在链中被使用或以独立模式(全局源和全局目的地)被使用。但是,在该示例中,存储器管理指令(以vrf_开始的那些指令)不能在链内被使用,并且一些指令(v_pass、v_store)只能在链内被使用。表3节点服务可以使用应用编程接口(api)与包括控制/标量处理器(csp)和nfu的每个节点通信。api可以用于向nfu发送指令并且接受/制定对网络的请求/响应。节点服务可以从网络接收请求、利用来自请求的参量启动子例程,并且然后通过网络发送回响应。在该示例中,请求可以包括由csp解释的节点报头以及被转发到nfu的有效载荷。同样,传出响应可以具有节点报头和(可选的)有效载荷。针对节点的编程模型可以允许子例程占用多达30个运行时参量。这些参量可以通过节点报头作为“辅助数据”被传递到子例程中。在一个示例中,可以保留aux[0]以用于选择子例程。在一个示例中,对于运行时参量的一个常见用途是针对给定lstm评估设置迭代次数。每个子例程可以是执行矩阵和向量运算的一系列api调用。这些api调用中的每个api调用可以对应于nfu指令,并且当csp遇到这些api调用中的一个api调用时,它可以将该指令发送到nfu。在一个示例中,所有指令可以作用于维度为hwvec_elems的向量和维度为hwvec_elems×hwvecv_elems的矩阵。一组协助函数(如下面的表4所示)可以用于在参量中设置适当的位字段:表4另外,可以使用三个协助常数,如下面的表5中所示:next仅设置dst的forward标志prev仅设置gsrc的receive标志acc仅设置dst的store标志(仅与mv_mulapi一起使用)表5子例程中的一个子例程可以是环回,其将向量从输入队列取到nfu中并将其存储在全局存储器中,然后从全局存储器读取它并将其发送出nfu通过输出队列。示例环回子例程如下面的表6中所示:表6可以通过在将输入向量发送回之前,对输入向量执行逐元素的sigmoid来扩展环回示例。实现此的一种方式是在独立模式下调用输入向量、sigmoid和输出向量api,如下面的表7中所示:表7上面的表7中的示例没有使用任何指令链接,但是可以通过将所有三个运算链接在一起来实现更高的性能。为了实现链接,对输入队列、执行sigmoid的mfu和输出队列之间的数据流进行分析。关于图4中的示例nfu,链需要将数据传递通过管线中的mvu和其他4个mfu。链接使用较少的周期,因为,作为示例,它避免了进行通过全局存储器的多次往返,这在时间消耗方面可能是昂贵的操作。下面的表8示出了使用链接优化的子例程的一个示例。表8第二种方法使用更多的指令,但也以显著更少的周期执行。注意,第二种方法在初始使用后丢弃输入向量和输出向量。如果需要存储这些值以供之后的使用,则可以使用表9中的子例程4。表9用于将两个向量相加的过程建立在用于获取向量的sigmoid的过程上。主要区别在于相加需要第二输入向量,在一个示例中,该第二输入向量必须始终来源于执行该相加的mfu的本地存储器。在该示例中,如果第二操作数尚未存在于本地存储器中,则需要另一指令(例如,vrf_g_i_copy)将其放置在本地存储器中。假设表9的子例程4已经执行并且已经在全局地址0中存储了一个向量,并且在mfu0的本地地址中的该向量的sigmoid是0,则下面的api调用会将这两个向量相加在一起,并将结果存储回全局存储器中。表10如前面所讨论的,被使用处理组件的程序使用的任何矩阵在启动时被预加载,因为在该示例中,需要o(hwvec_elems2)个周期来存储来自节点外部的矩阵,而每个其他运算需要o(hwvec_elems)个循环。还可能需要预加载一组偏置向量,其在整个执行期间保持恒定。以下示例子例程将两个权重矩阵存储在矩阵存储器(mvu内的矩阵寄存器文件)中。然后它加载两个偏置向量,一个放入mfu1的本地存储器中,一个放入mfu2中。表11通过使用具有指令链接的示例子例程,可以提高向量加载的性能,如下面的表12中所示。表12在预加载矩阵和向量之后,表13是说明执行v_out=(m[0]*v_in[2]+m[1]*v_in[3]+v_in[0])*v_in[1]的示例子例程的示例。因此,在该示例中,假设已经调用子例程6来预加载m[0]、m[1]、v_in[0]和v_in[1]。表13在一个示例中,mvu特征可以用于优化表13的子例程8的资源利用,其使用mfu0对两个mv_mul()结果进行累加。mvu允许将矩阵-向量乘法的结果保持在其累加寄存器中而不是将向量输出。如果针对mv_mul启用了该特征(通过断言store标志),则下一mv_mul的结果将与第一个的结果累加。在该示例中,为了使该优化工作,如下面的表14中所示,可以调整子例程6以在mfu0和mfu1中存储v_in[0]和v_in[1]。下面的表15示出了使用链接的优化的矩阵-向量子例程。表14表15通过使用编码和编译器技术,可以对子例程进行附加的改进,该编码和编译器技术避免经硬编码的地址,并且用具有良好命名的常量来暴露地址的意图。另外,可以提供typedef,以分别利用vectornum、matrix和mfu标识向量、矩阵和mfu地址。为确保编码的一致性,可以使用下面的表16中所示的样式:表16在该示例中,下面的表17中所示的某些地址必须被设置为节点的分布式存储器中的物理地址:1.constvectornumb_0=0;2.constvectornumb_1=1;3.constvectornummfu0_b_0=0;4.constvectornummfu0_b_1=1;5.constmatrixm0=0;6.constmatrixm1=1;7.constmfumfu0=0;8.constmfumfu1=1;9.constmfumfu2=2;10.constmfumfu3=3;11.constmfumfu4=4;表17作为示例,用于具有csp和nfu的节点的lstm评估程序可以包括预加载步骤,之后是评估的若干次迭代,直到输出被创建。因此,在该示例中,首先,预加载步骤跨nfu的分布式存储器存储评估所需的权重矩阵和偏置向量。接下来,对于评估的每次迭代,输入向量到达并且通过越来越长的指令链被处理,直到输出被创建。图11示出了根据一个示例的用于神经网络评估的数据流图1100。在该示例中,在高级别,一个输入向量(iq_v)被加载并且与两个权重矩阵相乘(mv_mul1和4)。历史向量也与另外两个权重矩阵相乘(mv_mul2和3)。接下来,将一对输入/历史结果累加在一起,另外一对输入/历史结果也是如此(vv_add1和3)。之后,每个和向量与偏置向量相加(vv_add2和4),然后被应用于sigmoid(v_sigm1和2)。然后将sigmoid结果相乘在一起,并且结果是最终的输出(vv_mul和oq_v)。对该数据流图的依赖性分析示出了存在4条指令链的机会。可以使用编译器或类似的工具来执行依赖性分析。例如,链a(经由图11中的虚线示出)从输入队列获取其向量输入、将该向量存储在gvrf中、并且然后使用它与本地存储器中的矩阵执行mv_mul1。mv_mul的结果也被存储在本地存储器中。在该示例中,链b(经由图11中的虚线示出)可以紧跟链a通过管线,因为它从全局存储器获取一个输入(历史向量)、从本地存储器获取矩阵以进行mv_mul2、与本地存储器中的预加载的偏置向量相加以进行vv_add1,并且与被本地存储的mv_mul1的结果相加以进行vv_add2,并且对vv_add2的结果执行v_sigm1。v_sigm的结果也被存储在本地存储器中,以有助于链d(经由图11中的虚线示出)。来自图11的示例数据流图可以在以下的示例子例程中、以优化的方式实现,示例子例程包括用于lstm初始化的子例程11和用于lstm评估的子例程12。表18表19图12示出了根据一个示例的神经功能单元对指令链的示例处理1200。另外,参考图12,其示出了子例程12的总执行时间的近似图。如前面所解释的,在指令链(链a-d)被控制处理器(例如,图3的控制/标量处理器)映射之后,指令以管线化方式从左到右地(例如,在图4中所示的包括mvu和5个mfu的管线)被处理。因此,链a包括在输入向量被加载到对应于mvu的矩阵寄存器文件之后对mv_mul1指令的处理。链b包括mvu和mfu0对指令mv_mul2和w_add1的并行处理。同时,使用例如mfu1和mfu2处理w_add2和v_sigm1。链c(其仅包括一个指令mv_mul3)由mvu处理。最后,链d由整个管线处理。mvu同时处理mv_mul4和w_add3,并且mfu并行地处理链d中的其余指令,包括两个指令v_pass,其仅将从先前的mfu接收到的输入传递到下一mfu或输出队列(oq)。在该示例中,总执行时间主要由mv_mul指令驱动,而其他向量运算都被管线化到mv_mul。并且w_add1和w_add3在mvu的累加寄存器内进行。在另一lstm实施方式中,在由nfu处理向量数据和标量数据之前执行两个附加步骤。第一,使用循环以针对由每个请求提供的迭代的次数展开lstm。第二,使用矩阵分块以将算法矩阵和向量大小映射到可以具有不同的本机大小的处理器。在该示例中,我们具有250的hwvec_elems,而算法输入向量的大小为200,其余算法向量的大小为500,算法输入矩阵为500×200,并且算法历史矩阵为500×500。因此,输入矩阵-向量相乘被分块为两个mv_mul()调用(使用一些零填充),而历史矩阵-向量相乘被分块为四个mv_mul()调用和两个vv_add()调用。作为该示例的一部分,存在三个子例程:一个用以初始化一组矩阵,一个用以初始化偏置向量,并且一个用以对一组向量执行lstm评估。作为示例,在启动时,一个使用场景将是调用对8个矩阵的矩阵初始化(例如,表20中的子例程13)三次,以加载24个矩阵,然后调用偏置向量初始化(例如,表21中的子例程14)一次。然后,在该示例中,在运行时,将针对每个查询调用lstm评估(例如,表22中的子例程15)。表20表21表22虽然上述子例程示例提供了用以说明各种实施例的相应的指令集,但是相应的指令集可以包括更多或更少的指令。另外,这些指令可以以不同的顺序执行。另外,虽然描述了用于配置或控制节点的各个方面和由节点进行的处理的若干参数,但是这些参数仅是示例。附加的或更少的参数可以与本公开中讨论的示例的不同版本一起使用。图13示出了根据一个示例的用于神经网络评估的数据流图1300。数据流图1300包括四个指令链:链1、链2、链3和链4。链1包括在运行时输入向量(例如,x)和对应于神经网络模型的权重(例如,w_xi,其可以对应于神经网络模型)之间执行矩阵相乘运算。链1还包括在输入向量的过去值(例如,h_prev)和历史权重(例如,w_hi)之间执行矩阵相乘运算。可以使用向量的逐点相加对乘法输出进行相加。接下来,作为链1的一部分,可以执行sigmoid运算。作为链2的一部分,可以在遗忘门权重矩阵(例如,w_xf)和运行时输入向量(例如,x)之间执行矩阵相乘运算。链2还包括在输入向量的过去值(例如,h_prev)和历史遗忘门权重矩阵(例如,w_hf)之间执行矩阵相乘运算。可以使用向量的逐点相加对乘法输出进行相加。接下来,作为链2的一部分,偏置输入向量(例如,b_i)可以与加法运算的输出相加。接下来,作为链2的一部分,可以执行sigmoid运算。现在转向链3,作为链3的一部分,可以在单元门权重矩阵(例如,w_xc)和运行时输入向量(例如,x)之间执行矩阵相乘运算。链3还包括在输入向量的过去值(例如,h_prev)和历史单元门权重矩阵(例如,w_hc)之间执行矩阵相乘运算。可以使用向量的逐点相加对乘法输出进行相加。接下来,作为链3的一部分,偏置单元门向量(例如,b_c)可以与加法运算的输出相加。接下来,作为链3的一部分,可以执行双曲线函数运算。关于链4,可以在输出门权重矩阵(例如,w_xo)和运行时输入向量(例如,x)之间执行矩阵相乘运算。链4还包括在输入向量的过去值(例如,h_prev)和历史输出门权重矩阵(例如,w_ho)之间执行矩阵相乘运算。可以使用向量的逐点相加对乘法输出进行相加。接下来,作为链4的一部分,可以将偏置输出门向量(例如,b_o)与加法运算的输出相加。接下来,作为链4的一部分,可以执行sigmoid运算。可以对四个链的输出执行附加运算。尽管图13示出了使用特定数目的链执行的特定数目的运算,但是可以使用不同数目的链来执行附加的或更少的运算。图14示出了根据一个示例的如何使用硬件节点(例如,fpga)处理指令链的图。可以使用与前面描述的硬件节点相对应的架构来实现示例处理1400。如经由处理方面1410所示,控制处理器(例如,图3的控制/标量处理器320)可以被配置成接收和解码从队列接收的指令。作为处理方面1410的一部分,所接收的指令被处理,使得它们扇出到独立的控制队列中,诸如图14中所示的作为框1410的一部分的各种队列。在一个示例中,独立控制队列可以确定神经功能单元的哪个部分(例如,前面描述的nfu中的任一个)被激活。处理单元中的每个处理单元(包括mvu和mfu)将看到与该单元相关联的控制队列的头部。在该示例中,具有用于各种处理元件的独立控制队列可以允许在一个链的输入不依赖于来自另一链的输出的程度上并行地处理指令链。另外,关于mfu,将基于由相应的控制队列发起的相应的控制信号来激活各种多路复用器、控制门或其他类似结构。作为示例,当控制输入去往mfu的加法块的多路复用器被允许以传递通过输入时,mfu的加法块可以经由被输入到硬件节点的比特流来接收输入。在一个示例中,比特流可以表示查找表的内容及其连接。将数据输入到加法块的队列可以不被出列,直到所有向量都已通过。在执行相应的链期间生成的中间输出可以被存储在与相关的mvu或mfu相对应的本地向量寄存器文件中。然后,来自相应的链的后续指令可以获取该值以进行进一步消耗。大多数指令可以包括一组参量:源、目的地和可选的第二源。每个源和目的地参量可以使用前面描述的表4中的一种参量类型。作为示例,dst参量意味着指令的输出可以被转发、全局存储或本地存储,而gdst参量意味着指令的输出只能被全局存储(例如,作为相关的gvrf寄存器的一部分)。在一个示例中,只有可以从gsrc获取输入的那些指令才可以被附加到链,并且只有可以提供dst参量的那些指令可以将数据传递下去到另一链。参考图14中所示的示例,在与决策框1420处的指令相关联的操作码被解码之后,则可以确定该指令是以哪个目标功能单元为目标。如果指令以输入队列(iq_v(框1412))为目标,并且参量是dst(框1422),则硬件节点逻辑可以通过输入队列进入dst而将下一向量移动到nfu中(框1424)。如果与指令相关联的参量是gdst(全局dst),则可以根据与gdst相关联的地址将下一向量移动到全局寄存器中。如果与指令相关联的参量是ldst(本地dst),则可以根据与ldst相关联的地址将下一向量移动到本地寄存器中。如果与指令相关联的参量是fgdst,则可以根据与fgdst相关联的地址将下一向量移动到全局寄存器中。继续参考图14,如果指令以矩阵-向量乘法单元(mvu)为目标(例如,mv_mul(框1414)),则与硬件节点相关联的逻辑可以采取与矩阵相乘相关联的步骤,该矩阵从寄存器或指定地址获得。mv_mul指令可以包括将在msrc处的矩阵与来自gsrc的向量相乘并将其递送给dst。本地存储可以在累加寄存器中进行,并且与转发互斥。关于向量数据的源,作为框1432的一部分,与硬件节点相关联的逻辑可以确定数据的源是gsrc还是来自另一矩阵乘法运算的输出(框1438)。取决于源,可以将向量数据提供给mvu。备选地,如果向量数据的源是特定地址(例如,op#2x21(框1436)),则可以从该源加载向量数据并将其提供给mvu。另外,关于向量数据的目的地,如果与指令相关联的参量是gdst(全局dst),则可以根据与gdst相关联的地址将下一向量移动到全局寄存器中。中间结果可以被本地存储在累加器(acc)中。有利地,在一个示例中,结果不被存储为中间结果,而是它们可以被直接转发到下一mvu(如框1440中所示)。如果与指令相关联的参量是fgdst,则可以根据与fgdst相关联的地址将下一向量移动到全局寄存器中。仍然参考图14,如果指令是sigmoid运算(v_sigm(框1416))并且因此它以mfu中的一个mfu为目标,则与硬件节点相关联的逻辑可以确定以mfu中的哪一个mfu(例如,mfu#0、mfu#1、mfu#2、mfu#3或mfu#4)为目标(框1452)。在该示例中,如图14中所示,该指令以mfu#0为目标来进行sigmoid运算。作为框1460的一部分,可以通过与硬件节点相关联的逻辑来进行附加处理。作为示例,在框1462处,与硬件节点相关联的逻辑可以确定数据的源是gsrc还是来自另一源的输出(框1438)。取决于源,可以从gsrc或其他源提供向量数据(框1466)。可以对向量数据(例如,从gsrc获得的)执行逐点sigmoid运算并将其递送到dst。在框1464处,与硬件节点相关联的逻辑可以确定输出的目的地。可以向框1468中列出的目的地中的任一个提供数据。尽管图14示出了与以特定方式链接的指令有关的特定的一系列动作,但是可以执行其他动作。另外,数据可以从图14中描述的之外的其他源获得,并且可以被提供给图14中描述的之外的其他目的地。图15示出了根据一个示例的用于评估神经网络的方法的流程图1500。在一个示例中,可以使用之前描述的系统和节点来执行该方法。作为示例,方法可以包括评估系统中的神经网络模型,该系统包括经由网络互连的多个节点,其中每个节点可以包括多个区块。在一个示例中,节点可以是之前描述的任何节点。例如,每个节点可以包括关于图1至图10描述的组件。区块可以是关于图8和图9描述的区块。作为示例,片上存储器可以对应于关于图6和图9描述的sram。计算单元可以对应于关于图6和图9描述的12-输入点积单元。方法可以包括以下步骤(例如,步骤1510):该步骤包括经由入口树接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数,并且m是等于或大于8的整数。作为示例,可以经由关于图1描述的数据中心网络和关于图2描述的接口来接收系数。方法还可以包括以下步骤(例如,步骤1520):该步骤包括将n乘m系数矩阵的第一行存储在第一片上存储器中,并且将n乘m系数矩阵的第二行存储在第二片上存储器中,该第一片上存储器被并入多个区块中的第一区块内,该第二片上存储器被并入多个区块中的第二区块内。将系数存储到片上存储器中可以包括:将系数加载到之前关于图6和图9描述的sram(或bram)中。下一步骤(例如,步骤1530)可以包括:使用第一计算单元来处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量,该第一计算单元被并入多个区块中的第一区块内。计算单元可以是之前描述的点积单元。n乘m系数矩阵可以包括对应于神经网络模型的权重。第一组输入向量和第二组输入向量中的每组输入向量包括输入向量的运行时值和输入向量的过去值,如之前关于神经网络模型的评估所描述的。下一步骤(例如,步骤1540)可以包括:使用第二计算单元来处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量,该第二计算单元被并入多个区块中的第二区块内。计算单元可以是之前描述的点积单元。n乘m系数矩阵可以包括对应于神经网络模型的权重。第一组输入向量和第二组输入向量中的每组输入向量包括输入向量的运行时值和输入向量的过去值,如之前关于神经网络模型的评估所描述的。总之,本公开涉及一种用于评估系统中的神经网络模型的方法,该系统包括经由网络互连的多个节点,其中每个节点包括多个区块。方法可以包括经由入口树接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8的整数。方法还可以包括将n乘m系数矩阵的第一行存储在第一片上存储器中,并且将n乘m系数矩阵的第二行存储在第二片上存储器中,该第一片上存储器被并入多个区块中的第一区块内,该第二片上存储器被并入多个区块中的第二区块内。方法还可以包括使用第一计算单元来处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量,该第一计算单元被并入多个区块中的第一区块内。方法还可以包括:使用第二计算单元来处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量,该第二计算单元被并入多个区块中的第二区块内。在该示例中,处理第一行还可以包括:对n乘m系数矩阵的第一行和第一组输入向量执行第一逐点点积运算,并且处理第二行还可以包括:对n乘m系数矩阵的第二行和第二组输入向量执行第二逐点点积运算。方法可以包括:经由出口树输出由第一逐点点积运算生成的第一组输出值,该出口树耦合到多个区块中的每个区块,并且经由出口树输出由第二逐点点积运算生成的第二组输出值,该出口树耦合到多个区块中的每个区块。在该示例中,n乘m系数矩阵包括对应于神经网络模型的权重。第一组输入向量和第二组输入向量中的每组输入向量可以包括输入向量的运行时值和输入向量的过去值。在另一示例中,本公开涉及包括多个区块的硬件节点。硬件节点还可以包括入口树,该入口树被配置成接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8的整数。硬件节点还可以包括被并入多个区块中的第一区块内的第一片上存储器,其被配置成存储n乘m系数矩阵的第一行。硬件节点还可以包括被并入多个区块中的第二区块内的第二片上存储器,其被配置成存储n乘m系数矩阵的第二行。硬件节点还可以包括被并入多个区块中的第一区块内的第一计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量。硬件节点还可以包括被并入多个区块中的第二区块内的第二计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量。第一计算单元还可以被配置成:对n乘m系数矩阵的第一行和第一组输入向量执行第一逐点点积运算,并且第二计算单元还被配置成:对n乘m系数矩阵的第二行和第二组输入向量执行第二逐点点积运算。硬件节点还可以包括耦合到多个树中的每个树并且还被配置成输出由第一逐点点积运算生成的第一组输出值的出口树,以及耦合到多个树中的每个树并且还被配置成输出由第二逐点点积运算生成的第二组输出值的出口树。在该示例中,n乘m系数矩阵包括对应于神经网络模型的权重。第一组输入向量和第二组输入向量中的每组输入向量可以包括输入向量的运行时值和输入向量的过去值。在又一示例中,本公开涉及包括多个区块的硬件节点。硬件节点还可以包括入口树,入口树被配置成接收n乘m系数矩阵,其中n乘m系数矩阵被配置成控制神经网络模型,其中n是等于或大于8的整数并且m是等于或大于8的整数,并且其中入口树包括第一入口树寄存器,其扇出到第二入口树寄存器和第三入口树寄存器。硬件节点还可以包括被并入多个区块中的第一区块内的第一片上存储器,其被配置成存储n乘m系数矩阵的第一行。硬件节点还可以包括被并入多个区块中的第二区块内的第二片上存储器,其被配置成存储n乘m系数矩阵的第二行。硬件节点还可以包括被并入多个区块中的第一区块内的第一计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第一行和第一组输入向量。硬件节点还可以包括被并入多个区块中的第二区块内的第二计算单元,其被配置成处理经由入口树接收的n乘m系数矩阵的第二行和第二组输入向量。第一计算单元还可以被配置成:对n乘m系数矩阵的第一行和第一组输入向量执行第一逐点点积运算,并且第二计算单元还被配置成:对n乘m系数矩阵的第二行和第二组输入向量执行第二逐点点积运算。硬件节点还可以包括耦合到多个树中的每个树并且还被配置成输出由第一逐点点积运算生成的第一组输出值的出口树,以及耦合到多个树中的每个树并且还被配置成输出由第二逐点点积运算生成的第二组输出值的出口树。在该示例中,n乘m系数矩阵包括对应于神经网络模型的权重。应当理解,本文中所描绘的方法、模块和组件仅仅是示例性的。备选地或附加地,本文中所描述的功能性可以至少部分地由一个或多个硬件逻辑组件来执行。例如但不限于,可以被使用的说明性类型的硬件逻辑部件包括现场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、片上系统(soc)、复杂可编程逻辑设备(cpld)等。在抽象但明确的意义上,任何实现相同功能性的组件布置都被有效地“关联”,从而实现所需的功能性。因此,本文中被组合以实现特定功能性的任何两个组件都可以被视为彼此“相关联”,使得实现期望的功能性,而与架构或中间组件无关。同样,如此关联的任何两个组件还可以被视为彼此“可操作地连接”或“耦合”以实现期望的功能性。与本公开中所描述的一些示例相关联的功能性还可以包括被存储在非暂态介质中的指令。如本文中所使用的术语“非暂态介质”是指存储数据和/或指令的任何介质,该指令使得机器以特定方式操作。示例性非暂态介质包括非易失性介质和/或易失性介质。非易失性介质例如包括硬盘、固态驱动器、磁盘或磁带、光盘或带、闪存、eprom、nvram、pram或其他这样的介质、或者这样的介质的联网版本。易失性介质包括例如动态存储器,诸如dram、sram、高速缓存或其他这样的介质。非暂态介质不同于传输介质,但可以与传输介质一起使用。传输介质用于传送去往和/或来自机器的数据和/或指令。示例性传输介质包括同轴电缆、光纤电缆、铜线以及诸如无线电波的无线介质。另外,本领域技术人员将认识到,上文所描述的操作的功能性之间的界限仅仅是说明性的。多个操作的功能性可以被组合成单个操作,和/或单个操作的功能性可以被分配在附加操作中。而且,备选实施例可以包括特定操作的多个实例,并且在各种其他实施例中可以更改操作的次序。尽管本公开提供了具体示例,但是可以在不背离如权利要求中阐述的本公开的范围的情况下做出各种修改和改变。因而,说明书和附图被认为是说明性的而非限制性的,并且所有这种修改旨在被包括在本公开的范围内。本文中关于具体示例描述的任何益处、优点或问题的解决方案不旨在被解释为任何或所有权利要求的关键的、必需的或基本的特征或元素。另外,如本文中使用的术语“一”或“一个”被定义为一个或多个。另外,在权利要求中使用诸如“至少一个”和“一个或多个”的介绍性短语不应当被解释为暗示由不定冠词“一”或“一个”对另一权利要求元素的引入将包含这种引入的权利要求元素的任何特定权利要求限制为仅包含一个这种元素的发明,即使当相同的权利要求包括介绍性短语“一个或多个”或“至少一个”以及诸如“一”或“一个”的不定冠词时。对于定冠词的使用也是如此。除非另有说明,否则诸如“第一”和“第二”的术语被用于对这种术语所描述的元件之间的任意区分。因此,这些术语不一定旨在指示这些元素的时间或其他优先化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1