深度视觉处理器的制作方法
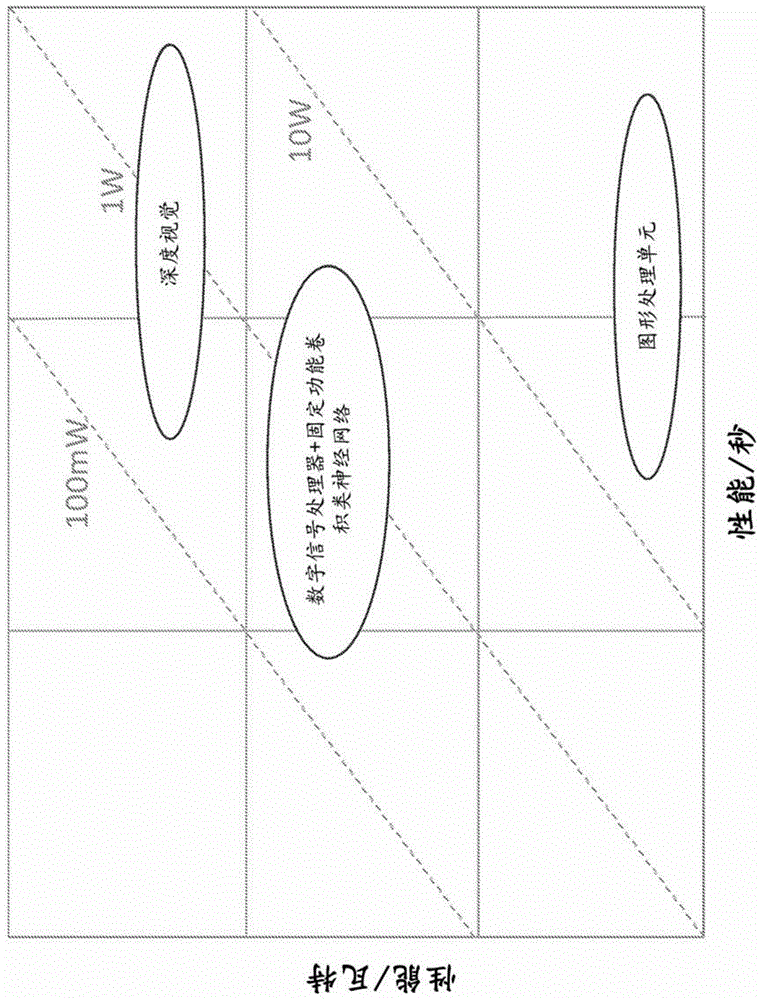
相关申请的交叉引用本申请要求于2017年7月5日提出、标题为“deepvisionprocessor”的第62/528,796号美国临时申请的优先权的权益,该美国临时申请通过引用以其整体并入本文中。版权声明此专利文档的公开内容的一部分含有受版权保护的材料。如在专利商标局专利文件或记录中出现,版权所有者不反对任何人对本专利文档或专利公开内容进行拓制,但无论如何将以其他方式保留所有版权。领域本公开涉及可编程处理器,且特别涉及可执行一种或更多种神经网络(neuralnetwork)技术(例如,深度学习技术)和计算机视觉技术(例如,传统计算机视觉技术)的较低能量的可编程处理器。背景依赖于深度学习的计算机视觉技术(诸如基于卷积神经网络(cnn)的计算机视觉技术)可以以可靠且稳健方式完成复杂任务。举例而言,汽车行业在自动驾驶车辆中且在安全特征(诸如汽车中的障碍检测和撞击避免系统)中部署高级计算机视觉芯片集。在制造和仓储部门中,实施神经网络和深度学习技术以开发执行类人类任务的适应性机器人。在安全和监督应用中,具有神经网络和深度学习能力的嵌入式装置依据大量数据进行实时图像分析。在移动和娱乐装置中,深度学习达成“智能”图像和视频捕获及搜寻,以及基于虚拟现实的内容的递送。在嵌入式装置中广泛采用神经网络和深度学习的一个障碍是神经网络和深度学习算法的极其高的计算成本。某些计算机视觉产品使用可编程的通用图形处理单元(gpu)。这些芯片可能是电力消耗性的,然而电池操作的嵌入式装置可被设计用于低电力的高效操作。甚至并非电池操作的装置(例如,可插入壁式插座中的装置)及以太网供电(poe)装置(诸如家用安全摄影机系统)也可(举例而言)由于热管理要求(诸如一装置可具有的热耗散量)而被设计用于低电力的高效操作。某些计算机视觉产品使用依赖于固定功能加速器的专门芯片,该固定功能加速器即使未必是电力消耗性的,也缺乏弹性和可编程性。概述下文的随附附图和实施方式中阐明了本说明书中所描述的主题的一个或更多个实施方案的细节。依据说明书、附图和权利要求将明了其他特征、方面及优点。此概述和以下详细描述皆不意欲定义或限制本公开的主题的范围。在本文中公开一种用于深度学习的处理器。在一个实施例中,该处理器包括:加载与储存单元,其被配置为加载且储存图像像素数据及样板数据(stencildata);寄存器单元,其实现分库式(banked)寄存器文件,被配置为:从该加载与储存单元加载且储存该图像像素数据的子集;且同时提供对储存于该分库式寄存器文件的寄存器文件项目(entry)中的图像像素值的存取,其中该图像像素数据的子集包括储存于该寄存器文件项目中的图像像素值;互连单元,其与该寄存器单元和多个算术逻辑单元通信,该互连单元被配置为:提供储存于该寄存器文件项目中的图像像素值;且提供与储存于该寄存器文件项目中的图像像素值对应的样板数据;以及该多个算术逻辑单元,其被配置为同时对来自该互连单元的储存于该寄存器文件项目中的图像像素值和与储存于该寄存器文件项目中的图像像素值对应的样板数据执行一个或更多个操作。附图简单说明在所有附图中,可重复使用参考符号来指示参考元素之间的对应性。提供附图以图解说明本文中所描述的实例性实施例且不意欲限制本公开的范围。图1是比较深度视觉(dv)处理器、具有固定功能卷积神经网络(cnn)的数字信号处理器(dsp)和图形处理单元(gpu)的性能的一实例性绘图。图2是比较为单维及二维(2d)像素数据的数字信号处理器的一实例性示意性图解说明。图3展示具有与静态随机存取存储器(sram)通信的一数字信号处理器/单指令多数据(simd)核心和一卷积神经网络加速器的一实例性处理器架构。图4展示一卷积引擎(ce)或dv处理器的某些实施例的一实例性架构。图5展示一dv核心的三个实例性计算流程。图6是深度学习工作负荷中的效率机会的一实例性图解说明。图7是利用数据重复使用机会的一深度视觉(dv)处理器架构的实例性图解说明。图8展示用于一卷积神经网络的实例性计算。图9展示一dv处理器架构至许多核心的一实例性扩展。图10a至图10b展示一dv核心的样板流的一寄存器文件架构的示意性图解说明。图11是用分库式寄存器文件架构实现的2d寄存器(2d_reg)抽象化的示意性图解说明。图12是展示一实例性智能寄存器文件架构的示意性图解说明。图13展示一传统向量寄存器文件与具有两个或四个寄存器的群组的向量寄存器文件的实例性比较。图14a至图14f展示在图像数据储存于v4r寄存器群组中的情况下使用一实例性stencil2d指令来产生多个3×3卷积输出的示意性图解说明。图15展示在输出储存于一累加器寄存器文件中的情况下stencil2d指令的实例性执行流程的示意性图解说明。图16是展示一实例性1×1卷积计算图表的示意性图解说明。图17a至图17f展示使用stencil1dv指令进行1×1卷积的实例性执行流程的示意性图解说明。图18展示使用一实例性dotv2r指令以使用储存于v2r寄存器群组中的数据产生两个128元素向量的向量-向量乘法的示意性图解说明。图19a至图19b展示在不具有16位至8位标准化的情况下dotv2r指令的实例性执行流程的示意性图解说明。图20a至图20c展示将一典型cnn运算操作映射至dv核心的示意性图解说明。图21展示用于将cnn运算操作映射至dv核心的伪程序代码。图22展示使用dv处理器进行的空间导数计算的实例性运算图表。图23a至图23b展示使用dv处理器进行的光学流运算的示意性图解说明。图24展示使用dv处理器进行的运动估计的示意性图解说明。图25展示图解说明dv处理器的所预计性能的实例性绘图。图26展示一深度视觉cnn映射工具的实例性工作流程。图27是展示一实例性dv处理器芯片的方块图。图28展示用于光学流的运动向量精细化的一实例性dv处理器架构。图29展示具有分散-集中支持的另一实例性dv处理器架构。图30是表示一dv处理器核心的方框图。图31是一fpga系统的实例性示意图。详细描述概述本公开针对视觉处理器和嵌入式深度学习(dl)计算机视觉软件两者提供一种新方法。本文中所公开的方法可由系统、方法、装置、处理器及处理器架构实现。本文中所公开的实现一深度视觉处理器架构的一深度视觉(dv)处理器可具有与用于一类似工作负荷的一gpu相比较高一个或更多个量级的功率效率(例如,高达两个量级)、低一个或更多个量级的成本(例如,至少一级)和/或比gpu更好的性能/瓦特(例如,好66倍的性能)。因此,该处理器可达成快速、功率高效且较低成本的本地与基于云的图像和数据处理。在某些实施例中,dv处理器可以是一种高性能、超低功率、可扩展的专用集成电路(asic)处理器。除传统视觉算法之外,其新颖、完全可编程的架构被设计用于机器学习(例如,深度学习)。对处理器进行补足的深度学习优化软件可使得复杂卷积神经网络(cnn)和其他算法能够高效地映射至嵌入式处理器以达成最佳性能。其减少层且修剪cnn以在嵌入式平台中达成最佳功率和性能。该软件包含最适合用于嵌入式处理器的较轻较薄cnn的一链接库。应用近年来,深度学习已通过使一基于人工智能的方法进行经典计算机视觉任务(诸如图像分类、目标检测和识别、活动识别等)而彻底改革计算机视觉领域。此方法已对该领域具有如此的变革性影响,使得机器在这些视觉认知任务中的某些视觉认知任务中已经开始超越人类。基于深度学习的视觉已用于数据中心中,且需要使大量装置(包含自动驾驶汽车、无人机、机器人、用于家庭监控以及安全/监督应用的智能摄影机、增强现实、混合现实和虚拟现实头戴式装置、移动电话、物联网(iot)摄影机等)具有视觉智能。取决于计算机视觉的自动化任务已跨越数个行业从实验概念演变为日常应用。随着对增强的驾驶员安全、远程监测及实时监督功能的需要继续增长,自动驾驶车辆、无人机及人脸识别系统可能对社会具有一变革性影响。在过去十年,虽然装置嵌入式摄影机和其他检测器的能力和性能已显著改良,但关于芯片设计和一给定操作所需要的计算的功率效率两者,所获取图像的计算处理已相对落后。本公开针对处理器设计提供一种深度视觉(dv)架构,其可在跨越数个行业的嵌入式装置中释放计算机视觉的潜力。dv架构的应用包含低成本超低功率摄影机中的识别任务至自动驾驶汽车中的复杂场景分析及自主导航。然而,此技术在嵌入式装置中的大规模采用的一个障碍是深度学习算法的高计算成本。当前,gpu是用于实施深度学习解决方案的主要平台,但gpu对于电池操作的嵌入式装置而言消耗非常多电力。同时,gpu对于这些目标领域中的诸多领域而言亦是太过昂贵的。在某些实施例中,本文中所公开的实施该dv处理器架构的一dv处理器具有与用于此工作负荷的一gpu相比较高若干量级的功率效率和低至少一个量级的成本。在某些实施例中,本文中所公开的一dv处理器可执行传统图像分析方法,诸如特征提取、边缘检测、过滤或光学流(opticalflow)。计算机视觉技术的应用包含汽车、运动及娱乐、消费性电子器件、机器人与机器视觉、医疗、安全与监督、零售及农业。已预计计算机视觉技术(例如,硬件和软件)的全世界收益到2022年将增长500%(从小于$100亿至接近于$500亿),其中汽车应用占最大收益份额,随后是消费性电子器件、机器人及安全应用。已预计这些市场分部见证嵌入式硬件(例如,检测系统和图像处理芯片)的大量销售,该销售占在一给定年内的总收益的约70%至80%。表1列出了在垂直市场内的非限制性实例性具体应用,其中对嵌入式计算机视觉的低功率高性能解决方案的需求预计在未来几年会显著增长。表1.具有计算机视觉能力的嵌入式装置的应用。高级驾驶员辅助系统。高级驾驶员辅助系统(adas)市场的一个驱动力是安全性。已预计仅在美国的年度道路交通损伤到2030年将高达360万,其中超出90%归因于人为失误及缺陷。用于控制这些事故的立法可驱动汽车安全特征(诸如adas)的广泛采用,该汽车安全特征补充和/或补足驾驶员警惕以实质上帮助减少或消除人为失误、损伤及死亡。在某些实施例中,汽车行业中开发adas子系统的公司可利用dv处理器。诸如bosch、delphi及continental的公司可连同适当软件链接库及参考设计一起利用本文中所公开的深度学习/计算机视觉芯片以集成至adas子系统中。汽车制造商可将adas子系统集成至汽车中。在adas解决方案空间中的两个公司是mobileye和nvidia–针对adas的开发和装运解决方案两者。mobileye的当前产品是固定功能,例如,其非常良好地执行一具体功能,诸如识别一“停止”标志或行人。nvidia的gpu产品可编程有任何目前最佳技术深度学习算法。然而,nvidia的解决方案是高度电力消耗性的且花费超过数百美元,或超过每芯片$1,000(例如,nvidiadrivepx2)。在下一个十年,每一辆新汽车可具有每天产生超过4tb的数据且需要50至100太拉(tera)浮点操作/秒(tflops)的运算处理功率的多个8k和4khd摄影机、雷达及光达。每一辆汽车可需要多个gpu来跟上不断增加的数据和运算循环的需要以处理该不断增加的数据和运算循环。mobileye的产品(尽管具成本效益)趋向于是严格的且不可编程的,且因此对于将在未来由汽车产生的数据量是不可扩展的。就成本、电力、性能、可扩展性及可编程性而言,dv处理器可克服这些障碍中的一者或多者。汽车市场总量已经每年固定在1.1亿个单位。虽然adas在此分部中的渗透率当前处于6%,但已预测其到2020年将上升至50%。若小客车市场总量存在低增长/不存在增长,则这使adas的可寻址市场份额在2020年达到5,500万个单位。本文中所公开的dv处理器架构可使这些解决方案的成本和障碍实质上降低以到2020年达成50%的一预测渗透率。因特网协议(ip)安全摄影机。在因特网协议(ip)安全摄影机分部中,每年装运6,600万个网络摄影机且存在对人和对象的分析、尤其是实时检测及识别的一增长需求。ip摄影机的某些终端市场(诸如医院)出于病人隐私原因而不允许将所记录视频上传至一服务器/云上。在这样的情形中,具有使用(举例而言)本文中所公开的系统、方法、装置、处理器及处理器架构实施的在边缘处提供检测和识别的一解决方案可确保合规性同时满足机构的安全需要。已在2017年预测实时边缘分析的可寻址市场份额到2020年上升至年度单位的30%。在ip安全摄影机分部中的公司(例如,摄影机和安全系统制造商,诸如axis、bosch、avigilon及pelco)可利用本文中所公开的dv处理器。摄影机制造商可利用本文中所公开的计算机视觉芯片和软件链接库。另一选择是或另外,摄影机soc(系统单芯片)解决方案提供商(诸如ambarella、geovision、novatek)可将本文中所公开的方法用在soc中,摄影机制造商可将soc集成至相机中。在ip安全摄影机市场内,当前分析方法包含基于软件的解决方案且通常(例如)在将视频馈送上传至云/数据中心之后脱机执行。此方法可能不满足对摄影机处的实时分析(诸如人和对象识别)的需要。为了边缘处的识别和检测,可能需要嵌入于摄影机中的一低功率高性能硅。由于可通过ip电缆路由至摄影机的有限功率,因此低功率在此分部中可能是重要的。本文中所公开的dv处理器可以良好地适合于解决此市场。在此空间中开发soc的公司是ambarella、hisilicon、fujitsu、geovision或grainmedia,它们利用本文中所公开的dv处理器。深度学习深度学习(dl)是指使用非常深的卷积神经网络(cnn)来完成运算任务的一种机器学习技术。卷积神经网络(cnn)可以指多层感知器(mlp)的特殊变体,该多层感知器含有可跨越空间或时间施加以将一输入量变换为一输出量的重复神经元层。一般在cnn中遇到的该重复层包括卷积、标准化、池化及分类。lenet-5(已彻底改革深度学习领域的第一cnn架构中的一者)被设计以执行字符识别且由两个卷积层、两个池化层及三个分类器或完全连接层组成。尽管lenet-5不以标准化层为特征,但最近网络已证明采用标准化层来改良训练准确度的功效。卷积层。卷积层构成cnn的一组成部分。cnn层可由以一个或更多个大小的过滤器库(bank)的形式配置的一可学习神经元集合组成,在空间(图像)上或在时间(语音)上使该可学习神经元卷积以识别输入特征图谱的可学习特性。这些过滤器库可将由在若干维度上延伸的若干个通道组成的一输入量映射至由涵盖维度的深度组成的一输出量。该过滤器库的输出可以是在维度上经配置以产生最后输出量的激活功能。卷积层的一功能可以是在不同空间或时间位置处学习相同特征。可通过用输入量使以过滤器库之形式配置的神经元卷积而达成此学习。由于跨越输入的空间维度采用相同过滤器,因此神经元能够共享权重,从而产生具有比传统mlp实质上小的内存占用面积的网络。卷积层趋向于是一cnn网络的运算密集组件。在cnn中采用的卷积核的大小实质上变化,其中在开始层中采用较大核大小,从而在稍后阶段中让位于较小核大小。含有大过滤器大小的初始层在捕获激活处可以是较佳的,这起因于高或低频率特征图谱。然而,采用较小过滤器的稍后层可捕获中间频率信息。较小过滤器大小可产生更有特色且更少的“死亡”特征。3×3的卷积在最近网络(诸如google之alphago网络或microsoft之深度残差网络)中已成为选择的过滤器。池化层。一般在一卷积阶段之后采用一池化层且跨越空间维度在每一深度层级处执行下采样的任务。池化功能(类似卷积层)以一滑动窗方式对数据样板进行操作,其中2×2和3×3的窗大小是更常见的。下采样操作符本质上可以是非线性的,其中最大值是最常使用的功能。然而,可使用诸如l2范数和求平均的其他功能。池化减少稍后阶段中的参数数目和运算量且通过不再强调所学习特征相对于其他特征的精确位置而防止过度拟合。标准化层。标准化层通过阻止权重分布自一个层至另一层太迅速地改变而加速训练。权重标准化可阻止非线性饱和,从而在不需要仔细参数初始化的情况下产生实质上加速的训练。在最近网络中标准化的一种方法是批标准化。批标准化在通过需要减少高达14倍的步骤而加速训练方面可以是高效的。可使用下文的方程式[1]在每一深度切片处对训练数据执行批标准化。其他标准化包含局部响应标准化和局部对比标准化。分类或完全连接层。完全连接(fc)层就像常规神经网络层且通常在卷积、池化和其他层的一序列之后采用。这些层通过将先前层的所有激活连接至输出神经元而计算最后输出。由于全部到全部的连接,这些层可产生许多参数和相当大量的存储流量。近年来深度学习已取得数个进展,从而引起尤其在计算机视觉领域中采用深度学习的一爆发。此广泛采用因在对象分类和识别方面比人类准确度好而变得可能。可通过回顾在过去几年imagenet大规模视觉识别挑战赛(ilsvrc)的结果而了解到深度学习在计算机视觉领域中的优势。ilsvrc是在斯坦福大学组织的一年度竞赛,其大规模地评估用于对象检测和图像分类的算法。在2010年和2011年,即使采用最好的传统计算机视觉技术,也分别导致28%和26%的高误差率。相比之下,深度学习方法仅在4年内使误差率降至3.7%的一非常低的值。由处理视觉信息的嵌入式装置采用更准确深度学习算法的一主要障碍是其计算复杂度。深度学习算法的增加准确度一般已通过采用愈来愈深且愈来愈大的网络而达成。在ilsvrc挑战项目中采用的cnn层的数目已自2012年的8个层(alexnet)迅速地上升至2015年的152个层(resnet-152)。googlenet–google开发的一受欢迎cnn(其是2014年ilsvrc的赢家)-需要大约30亿个计算操作来进行一个推断。为以一3.57%误差率对单个对象进行分类,2015年ilsvrc赢家resnet-152需要3,000亿个操作。预期在完全自动驾驶的汽车中的计算机视觉系统的计算工作负荷在500,000至1,000,000亿个计算操作/秒(tops)的范围内。可针对深度学习算法(诸如alexnet、bn-alexnet、bn-nin、enet、googlenet、resnet-18、resnet-50、resnet-34、resnet-101、resnet-152、inception-v3、inception-v4、vgg-16及vgg-19)利用一dv处理器以达成高于50%的准确度,诸如60%、70%、80%、90%、99%或更高。dv处理器执行的操作数目可以是5m、35m、65m、95m、125m、155m、200mgiga-ops(gops)或更多。层数目可以是8、19、22、152、200、300或更多个层。dv处理器可用于现有和新的深度学习算法及架构。gpu已用于达到tops的规模的工作负荷。gpu提供高计算吞吐量且同时其是完全可编程的,因此能够适应于改变的深度学习网络算法。其提供高计算吞吐量,可以是完全可编程的,因此能够适应于深度学习网络算法的不断改变的复杂度。然而,性能与可编程性的这一组合就功率和美元成本两者而言皆是有代价的。当今可用的一个嵌入式gpu是nvidia的tegrax1,其提供1tops的性能但消耗10w至20w的功率且花费数百美元,远远超出了大多数较小嵌入式装置的成本和功率预算。nvidia的drivepx-2(自动驾驶汽车的高端gpu解决方案)花费数千美元且消耗数百瓦特的功率以实现20tops/s的性能。给定这些汽车的50至100tops性能要求,一基于drivepx-2的系统将花费数千美元且消耗若干千瓦的能量,此对于除了极其昂贵的高端汽车以外的任何事物是不可行的。克服嵌入式系统上的深度学习网络的计算挑战的一种方法是开发固定功能硬件。然而,深度学习领域正在以这样的速度演变,使得在硬件中具有任何算法可能存在使芯片在一年内过时的风险。随着制作专用集成电路(asic)的成本每年上升,这样的方法可能是不可行的。在某些实施例中,本文中所公开的可编程处理器架构(其与gpu不同)可专门用于基于深度学习的计算机视觉任务。具有该架构的一dv处理器与gpu相比较可使深度学习计算的功率成本下降(举例而言)50倍且使美元成本下降(举例而言)多于10倍。本文中所公开的dv处理器架构良好地适用于迅速演变的深度学习领域,包含不同深度学习参数、输入通道和输出深度。该dv架构可使数据尽可能(或实际或期望地)接近于处理器以摊销存储功率耗散。实现dv处理器架构的一dv处理器可以是完全可编程的且提供与固定功能硬件相当的功率效率。一dv处理器可以是具有高效率的一低功率可编程图像处理器以用于图像处理应用。与当前行业标准相比较,一dv处理器可处理具有若干量级功率成本优点的深度学习任务。在某些实施例中,一dv处理器可以是在汽车安全、安全摄影机和自导无人机系统的市场分部中使用的一嵌入式计算机视觉处理器。与其他处理器相比较,一dv处理器可以是具有高性能功率包络的一低成本处理解决方案。gpu、具有固定功能cnn的dsp和dv处理器的实例性比较图1是比较深度视觉(dv)处理器、具有固定功能cnn的数字信号处理器(dsp)和图形处理单元(gpu)的性能的一实例性绘图。dv处理器可具有高效率,其中一完全可编程架构可自低于1w摄影机扩展至大汽车系统。具有固定功能cnn的dsp可比gpu更高效。然而,dsp可能不会良好地适应于改变的算法方法。而且,具有一固定功能cnn的一dsp可能具有受限的关键存储和计算优化。gpu可以是一非常弹性(flexible)的通用数据并行引擎,其可无缝地从小系统扩展至大系统。然而,gpu可具有非常高的功率、大小和成本。gpu对于深度学习可能是低效的。举例而言,gpu的每一核心可从储存器提取数据以处理单个像素。举例而言,gpu的不同核心可从l1储存器提取相同或不同像素的数据。昂贵的数据重新提取的过程可能是电力消耗性的,从而导致来自大数目个核心的显著硬件和能量额外负担。gpu可能需要大的昂贵数据储存装置。举例而言,一nvidiategrax1处理器可包含共享一64kb寄存器文件的32个核心的一群组。gpu需要维持用于在每一核心上调度的多个线程的数据。每一核心可能必须在其切换至不同线程时从大寄存器文件来回地连续地读取/写入数据。在具有64kb寄存器文件的情况下,每一核心(例如,每一核心可具有2个算术逻辑单元)需要2kb的寄存器储存装置。数字信号处理器(dsp)可以是单维或一维(1d)的且需要数据随机排列(shuffle)以与二维(2d)像素数据一起工作。图2是比较为单维和二维像素数据的数字信号处理器的一实例性示意性图解说明。dsp处理器固有地是1d的且一次对一个像素行进行操作。因此,执行重叠2d样板需要不必要的数据随机排列。举例而言,一二维像素数据可具有4×4的尺寸。即使一64元素向量寄存器可储存二维像素数据的16个元素,也可能需要数据随机排列将4×4像素数据变换成一维数据。若增加simd的向量大小以获得更多并行性,则simd的利用率会下降。这对于较小图像会发生。这对于多个非常长的指令字(vliw)插槽也会发生,此情况可通过使用多个小向量操作而缓解。但是,寄存器文件(rf)面积和能量成本可由于端口数目的增加以及对核对多个指令槽的数据旁路和互锁的需要而实质上增加。在某些实施例中,一dv处理器可具有比一dsp低的寄存器文件面积和能量成本。与dsp相比较,该dv处理器可具有相同数目或不同数目个端口(例如,更多端口或更少端口)。在某些实施方案中,该dv处理器可或可不实现核对多个指令槽的数据旁路和/或互锁。将一深度学习加速器添加至一dsp可能不会提高dsp效率。图3展示具有与静态随机存取存储器(sram)通信的一数字信号处理器或单指令多数据(simd)核心和一卷积神经网络(cnn)加速器的一实例性处理器架构。cnn计算的结构可以是改变的。举例而言,alexnet需要11×112d卷积,而inception-v2网络可需要1×3和3×11d卷积。可能需要在dsp或simd核心上执行许多cnn计算,这可需要穿过一sram在dsp或simd核心与cnn加速器之间进行许多来回通信。此来回通信可招致一大能量成本。一cnn加速器可能不使其他算法(诸如特征提取、分割或长短期记忆网络(lstm))加速。执行额外负担和数据移动可支配一处理器的功率和成本。指令执行额外负担可包含与加载储存单元、高速缓存管理、流水线管理、数据旁路逻辑、寄存器文件、计算操作、指令提取、指令译码、定序和分支或例外情况处理相关联的那些指令执行额外负担。相对于计算操作,l1存储器提取、l2存储器提取和dram提取可消耗50倍、400倍和2000倍的能量数量。对于一处理器,计算操作可使用处理器电力消耗总量的1%,而执行额外负担和数据移动可分别消耗处理器电力消耗总量的20%和79%。实例性卷积引擎架构和深度视觉处理器架构卷积引擎(ce)可以是可编程处理器。已在第9,477,999号美国专利中公开一ce引擎的特定实施例,该美国专利的内容在此通过引用以其整体并入本文中。简而言之,ce可实现专用于在计算摄影、传统计算机视觉和视频处理中流行的数据流的指令集架构(isa)。在ce或dv处理器的某些实施例中,因不需要完全可编程性且替代地以在深度学习中使用的关键数据流模式(pattern)为目标,处理器可以是高效的且被编程且在宽广范围的应用中重复使用。ce或dv处理器可囊括在下文的方程式[2]中所展示的映射-归约(map-reduce)抽象化。ce或dvimg*j[n,m]=r|l|<c{r|k|<c{map(img[k],f[n-k,m-l])}}[2]表2.传统cv的功率(瓦特)与性能(毫秒)的比较。缩写如下:整数像素运动估计(ime)绝对差和(sad)、分数像素运动估计(fme)、sift(尺度不变特征变换)和高斯差(dog)。ce或dv处理器架构可定义一抽象计算模型,称为映射-归约。此映射-归约计算抽象化是使用一基于类卷积样板的数据流的整个算法域的一广义表示。方程式[2]展示此广义计算模型,且表2展示各种典型成像操作可如何通过选择适当映射和归约函数以及样板大小而被表达为映射-归约计算。2d移位寄存器可以是用于图像数据的主要储存缓冲器。与一次存取一个行的传统寄存器文件不同,此寄存器允许读取其行、列或甚至2d子区块的能力。其还提供水平和垂直数据移位能力以支持类卷积滑动窗数据流。2d系数寄存器类似于2d移位寄存器,但不具有移位。2d系数寄存器用于储存卷积系数或在处理一图像或视频帧的不同部分时不改变的其他“恒定”数据。输出寄存器文件是具有仅行存取的一更传统的向量/simd寄存器文件。这可由位于映射-归约核心旁边的simd引擎使用,且还充当用于映射-归约核心的中间输出寄存器。ce或dv处理器可包含若干个接口单元(if)、alu、归约单元和simd。诸如水平if、垂直if和2dif的接口单元可用于从寄存器读取出适当大小的适当行、列或2d数据样板且基于大小和计算类型而将其路由至alu。alu层可包括可并行操作以在一单指令中实现大数目个计算操作的64、128、256或更多个alu。寄存器、接口单元和alu实现映射-归约抽象化的“映射”部分。归约单元支持“归约”抽象化,从而提供对各种归约类型(包含算术、逻辑和广义图表归约)的支持。除映射-归约核心之外,ce或dv处理器还可包含一宽广simd引擎以支持并不良好地映射至映射-归约抽象化的那些数据并行操作。在某些实施例中,dv处理器的一智能互连可实现一映射单元的若干个接口单元。图4展示ce或dv处理器的某些实施例的一实例性架构。ce或dv处理器40可包含加载与储存单元42、移位寄存器单元44、映射单元46、归约单元48和输出寄存器50。加载与储存单元42加载且储存去往和来自各种寄存器文件的图像像素数据和样板数据。为提高效率,加载与储存单元42支持多个存储器存取宽度且可处理未对准的存取。在一个实施例中,加载与储存单元42的最大存储器存取宽度是256个位。此外,在另一实施例中,加载与储存单元42提供交插存取,其中来自一存储器加载的数据被分割且储存于两个寄存器中。这在诸如去马赛克(其需要将输入数据分割成多个色彩通道)的应用中可能是有帮助的。通过设计加载与储存单元42来支持多个存储器存取宽度和未对准的存取,极大地提高了ce或dv处理器40中的数据流的弹性。也就是说,可经由一单一读取操作来存取加载与储存单元42中的任何数据,这节省时间和功率两者。移位寄存器单元44包含若干个1维和2维移位寄存器。具体而言,移位寄存器单元44包含第一1维移位寄存器52、2维移位寄存器54和2维样板寄存器56。一般而言,第一1维移位寄存器52、2维移位寄存器54和2维样板寄存器56将图像像素数据的一子集从加载与储存单元42提供至映射单元46,从而允许视需要移入新图像像素数据。第一1维移位寄存器52可由ce或dv处理器40用于一水平卷积过程,其中当一1维样板在一图像行上移动时,将新图像像素水平地移位至1维移位寄存器52中。2维移位寄存器54和2维样板寄存器56可用于垂直和2维卷积过程。具体而言,2维移位寄存器54可用于储存图像像素数据,而2维样板寄存器56可用于储存样板数据。2维移位寄存器54支持垂直行移位:当2维样板垂直向下移动至图像中时,将图像像素数据的一个新行移位至2维移位寄存器54中。2维移位寄存器54还提供对储存于其中的所有图像像素的同时存取,从而使得移位寄存器单元44能够将任何数目的期望图像像素同时馈送至映射单元46。标准向量寄存器文件由于其受限制的设计而不能够提供前文提及的功能性。2维样板寄存器56储存不随着样板在图像上的移动而改变的数据。具体而言,2维样板寄存器56可储存样板数据、当前图像像素或在窗化的(windowed)最小/最大样板的中心处的像素。将来自映射单元46和归约单元48的过滤操作的结果往回写入至2维移位寄存器54或输出寄存器50。输出寄存器52被设计成表现为2维移位寄存器以及向量寄存器文件两者。当将来自归约单元48的数据写入至输出寄存器50时,调用输出寄存器50的移位寄存器行为。输出寄存器50的移位寄存器功能性简化寄存器写入逻辑且减少能量,这在样板操作仅仅针对几个位置产生数据且新产生的数据需要与现有数据合并(其通常将引起一读取修改和写入操作)时是尤其有用的。具体而言,通过在来自归约单元48的每一写入操作之后立即使输出寄存器50的写入位置移位至下一空元素,可节省ce或dv处理器40中的时间和能量。当输出寄存器文件与某一种类的向量单元接口(interface)时调用输出寄存器50的向量寄存器文件行为。在移位寄存器单元44中使用2维移位寄存器54和2维样板寄存器56使ce或dv处理器40适合于图像像素数据的储存和存取。具体而言,由于图像像素数据包含图像像素值的行和列两者,因此储存和存取如在一2维寄存器中的图像像素数据会产生在储存或存取数据时卷积图像处理器的效率和性能的显著优点。如上面所讨论,数据额外负担(诸如预测、提取、储存和存取存储器中的数据)占通用处理器中处理时间的一大部分。因此,ce或dv处理器40是更高效的且性能比这样的通用处理器好。映射单元46包含若干个接口单元(if)58a-58f和若干个算术逻辑单元(alu)60。if58将由移位寄存器单元44中的移位寄存器中之一者提供的图像像素数据排列成将由alu60作用的一特定模式。排列该数据可包含提供图像像素数据的多个经移位的1维或2维区块,提供对图像像素数据的多个经移位的垂直列的存取,或提供图像像素数据的多个任意排列。产生图像像素数据的多个经移位的版本所需要的所有功能性被囊括在if58中。这通过在一个区块内高效地产生alu60所需要的图像像素数据而允许导线的一短路同时使ce或dv处理器40的数据路径的剩余部分保持为简单的且相对地摆脱控制逻辑。由于给if58分派任务以促进基于样板的操作,因此用于if58的多任务逻辑保持简单且阻止if58成为瓶颈。if58可包含被配置为以一特定方式排列图像像素数据的若干个任务特定if58。具体而言,if58可包含数据随机排列if58a、水平if58b、列if58c、第一2维if58d、1维if58e和第二2维if58f。数据随机排列if58a可耦合至2维移位寄存器54且被配置为将来自2维移位寄存器54的图像像素数据的一个或更多个任意排列提供至归约单元48。水平if58b可耦合至1维移位寄存器52且被配置为将来自1维移位寄存器52的一行图像像素数据的多个经移位的版本提供至alu60的第一输入62a。列if58c可耦合至2维移位寄存器54且被配置为将来自2维移位寄存器54的一列图像像素数据的多个经移位的版本提供至alu60的第一输入62a。第一2维if58d可耦合至2维移位寄存器54且被配置为将来自2维移位寄存器54的图像像素数据的2维区块的多个经移位的版本提供至alu60的第一输入62a。1维if58e可耦合至2维样板寄存器56且被配置为将来自2维样板寄存器56的样板数据的1维区块(行或列)的多个经移位的版本提供至alu60的第二输入62b。第二2维if58f可耦合至2维样板寄存器56且被配置为将来自2维样板寄存器56的样板数据的一2维区块的多个经移位的版本提供至alu60的第二输入62b。多个数据大小被if58中的每一个支持且可选择一适当数据大小。由于全部的数据重新排列由if58处理,因此alu60仅仅是固定点双输入算术alu。alu60可被配置为对给定图像像素和样板值执行算术操作,诸如乘法、绝对差、加法、减法、比较及类似者。映射单元46可以是可编程的,使得可(举例而言)由一使用者选择由if58提供至alu60中的每一者的图像像素数据的特定排列和由alu60中的每一者执行的操作。在映射单元46中提供这样的弹性允许卷积图像处理器40实现大数目个卷积操作,使得卷积图像处理器可执行各种图像处理技术。映射单元46的通用性在与移位寄存器单元44的效率组合时产生由于移位寄存器单元44和映射单元46两者中的数据写入和存取模式而是高度高效的一卷积图像处理器40,该数据写入和存取模式适合于图像像素数据且由于映射单元46的可编程性而是高度通用的。将alu60中的每一者的输出馈送至归约单元48。一般而言,归约单元48被配置为组合来自映射单元46的所得值中的至少两个值。由归约单元48组合的来自映射单元46的所得值的数目取决于在卷积过程中使用的样板的大小。举例而言,一4×4的2维样板需要一16:1归约,而一2×2的2维样板需要一8:1归约。归约单元48可被实现为一树且可从树的多个级分接出输出。在一个实施例中,复合归约可由归约单元48执行以便增加ce或dv处理器40的功能性,如下文进一步详细地讨论的。作为ce或dv处理器40的操作的一实例,现在描述使用4×4的2维样板数据的一卷积过程。将来自加载与储存单元42的样板数据加载至2维样板寄存器56的前四个行中。此外,将四行图像像素数据移位至2维移位寄存器54的前四个行中。在当前实例中,映射单元46中存在64个alu60。因此,可并行地对高达四个4×4的2维区块进行操作。第一2维if58d因此产生来自2维移位寄存器54的图像像素数据的4×42维区块的四个经移位的版本且将其馈送至alu60的第一输入62a。第二2维if58f将4×42维样板复制四次且将每一样板值发送至alu60的第二输入62b。64个alu60中的每一者然后对一不同图像像素和对应样板值执行一逐元素(element-wise)算术操作(例如,乘法)。然后将64个所得值递送至归约单元48,其中这些值(举例而言)通过对每一个4×4区块的所得值求和而针对一16:1归约与来自4×4区块(这些值起源于其中)的其他所得值组合。归约单元48的四个输出然后被标准化且写入至输出寄存器50。由于寄存器含有用于十六个过滤器位置的数据,因此继续上文所描述的相同操作,然而,第一2维if58d采用水平偏移来跳过已经处理的位置且获得新数据同时上文所描述的操作的剩余部分继续执行。一旦已对十六个位置进行过滤,便使现有行向下移位且使图像像素数据的一新行从加载与储存单元42进入2维移位寄存器54。数据处理然后在垂直方向上继续。一旦已对所有行进行操作,便再次从第一图像行开始过程,处理下一垂直条带且继续执行直至已对整个输入数据进行过滤为止。对于对称样板,if58在系数乘法之前组合对称数据(这是因为样板值是相同的)。因此,alu60可被实现为加法器而非乘法器。由于加法器花费比乘法器少2倍至3倍的能量,因此可进一步降低ce或dv处理器的能量消耗。表3.示例性卷积引擎指令和功能在一个实施例中,一额外simd单元64可被提供于ce或dv处理器40中以使得一算法能够对位于输出寄存器50中的输出数据执行向量操作。simd单元64可与输出寄存器50接口以执行常规向量操作。simd单元64可以是仅支持基本向量加法和减法类型操作而不支持较高成本操作(诸如存在于一典型simd引擎中的乘法)的一轻量单元。一应用程序可执行既不符合卷积区块也不符合向量单元的计算,或可以其他方式受益于一固定功能实施方案。若设计者想要构建用于此计算的一定制化单元,则卷积图像处理器允许固定功能区块对其输出寄存器50进行存取。在一个例示性实施例中,在额外simd单元64中实现额外定制功能区块,诸如用于运算ime、fme和fme中的哈达马变换中的运动向量成本的那些区块。在一个实施例中,ce或dv处理器40被实现为一处理器扩展部,将一小卷积引擎指令集添加至处理器指令集架构(isa)。可视软件中需要而通过编译器内在(compilerintrinsics)发布额外卷积引擎指令。表3列出根据各种实施例的可与ce或dv处理器40一起使用的多个例示性指令及其功能。表4.在一个dv核心上运行的传统cv算法的功率(瓦特)和性能(毫秒)与inteliris5100gpu的比较。dv核心可在功率的1/80处达成类似性能。dv处理器可实现一新指令集架构、寄存器文件组织和数据路径互连以使处理器更好地适用于深度学习。在某些实施例中,dv处理器可实现ce的某些实施例的特征。举例而言,dv处理器可执行传统cv算法。dv处理器可具有对深度学习的额外支持,而且具有用于由深度学习达成的额外优化的处理器微架构。可进一步降低架构的面积和功率要求。dv处理器的isa可基于一新颖寄存器文件组织以及一智能互连结构,其允许该dv处理器高效地捕获数据重复使用模式,消除数据传送额外负担,且达成每存储器存取的大数目个操作。在某些实施例中,dv处理器针对大多数图像处理应用相比于数据并行的单指令多数据引擎使能量和面积效率提高8倍至15倍,且与gpu相比较提高超过30倍。显著地,尽管提供一完全可编程解决方案,所得架构可在针对一单个内核优化的定制加速器的能量和面积效率的2倍至3倍内。表4展示dv的实例性性能。dv的改进。基于深度学习的网络支持除卷积以外的重要操作,诸如池化、修正线性单元层(relu)和矩阵向量乘法。可在分类器层中广泛地使用这些操作。dv处理器架构的指令集是足够多样的以在数据路径中高效地支持处理某些或所有深度学习构造。此支持使得dv处理器架构能够支持编译器优化,从而使得更容易写入用于深度网络的程序代码。在某些实施例中,dv处理器具有比ce的某些较早实施例好的性能和高的效率。寄存器文件架构。卷积引擎或dv处理器的某些实施例采用一个二维移位寄存器文件来促进基于样板的数据流。寄存器文件具有在水平以及垂直方向上独立地移位从而允许ce或dv处理器以相等容易度在一维内核和二维内核两者中利用数据重复使用的能力。虽然移位寄存器可良好地适用于执行各种大小的卷积,但其不能授予对其个别项目(如常规寄存器文件)的访问权可呈现关于支持其他深度学习层(诸如在ce的某些较早实施例中的relu、完全连接层、1×1卷积)的挑战。dv处理器的某些实施例解决这些挑战。ce或dv的某些实施例可通过以下方式解决此挑战:针对simd操作使用一单独寄存器文件,从而产生两个单独寄存器文件之间的额外数据传送。功率和性能可能会降低。在某些实施例中,dv处理器采用可高效地支持卷积以及relu、完全连接层和标准化层的一个寄存器文件。此外,ce的某些实施例的移位寄存器可被设计成使整个寄存器文件移位而不管所执行的移位的大小如何,这可以使用寄存器文件能量(例如,对于在深度学习网络中流行的小内核,诸如3×3的内核)。在dv处理器的某些实施例中,可不需要使整个寄存器文件移位(例如,取决于所执行的移位的大小)。另外或另一选择是,dv处理器的某些实施例的移位寄存器文件可储存同时与多个深度学习通道对应的数据。这通过多个深度内核改进输入通道数据的重复使用,从而减少处理器与l1存储器之间的流量和存储器用电量。在某些实施例中,dv处理器可利用一寄存器文件来获取群组中的访问权以及对移位寄存器文件项目进行存取,其中每一群组的大小对应于内核大小。dv处理器的移位寄存器文件架构可不需要在每次存取时使所有项目移位,从而允许在使用传统寄存器文件编译器的asic上实现移位寄存器文件,产生较小面积和能量用量。在某些实施例中,dv处理器的移位寄存器文件可具有基于触发器(flip-flop)的实施方案。在某些实施方案中,为高效地支持深度学习,dv处理器实现允许在具有同时储存多个群组的能力的情况下对寄存器文件项目群组进行移位操作的一寄存器文件。这将通过在处理器内部的深度内核来改进通道数据的重复使用,从而削减处理器与l1高速缓存之间的存储流量。除移位操作之外,dv处理器还可支持存取个别寄存器文件项目的其他方法,以支持除卷积之外的层(诸如relu、完全连接层和标准化层)。dv处理器在使用一传统寄存器文件编译器实现时可具有这些属性,因此最小化面积和能量用量。智能互连。在某些实施方案中,智能互连是ce和dv处理器的重要组件。智能互连可直接影响ce或dv处理器的可编程性。由于互连支持多个内核大小,因此其含有多个大的多路复用器(multiplexer)和众多导线。dv处理器的某些实施例可解决由导线和多路复用器形成的拥塞,因此需要较少流水线级来满足定时约束。在具有较少的多路复用器的情况下,面积可有利地更小。在某些实施例中,dv处理器利用一受欢迎的深度学习内核大小(例如,3×3的内核大小)作为基本构建区块以减少互连中的拥塞。通过支持作为基本构建区块的一个内核大小(或一个或更多个内核大小)且在基本构建区块的顶部上构建较大内核大小,可使dv处理器的互连的实现不那么复杂。这将缓解对导线和多路复用器的压力,但可为其他可编程性选项腾出空间。simd。ce或dv处理器的某些实施例支持simd操作,包含简单加法和减法。在ce或dv处理器的某些实施例中,采用与移位寄存器文件分开的一寄存器文件,这是因为simd操作对个别寄存器文件项目进行操作。在某些实施例中,本文中所公开的dv处理器扩展ce的某些实施例的simd指令以熟练地支持深度学习构造。除诸如乘法、加法和减法的常规simd指令以外,dv处理器还可针对矩阵-向量和矩阵-矩阵乘法被明确地优化以高效地支持1×1卷积和完全连接层。就此而言,dv处理器可运用用于支持样板指令中的映射与归约逻辑的组件且将这些组件优化以与simd操作一起使用,从而支持矩阵-向量和矩阵-矩阵操作。关于传统simd寄存器文件的一个挑战是寄存器文件项目的宽度必须匹配simd宽度。宽simd数组将需要宽寄存器文件项目。由于微架构限制,因此无法使寄存器文件的大小为任意地大。而且,对于所有操作(除几个操作以外),保持大寄存器文件项目充分变得不可行。在某些实施方案中,dv处理器的simd宽度可以是大的,但无需增加寄存器文件项目的宽度。就此而言,寄存器文件群组可被配置成使得多个寄存器文件项目可被结合在一起作为整体工作。这也将允许dv处理器在数据是小的时仅使用一个寄存器文件项目而在数据是大的时共同使用寄存器文件群组。在某些实施例中,dv处理器可实现本文中所描述的架构修改以扩展ce的某些实施例的范围,从而高效地解决传统计算机视觉以及深度学习两者的性能和能量需要。深度视觉处理器架构的实例在某些实施例中,深度视觉(dv)处理器架构扩展指令集架构、寄存器文件组织和数据路径互连以使其更好地适用于深度学习。图5展示一dv核心的三个实例性计算流程。像素处理计算可被抽象化为以下三个计算流程中的一个:dv处理器中的滑动窗、矩阵-向量计算和simd计算。该dv处理器架构可将对所有三个计算流程的高效支持组合在单个核心中。下面参考附图图解说明使用dv处理器架构进行的某些计算流程。dv处理器可以是可编程的、可扩展的或低功率的。dv处理器可具有以接近于一固定功能处理器的功率/成本达成的可编程性能。dv处理器可用于整个范围的视觉算法,诸如深度学习/cnn、传统计算机视觉(诸如光学流)、分割、特征提取、向量-向量和矩阵向量操作、复发率(recurrence)和lstm。dv处理器架构可以是可扩展的且可编程的。举例而言,可多次复制一个同质核心以扩展至高性能层级。作为另一实例,dv运行时驱动器可使软件自动扩展以利用较大或较少数目个核心,从而从开发人员抽象出这些细节。自动化映射(例如,在软件中)可支持宽广范围的cnn框架。dv处理器可具有用于各种深度学习网络的一优化的微架构。dv处理器可使得计算上具挑战性的任务由嵌入式装置执行。dv处理器可具有一较小总占用面积和改进的性能-功率包络。在某些实施方案中,dv处理器可以是高效的。它可最小化(甚至对l1存储器的)存储器存取。举例而言,数据可驻存于处理器核心内部的小的低能量缓冲器中尽可能长的时间。一大程度的并行在单个核心内是可能的。举例而言,可摊销指令执行机器的成本。每核心数百个算术逻辑单元(alu)操作是可能的。图6是深度学习工作负荷中的效率机会的一实例性图解说明。该图展示(举例而言)在一单个处理器核心内的三个重叠像素窗,其可为数据重复使用创造机会。图7是一深度视觉(dv)处理器架构(其利用数据重复使用的机会)的一实例性图解说明。可将所需要的所有像素的像素数据从l1存储器带到一智能寄存器。该架构可致使需要较少提取。在具有广泛数据重复使用的情况下,通过智能互连,100个算术逻辑单元可具有较佳利用率。在某些实施例中,可能需要较少核心。dv处理器可包含一专属寄存器文件和寄存器与alu互连架构。该寄存器文件可提供对在图像和媒体处理中涉及的各种存取模式(诸如2d样板、1d样板、列存取、2d向量和传统1d向量)的直接支持。该寄存器文件可通过将某些或大部分数据保持在一小数据储存装置中来消除对昂贵数据随机排列的某些或所有需要,因此最小化去往更昂贵存储器(例如,l1存储器)的需要。该dv处理器可借助2读取-1写入寄存器文件在简单的单一发布处理器核心中达成高量的并行(256个16位alu操作)。图8展示一卷积神经网络(cnn)的实例性计算。cnn可包含卷积层,后续接着修正线性单元(relu)层和批标准化层。在一项实施方案中,dv处理器的dv核心可通过将来自多个计算操作(例如,用于卷积的操作)的数据保持在寄存器文件中来消除对存储器的中间写入。相比之下,具有cnn加速器的simd处理器可需要在每一卷积之后将高精度中间值回写至存储器。可不在dsp中使批标准化加速,然而通过dv核心使批标准化加速。可扩展设计。可通过重复相同同质dv核心来达成可扩展性。举例而言,每一核心能够执行某些或所有视觉或深度学习工作负荷。深度学习算法可以是固有地大规模并行的。举例而言,在运行时可容易地在任一数目个可用核心上分布cnn计算。多个深度学习应用可在每一核心上同时运行。举例而言,可达成多个应用程序在任一同质核心子集上的运行时调度。图9展示一dv处理器架构至许多核心的一实例性扩展。该dv处理器可具有可从一个核心扩展至许多核心的类gpu运行时。dv处理器可使用直接存储器存取(dma)实现对存储器层次的明确管理。表5至表6展示dv处理器架构效率度量。表5.比较gpu与深度视觉处理器的dv处理器架构效率度量。gpudv每alu的储存1kb18个字节归约方案高精度加法器低成本归约网络表6.比较dsp/simd与深度视觉处理器的dv处理器架构效率度量。实例性深度视觉处理器实施方案dv处理器的某些实施例对一卷积引擎进行改良。使用cadence/tensilica处理器产生器工具构建dv处理器。该处理器产生器工具允许使用tensilica的tie语言为一处理器指定数据路径分量和所期望的指令集。ce的某些实施例的指令集架构被修改且被增强以使用tensilica指令扩展(tie)使对应数据路径分量相加。cadencetie编译器使用此描述来针对所创建的处理器配置来产生周期准确的仿真模型、c编译器和寄存器传送语言(rtl)。由tie编译器产生的仿真模型用于针对在dv处理器上运行的算法确定下文所展示的准确性能数。对于准确能量和面积数,cadencegenus和innovus工具用于合成且放置且路由设计且映射至tsmc28nmhpc标准单元链接库。此映射给出设计的面积以及可达成的时钟频率。用tsmc功率模型仿真布局后网络联机表以确定在用于真实工作负荷的设计中花费的功率。实例性寄存器文件组织1.为避免使整个移位寄存器文件移位,dv处理器架构可将寄存器文件划分成若干寄存器项目群组且增添对使这些群组移位以更好地支持较小内核大小(诸如3×3)的硬件支持。2.在某些实施方案中,以上寄存器文件可映射至标准寄存器文件编译器。可替代触发器而使用标准寄存器文件组件。当替代标准寄存器文件组件而使用触发器时,分组的移位寄存器文件的功率和性能可比非基于群组的移位寄存器文件高。3.为合并在一ce的某些实施例中使用的移位寄存器文件和单独simd寄存器文件,dv处理器架构可采用一标准向量/simd寄存器文件。可增强寄存器文件以还支持对寄存器项目(除个别项目之外)的群组的存取。可添加一单独指令以使寄存器群组移位以仿真移位寄存器文件行为。由于可在软件中执行移位,因此可影响功率和性能。4.在具有对寄存器群组的支持的情况下可存在向量寄存器文件的功率和性能折衷。在某一实施方案中,dv处理器可实现寄存器文件的一个或更多个存储器分库(memorybanking)策略,这是因为寄存器文件群组所添加的复杂度可阻止编译器推断标准寄存器文件组件。5.dv处理器可在具有不同寄存器文件组织的情况下就性能、功率以及可编程性容易度而言针对卷积算法来优化。实例性分库式寄存器文件架构图10a至图10b展示dv核心的样板流的一寄存器文件架构的一示意性图解说明。dv处理器的一寄存器单元可实现dv寄存器文件架构。为了高效样板计算,可需要对多个图像行的同时存取以及读取水平、垂直和二维像素子区块的能力。dv处理器可包含用作高效样板计算的一储存区块的一个二维寄存器(2d_reg)。可将像素移位能力添加至2d_reg以支持滑动窗流。然而,传统asic寄存器文件区块不支持这种2d寄存器。举例而言,dv处理器可使用一分库式寄存器文件架构或基于群组的移位寄存器架构(图11)实现2d_reg抽象化。举例而言,四个传统向量寄存器库可实现32个1行1d向量寄存器、16个2行2d向量寄存器(例如,两个寄存器的16个群组)或8个4行2d向量寄存器(例如,四个寄存器的8个群组)。在某些实施方案中,库数目可以是2、3、4、5、6、7、8、9、10、20、30或更多。每库的群组数目可以是2、4、8、16、32、64、128、256或更多。图12是展示一实例性智能寄存器文件架构的一示意性图解说明。寄存器文件在1个寄存器(vr)、2个寄存器(v2r)和4个寄存器(v4r)的群组中是可存取的。举例而言,v4r充当“2d寄存器”以储存支持2d样板和1d垂直样板操作的多个图像列。v4r可支持垂直行移位以促进滑动窗流。寄存器群组还可促进多个simd宽度(64、128、256或更多个元素)。图13展示一传统向量寄存器文件与具有两个或四个寄存器的群组的向量寄存器文件的一实例性比较。为避免使整个移位寄存器文件移位且用标准寄存器文件组件替换触发器且使用一软件编译器执行基于寄存器文件的优化,在某些实施方案中,dv处理器架构用32项目传统向量寄存器文件替换移位寄存器文件。由于传统向量寄存器文件通常允许一次仅存取一个寄存器文件项目,因此其无法支持对于高效地执行样板计算必要的向上/向下移位操作。已改变传统向量寄存器文件的语义以解决此挑战。已添加对一个、两个和四个寄存器的群组的存取,其中每一群组同时对在该群组内的所有寄存器进行读取/写入。加上对3×3(2d)、4×4(2d)、1×3(1d垂直)和1×4(1d垂直)作为用于2d和1d垂直样板操作的基本构建区块的支持,在某些实施例中,向上/向下移位操作可仅限定于四个寄存器项目的群组。为促进同时存取多个寄存器文件项目,可在四个寄存器项目的库中实现寄存器文件,其中每一库的宽度是一个寄存器文件项目的大小。可替代触发器而使用标准寄存器文件组件来实现这些寄存器库,从而导致较低寄存器文件功率,在软件中添加使寄存器群组移位的一单独指令可仿真移位寄存器文件行为同时最小化对功率和性能的影响。实例性智能互连组织1.dv处理器架构可通过支持3×3内核(或更高阶,诸如4×4)作为基本构建区块而简化互连以减少路由拥塞、功率和面积。在一项实施方案中,dv处理器架构可包含用于支持比3×3大的内核的累加器寄存器。累加器可不利地影响数据路径的定时(timing)。2.就性能和功率而言,dv处理器可通过本文中所公开的不同智能互连组织来针对卷积算法被优化。通过使用3×3(2d)、4×4(2d)、1×3(1d垂直)、1×4(1d垂直)、3×1(1d水平)和4×1(1d水平)作为基本建构区块以用于所有样板操作,dv处理器的互连样板可以是大小不可知的。还可以简化互连设计。dv处理器的累加器寄存器可允许来自基本构建区块的结果的累加以形成较大样板大小。这些寄存器可放置在归约级(或上文所描述的映射-归约抽象化)后面。这些简化集合已不仅降低了路由拥塞,而且改良了功率和寄存器文件面积。实例性simd1.dv处理器架构可支持1×1卷积、relu和其他操作。dv处理器可包含用于乘法、算术移位、比较和预测的执行操作的许多simd指令。2.dv处理器架构可通过(举例而言)实现对simd中的归约操作的支持而支持矩阵-向量和矩阵-矩阵操作。由于在将数据从乘法操作传送至归约指令时可发生精度损失,因此寄存器文件可支持写入大位宽数据操作。dv处理器架构可实现累加器以累加多个归约操作的结果。3.dv处理器架构可支持不同群组大小,该不同群组大小提供复杂度与效率之间的一良好折衷。群组大小可通过标准寄存器文件编译器影响寄存器文件的映射。在某些实施方案中,dv处理器架构扩展一ce的某些较早实施例的simd支持以熟练地支持多样深度学习和传统计算机视觉构造。存取寄存器群组的能力允许dv处理器在不增加寄存器文件存取宽度的情况下支持各种simd宽度。关于传统simd寄存器文件的挑战一直是:寄存器文件项目的宽度可能需要匹配simd宽度。因此,一宽simd数组将需要一宽寄存器文件项目。然而,微架构限制,无法使寄存器文件的大小为任意地大。而且,对于所有操作(除几个操作以外),保持大寄存器文件项目充分地被利用变得不可行。因此,为在不增加寄存器文件项目的宽度的情况下使simd宽度保持为大的,dv处理器可采用寄存器文件群组,其中多个寄存器文件项目结合在一起作为整体工作。这允许dv处理器在数据是小的时仅使用一个寄存器文件项目而在数据是大的时共同使用两个或四个寄存器的群组。所有simd操作可具有1个寄存器、两个寄存器的一群组(也称为一2寄存器群组)和四个寄存器的一群组(也称为一4寄存器群组)。除常规simd指令(诸如乘法、算术操作、逻辑操作、归约等)之外,dv处理器架构还可针对矩阵-向量和矩阵-矩阵乘法明确地被优化以高效地支持1×1卷积和完全连接层。dv处理器架构利用用于支持样板操作中的映射与归约逻辑的组件且将这些组件优化以与simd操作一起使用。在某一实施例中,这可以以一向量-向量矩阵指令的形式达成,该向量-向量矩阵指令使用逐元素乘法作为映射操作,后续接着基于进位选择加法器的低成本、低能量归约作为归约步骤。结果是一融合的向量-向量乘法指令,具有比使用mac(乘法和累加单元)来执行相同操作高得多的一性能和能量效率。实例性指令实例性2d样板指令图14a至图14f展示在图像数据储存于一v4r寄存器群组(例如,四个寄存器的一群组)中的情况下使用stencil2d指令来产生多个3×3卷积输出的一示意性图解说明。在所图解说明实例中,v4r寄存器群组的每一行可包含64×8位元素。可从包含v4r寄存器群组(例如,关于一读取v4r操作)的一向量寄存器文件检索v4r中的图像数据,且一产生网络可产生从v4r寄存器群组读取的数据以用于由alu处理。一复制网络可复制从一系数寄存器文件读取或检索的权重。dv核心(例如,dv核心的alu)可使用288×8位alu使所产生的数据与对应的所复制的权重相乘。alu的输出元素可具有16位精度。在具有一归约树的情况下,可对alu的对应输出元素求和以产生一通道(诸如通道0)的32×16位元素。归约树的32×16位输出元素可往回储存至向量寄存器文件(例如,在向量寄存器文件的一个行中)。在某些实施例中,16位输出元素可在往回储存至向量寄存器文件之前归约为8位元素(例如,向量寄存器文件的一行的二分之一)。在某些实施例中,alu的输入元素和输出元素可具有8位精度。除实现3×3stencil2d指令之外,dv处理器还可实现stencil2d的其他变体(例如,4×4stencil2d)。可通过组合多个stencil2d操作而计算较大样板(诸如5×5、7×7和8×8)。在某些实施例中,可在不组合多个stencil2d操作的情况下支持较大样板。所支持样板变体可包含2d样板、1d水平样板或1d垂直样板。2d样板包含可由一样板产生网络直接支持的3×3和4×4样板产生。可通过累加来自多个较小样板的结果而计算较大样板大小(诸如5×5、7×7、8×8等)。可由一样板产生网络直接支持1d水平样板(诸如1×3和1×4样板产生)。可通过累加较小样板而计算较大样板(1×5、1×7、1×8等)。可由一样板产生网络直接支持1d垂直样板(诸如3×1和4×1样板产生)。可通过累加较小样板而计算较大样板(5×1、7×1、8×1等)。具有累加器寄存器文件的实例性2d样板指令在某些实施例中,dv核心可包含累加器寄存器的一个或更多个累加器寄存器文件。一累加器寄存器文件可用于储存本公开的样板指令(例如,2dstencil、1dstencil等)的部分结果。指令(诸如stencil2d、stencil1dv或dotproduct)的结果可储存于一累加器寄存器文件而非向量寄存器文件中。图15展示在输出储存于一累加器寄存器文件中的情况下stencil2d指令的一实例性执行流程的一示意性图解说明。替代将卷积的部分结果保存于存储器(例如,图14f中所展示的一向量寄存器文件)中,可将部分结果保持在累加器寄存器文件的一个或更多个累加器寄存器中。可使用(举例而言)32×24位加法器使额外新结果与已经储存于累加器寄存器中的先前部分结果相加。有利地,部分结果不需要写入至存储器文件或从存储器文件往回读取,这节省电力和处理周期。使新结果与先前结果相加的明确向量add指令可能是不必要的,这节省处理周期。此外,累加器寄存器可具有比一向量寄存器文件高的精度。举例而言,一累加器寄存器文件可具有24位精度,且向量寄存器文件可具有8位精度。实例性1d样板指令图16是展示一实例性1×1卷积计算图表的一示意性图解说明。可通过以下方式计算cnn中的每个1×1卷积层的输出:使大小为“w”דh”的输入通道与一预先训练(pre-trained)的标量权重相乘,且然后将加权通道的输出加总起来以产生大小为“w”דh”的输出。举例而言,可使大小为64×64的输入通道与一预先训练的标量权重相乘,且可将加权通道的输出加总起来以产生大小为64×64的一输出。dv核心可支持stencil1d指令(例如,stencil1dv、stencil2dh)。图17a至图17f展示使用stencil1dv指令进行1×1卷积的一实例性执行流程的一示意性图解说明。可将四个输入通道的行“x”(例如,行0)加载至一v4r寄存器中(图17a至图17b)。每一行可包含64个8位元素。可将四个标量权重(其中每一权重与每一输入通道和每一输出对应)加载至一单个系数寄存器中(图17a至图17b)。产生区块产生v4r寄存器的1×4个值的64个列同时将系数复制64次(图17c)。图17c展示将一v4r的列平放。256个8位alu的alu数组(举例而言)执行使数据与系数相乘(图17d),而归约层执行4:1归约(图17e)。举例而言,可对四个对应元素求和。因此,将256个输出归约至64个。所产生的输出数目可以是64(其中每一输出为16位宽)且写入至一v2r寄存器(图17f)。图17f展示64个输出具有16位精度。实例性dotv2r指令图18展示使用一实例性dotv2r指令以使用储存于一v2r寄存器群组中的数据产生两个128元素向量的一向量-向量乘法的一示意性图解说明。在图18中所展示的dotv2r指令的实例性执行流程中,将归约树的64个16位输出转换为8位输出。图19a至图19b展示在不具有16位至8位标准化的情况下dotv2r指令的实例性执行流程的示意性图解说明。归约树的输出在不同实施方案中可以是不同的,诸如64×8位输出(图18)、2×16位输出(图19a)和4×16位输出(图19b)。dv处理器可支持点积的其他变体,诸如dotvr(1个寄存器的一群组)、dotv4r(4个寄存器的一群组)。实例性算法实例性cnn图表算法图20a至图20c展示将一典型cnn计算操作映射至一dv核心的一示意性图解说明。举例而言,cnn计算操作可包含cnn的一层的输入的通道0的3×3卷积、输入的通道1的3×3卷积、以及使两个3×3卷积的输出相加以产生一输出。图20a展示通道0输入的卷积,此包含使用stencil2d指令计算1个输出行。图20b展示通道1输入的卷积,此包含使用stencil2d指令计算1个输出行。图20a展示两个卷积的求和,此包含使用addv4r指令使四个输出通道行相加。图21展示用于将cnn计算操作映射至dv核心的伪程序代码。实例性光学流算法图22展示使用dv处理器进行的空间导数计算的一实例性计算图表。表7展示空间导数计算至dv核心的一实例性映射。图23a至图23b展示使用dv处理器进行的光学流计算的一示意性图解说明。图23a展示使用stencil1dh操作进行的导数x的一实例性计算。图23b展示使用stencil2d操作得出的一实例性3×3窗化总和。为执行光学流的运动向量精细化,针对每一像素从所计算出的运动向量提取5×5窗且使用addrvr来使多个像素的运动向量与图像基地址相加且产生32个连续像素的5×5窗的地址。然后,dv处理器可将地址发送至分散/集中队列,且从所有地址搜集数据且精细化运动向量。表7.空间导数计算至dv核心的实例性映射。计算步骤所使用的指令导数xstencil1dh–1d水平样板指令导数ystencil1dv–1d垂直样板指令平方multv4r–对4个寄存器的一群组的simd指令乘法multv4r–对4个寄存器的一群组的simd指令窗化总和stencil2d–2d样板指令实例性运动估计图24展示使用dv处理器进行的运动估计的一示意性图解说明。实例性深度视觉处理器性能判定使用目前领域中最佳的计算上密集型深度学习网络对照gpu解决方案对dv处理器进行基准测定。为证实dv架构,对于以下cnn,对照tegrax1(当前可在市场上购得的嵌入最大功率的gpu)比较新深度学习处理器的推断功率和性能:1.四层cifar10cnn(cs.toronto.edu/~kriz/cifar.html)。cifar-10分类是机器学习中的一常见基准问题。该问题是跨越10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车)将32×32像素rgb图像分类。数据集提供用于训练cnn模型的50,000个图像和用于证实分类准确度的10,000个测试图像。用于cifar-10的特定模型是在一gpu上几个小时训练时间内达成85%的准确度的一个多层架构。cifar10具有大约1m个参数且需要大约40m个操作以计算对一单个图像的推断。2.googlenet。googlenet是用于分类和检测的一22层深度卷积神经网络架构。在2014年imagenet大规模视觉识别挑战赛(ilsvrc2014)(分布在1,000个类别上的1,200万个图像的一训练集)中,googlenet设定用于分类和检测的新的领域中最佳技术。此网络引入允许作者使用比alexnet少12倍的参数的一新inceptioncnn架构,其是最受欢迎的深度学习网络同时达成一显著高的准确度。googlenet使用7m个参数且需要大约3g个操作来计算对一单个图像的推断。3.facenet。facenet是用于识别人脸的最准确网络之一。由google开发,其关于面部识别数据集“人面数据库(labeledfacesinthewild)”(其由来自因特网的13,000个面部图像组成)声称99.63%的准确度。“使用一新颖在线三重训练方法产生的大致对准的匹配/非匹配面部补片(patches)的三联体”。facenet使用7m个参数且需要大约0.5g个操作来计算对一单个图像的推断。对照tegrax1对一dv核心上的这些各项进行的基准测定涉及以下步骤:a.使用dv指令集架构在软件中实现优化的cnn功能的链接库。此链接库将允许我们通过使用这些基本基元(underlyingprimitives)容易地在dv核心上实现任何深度学习网络。b.使用googlenet、cifar10和facenet的caffe(caffe.berkeleyvision.org/,由berkeleyairesearch开发的一深度学习框架)实施方案作为一参考,实现这三个网络的matlab版本,且创建适合用于嵌入式部署的一固定点版本。c.在固定点matlab实施方案作为一参考的情况下,使用优化的cnn链接库作为基本构建区块来在dv处理器上实现这些网络。d.使用cadencecad工具来将处理器及其相关联存储器映射至tsmc28nmhpc标准单元链接库且创建用于准确功率和面积测量的一平面图。e.创建用于所映射的处理器的功率和性能测量脚本。f.测量基准cnn的功率和性能且以对照在一nvidiajetsontegrax1板中运行的gpu实施方案为基准进行测定。实例性深度视觉处理器性能表8至表10展示一dv处理器的实例性性能度量(28nmtsmchpm,以800mhz运行)。inteliris5100是一750gflopsmobilegpu,因此其具有一tegrax1gpu的性能的大约0.75倍。图25展示图解说明一深度视觉处理器的所预计性能的实例性绘图。在确定所预计性能中使用的代表性cnn模型包含用于对象分类(例如,googlenet、resnet、inceptionnet)、面部识别(例如,facenet)和图像分割(例如,segnet、fcn)的模型。表8.dv处理器的实例性googlenet性能googlenet性能功率deepvisiondv100128个推断/秒1.07wnvidiategrax133个推断/秒11wmovidiusmyriad215个推断/秒1.2w表9.dv处理器的实例性segnet性能segnet性能(256x256)功率deepvisiondv1009个帧/秒1.1wnvidiategrax1大约3个帧/秒10w至20w表10.传统计算机视觉技术的实例性dv性能。实例性深度视觉cnn映射工具工作流程图26展示一实例性深度视觉cnn映射工具工作流程。对dv处理器进行补足的深度学习优化软件可使得复合cnn及其他算法高效地映射至嵌入式处理器以达成最佳性能。其可减少层且修剪cnn以达成嵌入式平台中的最佳功率和性能。软件可包含最适合用于嵌入式处理器的较轻、较薄cnn的一链接库。实例性深度视觉处理器图27展示一实例性dv处理器芯片。该dv处理器芯片可包含8个核心@800mhz(例如,使用28nmtsmc制造)、1mbl2存储器、64kbl1数据存储器、16kbl1指令存储器和pciexpressgen2×4。该芯片可在具有1w电力消耗的情况下具有4tops性能。该处理器可具有20mm2的晶粒面积(diearea),其封装在15×15mm2fbga中。该dv处理器芯片可支持8位、16位、32位整数操作。该dv处理器芯片可通过其ddr控制器利用ddr3或lpddr3存储器。图28展示一实例性dv处理器架构。举例而言,针对每一像素从所计算运动向量提取5×5窗,使用addrvr来使多个像素的运动向量与图像基地址相加且产生32个连续像素的5×5窗的地址。随后,将地址发送至分散/集中队列且从所有地址搜集数据且精细化运动向量。图29展示另一实例性dv处理器架构。在神经网络中,两种类型的层多层感知器(完全连接层)、rnn/lstm通常需要具有可运行高达数百兆字节的大小的大数目个参数。这些参数一般用于关于传入数据执行矩阵-矩阵乘法以产生特定数目个输出。由于这些参数的大小可以是大的,因此减小这些参数的大小会是有利的。实质上修剪参数而不影响神经网络的准确度可能是可能的。然而,修剪参数创建稀疏性且密集矩阵-矩阵乘法改变为稀疏矩阵-矩阵乘法。在某些实施方案中,为促进稀疏向量乘法,dv处理器架构在l1存储器系统处包含分散-集中支持。可使用在l1存储器的每一库前面的队列实现分散-集中功能性。这些队列含有由参数的基地址加上稀疏参数的索引构成的关于输入数据的地址。从与稀疏参数对应的队列提取的输入数据在传递至处理器之前被累加至一向量寄存器中。在处理器内部,使此输入数据与参数数据相乘以执行一密集向量-向量乘法。图30是表示dv处理器芯片的一框图。该处理器可包含像素计算区块和位计算区块。像素计算区块的非限制性实例包含样板产生网络(例如,从v4r或vr产生3×3、4×4、3×1、4×1、1×3、1×4的重叠样板)、simd路由网络(例如,以传统simd方式或对多个向量行操作的增强的“2dsimd”路由数据)、系数寄存器(例如,储存非样板数据,诸如过滤器权重、运动估计参考宏区块等)、系数复制网络(例如,形成系数之多个复本以并行地进行多个样板操作)、alu(例如,支持乘法、加法及其他算术操作的多精度8位/16位/32位alu)和多层级归约网络(例如,支持多个层级的基于求和的归约(4:1、16:1、…128:1、9:1、3:1))。位计算区块的非限制性实例包含位向量寄存器(例如,每一向量寄存器含有48×2位元素)、位样板产生网络(例如,从位向量寄存器产生重叠样板)、位simd路由(例如,以传统simd方式路由位向量数据)、逻辑单元(例如,支持逻辑操作,诸如比较、大于等)和多层级逻辑归约网络(例如,基于and/or操作的逻辑归约)。在某些实施例中,dv处理器芯片可以是通过一总线基础结构(例如,armaxi总线基础结构)与(举例而言)一ddr控制器和一pciexpress控制器通信的一8核心计算机视觉处理器芯片。在某些实施方案中,一dv处理器可具有硬件压缩支持,以降低大cnn模型的存储器大小和带宽要求。实例性工作原型在某些实施例中,dv处理器的一工作原型可被实现以验证一真实嵌入式系统中的一实时应用程序的性能。可以以tsmc28nmhpc工艺(其包括具有800mhz的一目标频率的8个dv核心)制作一asic芯片。另一选择是或另外,可使用dv处理器架构的一基于fpga的处理器原型以证实性能度量。一xilinxzc706fpga原型板可用于实现一真实嵌入式系统且用实时视频数据测试处理器。此系统(图31)可用于从一视频摄影机实时捕获视频,使用在dv核心上运行的cnn来处理该视频以检测流(stream)中的对象,且然后使用在主机arm处理器上运行的一嵌入式linux应用程序来在一所附接显示器上显示结果。此原型可并入有单个dv核心且在fpga中达成的预期频率在25mhz至50mhz的范围内。因此,此原型的预期性能可比asic产品低150至300倍。不太复杂的cifar10cnn可用于实现一实时应用情景:直播视频流中的对象的实时分类可代表在安全摄影机中以及由自主导航汽车、无人机和机器人频繁地使用的对象分类任务。可达成以85%或更高的一准确度在来自10个不同类别的对象之间以24个帧/秒实时进行对象分类。举例而言,可达成在每帧检测多个对象的情况下在数百个类别之间进行分类的95%准确度。使用facenet进行的实时面部识别代表安全和家用摄影机的使用情形,这允许将已知人员或家庭成员与陌生人或罪犯区分开。深度视觉处理器可映射至fpga且实现l1/l2sram。该深度视觉处理器可与arm主机的xilinx硬件ip、ddr控制器和hdmi输入/hdmi输出整合在一起。dma可被配置用于使视频数据在hdmi输入/hdmi输出与ddr之间以及在arm与dv协处理器(co-processor)之间移动。嵌入式petalinux基础结构可连同用于hdmiip和视频dma的驱动器一起部署在arm上。api和链接库可用于arm主机处理器与dv处理器核心之间的通信。系统可与图形linux应用程序一起使用,该图形linux应用程序从摄影机捕获视频帧、将每一帧传递至dv处理器以使用cifar10cnn执行对象检测且在附接至板的图形显示器上显示结果。额外方面在第一方面中,公开一种处理器。该处理器包括:加载与储存单元,其被配置为加载且储存图像像素数据和样板数据;寄存器单元,其实现分库式寄存器文件,该寄存器文件被配置为:从该加载与储存单元加载且储存该图像像素数据的子集;且同时提供对储存于该分库式寄存器文件的寄存器文件项目中的图像像素值的存取,其中该图像像素数据的该子集包括储存于该寄存器文件项目中的该图像像素值;互连单元,其与该寄存器单元和多个算术逻辑单元通信,该互连单元被配置为:提供储存于该寄存器文件项目中的该图像像素值;且提供与储存于该寄存器文件项目中的该图像像素值对应的样板数据;以及该多个算术逻辑单元(alu),其被配置为同时对来自该互连单元的储存于该寄存器文件项目中的该图像像素值和与储存于该寄存器文件项目中的该图像像素值对应的该样板数据执行一个或更多个操作。在第二方面中,如方面1的处理器,其中该分库式寄存器文件包括多个向量寄存器库。在第三方面中,如方面2的处理器,其中该多个向量寄存器库中的一个库的宽度与该分库式寄存器文件的一个寄存器文件项目的大小是相同的。在第四方面中,如方面2至3中任一项的处理器,其中该多个向量寄存器库包括四个向量寄存器库。在第五方面中,如方面4的处理器,其中该四个寄存器库被配置为实现32个1行1d向量寄存器、16个2行2d向量寄存器、8个4行2d向量寄存器或其一组合。在第六方面中,如方面1至5中任一项的处理器,其中该处理器被配置为使用该分库式寄存器文件实现多个较小样板指令。在第七方面中,如方面6的处理器,其中该多个较小样板指令包括3×3stencil2d指令、4×4stencil2d指令、1×3stencil1d指令、1×4stencil1d指令、3×1stencil1d指令、4×1stencil1d指令或其组合。在第八方面中,如方面7的处理器,其中该多个较小样板指令包括使用该1×3stencil1d指令、该1×4stencil1d指令、该3×1stencil1d指令、该4×1stencil1d指令或其组合来实现的1×1样板指令。在第九方面中,如方面6至7中任一项的处理器,其中该处理器被配置为使用该多个较小样板指令实现多个较大样板指令。在第十方面中,如方面9的处理器,其中该多个较大样板指令包括5×5stencil2d指令、7×7stencil2d指令、8×8stencil2d指令、1×5stencil1d指令、1×7stencil1d指令、1×8stencil1d指令、5×1stencil1d指令、7×1stencil1d指令、8×1stencil1d指令或其组合。在第十一方面中,如方面9至10中任一项的处理器,其中该多个较大样板指令包括n×1stencil1d指令或1×nstencil1d指令,其中n是正整数。在第十二方面中,如方面9至11中任一项的处理器,其中该多个较大样板指令包括一n×mstencil2d指令,其中n和m是正整数。在第十三方面中,如方面1至12中任一项的处理器,其中该互连单元被配置为提供储存于该寄存器文件项目中的该图像像素值中的3×3图像像素值。在第十四方面中,如方面13的处理器,其中该互连单元包括被配置为提供从该3×3图像像素值累加的x×y图像像素值的累加器单元,其中x和y是正整数。在第十五方面中,如方面1至14中任一项的处理器,其中该处理器被配置为使用该分库式寄存器文件实现一个或更多个dotv2r指令。在第十六方面中,如方面1至15中任一项的处理器,其中该寄存器单元被配置为:加载且储存该alu的结果。在第十七方面中,如方面1至15中任一项的处理器,其还包括一累加器寄存器文件的多个累加器寄存器,该多个累加器寄存器被配置为:加载且储存该alu的结果。在第十八方面中,公开一种实现分库式寄存器文件的处理器核心的寄存器单元。该寄存器单元被配置为:加载且储存图像像素数据的子集;且同时提供对储存于该分库式寄存器文件的寄存器文件项目中的图像像素值的存取,其中该图像像素数据的该子集包括储存于该寄存器文件项目中的该图像像素值。在第十九方面中,如方面18的寄存器单元,其中该分库式寄存器文件包括多个向量寄存器库。在第二十方面中,如方面19的寄存器单元,其中该多个向量寄存器库中的一个库的宽度与该分库式寄存器文件的一个寄存器文件项目的大小是相同的。在第二十一方面中,如方面19至20中任一项的寄存器单元,其中该多个向量寄存器库包括四个向量寄存器库。在第二十二方面中,如方面21的寄存器单元,其中该四个寄存器库被配置为实现32个1行1d向量寄存器、16个2行2d向量寄存器、8个4行2d向量寄存器或其组合。在第二十三方面中,公开一种处理器核心。该处理器核心包括如方面18至22中任一项的寄存器单元,且其中该处理器核心被配置为使用该分库式寄存器文件实现多个较小样板指令。在第二十四方面中,如方面23的处理器核心,其中该多个较小样板指令包括3×3stencil2d指令、4×4stencil2d指令、1×3stencil1d指令、1×4stencil1d指令、3×1stencil1d指令、4×1stencil1d指令或其组合。在第二十五方面中,如方面24的处理器核心,其中该多个较小样板指令包括使用该1×3stencil1d指令、该1×4stencil1d指令、该3×1stencil1d指令、该4×1stencil1d指令或其组合实现的1×1样板指令。在第二十六方面中,如方面23至25中任一项的处理器核心,其中该处理器核心被配置为使用该多个较小样板指令实现多个较大样板指令。在第二十七方面中,如方面26的处理器核心,其中该多个较大样板指令包括一5×5stencil2d指令、7×7stencil2d指令、8×8stencil2d指令、1×5stencil1d指令、1×7stencil1d指令、1×8stencil1d指令、5×1stencil1d指令、7×1stencil1d指令、8×1stencil1d指令或其组合。在第二十八方面中,如方面26至27中任一项的处理器核心,其中该多个较大样板指令包括n×1stencil1d指令或1×nstencil1d指令,其中n是正整数。在第二十九方面中,如方面26至28中任一项的处理器核心,其中该多个较大样板指令包括n×mstencil2d指令,其中n和m是正整数。在第三十方面中,如方面23至29中任一项的处理器核心,其中该处理器核心被配置为使用该分库式寄存器文件实现dotv2r指令。在第三十一方面中,如方面23至30中任一项的处理器核心,其还包括alu,其中该寄存器单元被配置为:加载且储存该alu的结果。在第三十二方面中,如方面23至30中任一项的处理器核心,其还包括累加器寄存器文件的多个累加器寄存器,该多个累加器寄存器被配置为:加载且储存该alu的结果。在第三十三方面中,公开一种操作深度视觉处理器(或深度视觉处理器核心)的方法。该方法包括:加载且储存图像像素数据和样板数据;将该图像像素数据的子集加载且储存于分库式寄存器文件中,且同时提供对储存于该分库式寄存器文件的寄存器文件项目中的图像像素值的存取,其中该图像像素数据的该子集包括储存于该寄存器文件项目中的该图像像素值;以及对储存于该寄存器文件项目中的该图像像素值和对应样板数据执行一个或更多个操作。在第三十四方面中,如方面33的方法,其中该分库式寄存器文件包括多个向量寄存器库。在第三十五方面中,如方面34的方法,其中该多个向量寄存器库中的一个库的宽度与该分库式寄存器文件的一个寄存器文件项目的大小是相同的。在第三十六方面中,如方面34至35中任一项的方法,其中该多个向量寄存器库包括四个向量寄存器库。在第三十七方面中,如方面36的方法,其中该四个寄存器库被配置为实现32个1行1d向量寄存器、16个2行2d向量寄存器、8个4行2d向量寄存器或其一组合。在第三十八方面中,如方面33至37中任一项的方法,其中执行该一个或更多个操作包括使用该分库式寄存器文件对该图像像素值执行较小样板指令。在第三十九方面中,如方面38的方法,其中该多个较小样板指令包括3×3stencil2d样板指令、4×4stencil2d指令、1×3stencil1d指令、1×4stencil1d指令、3×1stencil1d指令、4×1stencil1d指令、1×1样板指令或其组合。在第四十方面中,如方面38至39中任一项的方法,其中执行该一个或更多个操作包括使用该较小样板指令对该图像像素值执行较大样板指令。在第四十一方面中,如方面40的方法,其中该多个较大样板指令包括5×5stencil2d指令、7×7stencil2d指令、8×8stencil2d指令、1×5stencil1d指令、1×7stencil1d指令、1×8stencil1d指令、5×1stencil1d指令、7×1stencil1d指令、8×1stencil1d指令或其组合。在第四十二方面中,如方面33至41中任一项的方法,其还包括将该一个或更多个操作的一个或更多个结果储存于该分库式寄存器文件或一累加器寄存器文件中。在第四十三方面中,公开一种用于计算两个卷积的总和的方法。该方法包括:加载通道0的m个n位元素的一个行;执行软件移位以将通道0的一个行加载至通道0的v4r中;加载通道1的m个n位元素的一个行;执行软件移位以将通道1的一个行加载至通道1的v4r中;在通道0的v4r中计算数据的第0个卷积以产生通道0的输出;在通道1的v4r中计算数据的第1个卷积以产生通道1的输出;且对通道0和通道1的该输出求和。在第四十四方面中,如方面43的方法,其中m是8、32、64、128、256、512或1024。在第四十五方面中,如方面43的方法,其中m是64。在第四十六方面中,如方面43至45中任一项的方法,其中n是8、32、64、128、256、512或1024。在第四十七方面中,如方面43至45中任一项的方法,其中n是8。在第四十八方面中,如方面43至47中任一项的方法,其中在通道0的v4r中计算数据的第0个卷积以产生通道0的一输出包括:对通道0的该一个行执行第1个stencil2d以产生第1个32×16位输出;对通道0的该一个行执行第2个stencil2d以产生第2个32×16位输出;加载通道0的64个8位元素的一个行;以及执行软件移位以将通道0的一个行加载至通道0的v4r中。在第四十九方面中,如方面43至48中任一项的方法,其中在通道1的v4r中计算数据的第1个卷积以产生通道1的一输出包括:对通道1的该一个行执行第1个stencil2d以产生第1个32×16位输出;对通道1的该一个行执行第2个stencil2d以产生第2个32×16位输出;加载通道1的64个8位元素的一个行;以及执行软件移位以将通道1的一个行加载至通道1的v4r中。在第五十方面中,公开一种映射卷积神经网络的方法。该方法包括:接收表示卷积神经网络(cnn)的数据;执行该cnn的神经网络格式转换;执行该cnn的固定点转换和精度分析;以及基于系统信息而执行该cnn的图表分析和存储器映射。在第五十一方面中,如方面50的方法,其中执行该cnn的该神经网络格式转换包括执行该cnn的该神经网络格式转换以产生一中间格式以使处理流水线工具不可知。在第五十二方面中,如方面50至51中任一项的方法,其中执行该cnn的该固定点转换和该精度分析包括执行8、16、32、64或128位精度分析以确保来自该固定点转换的几乎没有准确度损失。在第五十三方面中,如方面50至52中任一项的方法,其中基于该系统信息而执行该cnn的该图表分析和该存储器映射包括:在模块层级执行自动存储器区块化以在每一层次层级处最大化存储器重复使用;且执行任务图表融合以最大化性能且避免不必要存储器传送。在第五十四方面中,公开一种处理器。该处理器被配置为实现如方面33至53中任一项的方法。在第五十五方面中,如方面54的处理器。该处理器包括:加载与储存单元;寄存器单元,其实现分库式寄存器文件;互连单元,其与该寄存器单元通信;以及多个算术逻辑单元(alu),其与该互连单元通信。总结本文中所描述和/或附图中所描绘的过程、方法和算法中的每一者可体现于程序代码模块中,且完全地或部分地由程序代码模块自动化,该程序代码模块由被配置为执行具体且特定计算机指令的一个或更多个物理计算系统、硬件计算机处理器、特殊应用电路和/或电子硬件执行。举例而言,计算系统可包含被编程有具体计算机指令的一般用途计算机(例如,服务器)或特殊用途计算机、特殊用途电路等等。一程序代码模块可被编译且链接至一可执行程序中、安装于一动态链接库中或可以一解译编程语言来编写。在某些实施方案中,可通过专用于一给定功能的电路来执行特定操作和方法。此外,本公开的功能性的特定实施方案在数学上、在计算上或在技术上是充分复杂的,使得特殊应用硬件或者一个或更多个物理计算装置(利用适当专门可执行指令)可能(举例而言)由于所涉及的计算量及复杂性而有必要执行功能性或实质上实时提供结果。举例而言,一视频可包含许多帧,其中每一帧具有数百万个像素,且具体而言被编程的计算机硬件有必要处理视频数据以在一商业上合理时间量内提供一所期望图像处理任务或应用程序。程序代码模块或任何类型的数据可储存于任何类型的非暂时性计算机可读介质(诸如包含硬盘的物理计算机储存器、固态存储器、随机存取存储器(ram)、只读存储器(rom)、光盘、易失性或非易失性储存器、各项的组合和/或类似者)上。方法和模块(或数据)也可作为所产生数据信号(例如,作为一载波或其他模拟或数字传播信号的一部分)在各种计算机可读传输介质(包含基于无线的介质和基于有线/电缆的介质)上传输,且可采取各种形式(例如,作为一单个或多路复用的模拟信号的一部分,或作为多个离散数字数据包或帧)。所公开的过程或过程步骤的结果可永久地或以其他方式储存于任何类型的非暂时性有形计算机储存器中或可经由一计算机可读传输介质来传递。本文中所描述和/或附图中所描绘的流程图中的任何过程、方框、状态、步骤或功能性应理解为潜在地表示程序代码模块、片段或包含用于在过程中实现特定功能(例如,逻辑或算术)或步骤的一个或更多个可执行指令的程序代码的部分。各种程序、方框、状态、步骤或功能性可被组合、重新布置、添加至本文中所提供的说明性实例、从本文中所提供的说明性实例删除、修改或以其他方式从本文中所提供的说明性实例改变。在某些实施例中,额外或不同计算系统或程序代码模块可执行本文中所描述的功能性中的某些或所有功能性。本文中所描述的方法和过程也不限于任何特定序列,且与其有关的方框、步骤或状态可以适当的其他序列(举例而言,以串行方式、以并行方式或以某一其他方式)来执行。任务或事件可添加至所公开实例性实施例或从所公开实例性实施例移除。此外,在本文中所描述的实施方案中各种系统组件的分离是出于说明性目的且不应理解为在所有实施方案中需要这样的分离。应理解,所描述程序组件、方法和系统一般可一起整合于一单个计算机产品中或封装至多个计算机产品中。许多实施方案变化是可能的。可在一网络(或分布式)计算系统中实现这些过程、方法和系统。网络环境包含企业级计算机网络、企业内部网络、局域网(lan)、广域网(wan)、个人局域网(pan)、云计算网络、众包计算网络、因特网和全球信息网(worldwideweb)。该网络可以是一有线或一无线网络或任何其他类型的通信网路。本公开的系统和方法各自具有若干个新颖方面,这些新颖方面中的任何单个方面皆不单独地负责或需要用于本文中所公开的期望属性。本文中所描述的各种特征和过程可彼此独立地使用或可以各种方式组合。所有可能组合和子组合意欲落在本公开的范围内。本领域技术人员可容易地明了对本公开中所描述的实施方案的各种修改,且可将本文中所限定的一般原理应用于其他实施方案而不背离本公开的精神或范围。因此,权利要求范围并不意欲限于本文中所展示的实施方案,而被授予与本发明、本文中所公开的原理和新颖特征相一致的最宽广范围。也可将在本说明书中在单独实施方案的上下文中描述的某些特征以组合形式实施于一单项实施方案中。相反,也可将在一单个实施方案的上下文中描述的各种特征单独地或以任一适合子组合的形式实现于多项实施方案中。此外,尽管上文可将特征描述为以某些组合形式起作用且甚至最初是如此主张的,但在某些情形中,可从一所主张组合去除来自该组合的一个或更多个特征,且所主张组合可涉及一子组合或一子组合的变化形式。任何单个特征或特征群组对于每一及每个实施例并非是必要的或不可缺少的。除非另外具体声明或另外在上下文内如所使用而理解,本文中所使用的条件语言(诸如,尤其“可(can)”、“可(could)”、“可(might)”、“可(may)”、“例如(e.g)”及类似者)一般意欲传达某些实施例包含而其他实施例不包含某些特征、元素和/或步骤。因此,此条件语言一般不意欲暗示一或更多个实施例以任一方式需要特征、元素和/或步骤或一个或更多个实施例必然包含在有或没有作者输入或提示的情形下决定在任一特定实施例中是否包含或将执行这些特征、元素和/或步骤的逻辑。术语“包括(comprising)”、“包含(including)”、“具有(having)”及类似者是同义的且以一开放方式包含性地被使用,且不排除额外元素、特征、动作、操作等等。而且,术语“或(or)”以其包含性意义(而非以其排他性意义)来使用,使得当用于(举例而言)连接一元素列表时,术语“或(or)”意味列表中的元素中的一个、某些或全部。另外,除非另有规定,否则如在本申请和随附权利要求中所使用的冠词“一(a)”、“一(an)”和“该(the)”将解释为意味“一个或更多个”或“至少一个”。如本文中所使用,提及一项目列表中的“至少一个”的一短语是指那些项目的任何组合,包含单个部件。作为一实例,“a、b或c中的至少一个”意欲涵盖:a、b、c、a和b、a和c、b和c以及a、b和c。除非另有具体声明,否则诸如短语“x、y和z中的至少一个”的连接语言一般与如所使用的上下文一起以其他方式来理解,以传达一项目、术语等可以是x、y或z中的至少一个。因此,此连接语言一般不意欲暗示特定实施例需要x的至少一个、y的至少一个以及z的至少一个各自存在。类似地,虽然可在附图中以一特定次序描绘操作,但应认识到,不需要以所展示的特定次序或以顺序次序执行这些操作或执行所有所图解说明的操作以达成期望结果。此外,附图可以一流程图的形式示意性地描绘一个或更多个实例性过程。然而,未描绘的其他操作可并入于示意性地图解说明的实例性方法和过程中。举例而言,可在所图解说明操作中的任一者之前、之后、与其同时或在其之间执行一个或更多个额外操作。另外,可在其他实施方案中重新布置或排序这些操作。在某些情形下,多任务和并行处理可能是有利的。此外,上文所描述的实施方案中的各种系统组件的分离不应被理解为在所有实施方案中需要这样的分离,且应理解,所描述的程序组件和系统一般可一起整合于单个软件产品中或封装至多个软件产品中。另外,其他实施方案也在所附权利要求的范围内。在某些情形中,权利要求中所陈述的动作可以不同次序执行且仍达成期望结果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1