用于检索数据包的方法和设备与流程
本发明涉及一种用于在计算系统中对数据包的元数据进行排序以使可以基于排序后的元数据来检索数据包的方法和设备。
背景技术:
许多行业依靠必须由服务工程师维护的计算机系统来确保高标准的性能和可靠性。这给服务提供方提出了挑战,服务提供方必须投入大量时间和金钱来培训一组工程师进行各种维护操作。当该计算机系统包括专业设备时,这会更加复杂。这提出了另一个问题,即,服务工程师必须前往偏远位置来服务计算机系统,致使一些资源(诸如文档或培训视频)不可用,使得服务工程师可能没有足够的知识来完成任务。这就进一步强调了在所有服务工程师进行实际维护任务之前,需要对他们进行充分的培训(以及时间和金钱方面的相应投入)。
为了减轻上述问题,通过提供服务工程师经由移动计算装置学习相关知识和/或技术(或者提醒他/她自己学习相关知识和/或技术)以完成维护任务所需的资源,可以为该服务工程师提供协助。这些资源可以例如采取具有文档、培训视频或常见问题(faq)部分的互联网或内联网站点的形式。
随着移动计算装置获得更大的计算能力和更多数量的传感器(诸如,摄像机、加速度计、陀螺仪),这样的装置已经变得可以用于混合现实(mr)应用,包括增强现实(ar)和虚拟现实(vr)。mr通常是指将真实环境和虚拟(即,计算机生成)环境混合在一起的系统。vr是指高度沉浸式虚拟环境,其中视觉(并且通常还有听觉)环境是完全虚拟化的。商业上可获的vr系统包括htcvive和oculusrift,但也可以包括具有合适传感器和应用以提供这种环境的任何移动计算装置(诸如,结合有合适头戴设备的移动电话或智能手机,诸如samsunggalaxygearvr、googlecardboard或googledaydream)。ar是指主要现实环境,加上可以与现实环境无缝交互的虚拟要素。可以经由诸如智能手机的移动计算装置,或者经由诸如microsofthololens的专用硬件,将ar系统设置为应用。
可以将这些mr装置(特别是ar装置)设置为作为服务工程师的强大培训工具的远程协助系统(ras)的一部分。ar装置中的结合有计算能力的众多传感器(包括摄像机)允许ras对用户视野中的对象进行检测和分类,继而提供个性化信息和支持。例如,对远程位置处的网络节点进行维护的电信服务工程师可以经由ar装置的摄像机来拍摄所述网络节点的组件的品牌和型号。然后,ras可以对该组件进行分类,并且将所递送的视频/音频培训文献进行个性化,以使该培训文献仅与该特定组件相关。
ras通常利用媒体服务器来存储正被维护的每个计算设备的一个或更多个知识资产(ka),例如文档或培训视频文件。可以将ka与元数据一起存储在媒体服务器中,该元数据例如标识所述设备的品牌和型号、所述设备的位置等,以传达有关ka的上下文信息。
技术实现要素:
根据本发明的第一方面,提供了一种用于对知识管理系统(kms)中的多个数据包的上下文数据进行排序的方法,其中,kms为被配置成存储关于设备的维护的信息的计算机系统,所述多个数据包中的每个数据包包括与所述设备的维护有关的数据部分、针对所述数据部分的具有第一元数据值并且表示第一上下文信息类型的第一元数据部分以及针对所述数据部分的具有第二元数据值并且表示第二上下文信息类型的第二元数据部分,所述方法包括以下步骤:接收针对第一数据包的所述第一上下文信息类型的第一相关性值和所述第二上下文信息类型的第二相关性值,其中,所述第一相关性值和所述第二相关性值表示所述第一数据部分的所述第一上下文信息类型和所述第二上下文信息类型与所述设备的维护的相关性;接收针对第二数据包的所述第一上下文信息类型的第三相关性值和所述第二上下文信息类型的第四相关性值,其中,所述第三相关性值和所述第四相关性值表示所述第二数据部分的所述第一上下文信息类型和所述第二上下文信息类型与所述设备的维护的相关性;基于所述第一相关性值和所述第三相关性值来确定针对所述第一上下文信息类型的第一排序值;基于所述第二相关性值和所述第四相关性值来确定针对所述第二上下文信息类型的第二排序值;以及将所述第一排序值和所述第二排序值存储在所述kms中。
所述第一相关性值和所述第二相关性值可以从第一用户接收,而所述第三相关性值和所述第四相关性值可以从第二用户接收。
所述方法还可以包括以下步骤:接收针对所述第一数据包的第一有用性值和针对所述第二数据包的第二有用性值,其中,所述第一有用性值和所述第二有用性值分别表示所述第一数据部分和所述第二数据部分对所述设备的维护的有用性;并且确定所述第一有用性值和所述第二有用性值满足阈值。
如上面提到,所述多个数据包中的每个数据包包括与所述设备的维护有关的数据部分、针对所述数据部分的具有第一元数据值并且表示第一上下文信息类型的第一元数据部分以及针对所述数据部分的具有第二元数据值并且表示第二上下文信息类型的第二元数据部分。因此,第一数据包包括与所述设备的维护有关的第一数据部分;针对所述第一数据部分的具有第一元数据值并且表示第一上下文信息类型的第一元数据部分;以及针对所述第一数据部分的具有第二元数据值并且表示第二上下文信息类型的第二元数据部分;并且第二数据包包括与所述设备的维护有关的第二数据部分;针对所述第二数据部分的具有第一元数据值并且表示所述第一上下文信息类型的第一元数据部分(即,尽管所述第二数据包的该第一元数据部分和所述第一数据包的所述第一元数据部分这两者都表示所述第一上下文信息类型,但是所述第二数据包的该第一元数据部分的所述第一元数据值不同于所述第一数据包的所述第一元数据部分的所述第一元数据值);以及针对所述第二数据部分的具有第二元数据值并且表示所述第二上下文信息类型的第二元数据部分(即,尽管所述第二数据包的该第二元数据部分和所述第一数据包的所述第二元数据部分这两者都表示所述第二上下文信息类型,但是所述第二数据包的该第二元数据部分的所述第二元数据值不同于所述第一数据包的所述第二元数据部分的所述第二元数据值)。
根据本发明的第二方面,提供了一种用于检索知识管理系统(kms)中的多个数据包中的一个数据包的数据的方法,其中,kms为被配置成存储关于设备的维护的信息的计算机系统,所述多个数据包中的每个数据包包括与所述设备的维护有关的数据部分、与所述数据部分有关的具有第一元数据值并且表示第一上下文信息类型的第一元数据部分以及与所述数据部分有关的具有第二元数据值并且表示第二上下文信息类型的第二元数据部分,并且所述kms存储了针对所述第一上下文信息类型的第一排序值和针对所述第二上下文信息类型的第二排序值,所述方法包括以下步骤:接收包括所述第一上下文信息类型的第一元数据值和所述第二上下文信息类型的第二元数据值的数据包请求;基于所述数据包请求中的所述第一元数据值和所述第二元数据值、所述第一排序值和所述第二排序值、以及所述多个数据包中的每个数据包的所述第一元数据值和所述第二元数据值中的至少一个元数据值,来检索所述多个数据包中的第一数据包。
所述检索步骤可以包括:基于所述第一排序值和所述第二排序值来确定所述第二上下文信息类型比所述第一上下文信息类型更相关;将所述数据包请求中的所述第二元数据值与所述多个数据包中的每个数据包的所述第二元数据值进行比较;以及基于所述第二元数据值的比较来检索所述多个数据包中的第一数据包。
所述多个数据包中的每个数据包还可以包括与所述数据部分有关的具有第三元数据值并且表示第三上下文信息类型的第三元数据部分,所述kms存储针对所述第三上下文信息类型的第三排序值,所述数据包请求包括所述第三上下文信息类型的第三元数据值,并且所述方法还可以包括以下步骤:基于所述第二排序值和所述第三排序值来确定所述第三上下文信息类型比所述第二上下文信息类型更相关;将所述数据包请求中的所述第三元数据值与所述多个数据包中的每个数据包的所述第三元数据值进行比较;以及基于所述第三元数据值的比较来检索所述多个数据包中的所述第一数据包。
根据本发明的第三方面,提供了一种包括指令的计算机程序,当所述程序由计算机执行时,使所述计算机执行根据本发明的第一方面所述的方法的步骤。所述计算机程序可以设置在计算机可读载体介质上。
根据本发明的第四方面,提供了一种计算设备,该计算设备包括协作以执行本发明的第一方面和/或第二方面所述的方法的步骤的通信接口、存储器以及处理器。
附图说明
为了可以更好地理解本发明,下面参照附图,仅通过示例的方式,对本发明的实施方式进行描述,其中:
图1是作为包括电信节点和增强现实(ar)装置的电信网络的一部分的本发明的计算系统的第一实施方式的示意图;
图2是图1的电信节点的示意图;
图3是图1的ar装置的示意图;
图4是图1的计算系统的示意图;
图5是本发明的方法的实施方式的第一处理的流程图;以及
图6是本发明的方法的实施方式的第二处理的流程图。
具体实施方式
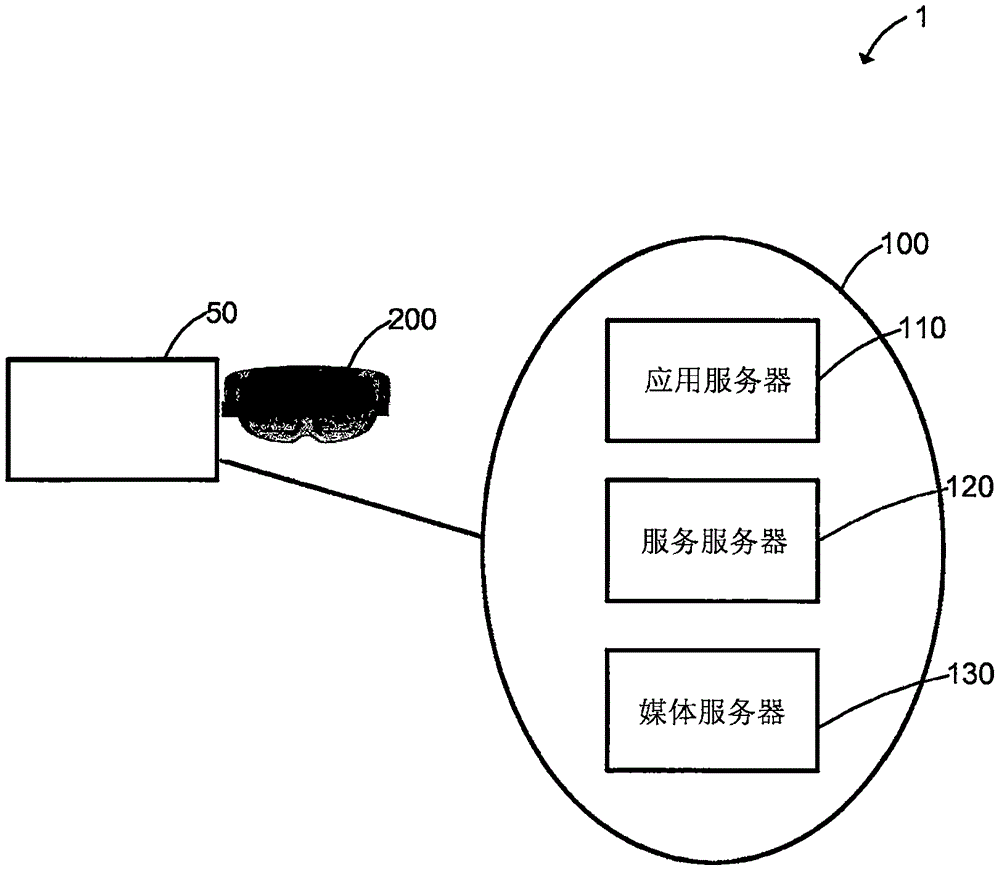
下面,参照图1至图4,对本发明的电信系统1的第一实施方式进行描述。电信系统1包括:电信节点50、计算系统100以及增强现实(ar)装置200。该增强现实(ar)装置200被指派给负责维护电信节点50的代理(例如,维修工程人员)。这将在讨论本发明的方法时进行更详细说明。首先,对电信节点50的组件、计算系统100以及ar装置200进行详述。
图2更详细地例示了电信节点50。在这个实施方式中,电信节点50是数字用户线路(dsl)接入网络的街柜,并且包括外部机柜51、dsl接入复用器(dslam)53、光纤通信接口55(在上游连接至电话交换机)以及多个双绞铜线对通信接口57a...57e(在下游连接至多个客户驻地设备(cpe))。
图3是ar装置200的示意图。在这个实施方式中,ar装置200包括:框架、显示器203、摄像机205、麦克风206、扬声器207以及集成处理单元。将框架、显示器203以及摄像机205整形并配置成,使得当作为头戴式显示器(hmd)由用户佩戴时,将显示器203定位在用户的眼睛前方,并且摄像机205拍摄用户的视野。集成处理单元包括全部经由数据传输总线连接的通信接口201、处理器208以及存储器209。处理单元还具有针对显示器203、摄像机205、麦克风206以及扬声器207的通信接口,以使它们可以通过处理器208和存储器209被控制以及与处理器208和存储器209协作(例如,显示器203与处理器208和存储器209协作以在该显示器上显示计算机生成的图像)。通信接口201被配置成使用诸如长期演进(lte)的蜂窝电信协议(例如,与天线协作),以便与其它计算系统发送和接收数据。要在本发明的该实施方式中使用的合适ar装置200是以商标microsofthololens出售的ar装置,但是可以使用其它ar装置200。
图4更详细地例示了计算系统100。计算系统100包括:应用服务器110、服务服务器120以及媒体服务器130。应用服务器110包括全部经由数据传输总线连接的通信接口111、处理器113、存储器115以及包括kms数据库117的知识管理系统(kms)。应用服务器110经由互联网在服务服务器120、媒体服务器130以及任何远程连接的装置(诸如,ar装置200)之间提供信令和通信网关。
媒体服务器130包括全部经由数据传输总线连接的通信接口131、处理器133、存储器135以及元数据数据库137。存储器135被配置成存储与多个电信节点(包括本发明的该实施方式的电信节点50)的维护有关的数据文件。这些数据文件在下文中被称为知识资产(ka)。元数据数据库137存储了下面将更详细描述的每个ka的元数据。通信接口131允许媒体服务器130与应用服务器110通信并且将ka递送至任何远程连接的装置,诸如ar装置200。媒体服务器的通信接口131支持多种通信协议(诸如,rtsp、http、web套接字、webrtc、voip、tcp/udp),以允许将多种ka类型有效地传输至ar装置200。
服务服务器120包括再次通过数据传输总线连接的通信接口121、处理器123、存储器127以及数据库125。数据库125被配置成存储服务特定信息,诸如用户配置文件。通信接口121允许服务服务器120与应用服务器110进行通信。
概括而言,计算系统100实现两个核心处理。第一核心处理开始于新ka的捕获,诸如通过由ar装置200记录涉及电信节点50的维护的视听(av)数据文件,然后将该数据文件发送至应用服务器110。应用服务器110被配置成利用元数据来注释所述新ka,该元数据诸如是电信节点的标识符、将ka发送至应用服务器110的用户的标识符或其它特征(这可以从服务服务器数据库125获取)、电信节点的位置以及用户承担的维护任务的标识符。在为ka创建元数据之后,应用服务器110将ka以及该ka的元数据发送至媒体服务器130。媒体服务器130将ka存储在存储器135中,并将相关联的元数据存储在元数据数据库137中。出于下面描述的目的,元数据数组采取下面的形式:
{kamid,m1*,m2*,...,mn*}
其中,kamid是第m个ka的标识符(诸如存储器135中的ka的查找地址),并且mi*是第m个ka的第i个元数据项(其中i是1到n的集合)的值。例如,i=1涉及“位置”元数据项并且m1*取第m个ka的值“51.5126258,-0.0997588000000178”,i=2涉及“设备技术”元数据项并且m2*取第m个ka的值“dslam”,i=3涉及“制造商(manufacturer)”元数据项并且m3*取第m个ka的值“思科(cisco)”等等。
第二核心处理开始于计算系统100的用户对ka的请求。应用服务器110被配置成分析该请求以确定一个或更多个特征,诸如它所涉及的电信节点、用户的标识符或其它特征(这可以从服务服务器数据库125获取)或者用户的位置。出于下面描述的目的,ka请求数组采取下面的形式:
{a1*,a2*,...an*}
其中,ai*是请求中第i个元数据项的值。例如,a1*取值“51.5126258,-0.0997588000000178”,a2*取值“dslam”,a3*取值“思科”等等。如上面提到,这些值中的一些值可能不是直接从接收到的请求中导出的,而是可以在向其它实体咨询后被填充的。例如,应用服务器110可以利用用户标识符来查询服务服务器120,并且作为响应,可以接收到用户技能水平的元数据值。然后,这可以形成取值“新手(novice)”的另一元数据项a4*。
然后,应用服务器110可以基于该数据在媒体服务器存储器135中检索合适ka,诸如被分类为与该电信节点有关和/或适合于该用户的技能水平的ka。然后,应用服务器110(经由通信接口)将该ka递送至与该用户相关联的远程装置,从而允许用户在该ka的辅助下承担维护任务。
本发明的实施方式涉及一种用于对元数据项的有用性进行排序以使可以在给定场景中将最相关的ka递送至用户的方法。现在,参照图5和图6,对本发明的方法的实施方式进行描述。
在图5的流程图中例示了本发明的实施方式的第一处理。在该示例中,用户佩戴着ar装置200,位于电信节点50,并且正在通过ka(由计算系统100的应用服务器110和媒体服务器130先前递送的)的辅助来执行维护任务。ka是一个av文件,这是经验丰富的服务工程师的av记录,它给出了如何针对类似电信节点(例如,具有相同的制造商和型号标识符但是来自不同位置的dslam)执行相同维护任务的按步指令。用户在ar装置200的显示器203上观看av文件(使用av回放应用)。
在执行ka之后,ar装置200在显示器203上呈现数据输入表单(form),该数据输入表单允许用户给出ka的音频反馈(该音频反馈可以经由麦克风206接收并且可以经由处理器中的语音到文本功能来进行处理)。在这个实施方式中,该数据输入表单允许用户最初将ka的总体有用性得分输入至维护任务(下文中称为“ka有用性得分”)。如果ka有用性得分高于某个阈值(例如,80%),则数据输入表单允许用户输入用于ka的五个元数据项“位置”、“设备技术”、“制造商”、“用户技能”以及“任务类型”的相关性得分,指示该ka的那些元数据项与维护任务的相关性(这些相关性得分中的每个相关性得分在下文中被称为“元数据相关性得分”)。例如,用户可以指示ka具有为80%的ka有用性得分,并且设备技术、制造商、用户的技能以及任务类型元数据都是相关的(即,位置元数据是不相关的)。在步骤s1中,ar装置200制备第一消息并将第一消息发送至应用服务器110,其中,第一消息包括用于ka的标识符(例如,媒体服务器存储器135内的ka的查找值)、ka有用性得分的值以及(如果可应用)每个元数据项的元数据相关性得分。
在步骤s2中,应用服务器110接收第一消息并且基于ka的ka有用性得分的值更新存储在kms数据库117中的该ka的总ka有用性得分f(s)。该值归因于单个ka,并且在从任何用户接收到该ka的每个ka有用性得分之后被更新。在这个实施方式中,函数f(s)是针对该ka的来自所有用户的所有ka有用性得分的平均值,该函数现在被更新以考虑最新接收的ka有用性得分(80%)。
然后,应用服务器110确定来自第一消息的ka有用性得分是否高于相关阈值(即,确定是否向用户呈现ka的每个元数据项的元数据相关性得分的数据输入表单的同一阈值)。如果ka有用性得分高于相关阈值,则该方法进行至步骤s3(如下)。如果ka有用性得分不高于相关阈值,则该方法进行至步骤s5(如下)。在该示例中,来自第一消息的ka有用性得分高于阈值,因此还包括ka的每个元数据项的元数据相关性得分。
在步骤s3中,这些元数据相关性得分由处理器113处理,以通过递增以下累积元数据相关性函数来生成每个元数据项的累积元数据相关性得分:
ci=(ci+a)
其中,如果第一消息指示元数据类型i被认为与该维护任务的执行相关,则a=1,而如果第一消息指示元数据类型i不被认为与该维护任务的执行相关,则a=0。因此,在该示例中,“设备技术”、“制造商”、“用户的技能”以及“任务类型”(c2至c5)的累积元数据相关性得分的值都递增了1,而“位置”(c1)的累积元数据相关性得分的值保持不变。
应注意,累积元数据相关性函数ci涉及针对所有ka的元数据项的相关性,以使针对从任何用户接收的任何ka的元数据项的相关性得分被处理,以递增该元数据项的累积元数据相关性得分。
在步骤s4中,应用服务器处理器113还更新排序矢量r,该排序矢量根据元数据类型的相应累积元数据相关性得分的值来对这些元数据类型进行排序。因此,该排序矢量是最相关的元数据项(针对所有用户的所有ka)到最不相关的元数据项(针对所有用户的所有ka)的排序。在该示例中,排序矢量是:r=(3,4,1,5,2),以使“制造商”被视为最相关的元数据项,“用户的技能”被视为第二最相关的元数据项,“位置”被视为第三最相关的元数据项,“任务类型”被视为第四最相关的元数据项,以及“设备技术”被视为最不相关的元数据项。
每当应用服务器110从任何用户接收到指示任何ka的元数据项的元数据相关性得分的消息时,更新这两个函数(累积元数据相关性函数和排序矢量)。即,这些函数不是ka特定的(就像总ka有用性得分一样),而是与相关性得分所涉及的ka无关地被更新(假设ka的有用性高于相关阈值)。
因此,随着应用服务器110在一段时间内从许多用户接收到许多ka的ka有用性得分和元数据相关性得分,应用服务器110建立总ka有用性得分的更加准确值(针对每个ka)、每个元数据项的累积元数据相关性得分的更准确值(跨所有ka)以及更准确排序矢量(跨所有ka)。
在步骤s5中,应用服务器110将总ka有用性得分并且如果可应用将累积元数据相关性得分存储在kms数据库117中。在这个实施方式中,kms数据库117包括两个表。第一个表按具有{kamid,f(s)m}的形式的元组(tuple)存储每个ka的总ka有用性得分的值f(s),其中,kamid是第m个ka的标识符(例如,媒体服务器存储器135内的ka的查找值),而f(s)m是第m个ka的总ka有用性得分。kms数据库117的第二个表按具有形式{ci=1,...,ci=n}的元组存储每个元数据项的累积元数据相关性得分的值,并且按具有形式{ri=1,...,ri=n}的元组存储排序矢量的值。
上面的步骤例示了在接收到第一消息之后更新总ka有用性得分并且如果可应用则更新累积元数据相关性得分以及排序矢量的处理。该处理结束,但是当从远程装置中的任一远程装置(例如,ar装置200)接收到包括ka有用性得分并且如果可应用包括用于任何ka的元数据相关性得分的另一消息时重复该处理。下面在本发明的实施方式的第二处理中讨论这些值的重要性和使用。
现在参照图6,对本发明的实施方式的第二处理进行描述。该处理的示例开始场景是ar装置200的用户位于电信节点50的位置并负责执行特定维护任务(在这种情况下,对特定dsl上的故障进行诊断)。在该处理的第一步骤(步骤s11)中,用户请求ka辅助他/她完成此特定维护任务。在该示例中,用户使用由麦克风206接收并且由处理器208处理和解释的语音命令发出请求。而且,ar装置200捕获关于电信节点50的信息,诸如,在该示例中,使用摄像机205以及处理器208中的合适光学字符识别(ocr)和/或计算机视觉(cv)处理来标识节点50的设备类型和制造商,并且在第二示例中,使用现有技术已知的组件标识全球导航卫星系统(gnss)坐标。然后,处理器208形成第二消息,该第二消息包括具有以下形式的ka请求元组(如稍早讨论的):
{a1*,a2*,...an*}
其中,ai*是请求中的第i个元数据项的值。在该示例中,a1*涉及元数据项“位置”,并且取值“51.5126258,-0.0997588000000178”,a2*涉及元数据项“设备技术”,并且取值“dslam”,a3*涉及元数据项“制造商”,并且取值“思科”,并且a5*涉及元数据项“维护任务”,并且取值“诊断dsl”。
然后,ar装置200使用收发器201将第二消息发送至应用服务器110。应用服务器110接收该消息,并且在步骤s12中,检索ka请求中未包含的任何其它可用数据值。在该示例中,没有填充涉及元数据项“用户技能”的a4*的数据值。因此,应用服务器110向服务服务器120发送包括该用户的标识符的查询消息,并且作为响应,接收元数据项“用户技能”的值。在该示例中,a4*的值为“新手”。
在步骤s13中,应用服务器110将包括ka请求元数据{a1*,a2*,...an*}的ka检索请求发送至媒体服务器130。当在步骤s14中接收到该请求时,媒体服务器的处理器133查询元数据数据库137以确定任何元数据元组{m1*,...,mn*}是否具有与ka请求元组{a1*,...,an*}的值完全匹配的值。即,如果特定ka的元数据元组也具有下列值:m1*=“51.5126258,-0.0997588000000178”、m2*=“dslam”、m3*=“思科”、m4*=“新手”以及m5*=“诊断dsl”,则该ka变为候选ka。
在步骤s15中,媒体服务器130确定查询是返回空值(null)、一个结果、还是更多个结果,并将该结果报告回至应用服务器110。如果存在单个候选ka,则选择该单个候选ka作为要递送给用户的ka,然后该处理继续至步骤s20。然而,如果存在多于一个候选ka,则应用服务器110通过查询kms数据库117的第一个表,来确定这些候选ka中的哪个候选ka具有最大总ka有用性得分f(s)。然后,选择具有最大总ka有用性得分的ka作为要递送给用户的ka,并且处理进行至步骤s20。然而,如果媒体服务器130向应用服务器110通知了空值结果(即,没有ka具有与ka请求的元数据项相匹配的元数据项),则在步骤s17中,应用服务器制备第一经修改ka检索请求。
该第一经修改ka检索请求采取与步骤s13的原始ka检索请求类似的形式,{a1*,a2*,...an*}。然而,在该实施方式中,通过去除已经基于排序矢量确定为最不相关的的元数据项来修改第一经修改ka检索请求。因此,在该实施方式中,应用服务器110查询kms数据库117的第二个表,以确定哪个元数据项是最不相关的(即,与排序矢量中的最后一个值相对应的元数据项)。在该示例中,返回元数据项“设备技术”作为最不相关的元数据项。然后,应用服务器110通过从ka检索请求中去除对应元数据项a2*来制备第一经修改ka检索请求。换句话说,第一经修改ka检索请求包括:a1*、a3*、a4*以及a5*(分别与“位置”、“制造商”、“用户技能”、“维护任务”有关)。然后,应用服务器110将该请求发送至媒体服务器130。
然后,媒体服务器130查询元数据数据库137以再次确定任何元数据数组{m1*,...,mn-1*}是否具有与第一经修改ka请求数组{a1*,...,an-1*}的值完全匹配的值。然后,任何结果都将变为候选ka。接着,将该查询的结果报告回至应用服务器110。
如果针对第一经修改ka检索请求的查询再次生成空值结果,则迭代地重复该处理,以确定下一个最不相关的元数据项(如由排序矢量确定的),制备去除了所确定的下一个最不相关的元数据项的经修改ka检索请求,并且针对一个或更多个候选ka,将检查媒体服务器对该请求的响应。因此重复该处理,直到媒体服务器130报告一个或更多个候选ka(其中,使用与步骤s15中详述的逻辑相同的逻辑选择这些候选ka中的一个候选ka以递送给用户),或者直到针对最相关的元数据项的最终经修改ka检索请求产生空值结果。
如果最终经修改ka检索请求产生空值结果,则在步骤s19中,应用服务器110向ar装置200发送包括对另一元数据的请求的第三消息。ar装置200通过呈现用于与维护任务有关的另一些元数据值的输入画面来响应对另一元数据的请求。在这个实施方式中,该输入画面使得用户仅能够输入(如由排序矢量确定的)最相关的元数据项的附加元数据值。用户可以通过对着麦克风206讲话来输入该数据,然后可以由处理器208对该数据进行处理和解释。如果用户希望继续,则用户可以接着输入第二最相关的元数据项的附加元数据值等,直到他/她指示数据输入处理完成为止。然后,ar装置200向应用服务器110发送包括这些附加元数据值的第四消息。
然后,应用服务器110可以与媒体服务器130协作,以按类似于之前的方式为用户检索合适ka,但是用于检索ka的查询将ka的元数据与更广泛ka请求进行匹配(其中,元数据值可以是原始ka请求的元数据值或者是另一些ka输入值)。因此,这种更广泛搜索更有可能检索到一个或更多个候选ka。
因此,应用服务器110最终进行至步骤s20,在步骤s20中,应用服务器110与媒体服务器130协作,以将所选ka(即,单个候选ka或者多个候选ka中的所选ka)递送至用户。在这个实施方式中,媒体服务器130经由通信接口131和互联网将所选ka直接递送至ar装置200。
然后,ar装置200执行ka。在这个实施方式中,ka是av文件,以使显示器203和扬声器207由处理器208控制以向用户播放av内容。然后,用户在ka的辅助下执行维护任务。
因此,本发明的上述实施方式具有向用户递送更相关ka的优点,使得用户更可能在计算设备上快速且正确地执行维护任务。因此,可以在包含计算设备的系统中实现许多改进,诸如减少修理时间并且降低故障率。通过基于如由许多用户确定的最相关的元数据项来选择ka实现了这种改进(换句话说,元数据项的相关性是“众包(crowdsourced)的”)。
在上述实施方式中,媒体服务器130可以向应用服务器110报告多于一个候选ka,并且然后,应用服务器130选择这些ka中的一个ka以递送给用户。技术人员应当明白,这不是必要的,因为应用服务器130可以递送这些候选ka中的几个候选ka或全部候选ka,然后用户可以进行选择。
而且,在上述实施方式的修改例中,应用服务器110可以精简候选ka的结果,以便去除已经从做出针对ka的请求的用户接收到低(例如,小于阈值)ka有用性得分的任何候选ka。在这种场景中,除了更新总ka有用性得分之外,kms数据库117还必须存储来自每个用户的每个ka的ka有用性得分。
而且,当选择要递送给用户的候选ka时,计算系统100可以在递送之前进一步个性化ka(例如,基于用户和/或正被维护的电信节点的身份和已知特征)。
在上述实施方式中,每个元数据项的元数据相关性得分是二元得分。即,用户认为元数据项是“相关的”或“不相关的”,并且这被用于更新每个元数据项的累积元数据相关性得分。然而,这不是必要的,并且可以使用记录和总计每个元数据项的相关性的其它方法。例如,用户可以将元数据相关性得分作为百分数给出,然后应用服务器110可以基于来自所有用户的针对所有ka的元数据相关性得分的平均值来更新总元数据相关性得分。然后,排序矢量可以基于平均百分数值对元数据项的相关性进行排序。
本发明的实施方式提供了一种根据每个元数据项的上下文信息与计算设备的维护的相关性来对元数据项进行排序的手段。该排序处理对于ka和给出关于该上下文信息的相关性的反馈的用户都是不可知的。排序矢量仅是可以存储该排序的一个示例,以使可以以利用对具有更高排序元数据项的那些ka的偏好(preference)来检索ka。然而,排序矢量不是必要的,并且可以使用表达每个元数据项相对于其它元数据项的相关性的任何函数。
技术人员还将明白,将计算系统100上的组件分布在几个单独节点上不是必要的。即,本发明的方法的实施方式可以在单个计算设备中实现。
只要所描述的本发明的实施方式至少部分地可利用诸如微处理器、数字信号处理器或其它处理装置的软件控制可编程处理装置、数据处理设备或系统来实现,就应当清楚,用于配置用于实现前述方法的可编程装置、设备或系统的计算机程序都被认为是本发明的一方面。该计算机程序例如可以被具体实施为源代码或者经历编译以在处理装置、设备或系统上实现,或者可以具体实施为目标代码。
合适地,该计算机程序以机器或装置可读形式存储在载体介质上,例如存储在固态存储器、诸如磁盘或磁带的磁存储器、光学或磁光可读存储器(诸如光盘或数字通用光盘等)中,并且处理装置利用该程序或该程序的一部分来配置该处理装置以供操作。该计算机程序可以从在诸如电子信号、射频载波或光学载波的通信媒介中具体实施的远程源提供。这种载体介质也被认为是本发明的各方面。
本领域技术人员应当明白,尽管已经关于上述示例实施方式对本发明进行了描述,但本发明不限于此,而是存在落入本发明的范围内的许多可能变型例和修改例。
本发明的范围包括本文所公开的任何新颖特征或特征组合。本申请人提请注意,在进行本申请或从本申请衍生的任何这种进一步申请的过程期间,可以对这种特征或特征的组合制定新的权利要求。具体地,参照所附权利要求,来自从属权利要求的特征可以与独立权利要求的那些特征组合,并且来自相应独立权利要求的特征可以以任何恰当的方式组合,而不仅仅是权利要求中列举的具体组合。
- 还没有人留言评论。精彩留言会获得点赞!