修改用于深度学习模型的视网膜眼底图像的方法与流程
本公开涉及用于深度学习技术的图像处理,并且更具体地但是非排他性地涉及一种修改用于深度学习模型的视网膜眼底图像的方法。
背景
在全球范围内,糖尿病性视网膜病变(dr)是引起视力丧失的主要原因。筛查dr并及时进行转诊和治疗是预防视力受损的普遍接受的策略。当前,由评估人员针对dr进行的临床眼底镜检查或者视网膜照片评估是最常用的dr筛查方法。然而,此类dr筛查项目受到实施问题、评估人员的提供和训练以及长期财务可持续性的挑战。随着全球糖尿病患病率的增加,需要可持续的、具有成本效益的dr筛查项目。
已提出了深度学习系统(dls),作为用于通过分析视网膜图像来进行大规模dr筛查的一种选择。dls利用人工智能和表示学习法来处理自然原始数据,以识别高维信息中错综复杂的结构。与用于检测特定图像、图案和病变的传统模式识别型软件不同,dls使用大型数据集来实现对有意义的图案或特征的挖掘、提取和机器学习。
dls的性能部分取决于用于训练和/或验证模型的数据集。例如,两项先前的dls研究显示出具有用于dr筛查的巨大潜力,从而证明在从视网膜照片中检测可转诊dr方面具有高灵敏度和特异性(>90%)。然而,所使用的性能指标基于从两个可公开获得的数据库中检索到的、而且在很大程度上局限于单个族群的高质量视网膜图像。
在“现实世界”dr筛查项目中,所捕获的、用于进行筛查的视网膜图像可能存在很大的可变性。例如,可能会使用不同的相机型号,从而导致图像差异。各个筛查中心之间的捕获标准也可能不同,这导致视网膜图像具有不同的质量(例如,很差的瞳孔扩张、很差的对比度/对焦)。各患者也可能具有不同的族裔,从而导致所捕获的视网膜图像具有不同的眼底色素沉着。这些可变因素将对在具有低可变性的高质量视网膜图像上训练的dls的性能具有影响。为了将dls在测试环境中的性能转变为在“现实世界”中的性能,应该使用“现实世界”dr筛查项目对dls进行训练和验证,在“现实世界”dr筛查项目中,用于训练的视网膜图像会受到“现实世界”可变因素的影响。
此外,在任何dr筛查项目中,都期望包括对偶发但是常见的威胁视力的病症(诸如可疑青光眼(gs)和年龄相关性黄斑变性(amd))的检测。这进一步拓宽了要纳入dls的训练数据集中的视网膜图像的可变性。
因此,期望提供一种通过各种各样的视网膜图像来训练dls的方法,以便解决现有技术中提到的问题和/或为公众提供有用的选择。
概述
现在将描述本公开的各个方面,以便提供本公开的总体概述。这些方面决不界定本发明的范围。
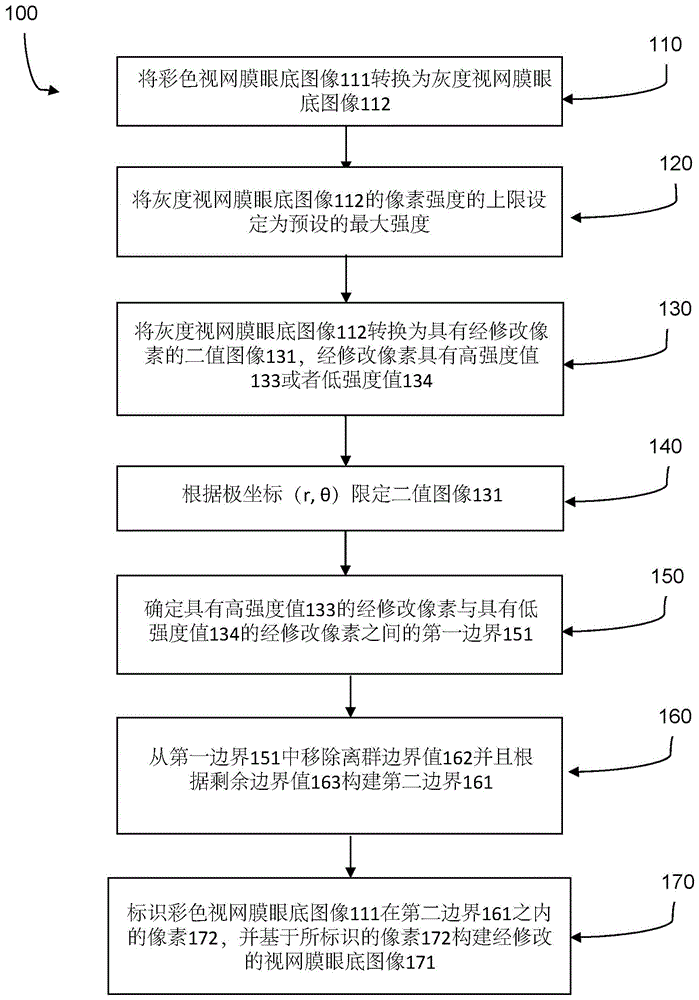
根据第一方面,提供了一种修改用于深度学习模型的视网膜眼底图像的方法。该方法包括:通过将视网膜眼底图像的像素转换为二值图像的低强度经修改像素和高强度经修改像素来将视网膜眼底图像转换为二值图像,以及确定在二值图像的低强度经修改像素与高强度经修改像素之间的第一边界。该方法进一步包括:从第一边界移除离群边界值;根据剩余边界值构建第二边界;标识视网膜眼底图像的在第二边界之内的像素;以及构建用于所述深度学习模型的经修改的视网膜眼底图像,所述经修改的视网膜眼底图像包括所标识的像素。
所描述的实施例用于在由经过训练的dls进行筛查之前,将所捕获的视网膜眼底图像标准化。此外,所描述的实施例允许大规模使用从筛查项目捕获的“现实世界”视网膜眼底图像来训练深度学习模型。所训练的模型或者dls在其在“现实世界”中的性能方面具有转化影响。
视网膜眼底图像可以是灰度图像。
该方法可以进一步包括:在将视网膜眼底图像转换为二值图像之前,使用绿色通道值将彩色视网膜眼底图像转换为灰度视网膜眼底图像。
将视网膜眼底图像转换为二值图像可以包括:将视网膜眼底图像的对应强度值低于预定强度阈值的像素分类为低强度经修改像素,并且将视网膜眼底图像的对应强度值高于预定强度阈值的像素分类为高强度修改像素。
低强度经修改像素中的每一者的强度值可以为“0”,并且高强度经修改像素中的每一者的强度值可以为“255”。
将视网膜眼底图像转换为二值图像可以使用二分类大津算法来执行。
该方法可以进一步包括在将视网膜眼底图像转换为二值图像之前,将视网膜眼底图像的像素强度的上限设定为预设的最大强度。
最大强度可以预设为“50”。
该方法可以进一步包括:在确定第一边界之前,根据极坐标来限定二值图像。
高强度经修改像素可以位于第一边界之内,并且低强度经修改像素可以位于第一边界之外。
确定第一边界可以包括根据用极坐标表示的边界值来限定第一边界。
移除离群边界值可以包括:根据边界值计算平均径向值,以及移除径向值未限定或者偏离所述平均径向值的边界值。
偏离平均径向值超过10个单位的边界值可以被移除。
该方法可以进一步包括对剩余边界值应用二次回归以构建第二边界。
该方法可以进一步包括在标识视网膜眼底图像的在第二边界之内的像素之前,以笛卡尔坐标限定第二边界。
构建经修改的视网膜眼底图像可以包括:将所标识的像素复制到第二边界中,以及用经修改的视网膜眼底图像的背景来填充第二边界内的未占用像素。
该方法可以进一步包括将经修改的视网膜眼底图像重新调节为512×512像素。
应当理解,该方法可以由专门配置的计算机或者计算系统来实现。然后,这形成第二方面,其中提供了一种存储有可执行指令的非暂时性计算机可读介质,该可执行指令在由处理器执行时,使得处理器执行第一方面的方法。
该方法具有许多用途,并且在一个特定的应用中,根据第三方面,提供了一种用于筛查眼部疾病的深度学习系统,其中该深度学习系统包括依据第一方面的方法的视网膜眼底图像训练的数据集。
附图简述
将参考附图描述示例性实施例,在附图中:
图1是示出根据优选实施例的修改用于深度学习模型的视网膜眼底图像的方法的流程图;
图2是从来自图1中的方法的彩色视网膜眼底图像转换而来的灰度图像的图片;
图3示出了其中设定了像素强度的上限的图2的灰度图像;
图4是从图3的灰度图像转换而来的二值图像;
图5描绘了用极坐标表示的图4的二值图像;
图6描绘了用极坐标表示的图5的二值图像的第一边界;
图7描绘了用极坐标表示的在从图6的第一边界中移除了离群边界值之后的剩余边界值;
图8是具有根据图7的剩余边界值构建的第二边界的模板;
图9是使用图8的模板构建的经修改的视网膜眼底图像;
图10是从图9的经修改的视网膜眼底图像得到的局部对比度归一化(lcn)图像;
图11a-图11b是呈现关于在dr、gs和amd训练和验证数据集的每一者中(将使用图1的方法100进行修改的)视网膜眼底图像的数量的数据的表格;
图12a-图12b是呈现关于图11a-图11b的dr训练和验证数据集的进一步数据的表格;
图13是呈现关于图11a-图11b的gs和amd训练数据集的进一步数据的表格;
图14描绘了将分别使用图9的经修改的视网膜眼底图像或者图10的lcn图像来训练的深度学习模型的示例性cnn的架构;
图15描绘了使用dls的两个不同筛查模型的流程图,该dls是使用图14的架构训练而成的;
图16是呈现关于在图11a和图12a中呈现的主要验证数据集(sidrp2014-15)中患者的总体人口统计资料、糖尿病史和系统性风险因素的数据的表格;
图17是呈现针对图11a和图12a中所示的主要验证数据集(sidrp2014-15)进行评估得到的关于dls对于可转诊dr和vtdr的诊断性能的数据与专业评级人员比对的表格;
图18是呈现针对图11a和图12a中所示的主要验证数据集(sidrp2014-15)中的独特患者进行评估得到的关于dls对于可转诊dr和vtdr的诊断性能的数据与专业评级人员比对的表格;
图19a-图19b是呈现针对图11a、图12a和图12b中所示的外部验证数据集进行评估得到的关于dls对于可转诊dr和vtdr的诊断性能的数据与专业评级人员比对的表格;
图20a-图20c描绘了基于图17的性能数据构建的示图;图19a-图19b;以及
图21是呈现针对图11b中所示的主要验证数据集(sidrp2014-15)进行评估得到的关于dls对于可转诊gs和amd的诊断性能的数据与专业评级人员比对的表格。
详细描述
现在将参考附图描述本公开的一个或者多个实施例。在说明书的各个部分中对术语“实施例”的使用不一定指同一个实施例。此外,在一个实施例中描述的特征可能不存在于其他实施例中,也不应仅仅因为其他实施例中没有这些特征而将这些特征理解为排除在那些实施例之外。所描述的各种特征可以存在于一些实施例中而不存在于其他实施例中。
另外,附图有助于对特定实施例进行描述。以下描述包含用于说明目的的特定示例。本领域技术人员将意识到,特定示例的变型和替换是可能的,并且在本公开的范围内。附图和以下对特定实施例的描述不应脱离前述
技术实现要素:
的一般性。
以下描述划分为以下几个部分。在第一部分中,讨论了用于修改用于深度学习模型的视网膜眼底图像的示例性方法。在第二部分中,讨论了训练程序,该训练程序使用经修改的视网膜眼底图像作为深度学习模型的输入。深度学习模型的任务是训练dls来筛查眼部疾病。在第三部分中,讨论了各个体疾病的分类。在最后一部分中,以示例性实施例讨论了训练和验证方法。结合第一部分的示例性方法,使用正在进行的“现实世界”dr筛查项目中的近500,000张视网膜图像对dls进行训练和验证。讨论了强调使用依据可通过示例性方法得到的视网膜图像训练的dls的优点的结果。
(1)从视网膜眼底图像中提取模板
图1是示出根据优选实施例的用于修改用于深度学习模型的视网膜眼底图像的方法100的流程图。在示例性方法100中,首先(例如从患者)捕获具有视网膜盘的彩色视网膜眼底图像111,并呈现该彩色视网膜眼底图像111以供进行修改。
在步骤110,通过仅提取并保留彩色视网膜眼底图像111中的绿色通道值并且将绿色通道值表示为灰度级来将彩色视网膜眼底图像111转换为灰度视网膜眼底图像112。图2示出了具有视盘200和视网膜盘210的灰度视网膜眼底图像112的图片。
可以利用其他颜色到灰度的转换技术来将彩色视网膜眼底图像111转换为灰度视网膜眼底图像112。例如,取代使用绿色通道值,可以改为使用红色通道值。
在步骤120,将灰度视网膜眼底图像112的像素强度的上限设定为预设的最大强度“50”,并且结果在图3中示出。通过使超过最大强度的像素强度降低到“50”来执行对像素强度的上限的设定。值得注意的是,通常为包含高像素强度的区域的视盘200(在图2中描绘)在图3中不再可见。
在步骤130,使用二分类大津算法(otsualgorithm),将灰度视网膜眼底图像112转换为具有经修改像素的二值图像131,这些经修改像素具有两种强度值:为“255”的高强度值133,或者为“0”的低强度值134:。换而言之,视网膜眼底图像的像素被转换为二值图像的低强度经修改像素和高强度经修改像素。详细地说,灰度视网膜眼底图像112具有处于不同的像素强度水平的灰度像素。二值图像131通过将这些像素强度降低到两个水平来形成。这是通过向像素强度高于预定强度阈值的所有像素分配为“255”的高强度值133并且向像素强度低于该预定强度阈值的所有像素分配为“0”的低强度值134来实现的。强度阈值被预定为使得其具有介于灰度视网膜眼底图像112的两个极限像素强度之间的像素强度。图4示出了具有经修改像素的二值图像131,该二值图像131被划分成具有高强度值133的区域和具有低强度值134的区域。
在步骤140,根据极坐标限定二值图像131。极坐标的参考点是二值图像的中心。在示例性方法100中,该中心也就是视网膜圆的中点,如使用具有高强度值133的所有经修改像素计算得到的视网膜圆的中点。图5示出了用具有径向坐标“r”500和角坐标“θ”600的极坐标表示的二值图像131。
可以注意到在图5(以及还有图6)的峰501处有一些白色斑点。这些白色斑点是二值图像131中的缺陷的结果,例如由图4所示的“嘈杂边界”401造成。出现缺陷的原因是,所使用的彩色视网膜眼底图像111是从现实世界筛查项目中获取的,该项目可能不需要所获取的图像必须完美。
在步骤150,确定低强度经修改像素与高强度经修改像素(即具有高强度值133的经修改像素与具有低强度值134的经修改像素)之间的第一边界151。由于二值图像131被划分成两个区域,因此有可能将第一边界151确定为使得具有高强度值133的经修改像素位于第一边界151之内,而具有低强度值134的经修改像素位于第一边界之外。图6示出了由用具有径向坐标“r”500和角坐标“θ”600的极坐标表示的边界值限定的第一边界151。在图4中还示出了用笛卡尔坐标限定的第一边界151。
应当注意,由边界值限定的第一边界可能不一定必须用极坐标表示。作为替代,可以用笛卡尔坐标限定边界值,并且图4示出了用笛卡尔坐标表示的第一边界151。在这种情况下,可以省略步骤140,因为不一定要用极坐标限定二值图像。
在步骤160,从第一边界151移除离群边界值162。在该实施例中,为了移除离群边界值,根据边界值计算平均径向值,并且将径向值未限定或者偏离平均径向值超过10个单位的边界值视为离群边界值162。从第一边界151移除这些离群边界值162。图7示出了步骤160的中间产物,即用极坐标示出的在从第一边界151移除了离群边界值162之后的剩余边界值163。
如果边界值是用笛卡尔坐标限定的,则移除离群边界值162所需的计算然后可以相应地通过极坐标到笛卡尔坐标映射的方式用笛卡尔坐标执行。
在离群边界值162已经被移除之后,对剩余边界值163应用二次回归以构建第二边界161。在示例性方法100中,第二边界是拟合圆。拟合圆的半径是根据从剩余边界值163提取的边界值估计的。提取的边界值可以视为图7中的白色像素。几乎所有白色像素都属于三个线段701,它们指示拟合圆的半径。在线段701右边的其余白色像素是被忽略的离群值。图8示出了包括以笛卡尔坐标限定的第二边界161的模板164。第二边界161对应于视网膜盘210(在图2中描绘)的估计参数。
在步骤170,标识出彩色视网膜眼底图像111中的将落在模板164的第二边界161之内的像素172。将标识出的像素172复制到模板164的第二边界161中。值得注意的是,在彩色视网膜眼底图像111的顶部和底部切除视网膜盘的部分(在图2中示出了灰度示例210)。结果,第二边界的顶部和底部可能不包括任何标识出的像素,并且未被占用。然后,利用所标识出的位于第二边界161之内的像素172来构建基于模板164的经修改的视网膜眼底图像171。图9示出了使用图8的模板164构建的经修改的视网膜眼底图像171。
第二边界内任何未被占用的像素都用经修改的视网膜眼底图像171的背景颜色填充,并且成为背景173的一部分。虽然在图9中未示出,但是示例性方法100中的默认背景颜色具有rgb值[255,0,255]。
允许与所标识出的在第二边界161之内的像素172有明显区别的任何背景颜色都可以是该默认颜色。
之后,经修改的视网膜眼底图像171就准备好被输入到深度学习模型中。如果尺寸不合适,则可以将经修改的视网膜眼底图像171重新调节至合适的尺寸,例如,“512x512”像素。
分类性能可以通过集成多个训练模型并使每个集合包括一个深度学习模型来进一步改进,深度学习模型是基于经历了局部对比度归一化(lcn)的经修改的视网膜眼底图像来训练的。
图10示出了经lcn修改的视网膜眼底图像1000。为了执行lcn,使用快速积分图像实现对视网膜盘1100内的所有像素在所有三个rgb通道上应用内核尺寸为“26×26”像素的大均值滤波。每个像素的值均被设为其原始值减去均值滤波值。最后,每一通道因此是使用所有有效像素在该通道内的均值和标准差统计值来归一化的。
使用示例性方法100,使训练方法不限于使用由特定相机型号或者特定类型的视网膜眼底相机捕获的视网膜眼底图像。可从现有健康筛查项目中得到的大量数据集也可被用于训练dls,使得dls在评估dr、gs和/或amd方面的性能可在现实世界筛查项目中具有转化影响。
(2)dls的训练程序
使用caffe框架训练深度学习模型。使用具有动量为0.9的基本学习率0.001,其中权重衰减为0.0005。使用伽玛参数值为0.98并且步长为1000次迭代的步长学习率策略。dr模型是通过从训练数据中进行采样来训练的,其中所有有效类均被采样了达200000次迭代,并且然后原始类分布被采样了达另外的300000次迭代。amd和gs模型是通过从所有有效类中进行采样来训练的,所有有效类均被采样了达200000次迭代。通过经验验证,这些训练程序产生所有尝试的变化中最佳的结果。
为了将进一步的变化包括在训练数据中,通过以下方式即时调整输入图像:
-整体缩放,其中均匀比例因子为从0.95到1.05
-整体旋转,其中均匀旋转因子为从0度到359度
-水平翻转,其中概率为0.5
-亮度调整,其中均匀比例因子为从0.7到1.3。
(3)个体疾病的分类
每个模型都有“n”个输出节点,其按严重度递增的顺序对应于目标疾病的临床相关严重度类别。例如,dr模型具有索引为从“0”到“4”的五个输出节点,其中“0”代表“无dr”,“1”代表“轻度dr”,“2”代表“中度dr”,“3”代表“重度dr”,“4”代表“增生性dr”。
经过训练后,模型的输出可以解释为输入图像类别的概率预测。例如,如果dr模型的五节点输出为(0.80,0.10,0.05,0.03,0.02),则它预测图像为“无dr”的可能性为80%,为“轻度dr”的可能性为10%,为“中度dr”的可能性为5%,为“重度dr”的可能性为3%,为“增生性dr”的可能性为2%。
出于评估目的,通过将每个节点的输出值乘以该节点的索引来将这些值转换为单个标量值。继续上面的示例,模型分数将为(0.80*0+0.10*1+0.05*2+0.03*3+0.02*4)=0.37。模型集成分数值被限定为各组成模型分数的均值。
对于每只眼睛,通过深度学习模型评估与两个标准视场(以od为中心和以黄斑为中心)相对应的至少两个图像。首先通过可评级性模型和非视网膜模型对这些图像中的每一个图像进行分类,以确定是否可接受对该图像进一步评估。如果所有相应的图像都被拒绝,则拒绝该眼睛并且将该眼睛转诊。如果有足够的图像来继续,则将眼睛的模型集成分数值限定为各个图像的模型集成分数值的均值。
对于每一个体疾病,通过对不可预知的验证数据集进行经验验证来确定分数阈值。然后将分数等于或者高于阈值的眼睛分类为对于该疾病呈阳性,否则将其分类为对于该疾病呈阴性。
(4)训练方法
在说明书的以下部分中,讨论了对dls的训练和验证方法。使用主要在进行中的“现实世界”国家dr筛查项目中的近500,000张视网膜图像在检测可转诊dr方面对dls进行训练和验证,并且进一步在10个额外的多个族裔(具有不同的眼底色素沉着)的数据集中以不同的环境(社区、基于人群和基于诊所、利用不同的视网膜相机)对dls进行外部验证。评估dls在检测以下两个结果方面的性能:(其中患者会被从筛查项目转诊给眼科医生的)可转诊的dr和(要求更紧急的转诊和管理的)vtdr。作为dr筛查项目的一部分,进行二次分析以确定dls在检测可转诊的可疑青光眼(gs)和可转诊的amd方面的能力。最后,评估dls在检测总体可转诊状态(可转诊的dr、gs、amd)方面的性能,并且将dls应用于以下两种dr筛查模型:(在没有现有筛查项目的社区中有用的)“全自动”筛查模型以及(其中来自dls的可转诊的案例由专业评级员进行二次评估的)“半自动”模型。
dls的训练数据集
在该实施例中,用于开发dls的总共493,667个视网膜图像(包括:76,370和112,648个针对dr的图像;125,189和71,896个针对可转诊gs的图像;以及71616和35,948个针对可转诊amd的图像)被分别用来进行训练和验证。图11a和图11b提供了有关可转诊dr训练和验证数据集、可转诊gs训练和验证数据集和可转诊amd训练和验证数据集中的每个训练和验证数据集中的图像的数量的概览(表1)。
用于可转诊dr的dls是使用参与了在2010年至2013年间进行的国家dr筛查项目(sidrp2010-13)的糖尿病患者的视网膜图像来开发和训练的,该项目使用了数字视网膜照片、远程眼科平台以及由经过训练的专业评级人员所做的dr评估。对于每位患者,拍摄了每只眼睛的两张视网膜照片(视盘和中央凹)。可转诊的眼睛由高级专业评级人员重新评级;如果存在不一致的发现,则由视网膜专家进行仲裁。图12a和图12b汇总了用于dr的训练和验证数据集(表2)。值得注意的是,在主要验证数据集(即sidrp2014-2015)中,有6291名患者与sidrp2010-2013重复患者,而有8,589名患者是独特患者。独特患者是未出现在sidrp2010-2013筛查项目中的患者,并且因此,sidrp2010-2013验证数据集与针对这些患者的sidrp2014-2015训练数据集之间没有重叠。
对于可转诊gs和可转诊amd,使用来自sidrp2010-13的图像以及若干附加的针对具有gs和amd的新加坡患者、中国患者、马来西亚患者、印度患者的基于种群和基于临床的研究来训练dls。图13汇总了gs训练数据集和amd训练数据集(表3)。
深度学习模型的架构
使用图1的示例性方法100,将彩色视网膜眼底图像111修改为经修改的视网膜眼底图像171,并将经修改的视网膜眼底图像171的尺寸缩放为512x512像素,然后由深度学习模型利用该经修改的视网膜眼底图像171。深度学习模型包括八个卷积神经网络(cnn),其全部使用vggnet架构的改编:(a)用于dr严重度分类的两个网络的集合;(b)用于标识可转诊gs的两个网络的集合;(c)用于标识可转诊amd的两个网络的集合;(d)一个用于评估图像质量的网络;以及(e)一个用于拒绝无效的非视网膜图像的网络。图14中显示了用于训练dls1400的深度学习模型的示例性cnn1410。
vggnet在视网膜图像分类方面表现出最先进的性能。训练cnn1410以用于建模dr是通过向该网络呈现几批带有标签的训练图像来实现的。然后,cnn1410递增地学习属于每个类别的图像的关键特征。训练多个cnn1410以通过组合各个cnn分数来获得图像分数。同样,使用具有可接受的质量的所有可用眼睛图像来产生眼睛级别分类,并且应用根据训练数据确定的分数阈值。
作为准备步骤,首先自动分割每张视网膜照片以仅提取视网膜盘。然后将此感兴趣的圆形区域均匀地重新调节成适合尺寸为512x512像素的标准化方形模板。然后输入经修改的视网膜眼底图像171的rgb值作为相关卷积网络1410的第一层的三个通道。输入层之后是一系列模块1420。每个模块1420都以多个卷积层1430开始,该多个卷积层1430学习处于目前比例下的特征。每个卷积层1430都包含特征图的集合,这些特征图的值被传送通过3×3的权重内核1440到达下一层1430中的特征图。每个模块1420都以2×2的最大合并层1450结束,该最大合并层1450有效地以因子2对特征尺寸下采样,使得这些特征尺寸可以用作下一模块1420的输入。当最后一个模块1420输出的特征是尺寸为1x1的特征时,模块1420的系列终止。然后,应用标准relu整流层和压降层,然后施加最终的归一化指数(softmax)输出层,该归一化指数输出层针对为其训练的每个类包含一个输出节点。每个卷积网络1410都包含五个这样的模块1420,总共19层。
每个卷积网络1410的训练程序都涉及重复从训练集中随机采样一批图像,并涉及对其进行基准真相分类(groundtruthclassifiation)。然后通过梯度下降法来调整卷积网络1410的权重值,这递增地改进了某类图像及其对应的输出节点的值之间的一般关联。同时,卷积网络1410自动学习处于其模型所呈现的每个比例(从最小可能的像素水平到接近原始输入的比例的比例)下的有用特征。为了使卷积网络1410受到额外的看似可信的输入特征变化的影响,将有限的变换族应用于输入图像,该变换族涉及镜像映射、旋转和少量的缩放。每个网络1410都在小型的验证集上大约训练到其性能的收敛。
对于dr严重度的分类,使用两个卷积网络1410的集合。经修改的视网膜眼底图像171被提供作为一个网络1410的输入,同时局部对比度标准化图像(lcn)1000被提供作为另一网络1410的输入。根据dr严重度分类递增的次序,将每个网络1410的输出节点的索引设定为从0到4。这允许使预测的dr严重度由通过将每个输出节点的值与其索引的乘积相加得到的单个标量值来表示。最终dr严重度分数因此是两个卷积网络1410的输出的均值。然后,通过为dr严重度分数设定阈值以获得如根据验证集估计的期望灵敏度/特异性性能,来实现对测试图像的分类。选择为0.9的阈值足以进行筛查的目的。对于amd和青光眼严重度的分类,遵循类似的步骤,不同的是,这些病症中的每一种仅允许从0到2三种严重度类别。amd的阈值选择为0.40,青光眼的阈值选择为0.70。
额外地,对卷积网络1410进行训练,以拒绝图像质量不足的图像以及作为无效输入(即,不是视网膜图像)的图像。对于后一种模型,在训练中将各种各样的自然图像用作否定类别。为了计算实验结果,被这些模型中的任何一个模型拒绝的图像都被认为被推荐进行进一步的转诊。一旦分析了图像后,就将为用户生成报告。平均而言,深度学习模型花费大约5分钟来使用单个图形处理单元(gpu)分析1000张图像(每幅图像0.3秒)。
可转诊pr验证数据集、vtdr验证数据集、可转诊gd验证数据集以及可转诊amd验证数据集
图11a和图11b中汇总了验证数据集的详细信息。对于dr,主要验证数据集与在2014年至2015年间就诊的患者的dr筛查项目(sidrp2014-15)相同。初步分析确定dls1400在主要验证数据集中检测可转诊dr和vtdr方面是否与专业评级人员相同或者比专业评级人员更好。
dls1400还使用10个额外的具有来自不同环境(社区、基于人群和基于诊所)的糖尿病参与者的多族裔群组进行外部验证。数据集1由中国广东省的中山眼科中心在社区中筛查出的中国糖尿病患者组成。数据集2-4是从基于人群的新加坡眼科疾病流行病学(seed)项目招募的华人糖尿病参与者、马来西亚人糖尿病参与者和印度人糖尿病参与者。数据集5和6是分别来自北京眼科研究(bes)和非裔美国人眼科研究(afeds)的对华人参与者和非裔美国人参与者的基于人群的研究。数据集7至10是来自澳大利亚墨尔本皇家维多利亚眼科和耳科医院的高加索人患者、来自墨西哥眼科学中心的西班牙人患者以及来自香港中文大学和香港大学的中国患者的基于临床的糖尿病研究。在所有数据集中患者没有重叠。
为了实现对可转诊gs和可转诊amd的二次分析,还在主要验证群组sidrp2014-15中对dls1400进行了验证。
最后,使用相同的主要验证群组,对用于检测总体可转诊状态(可转诊dr、可转诊gs或可转诊amd)的两个dr筛查模型(全自动模型与半自动模型)进行比较。
视网膜照片协议
跨这些群组使用了不同的相机。对sidrp参与者、广东华裔参与者、和墨西哥西班牙裔参与者的所有眼睛进行非散瞳的二视场(以视盘为中心和中央凹为中心的)视网膜摄影。对新加坡华裔马来西亚人患者、印度人患者、北京华人患者、非裔美国人患者、高加索人患者和香港华人患者进行散瞳的二视场视网膜摄影。视网膜图像不是跨各场所(例如,不同的闪光灯设置、瞳孔扩张状态、视野宽度(35度和45度))和相机(拓普康(topcon)、方舟(fundusvue)、佳能和卡尔·蔡司(carlzeiss)))都以标准化方式来捕获的。所有视网膜图像都具有jpeg压缩格式,分辨率在5-7兆像素之间,但是西班牙人的图像(大部分<1兆像素)除外。
可转诊dr、vtdr、可转诊gs和可转诊amd的定义
使用国际分类dr量表来定义所有视网膜图像的dr水平。可转诊dr被定义为糖尿病性视网膜病变严重度水平为中度非增生性dr(npdr)或者更差、糖尿病性黄斑水肿(dme)和/或不可打分的图像,以及;vtdr被定义为重度npdr和pdr。如果在视网膜图像的后极处检测到硬性渗出液,则评估存在dme。如果照片的三分之一以上被遮挡,则认为该照片是“不可打分的”,并且该个人被认为具有可转诊dr。可转诊gs被定义为:竖直杯/盘直径比≥0.8、神经视网膜边缘局灶性变薄或者缺口产生、视盘出血、或者局部视网膜神经纤维层缺陷。使用年龄相关性眼疾研究(areds)评级系统,可转诊amd被定义为:存在中间amd(众多中间尺寸的玻璃疣,1个最大线性直径>125um的大型玻璃疣,非中枢性地理萎缩(ga)和/或晚期amd(中央ga或者新生血管amd)。
参考标准
对于主要验证数据集(sidrp2014-15),参考标准是视网膜专家评级。dls1400的性能根据该参考标准进行评估。dls1400的性能然后参考视网膜专家评级与专业评级人员的评估进行比较。
对于来自(图11a中所呈现的)验证数据集1至10的所有其他视网膜图像,其本国的经过训练的专业评级人员是参考标准,并且根据该标准对dls1400的性能进行评估。
对于可转诊gs和amd的二次分析,参考标准分别是青光眼专家和视网膜专家。对于使用全自动模型还是半自动模型的总体可转诊状态,参考标准(对于可转诊dr和可转诊amd)是视网膜专家并且(对于可转诊gs)是青光眼专家。
统计分析
最初,在整个分类阈值范围内计算sidrp2010-13训练数据集上dls1400的接收者操作特征(roc)曲线的曲线下方面积(auc)。然后选择达到预定的90%最佳灵敏度来检测可转诊dr和vtdr的分类阈值。假设dls1400的性能能够与专业评级人员的表现相媲美,并且dls1400的阈值点预设为90%的灵敏度(sidrp评级人员先前已达到了该水平)。类似地,对于可转诊gs和可转诊amd,阈值点分别预设为90%的灵敏度和80%的特异性。可以取决于筛查项目的特定需求来调整为dls1400的灵敏度或者特异性预设的阈值。
对于初级分析,通过以下方式来评估在正在进行的dr筛查项目(sidrp2014-15,主要验证集)的环境中dls1400的性能:确定dls1400是否达到了最佳性能并且等于或者优于在该筛查项目中专业评级人员对dr的评定。因此,在各个眼睛水平上根据参考标准(视网膜专家)计算dls1400在检测可转诊dr和vtdr时的auc、灵敏度、特异性、阳性预测值(ppv)和阴性预测值(npv),然后将dls1400与专业评级人员的评定进行比较。为了比较诊断测试,推荐参考黄金标准(视网膜专家)来计算95%的置信区间(ci)即dls1400和专业评级人员之间在真阳性比率(tpf,灵敏度)和假阳性比率(fpf,1-特异性)方面的绝对差。mcnemar的测试是针对成对的比例进行的,以检查在dls1400与评级人员之间在每个比率方面的显著差异。
执行以下次级分析。首先,排除既出现在sidrp2010-13训练集中又出现在sidrp2014-15主要验证集中的患者(n=6291,其在sidrp中多次出现),并且重复上述分析以避免训练与验证数据集之间的数据污染。如果任一只眼睛具有可转诊dr,则将患者视为患有“可转诊dr”。其次,仅在专业评级人员所指出的没有介质混浊(例如白内障)的较高质量图像中评估dls1400的性能。第三,计算按年龄、性别和血糖控制划分的auc次级组,以针对具有不同特征的患者来评估dls1400的表现。第四,参考经过训练的评级人员,对10个多族裔验证集(上述数据集1-10)重复所有分析。
对于次要分析,使用主要验证数据集(sidrp2014-15)分别参考青光眼专家和视网膜专家评估dl1400s在检测可转诊gs和可转诊amd时的性能。
最后,在检测总体参考状态(可转诊dr、可转诊gs或者可转诊amd)方面对两种不同的筛查模型(“全自动”与“半自动”)进行比较。图15示出了用于所述两种不同的筛查模型的两个流程图。流程图a示出了全自动系统1510。在全自动系统1510中,由dls1400针对dr、gs和amd分析所有视网膜图像。如果检测到三种病症(可转诊dr、可转诊gs或者amd)中的任何一种,则将视网膜图像分类为“可转诊”。然后将患者转诊至第三眼科中心。如果视网膜图像被分类为“非可转诊”,则计划在一年内对患者进行重新筛查。在全自动系统1510中,不需要人工评级人员。流程图b示出了半自动系统1520。半自动系统1520遵循与全自动系统1510相同的程序,只是在视网膜图像被分类为“可转诊”的情况下,这些视网膜图像会经历由人工评级人员实现的二次评级,在那里,将这些视网膜图像被重新分类为“可转诊”或者“非可转诊”。
计算根据患者的群集情况而调整的渐近两面95%ci,并且分别呈现出比例(灵敏度、特异性、ppv和npv)和auc。在灵敏度的估计值在100%的边界处的少数异常情况下,使用精确的clopper-pearson方法来获取ci估计值。所有分析均使用stata版本14(statacorp,美国德克萨斯州大学城)进行。
结果
在训练数据集中的76,370张图像(38,185只眼睛)中,分别有11.7%、3.0%、1.4%的图像具有任何dr、可转诊dr和vtdr,而在组合的主要和外部验证数据集中的112,648张图像(59,324只眼睛)中,分别有14.8.3%、5.3%和1.5%的图像具有任何dr、可转诊dr和vtdr。dr结果被汇总在图12a和图12b中。对于gs和amd,每种症状分别有2,658张图像(1,329只眼睛)和2,499张图像(2,499只眼睛)被视为“可转诊”。gs和amd结果被汇总在图13中。图16示出了参与sidrp2014-15(主要验证集)的患者的总体人口统计资料、糖尿病史和系统性风险因素(表4)。
图17示出了使用主要验证数据集(sidrp2014-15)参考视网膜专业标准得到的dls1400的诊断性能与专业评级人员的比对(表5)。如图20a-图20c中(曲线图a)所示,dls1400的auc对于可转诊的dr为0.936,对于vtdr为0.958。dls1400在检测可转诊dr方面的灵敏度和特异性可与专业评级人员相比拟(dls:90.5%/91.6%比对评级人员:91.2%/99.3%)。对于vtdr,dls1400的灵敏度和特异性分别为100%和91.1%,而评级人员的则为88.5%和99.6%。在具有可转诊dr的眼睛之中,dls1400和评级人员的dme检出率分别为92.1%和98.2%。dls1400在检测vtdr方面更灵敏(100%比对88.5%),并且tpf要大11.5%(表5)。
在次级分析中,以多种方式证实了dls1400的稳定性。首先,dls1400在sidrp2014-15中的所有8,589名独特患者(与训练集没有重叠)中表现出可与专业评级人员相比拟的性能,结果与在图18中所示的主要分析(表6)相似。其次,在对具有优良视网膜图像质量(无介质混浊)的97.4%的眼睛(n=35,055)的子集分析中,对于可转诊dr和vtdr,dls1400的auc分别增加到0.949(95%ci:0.940-0.957)和0.970(0.968-0.973)。第三,如图20a-图20c(分别为曲线图b1、图b2、图b3)中所示,dls1400在按年龄、性别和血糖控制划分的患者的不同次级组中表现出可比拟的性能。第四,dls1400对不同社区、诊所和环境的多族裔人群表现稳定。在图11a中所呈现的额外验证数据集(数据集1到10)中,检测可转诊dr的auc、灵敏度和特异性的范围分别为从0.889至0.983;从91.8%至100%;以及从73.3%至92.2%;并且如图19a和图19b中所示(表7),vtdr的检出率为93%至100%。图20a-图20c(图c1和图c2)呈现了dls1400在10个验证群组中检测可转诊dr和vtdr的roc曲线。
如图21中所示(表8),对于次级分析,dls1400的auc、灵敏度和特异性对于可转诊gs分别为0.942、96.4%,87.2%,对于可转诊amd分别为0.931、93.2%和88.7%。
结果表明dls1400可以用于两种筛查模型:全自动模型检测总体可转诊病例(可转诊dr、gs或者amd)的灵敏度和特异性分别为93.0%(95%ci91.5%-94.3%)和77.5%(95%ci77.0%-77.9%),而半自动模型分别为91.3%(95%ci89.7%-92.8%)和99.5%(95%ci99.5%-99.6%)。
在图11a中所示的所有验证集(数据集1-10)中,当对同一图像进行两次测试时,dls1400的可重复性为100%,其中对于所有可转诊dr,vtdr、gs和amd的图像,dls1400产生的评级结果的第一次读数和重复读数相同。
使用来自世界各地多族裔数据集的近50万张视网膜图像,dls1400在dr筛查中的使用和适用性体现在几个关键特征上。首先,dls1400在新加坡正在进行的国家筛查dr项目中得到了验证,其中没有根据标准预先选择患者。dls1400的性能被证明可与当前的dr筛查系统相比拟,该当前的dr筛查系统基于受过训练的专业评级人员对视网膜图像的评定。使用具有不同族裔和设置(患者的人口统计资料、血糖控制、瞳孔扩张状态、视网膜相机、闪光灯设置和视网膜图像视野宽度)的10个额外的外部验证数据集来验证dls1400的一致性和诊断性能。其次,dls1400的诊断性能不仅在筛查可转诊dr和vtdr时非常出色,而且在筛查两种常见的威胁视力的病症(可转诊gs和amd)时也非常出色(所有auc>0.92;所有灵敏度>90%,所有特异性>85%),这对于此类dls1400在现实世界中采用的临床可接受性至关重要。最后,dls1400可以部署在两种dr筛查模型中:“全自动”筛查模型或者“半自动”模型,“全自动”筛查模型可以在没有任何现有dr筛查项目的情况下显示出最佳的在社区中检测所有3种病症方面的诊断性能,在“半自动”模型中,dr筛查项目已经存在(例如英国,新加坡),但是dls1400可以改善效率,降低成本并且节省人力资源。因此,在现实环境中采用dls1400系统可以增加筛查的次数,而没有当前的对基础设施和人力资源的需求。
由于在模型构建期间使用的训练数据集的多样性和大小,因此通过使用示例性方法100将视网膜图像修改为适合于输入到dls1400中的形式,dls1400可以用于筛查各种视网膜照片类型。因此,dls1400跨具有变化的图像质量、不同的相机类型、全身性血糖控制水平的不同患者状况并且跨多个族裔(即从非洲裔美国人和印度人的较深眼底色素沉着到高加索人的较浅眼底色素沉着)具有一致的诊断性能。此外,dls1400可根据可接受的临床表现指南诊断多种常见眼科疾病(可转诊dr和vtdr、可转诊gs和amd)。
值得注意的是,美国的少数群体(例如西班牙裔和非洲裔美国人)的dr筛查率较低。如图19a和图19b中所呈现的数据分别所示(表7),dls1400在非裔美国人和西班牙裔美国人中表现出出色的检测可转诊dr的性能,其中相应的auc分别为0.980和0.950。在这两个族裔中,vtdr的检出率均>97%。因此,使用该dls1400可以通过改进可及性来弥补筛查差距。
dls1400可用作自动化的第一手工具,用于对大量人群进行一般的眼科检查。dls1400还可以用作临床医生和评级人员的自动化助手,以获得第二意见。可替代地,dls1400还可以用作互联网上的独立的按需眼部诊断服务。
- 还没有人留言评论。精彩留言会获得点赞!