使用特定于上下文的词向量的自然语言处理的制作方法
发明人:b·麦卡恩
熊蔡明
r·佐赫尔
其他申请的交叉引用
本申请要求于2018年5月17日提交的美国专利申请号15/982,841和于2017年5月19日提交的美国临时专利申请号62/508,977,以及于2017年7月25日提交的美国临时专利申请号62/536,959的优先权,其全部内容出于所有目的通过引用并入本文。
本公开总体上涉及神经网络,并且更具体地涉及使用特定于上下文的词向量用于自然语言处理的神经网络。
背景技术:
神经网络作为一种以类人般的准确度自动分析现实世界信息的技术已显示出巨大的希望。通常,神经网络模型接收输入信息并根据输入信息进行预测。例如,神经网络分类器可以预测预定类别集合中的输入信息的类别。而其他分析现实世界信息的方法可涉及硬编码过程、统计分析等,而神经网络则使用机器学习过程通过反复尝试的过程来学习逐步做出预测。给定的神经网络模型可以使用大量训练示例来训练,迭代地进行,直到神经网络模型开始从人类可能做出的训练示例中一致地得出相似的推论。在许多应用中,神经网络模型已经显示出优异的表现和/或具有超越其他计算技术的潜力。实际上,甚至已经确定了神经网络模型超出人类水平性能的某些应用。
附图说明
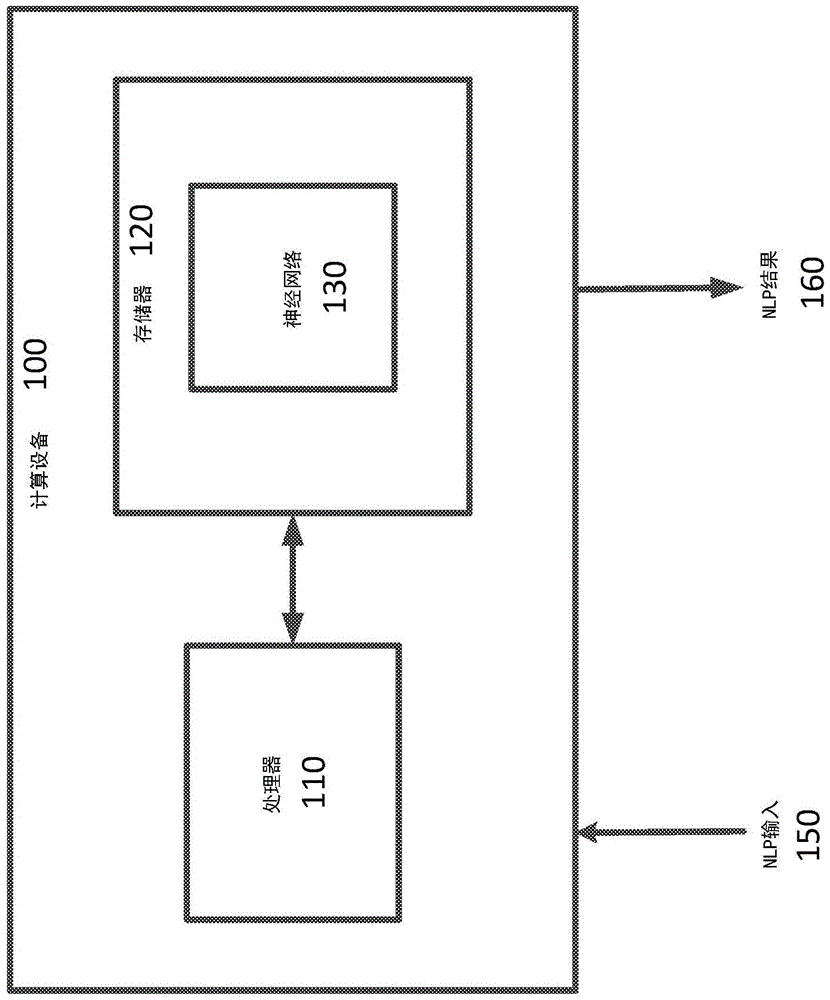
图1是根据一些实施例的计算设备的简化图。
图2是根据一些实施例的用于在第一自然语言处理(nlp)任务上预训练编码器并使用该编码器执行第二nlp任务的方法的简化图。
图3是示出根据一些实施例的编码器的预训练的简化图。
图4示出了词序列的词向量的示例。
图5是示出根据一些实施例的在nlp翻译任务上对编码器的预训练的简化图。
图6是用于在nlp翻译任务上对编码器进行预训练的方法的简化图。
图7是根据一些实施例的用于自然语言处理的系统的简化图。
图8是根据一些实施例的使用在nlp翻译任务上预训练的编码器进行自然语言处理的系统的简化图。
图9和图10是比较基于不同输入编码的自然语言处理系统的性能的简化图。
图11是示出了用于基于不同输入表示的自然语言处理的系统的性能结果的表。
在附图中,具有相同标号的元件具有相同或相似的功能。
具体实施方式
该说明书和附图示出了各方面、实施例、实现或应用,不应被认为是限制性的-权利要求书限定了受保护的发明。在不脱离本说明书和权利要求书的精神和范围的情况下,可以进行各种机械、组成、结构、电气和操作上的改变。在某些情况下,未详细示出或描述公知的电路、结构或技术,因为它们是本领域技术人员所已知的。在两个或更多个图中相似的数字表示相同或相似的元素。
在本说明书中,阐述了描述与本公开一致的一些实施例的具体细节。为了提供对实施例的透彻理解,阐述了许多具体细节。然而,对于本领域的技术人员将显而易见的是,可以在没有一些或所有这些具体细节的情况下实践一些实施例。本文所公开的具体实施方式意在说明而非限制。尽管在这里没有具体描述,但本领域的技术人员可以实现在本公开的范围和精神内的其他元件。另外,为了避免不必要的重复,除非另外特别说明或者如果一个或更多个特征会使一实施例不起作用,否则与一个实施例相关联示出和描述的一个或更多个特征可以结合到其他实施例中。
自然语言处理(nlp)是神经网络可以应用于的一类问题。nlp可用于在理解个体单词和短语的情况下注入新的神经网络。但是,对于nlp中的大多数问题或任务,理解上下文也很重要。例如,翻译模型需要了解英语句子中的单词如何协同工作才能生成德语翻译。同样,摘要模型也需要上下文以了解哪些单词最重要。执行情感分析的模型需要了解如何找到(pickup)改变他人表达的情感的关键词。问题回答模型依赖于对问题中的单词如何转移文档中的单词重要性的理解。因此,期望开发一种为nlp初始化神经网络的方式,同时了解各种单词可能如何与其他单词相关或上下文如何影响单词的含义。
根据一些实施例,通过在第一nlp任务上训练神经网络,例如,通过教神经网络如何从英语翻译成德语来教其如何在上下文中理解单词。然后,经训练的网络可以在执行第二nlp任务(例如分类、问题回答、情感分析、蕴含分类、语言翻译等)的新的神经网络或其他神经网络中重新使用。预训练网络的输出-特定于上下文的词向量(cove),被提供为学习其他nlp任务的新网络的输入。实验表明,向这些新网络提供cove可以提高新网络的性能,从而验证使用已经学会了如何语境化单词的神经网络,可以使各种nlp模型或任务受益。
在一些实施例中,各种nlp模型或任务(例如分类、问题回答、情感分析和翻译)可以通过使用由用nlp任务训练编码器而生成的特定于上下文的词向量来进行改进,该nlp任务可以与要执行的nlp任务不同。一般而言,通过在协同任务之间进行转移和多任务学习已经取得了显著成果。在许多情况下,依赖于相似组件的体系架构可以利用这些协同性。本文公开的实施例使用已经学习如何或被训练以使单词语境化的网络以使其他神经网络在学习理解自然语言的其他部分时具有优势。
图1是根据一些实施例的计算设备100的简化图。如图1所示,计算设备100包括耦合至存储器120的处理器110。计算设备100的操作由处理器110控制。并且尽管示出的计算设备100仅具有一个处理器110,但是应当理解,处理器110可以代表一个或更多个中央处理器、多核处理器、微处理器、微控制器、数字信号处理器、现场可编程门阵列(fpga)、专用集成电路(asic)、图形处理器(gpu)、张量处理器(tpu),和/或计算设备100中的类似物。计算设备100可被实现为独立子系统,被添加到计算设备的板和/或虚拟机。
存储器120可以用于存储由计算设备100执行的软件和/或在计算设备100的操作期间使用的一个或更多个数据结构。存储器120可以包括一种或更多种类型的机器可读介质。机器可读介质的一些常见形式可包括软盘、软磁盘、硬盘、磁带、任何其他磁介质、cd-rom、任何其他光学介质、打孔卡、纸带、任何其他带孔图案的物理介质、ram、prom、eprom、flash-eprom、任何其他内存芯片或盒式磁带、和/或处理器或计算机能从中读取的任何其他介质。
处理器110和/或存储器120可以以任何适当的物理布置来布置。在一些实施例中,处理器110和/或存储器120可以在相同的板上、在相同的封装(例如,系统级封装)、在相同的芯片(例如,系统级芯片)和/或类似物上实现。在一些实施例中,处理器110和/或存储器120可以包括分布式、虚拟化的、和/或容器化的计算资源。与这样的实施例一致,处理器110和/或存储器120可以位于一个或更多个数据中心和/或云计算设施中。在一些示例中,存储器120可以包括非暂时性有形机器可读介质,其包括可执行代码,当可执行代码由一个或更多个处理器(例如,处理器110)运行时,可以使一个或更多个处理器执行本文进一步描述的任何方法。
如所示的,存储器120包括神经网络130。神经网络130可用于实现和/或模拟本文进一步描述的任何神经网络。在一些示例中,神经网络130可以包括多层或深度神经网络。根据一些实施例,多层神经网络的示例包括resnet-32、densenet、pyramidnet、senet、awd-lstm、awd-qrnn和/或类似的神经网络。resnet-32神经网络在he等人于2015年12月10日提交的“用于图像识别的深度残差学习(deepresiduallearningforimagerecognition)”,arxiv:1512.03385中进行了更详细描述。densenet神经网络在iandola等人于2014年4月7日提交的“densenet:实现高效的convnet描述符金字塔(densenet:implementingefficientconvnetdescriptorpyramids)”,arxiv:1404.1869中进行了更详细描述。pyramidnet神经网络在han等人于2016年10月10日提交的“深度金字塔形残差网络(deeppyramidalresidualnetworks)”,arxiv:1610.02915中进行了更详细的描述;senet神经网络在hu等人于2017年9月5日的“挤压和激发网络(squeeze-and-excitationnetworks)”,arxiv:1709.01507中进行了更详细的描述;awd-lstm神经网络在bradbury等人于2016年11月5日提交的“准循环神经网络(quasi-recurrentneuralnetworks)”,arxiv:1611.01576中进行了更详细的描述。它们中的每一个通过引用并入本文。
根据一些实施例,神经网络130可以使用针对第一种类的nlp任务(例如,翻译)而预训练的编码器。计算设备100可以接收训练数据,该训练数据包括第一语言(例如,英语)的一个或更多个词序列,以及第二语言(例如,德语)的一个或更多个对应的词序列,其表示各个第一语言词序列的预期和/或所期望的翻译。为了说明,假设提供给计算设备100的输入词序列包括英语词序列“let'sgoforawalk(让我们去散散步)”。相应的德语词序列是“lassunsspazierengehen”。计算设备100使用该训练数据来生成和输出第一语言的单词或词序列的特定于上下文的词向量或“上下文向量”(cove)。换句话说,通过首先教编码器如何从一种语言翻译成另一种语言(例如,英语到德语)来教其如何理解上下文中的单词。一旦经过训练,编码器就可以被神经网络130用于执行第二种nlp任务-例如,情感分析(斯坦福情感树库(sst)、imdb)、问题分类(trec)、蕴含分类(斯坦福自然语言推断语料库(snli))、问题回答(斯坦福问题回答数据集(squad))和/或类似内容。为此,计算设备100接收用于第二种nlp任务的输入150,并生成用于该任务的结果160。
图2是根据一些实施例的用于在第一nlp任务上预训练编码器并使用该编码器执行第二nlp任务的方法200的简化图。方法200的过程210-220中的一个或更多个可以至少部分地以存储在非暂时性有形机器可读介质上的可执行代码的形式来实现,该可执行代码在由一个或更多个处理器运行时可导致一个或更多个处理器执行过程210-230中的一个或更多个。在一些实施例中,方法200可以由图1的计算设备100执行。
根据一些实施例,方法200利用转移学习或领域自适应。转移学习已应用于研究人员识别独立收集的数据集之间的协同关系的各个领域。在一些实施例中,转移学习的源域是机器翻译。
在过程210中,使用用于执行第一nlp任务的训练数据对神经网络的编码器进行预训练。在一些实施例中,第一nlp任务可以是翻译。翻译任务的性质具有用于训练通用的上下文编码器的吸引人的特性—例如与其他nlp任务(例如,文本分类)相比,翻译似乎需要更一般意义上的语言理解能力。在训练期间,编码器被提供有训练和/或测试数据150,在一些实施例中,训练和/或测试数据150可以包括第一语言(例如,英语)的一个或更多个词序列,以及第二语言(例如,德语)的一个或更多个对应的词序列。训练数据150可以是一个或更多个机器翻译(mt)数据集。机器翻译是适合于转移学习的源域,因为从本质上来说,任务需要模型更如实地再现目标语言的句子,而不会丢失源语言句子中的信息。此外,还有大量的机器翻译数据,其可用于转移学习。实际上,机器翻译训练集比大多数其他nlp任务的训练集要大得多。可能的训练集包括各种英语-德语机器翻译(mt)数据集。例如,wmt2016多模式翻译共享任务(通常称为“multi30k”,在2016年的第一届机器翻译会议论文集,wmt,第543-553页上的specia等人的文章“多模式机器翻译和跨语言图像描述上的共享任务(asharedtaskonmultimodalmachinetranslationandcrosslingualimagedescription)”中进行了更详细的描述,在此通过引用并入本文)是一数据集,由30,000个句子对组成,其简要描述了flickr字幕。由于图像字幕的性质,平均来说该数据集包含的句子比来自更大数据集的句子更短和更简单。为国际口语翻译研讨会准备的机器翻译任务的2016版(在2015年的国际口语翻译研讨会中cettolo等人的“iwslt2015评估活动”中进一步详细介绍,其已通过引用并入本文)是一更大的数据集,由来自转录的ted演讲的209,772个句子对组成,该ted演讲涵盖具有比其他机器翻译数据集更多的交谈语言的广泛主题。wmt2017的新闻翻译共享任务是一大型的mt数据集,包括大约700万个句子对,这些句子对来自网络抓取的数据、新闻和评论语料库、欧洲议会会议记录以及欧盟新闻稿。这三个mt数据集可以分别称为mt-small、mt-medium和mt-large。这些mt数据集中的每一个都使用mosestoolkit(moses工具包)进行了标记,并在2007年的计算语言学协会第四十五届年会论文集的第177-180页中koehn等人的“moses:用于统计机器翻译的开源工具包”中有更详细的描述,,其通过引用并入本文。
编码器为第一语言的单词或序列生成或输出上下文向量(或cove)160。来自在mt-small、mt-medium和mt-large上训练的编码器的上下文向量可以称为cove-s、cove-m和cove-l。神经网络的经预训练的编码器然后可以被重新使用或应用于一个或更多个其他nlp任务。
在过程220中,使用经预训练的上下文编码器为第二nlp任务训练新的或另一个神经网络130。经预训练的编码器的输出—第一语言的单词或序列的上下文向量(或cove)被提供为新的或其他神经网络130的输入,该新的或其他神经网络130学习或执行以相同语言执行的其他nlp任务,例如分类、问题回答、情感分析、其他机器翻译任务等。在一些实施例中,从神经机器翻译(nmt)编码器获得的固定长度表示被转移用于训练。在一些实施例中,输入序列中每个标记的表示被转移用于训练。后一种方法使针对其他nlp任务的预训练上下文编码器的传输与后续的长期短期存储器(lstm)、注意力机制以及通常的期望输入序列的层更直接兼容。另外,这促进了编码器状态之间顺序依存关系的传递。在一些实施例中,在过程220期间不进一步训练经预训练的编码器。
在过程230中,神经网络130用于执行第二nlp任务。计算设备100接收针对第二nlp任务的输入150,并且生成针对该任务的结果160。实验表明,为神经网络130提供来自在第一nlp任务(例如,机器翻译)上预训练的编码器的上下文向量,可以提高其在第二nlp任务(例如,分类、问题回答、情感分析)中的性能。
在此更详细地描述了方法200的每个过程210-230的各方面或实施例。
图3是示出根据一些实施例的编码器310的预训练的简化图。在一些实施例中,编码器310可以包括一个或更多个长期短期存储器(lstm)编码器或由其实现。
编码器310接收训练数据,该训练数据可以是用于第一语言(例如,英语)的一个或更多个词序列的词向量320的形式。深度学习模型不是读取词序列作为文本,而是读取词向量的序列。词向量将语言中的每个单词与数字列表相关联。nlp的许多深度学习模型都依赖于词向量来表示各个单词的含义。
图4示出了词序列“let'sgoforawalk(让我们去散散步)”的词向量的示例。在一些实施例中,在模型被训练用于特定任务之前,将模型的词向量320初始化为随机数列表。在一些实施例中,可以使用通过运行诸如word2vec、glove或fasttext之类的方法所获得的那些对模型的词向量320进行初始化。这些方法中的每一种都定义了一种学习具有有用属性的词向量的方法。前两种方法基于一个假设,即词的含义至少有一部分与使用方式有关。word2vec训练模型以吸收单词并预测局部上下文窗口;模型会看到一个单词并尝试预测其周围的单词。glove采用类似的方法,但它还明确地添加有关每个单词与另一个单词一起出现的频率的统计信息。在这两种情况下,每个单词都由对应的词向量表示,并且训练会迫使词向量之间以与自然语言中该单词的用法相关的方式相互关联。参考图4所示的“let'sgoforawalk”的具体示例,像word2vec和glove这样的算法产生的词向量会与自然语言中经常在其周围出现的词向量相关联。这样“go”的向量就意味着单词“go”出现在诸如“let’s”、“for”、“a”和“walk”之类的单词周围。
返回参考图3,通过使编码器310执行第一nlp任务来对其进行训练,在一些实施例中,该第一nlp任务可以是将第一语言的词序列(例如,“let'sgoforawalk”)机器翻译(mt)成第二语言的相应词序列(例如,“lassunsspazierengehen”)。为了完成该训练,编码器310与解码器330交互以生成翻译340。在一些实施例中,在几个机器翻译数据集上训练lstm编码器。实验表明,用于训练mt-lstm的训练数据量与下游任务的性能呈正相关,例如在将编码器用于或利用于第二nlp任务时。这是将mt用作训练任务的另一个优势,因为用于mt的数据比用于大多数其他受监督的nlp任务的数据更为丰富,并且还表明更高质量的mt-lstm可以携带更多有用的信息。尽管机器翻译似乎与其他nlp任务(例如文本分类和问题解答)无关,但这进一步加强了以下观点:对于具有更强自然语言理解力的模型,机器翻译是很好的候选nlp任务。
虽然图3是高级图,但是图5示出了根据一些实施例的针对机器翻译的nlp任务对编码器310进行预训练的更多细节。并且图6示出了用于预训练图5所示的编码器的对应方法600。
参照图5和图6,方法600从过程602开始。在过程602,第一语言或源语言的词序列wx=[wx1,…,wxn](例如,英语-“let'sgoforawalk”)的词向量320a-e被输入或提供给编码器310。第二语言或目标语言的词序列wz=[wz1,…,wzn](例如,德语-“lassunsspazierengehen”)的词向量540被输入或提供给解码器330。设glove(wx)是与wx中的单词相对应的glove向量的序列,而z是与wz中的单词相对应的随机初始化的词向量的序列。
在一些实施例中,编码器310包括循环神经网络(rnn)或由其实现。rnn是处理可变长度的向量序列的深度学习模型。这使得rnn适合于处理词向量320a-e的序列。在一些实施例中,编码器310可以用一个或更多个长期短期存储器(lstm)编码器510a-e来实现,它们是能够处理长词序列的特定种类的rnn。
在过程604,编码器处理词向量320a-e的序列以生成一个或更多个新的向量520a-e,其每一个被称为隐藏向量。在一些实施例中,编码器310例如利用每个lstm510a-e接收相应的词向量320a-e并输出相应的隐藏向量520a-e来对输入序列进行编码。前向运行编码器310,以便将在输入序列中较早出现的词向量320上操作的lstm编码器510生成的信息传递到在该序列中较晚出现的在词向量320上操作的lstm编码器510。这允许后面的lstm编码器510的隐藏向量合并用于较早的词向量320的信息。在一些实施例中,也后向运行编码器310,使得lstm编码器510a-e可以生成或输出隐藏向量,这些隐藏向量并入了来自序列中较晚出现的单词的信息。这些后向输出向量可以与前向输出向量拼接起来,以产生更有用的隐藏向量。每对前向和后向lstm都可以视为一单元,通常称为双向lstm。双向lstm编码器结合了各个单词之前和之后的信息。在机器翻译上训练的lstm可以称为mt-lstm。第一双向lstm510a在将输出传递给第二lstm510b之前处理其整个序列;第二双向lstm510b执行相同操作,依此类推。每个双向lstm(或bilstm)在每个时间步长i处都将输出生成为作为
h=mt-lstm(gglove(wx)).(1)
对于机器翻译,mt-lstm为注意力解码器提供上下文,该注意力解码器在每个时间步长t处产生输出词
在过程606,利用来自编码器310的最终状态/隐藏向量h520a-e来初始化解码器330。解码器330包括另一神经网络或由其实现,该神经网络在生成或翻译成第二语言或目标语言(例如,德语)句子时参考那些隐藏向量h520a-e。在一些实施例中,像编码器310一样,解码器330可以包括一个或更多个可以是双向的lstm530a-b或由其实现。在时间步长t处,解码器330首先使用两层单向lstm基于先前的目标嵌入(zt-1)和经上下文调整的隐藏状态
从编码器310的最终状态h初始化第一个解码器lstm530a,并读取特殊的德语词向量540a以开始。
在过程610中,从第一语言的序列中选择单词。在一些实施例中,注意力机制560向隐藏向量520a-e回看,以便确定接下来要翻译第一语言(例如,英语)句子中的哪个单词。注意力机制560计算表示每个编码时间步长与当前解码器状态的相关性的注意力权重α的向量。
在过程612,注意力机制560生成新的向量570,向量570可以被称为经上下文调整的状态。注意力机制560使用权重α作为注意力总和的系数,该注意力总和与解码器状态拼接并通过tanh层以形成经上下文调整的隐藏状态
换句话说,注意力机制560使用解码器状态向量550a来确定每个隐藏向量520a-e的重要性,并且然后产生经上下文调整的状态570以记录其观察。
在过程614中,生成器580查看经上下文调整的状态570,以确定要输出的第二语言(例如,德语)的单词。经上下文调整的状态570被传递回下一个lstm540,以使其对已经翻译的内容具有准确的感觉。输出单词的分布是通过经上下文调整的隐藏状态的最终转换生成的:
在过程616中,确定第一语言的当前单词是否是序列中的最后单词。如果不是,则解码器330重复过程610-616,直到它已经完成生成第二语言的翻译的词序列为止。
在一些示例中,训练编码器310的mt-lstm使用固定的300维的词向量,例如用于英语词向量的commoncrawl-840bglove模型。这些词向量在训练期间是完全固定的,因此mt-lstm学习如何使用预训练的向量进行翻译。所有mt-lstm中lstm的隐藏大小为300。由于所有mt-lstm是双向的,因此它们输出600维的向量。可以用随机梯度下降来训练编码器310,其学习速率从1开始,并且其在验证困惑度首次增加之后每个时期(epoch)衰减一半。比率为0∶2的丢弃度可应用于编码器310和解码器330的所有层的输入和输出。
当训练结束时,可以使用预训练的编码器来改善针对自然语言处理(nlp)中的其他任务而训练的神经模型的性能。可以提取针对机器翻译被训练作为编码器的lstm510,并将它们的学习转移到下游nlp任务(例如,分类或问题解答)。可以称为mt-lstm的预训练的lstm,可以用于输出第一语言的其他句子或词序列的隐藏向量。在被用作另一个nlp模型的输入时,这些机器翻译隐藏向量提供或用作特定于上下文的词向量或“上下文向量”(cove)。如果w是词序列,并且glove(w)是由glove模型产生的相对应的词向量序列,则:
cove(w)=mt-lstm(glove(w))(5)
是由mt-lstm产生的上下文向量序列。返回参见图5,例如,glove(w)对应于320a-e,并且cove(w)对应于520a-e。在一些实施例中,对于下游的nlp任务,对于输入序列w,可以将glove(w)中的每个向量与其在cove(w)中的对应向量拼接起来以产生向量序列(w):
计算设备(例如计算设备100)的一些示例可以包括非暂时性有形机器可读介质,该介质包括可执行代码,当可执行代码由一个或更多个处理器(例如,处理器110)运行时,可导致一个或更多个处理器来执行方法600的过程。可包括方法600的过程的机器可读介质的一些常见形式例如是软盘、软磁盘、硬盘、磁带、任何其他磁介质、cd-rom、任何其他光学介质、打孔卡、纸带、带孔图案的任何其他物理介质、ram、prom、eprom、flash-eprom、任何其他存储芯片或盒式磁带和/或与处理器或计算机可从其读取的任何其他介质。
图7是示出根据一些实施例的用于自然语言处理的系统700的简化图。系统700包括一个或更多个编码器710,其在第一nlp任务(例如,如本文所述的机器翻译)上被预训练,并且现在作为新模型的一部分被重新使用。在一些实施例中,每个编码器710与编码器310一致。在一些实施例中,每个编码器710包括一个或更多个预训练的mt-lstm或由其实现。预训练的编码器710能够提供或从输入词向量720生成上下文向量(cove)。
可以使用通过运行诸如word2vec,fasttext或glove之类的方法所获得的词向量来初始化模型的词向量720,每种方法都定义了一种学习具有有用属性的词向量的方法。在一些实施例中,在模型被训练用于特定任务之前,将模型的词向量720初始化为随机数列表。
系统700还包括用于执行第二种特定的nlp任务的神经模型730,所述第二个特定的nlp任务例如情感分析(斯坦福情感树库(sst)、imdb)、问题分类(trec)、蕴含分类(斯坦福自然语言推断语料库(snli))、问题回答(斯坦福问题回答数据集(squad))和/或类似内容。在一些实施例中,神经模型730与模型130的神经网络一致。向神经模型730提供来自预训练的编码器710的上下文向量(cove)。在一些实施例中,来自编码器710的上下文向量(cove)可以被附加或拼接词向量720(例如,glove),词向量720通常被用作这些种类的神经模型(参见方程6)的输入,并将结果提供给神经模型730。与仅使用预训练的词向量的基线模型的性能相比,该方法改进了用于下游任务的神经模型730的性能。通常,上下文向量(cove)可以与将其输入表示为向量序列的任何神经模型730一起使用。实验表明了使用预训练的mt-lstm为执行nlp任务(例如,文本分类和问题回答模型)的神经模型生成上下文向量(cove)的优势。对于斯坦福情感树库(sst)和斯坦福自然语言推理语料库(snli),上下文向量(cove)的使用将基线模型的性能推向了最新水平。
图8是示出根据一些实施例的、使用在nlp翻译任务上进行预训练的一个或更多个编码器810进行自然语言处理的系统800的图。在一些实施例中,每个编码器810与编码器310、710一致。系统800可以包括用于执行特定nlp任务(例如,问题分类(trec)、问题回答(squad)、情感分析(sst,imdb)、蕴含分类(snli)等)的多层神经网络或神经模型830或由其实现,该特定nlp任务与nlp翻译任务不同。在一些实施例中,神经模型830与神经模型130、730一致。
可以使用合适的数据集针对特定的nlp任务训练系统800的神经模型830。例如,针对问题分类训练神经模型830可以使用开放域、基于事实的问题的小型trec数据集,该数据集被划分为广泛的语义类别,如voorhees等人在第八届文本检索会议,第1999卷,第83页的“thetrec-8问答路径评估(thetrec-8questionansweringtrackevaluation)”中所详细描述的,其通过引用并入本文。该数据集可以是trec的五十类或六类版本,分别称为trec-50和trec-6。两者都有4300个训练示例,但是trec-50具有更细粒度的标签。对于问题回答,可以使用斯坦福问题回答数据集(squad)训练神经模型830,如rajpurkar等人在2016年6月16日提交的“squad:用于文本的机器理解的100,000多个问题(squad:100,000+questionsformachinecomprehensionoftext)”,arxiv预印本arxiv:1606.05250中所详细描述的,其通过引用并入本文。squad是具有87,599个训练示例和10,570个开发示例的大规模问答数据库。示例包括英语维基百科的一段以及该段上的相关问答对。squad示例假定该问题是可以回答的,并且答案是逐字包含在段落中的某个位置。对于情感分析,可以在两个情感分析数据集上分别训练神经模型830:斯坦福情感树库(sst)(如socher等人在2013年的《自然语言处理中的经验方法》中“情感树库上语义组成的递归深层模型(recursivedeepmodelsforsemanticcompositionalityoverasentimenttreebank)”中所详细描述的,其通过引用并入本文)和imdb数据集(如maas等人在“学习用于情感分析的词向量(learningwordvectorsforsentimentanalysis)”,美国计算语言学协会第49届年会论文集:人类语言技术,第142-150页,俄勒冈州波特兰,美国,2011年6月。计算语言学协会。urlhttp://www.aclweb.org/anthology.p11-1015]中所详细描述的,其通过引用并入本文)。这两个数据集都包含电影评论及其情感。每个数据集的二进制版本以及sst的五类版本都被使用。imdb包含22,500个多句评论,每个评论都可以被截断为前200个单词。sst-2包含删除了“中性”类并包括了所有子树的56,400个示例,并且sst-5包含具有所有类和子树的94,200个评论。对于情感,可以用斯坦福自然语言推理语料库(snli)训练神经模型830,如bowman等人在2014年6月6日提交的“用于学习逻辑语义学的递归神经网络(recursiveneuralnetworksforlearninglogicalsemantics)”,arxiv预印本arxiv:1406.1827中所详细描述的,其通过引用并入本文。snli拥有550,152个训练、10,000个验证和10,000个测试示例。每个示例都包含前提、假设和标签,该标签指定前提是否与假设相关、相矛盾或中立。
如图8所示,系统800包括用于通用双注意力分类网络(bcn)的神经模型830。该模型830被设计为处理单序列和双序列分类任务两者。在单序列任务的情况下,输入词序列被复制以形成两个序列。
在预训练的编码器810处将两个输入序列wx和wy作为词向量820(例如,glove(w))提供给系统800。在一些实施例中,每个编码器810与编码器310、710一致。在nlp机器翻译任务上预训练编码器810,从而从输入词向量820提供或生成相应的上下文向量(cove)(w)。在一些实施例中,将每个词向量820(例如,glove(w))拼接或附加其相应的上下文向量(cove)(w)来生成向量序列
使用预训练的编码器810来训练神经网络或模型830。在一些实施例中,当训练神经网络或模型830时不进一步训练编码器810。
模型830包括一个或更多个整流器线性单元(relu)832,其接收输入向量序列
这些序列均沿时间轴堆叠以生成矩阵x和y。
为了计算相互依赖的表示,模型830使用了双注意力机制836,如seo等人在“用于机器理解的双向注意力流”,国际学习表示会议,2017年,以及xiong等人在“用于问答的动态协同注意力网络(bidirectionalattentionflowformachinecomprehension)”,国际学习表示会议,2017年中所详细描述的,两者均通过引用并入本文。双注意力将每个表示彼此作为条件。
在神经模型830中使用双注意力机制836提供了一个优势,例如在某些nlp分类任务(例如蕴含分类和情感分析或分类)中。蕴含分类涉及针对其可能存在某种形式的关系的两个词序列的处理-例如确定一个序列是否为真需要另一序列,确定一个序列是否为真需要另一序列的否定,或者确定一个序列是否为真允许另一序列为真或假。蕴含分类的序列的示例可以是:(wx)“twowomenarediscussingcircuit(两个女人在讨论电路)”,和(wy)“twopeoplearediscussingtechnology(两个人在讨论技术)”。在此示例中,序列wx蕴含序列wy。情感分类旨在确定说话者或词序列的作者对某话题的态度或情感。可以将这些序列中的每一个提供给神经模型830中的相应通道(例如,作为relu832的输入)。蕴含分类的序列的示例可以是:(wx)“thismoviewasawasteoftime(这部电影浪费时间)”。可以重复该序列并将其提供给神经模型830中的每个通道。在一些实施例中,双注意力机制836通过将注意力与分类的逐元素特征相结合,来为nlp分类任务产生或获得更好的结果。
双注意力机制836首先计算亲和矩阵a=xyt。然后,双注意力机制836采用逐列归一化提取注意力权重(ax和ay):
ax=softmax(a)ay=softmax(at)(9)
当特定于任务的表示相同(x=y)时,其可以是一种自我注意的形式。接下来,双注意力机制836使用上下文摘要(cx和cy)
来将每个序列彼此作为条件。
两个单独的集成器838针对每个输入序列将调节(conditioning)信息(从双注意力机制836生成)集成到特定于任务的表示(x和y)中。在一些实施例中,每个集成器838可以包括一层bilstm或由其实现。bilstm对原始表示的拼接(以确保调节过程中不会丢失任何信息)、它们与上下文摘要的差异(cx和cy,以明确捕获与原始信号的差异)以及原始文档与上下文摘要(以放大或衰减原始信号)的逐元素乘积进行操作。
x|y=bilstm([x;x-cy;x⊙cy])(11)
y|x=bilstm([y;y-cx;y⊙cx])(12)
池机制840通过沿时间维度进行池化来聚合集成器838的双向lstm的输出。在一些实施例中,最大池和平均池可用于提取特征。在一些实施例中,已经发现同时添加最小池和无参数形式的自注意池有助于某些任务。每种类型的池在条件序列上捕获不同的视角。自注意池会为序列的每个时间步长计算权重(βx和βy):
βx=softmax(x|yv1+d1)βy=softmax(y|xυ2+d2)(13)
权重(βx和βy)用于获得每个序列的加权总和(xself和yself):
池化表示被合并以获得所有输入的联合表示(xpool和ypool):
xpool=[max(x|y);mean(xy);min(x|y);xself](15)
ypool=[max(y|x);mean(y|x);min(y|x);yself](16)
对于nlp分类任务,提供联合表示或将联合表示输入到maxout层842中。maxout层842可以实现为三层批归一化的(如ioffee等人在“批归一化:通过减少内部协变量偏移来加速深度网络训练(batchnormalization:acceleratingdeepnetworktrainingbyreducinginternalcovariateshift)”,第32届国际机器学习会议论文集,2015中所详细描述的,其通过引用并入本文)maxout网络(如goodfellow等人在“maxout网络(maxoutnetworks)”,第30届机器学习年会论文集,2013中所详细描述的,其通过引用并入本文)以产生可能类别上的概率分布。
如上所述并且在此进一步强调,图8仅仅是用于自然语言处理的系统的示例,其不应不适当地限制权利要求的范围。本领域普通技术人员将认识到许多变化、替代和修改。在一些实施例中,可以修改系统800,使得其执行不同的nlp任务(例如,问题回答)。对于nlp问题回答任务,以与用于分类(方程7和方程8)的相同的方式获得特定于任务的序列x和y,不同之处在于,将函数f替换为使用tanh激活而不是relu激活的函数g。在这种情况下,序列之一是文档,以及另一个序列是问题-文档对中的问题。然后,将这些序列x和y通过被实现为例如动态协同注意力网络(dcn)的协同注意力和动态解码器馈送,如xiong等人在“用于视觉和文本问题回答的动态内存网络(dynamicmemorynetworksforvisualandtextualquestionanswering)”,第33届国际国际机器学习会议论文集,第2397-2406页,2016年中所详细描述的,其在此通过引用并入本文。
图9和图10是比较基于不同输入编码的自然语言处理系统的性能的简化图。这些图9和图10说明了改变输入表示(例如,单独的glove、glove加cove、glove加char以及glove加cove加char)如何影响nlp任务(例如,情感分析、问题分类、蕴含分类和问题解答)的最终性能。
同样,图11是说明基于不同输入表示(sst-2、sst-5、imdb、trec-6、trec-50、snli、squaad)并且具有用于编码器(分别为cove-s、cove-m、cove-l)的不同训练集(分别为mt-small、mt-medium和mt-large)的自然语言处理系统的性能结果的表格。
图9和图10示出了与仅使用glove的模型相比,将cove与glove一起使用实现了更高的性能的模型。图11示出了在方程6中使用cove比使用字符n-gram嵌入(如hashimoto等人在2016年11月5日提交的“联合多任务模型:为多个nlp任务发展神经网络(ajointmany-taskmodel:growinganeuralnetworkformultiplenlptasks)”,arxiv预印本arxiv1611.01587中所详细描述的,其通过引用并入本文)带来了更大的改进。它也表明,通过额外添加字符n-gram嵌入来改变方程6可以进一步提高某些nlp任务的性能。这表明cove提供的信息是对glove提供的词级信息以及字符n-gram嵌入提供的字符级信息的补充。
图9-图11验证了将知识从在机器翻译上预训练的编码器转移到各种其他下游nlp任务的优缺点。在所有情况下,使用上下文向量(cove)的模型的性能均优于使用随机词向量初始化的基线、使用来自glove模型的经预训练的词向量的基线以及同时使用来自glove模型的词向量和字符n-gram嵌入的基线。
尽管已经示出和描述了说明性的实施例,但是在前述公开中设想了各种各样的修改、改变和替换,并且在某些情况下可以在不相应使用其他特征的情况下采用实施例的一些特征。本领域普通技术人员将认识到许多变化、替代和修改。因此,本申请的范围应仅由所附权利要求书来限制,并且适当的是,以与本文公开的实施例的范围一致的方式广义地解释权利要求书。
- 还没有人留言评论。精彩留言会获得点赞!