对组织切片图像的虚拟染色的制作方法
背景技术:
本公开涉及一种从组织样本的输入图像中产生具有被(一个或多个)具体的特殊染色化学品(诸如免疫组织化学染色剂)染色的显现的组织样本的人造或虚拟图像的方法。输入图像可以是组织样本的未染色的图像,或者可以是被第一染色剂(通常是苏木精和曙红(hematoxylinandeosin,h&e))染色的组织样本的图像。
组织学组织图像通常用h&e染色以突出组织形态,称为“常规染色”的一种过程。存在更特定的染色剂(在本领域中称为“特殊染色剂”(例如,免疫组织化学染色剂(immunohistochemicalstains,ihc))用以突出特定的靶标(例如,非常特定的肿瘤标志物或细胞或组织结构)。宽松地说,这可以看作是非常特定的图像重新着色。特殊染色剂的示例包括用于检测乳腺癌样本中特定基因突变标志物的her2染色剂、用于前列腺样品的pin4(也称为“前列腺三重染色剂”(p504s、hmw角蛋白、p63))、用于肺癌组织的verhoeff染色剂和用于淋巴结组织的ck7和ae1/ae3混合液染色剂。
由于染色剂本身的成本(其中一些染色剂本身的成本比h&e染色剂的价格昂贵五倍)和劳动和设备的成本,因此相对昂贵来获得用特殊染色剂染色的组织样本的图像。另外,通常没有足够的组织可用于病理医生可能想获取的用于诊断的所有染色图像,通常每个染色图像都需要从一块组织中的分离的一片组织。获取其他特殊染色图像通常也需要花费大量额外时间。因此,在某些情况下,例如在肺癌中,希望获得用许多不同的ihc染色剂染色的样本的图像,但是,如果不获得进一步的活检,获得这样的图像既昂贵又可能无法实现,或者无论如何都会导致诊断的延迟。本公开的方法解决并且优选地克服了这些限制中的一个或多个。我们公开了如何从组织样本的输入图像对于一套特殊染色剂生成虚拟特殊染色的图像。输入的图像可能是未染色的,或者是用普通的h&e染色剂染色的。
该方法旨在具有应用和益处,包括以下一个或多个:(1)减少所需要的实际染色的数量,从而降低成本并消除获取额外特殊染色的图像的额外延迟,(2)为病理医生提供实际的特殊染色的图像或特殊染色的图像组的可能的显现预览,用于病理医生决定他们需要订购什么图像;以及(3)提供可视化和解释以补充其他预测(诸如针对组织样品的肿瘤检测、分类或预测)。
在本文档中,术语“特殊染色剂”定义为表示除了苏木精和曙红(h&e)以外的、用于帮助可视化和/或识别在生物样本中的结构和物质的染色剂。这些包括其中的免疫组织化学染色剂(诸如用于检测乳腺癌样本中特定基因突变标记的her2染色剂、用于前列腺样品的pin4和“前列腺三重染色剂”(p504s、hmw角蛋白、p63)、以及用于淋巴结组织的ck7染色剂)以及在病理学中使用的其他类型的染色剂(包括但不限于用于分枝杆菌的耐酸染色剂、用于淀粉样蛋白的刚果红、用于细菌的革兰氏染色剂(多种方法)、用于真菌的grocott的甲基苯二胺银(grocott’smethenaminesilver,gms)、用于基底膜和中膜的jones甲基苯丙胺银、用于脱髓鞘的luxol固蓝pas、用于胶原蛋白和肌肉的masson三色、高碘酸schiff(periodicacid-schiff,pas)、用于纤维蛋白的磷钨酸苏木精(phosphotungsticacid-hematoxylin,ptah)、用于三价铁的普鲁士蓝、用于脂质和脂质染料的苏丹黑、用于弹性蛋白的verhoeff染色剂、以及用于细菌的warthin-starry染色剂)。
技术实现要素:
一般而言,我们在下面描述了一种用于生成机器学习预测器模型的系统,该模型预测组织样品的特殊染色图像。该系统包括:a)数据存储,该数据存储包含给定组织类型的组织样品的大量对齐的图像对,其中每个图像对由未染色或h&e染色(通常“第一染色”)的组织样品的第一图像和用不同于第一染色的第二染色(通常是特殊染色剂)染色的组织样品的第二图像组成;b)计算机系统,该计算机系统被配置为机器学习预测器模型,从数据存储中的大量对齐的图像对中训练所述机器学习预测器模型以输入图像中生成被特殊染色剂染色的组织样品的预测图像,所述输入图像具有图像对中的第一图像的类型(即,h&e染色的、或未染色的),并且具有给定组织类型。
请注意,用于模型的数据存储中的对齐的图像对尽可能紧密或精确地对齐;也就是说,它们具有低于阈值(诸如1或2个像素)的、在相应图像中的对齐的对应点之间的平均距离。例如,阈值可以使得用在实践中使用的对齐过程不可能进行更精确的对齐。
本公开的第一特定表达是用于生成预测组织样品的特殊染色图像的机器学习预测器模型的系统,其组合地包括:
a)数据存储,所述数据存储包含给定组织类型的组织样品的大量对齐的图像对,其中每个图像对由未染色或h&e染色的组织样品的第一图像和被特殊染色剂染色的组织样品的第二图像组成;
b)计算机系统,该计算机系统被配置为机器学习预测器模型,从数据存储中的大量对齐的图像对中训练机器学习预测器模型以输入图像中生成被特殊染色剂染色的组织样品的预测图像,该输入图像具有图像对的第一图像的类型(染色的、或未染色的),并且具有给定组织类型。
在一种配置中,特殊染色剂是本文档中提到多次的ihc染色剂的形式。它可能是her2、pin4或“前列腺三重染色”(p504s、hmw角蛋白、p63)、verhoeff染色剂和ck7染色剂中的任何一个(或多个)。具体的特殊染色剂可能取决于组织类型。在一种配置中,给定组织类型是以下类型中的一个:乳房组织、前列腺组织、淋巴结组织和肺组织。
在一个可能的实施例中,数据存储包含不同组织类型和不同特殊染色剂类型的大量图像对。这样的图像数据集合既可以从一个或多个公共或私有源获取,也可以专门精选用于预测器模型的开发。该计算机系统为不同的组织类型和染色类型的每个实现不同的机器学习预测器模型。
适用于当前目的的机器学习预测器模型的示例包括生成式对抗网络、自我监督学习神经网络、卷积神经网络和用于密集分割的卷积神经网络(例如称为“u-net”的卷积神经网络)。
在另一方面,公开了一种计算机系统,所述计算机系统包括实现一个或多个(或更优选地多个:“套”)机器学习预测器模型的一个或多个处理单元以及存储器,所述模型从代表给定组织样品的未染色的或h&e染色的输入图像的数据中,生成具有给定相应组织类型的组织样品的虚拟特殊染色的图像的显现的预测的形式的数据。
在另一方面,提供了一种用于生成被特殊染色剂染色的组织样本的虚拟图像的方法,该方法包括以下步骤:
获取输入图像;
将输入图像提供给从组织样本大量对齐的图像对中训练的机器学习预测器模型,该图像对中的一个图像包括被特殊染色剂染色的组织样本的图像,该模型经过训练以预测被特殊染色剂染色的组织样本的图像;
利用预测模型,生成被特殊染色剂染色的组织样本的预测图像,以及
将预测图像显示为虚拟图像。
在一种可能的布置中,输入图像是处于未染色状态的组织样本的图像。可替代地,输入图像是被h&e染色的组织样本的图像。特殊染色剂可以采取任何商业的ihc染色的形式。组织样本可以是包括以下多个可能的类型中的一种:乳腺组织、前列腺组织、淋巴结组织和肺组织。
在另一方面,公开了一种训练机器学习预测器模型的方法。该方法包括步骤a)获得给定组织类型的组织样品的大量对齐的图像对,其中每个图像对由未染色的或用h&e染色的组织样品的第一图像和被特殊染色剂染色的样本组织的第二图像组成;步骤b)提供大量对齐的图像对作为机器学习预测器模型的训练数据,该模型学习从输入图像中预测被特殊染色剂染色的组织样本的图像,该输入图像具有图像对的第一图形的类型(染色的,未染色的)并且具有给定组织类型。
对于以上定义的每个方法,本发明还提供了存储程序指令的相应计算机程序产品(例如,有形的机器可读记录介质,但也可以是可通过通信网络下载的软件),该程序指令在由处理器实现时使处理器执行该方法。本公开还为每个计算机程序产品提供了相应的计算机系统,该计算机系统包括处理器和存储该计算机程序产品的存储器。
附图说明
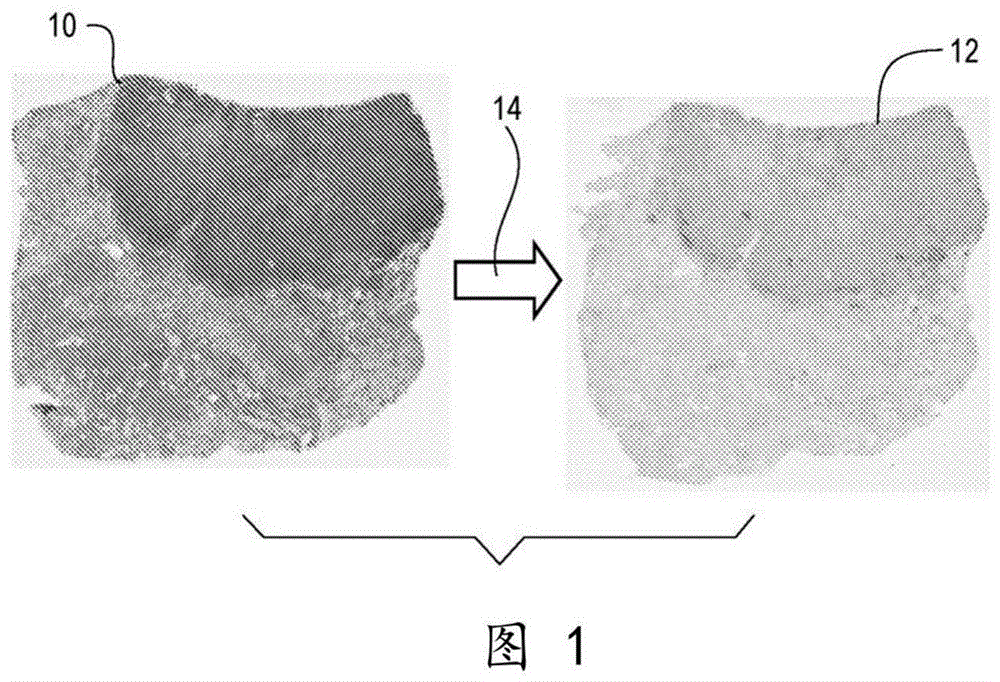
图1是用h&e染色的组织样本的低放大率完整切片图像和示出如果被ihc染色剂染色后将如何显现的组织样本的虚拟或人造图像的示意图。
图2是用h&e染色的组织样本的高放大率图像和示出如果被ihc染色剂染色后将如何显现的相同样本的虚拟图像的示意图。
图3是从组织块中获取组织部分以便生成用于训练机器学习预测器模型的训练图像的多个可能方法的示意图。
图4a-图4d是通过使用图3中所示的方法获得的图像组。
图5是组织样本的低放大率图像,显示了训练图像中可能存在的某些边缘效应。在一个实施例中,训练图像中包含组织边缘的部分在模型训练中不被使用,以避免由于这种边缘效应而对模型进行不适当的训练。
图6a-图6c是组织样本的三个不同图像:图6a是h&e染色的输入图像,图6b是图6a所示的组织样本的实际ihc染色的图像,图6c是由机器学习预测器模型预测的图6a所示的组织样本的虚拟ihc染色的图像。
图7是示出用于训练机器学习预测器模型以从输入的图像对中预测特殊染色的图像的模型训练过程的流程图。输入的图像对可以采取未染色图像+特殊染色的图像或染色的图像(通常为h&e染色的图像)+特殊染色的图像的形式。针对不同类型的特殊染色图像和不同的组织类型重复图7的过程,以建立机器学习预测器模型的套或复杂度以生成大量组织和染色类型的虚拟染色的图像。
图8是示出使用根据图7训练的机器学习预测器模型的过程的流程图。
图9是病理医生使用的工作站的示意图,该工作站具有简单的用户界面工具来选择要在工作站上查看的组织图像、并选择由机器学习预测器模型预测并随后在工作站上显示的一个或多个虚拟特殊染色图像。
图10是示出其中可以实践本公开的方法的计算环境的框图。
具体实施方式
如上所述,本公开的方法提供了从输入图像(可以是未染色的图像或者用h&e染色的样本的图像)生成示出如同被特殊染色剂(诸如ihc染色剂)染色的样本的显现的组织样本的虚拟染色的图像。
例如,图1是用h&e染色的组织样本的低放大率完整切片图像10和示出了如果被特殊染色剂(在该实例中,ihc染色剂cd3)染色将如何显现的组织样本的虚拟或人造图像12的示意图。箭头14指示如下所述的经过训练的机器学习预测器模型接收完整切片图像10作为输入并预测虚拟图像12的显现。预测的图像被显示给用户,例如在由病理医生使用工作站的显示器上。
机器学习预测器模型的训练可以在不同的放大率级别、例如低放大率(例如5或10x)、中放大率(例如20x)和高放大率(例如40x)上进行。因此,该模型可以从低、中或高放大率输入图像来预测特殊染色的图像。图2是用h&e染色的前列腺组织样本的高放大率图像20和示出了如果用ihc染色剂(在这种情况下,pin4特殊染色剂)将如何显现的相同样本的虚拟图像22的示意图。
我们将在下面详细介绍如何预测这些虚拟染色图像的两个方面:1)生成并训练机器学习预测器模型以从输入图像中预测特殊染色的图像,以及2)在训练后使用训练后的预测器模型从输入图像生成虚拟染色的图像。
训练
我们的训练过程包括收集各种组织类型(例如前列腺、肺、乳腺等)的大量(例如数千个)相同组织样品的图像对,其中所述图像对中的一个图像是组织样品的特殊染色的图像。图像对可以是,例如
(1)未染色的图像和特殊染色的图像(例如相同的组织样本的ihc图像),和/或
(2)相同的组织样本的h&e图像和特殊染色的图像。然后将这些图像对彼此精确对齐、并将其用作训练数据以训练机器学习预测器模型以从输入图像预测特殊染色的图像。
这样的图像对可以从来自组织块的连续组织样本或从未染色的、成像的,然后再特殊染色的、成像的单个组织样本、或者被h&e染色的、去染色的,然后被特殊染色剂再染色的获得单个组织样本获得。
图3示出了福尔马林固定的石蜡包埋的组织块30,其中用超薄切片机(microtome)切割组织块的连续(相邻)部分,并如本领域常规将其置于载玻片上。在一个可能的实施例中,第一部分32用h&e染色。与第一部分32相邻的第二部分34用ihc或其他特殊染色剂染色。染色后的部分32和部分34用常规的高分辨率rgb全玻片扫描仪(wholeslidescanner)以不同的放大率(诸如5x、10x、20x和40x)进行全玻片成像。该过程产生图像36和38,其中图像36是样本的10xh&e染色的图像,而图像38是样本的10xihc染色的图像,未示出其他放大率的图像。
另一种方法是:截取部分、诸如组织块的第三部分40,用h&e对其进行染色,然后用全玻片扫描仪以不同的放大率对其进行扫描,得到图像组,其中一个图像在42处示出,然后对样本进行去染色,然后用ihc或其他特殊染色剂对样本进行再染色,并以不同的放大率生成具有ihc染色剂的样本的新图像组,其中一个图像在44处示出。pct申请序列号pct/us18/13353在2018年1月11日提交的描述用于对组织样本去染色、再染色和成像的方法,其描述通过引用合并于此。
虽然图3示出了用h&e染色的组织样品的初始步骤,但可以对未染色的图像执行以下所述的方法,在这种情况下,将组织块的一部分切除,在未染色的条件下以各种放大率成像,然后被特殊染色剂染色,然后以相同的放大率成像。可以对组织块的多个不同部分重复此过程,并对这些部分施加不同的特殊染色剂,以构建具有不同特殊染色剂的图像对(未染色的/染色的)的组。同样,可以重复图3的过程,以生成针对不同特殊染色剂的h&e/特殊染色剂图像对的组。图4a-图4d更详细地示出了从图3的过程生成的图像的组,其中图4a是来自第一部分32的h&e染色的样本的图像36,图4b是来自相邻的第二部分34的ihc图像38。图4c是来自部分40的h&e染色的图像42,图4d是来自部分3(40)的再染色的ihc图像44。图4a和4b的图像可以形成用于模型训练的一图像对。类似地,图4c和图4d的图像可被视为用于模型训练的另一图像对。另外,图4c和图4b的图像可被视为用于模型训练的另一图像对。
下面将结合图7使用从图3的过程生成的图像对来更详细地描述模型训练过程。应该注意,获取和对齐图像对的过程将执行很多次,也许成千上万次,以建立一个庞大的图像对的训练组。应该执行图像对的非常精确的对齐,以便在模型训练期间使用精确对齐的图像。这种对齐可以包括使图像变形以确保尽管图像之间存在潜在的组织变形,但是仍然使细胞细节对齐。通过使用单个组织样本的再染色(图3和图4c和图4d,图像42、44),只要在再染色期间基本上不干扰组织样本,就可以获得非常精确对齐的图像。
图5是组织样本的低放大率图像,其示出了某些边缘效应,该边缘效应可能存在于训练图像中,并且应该在模型训练过程中去除,即在模型训练期间不考虑。区域50示出了在图5的图像中存在的组织的边缘中的撕裂,并且该撕裂对于图5中所示的组织样本可能是唯一的,即,在相邻的组织部分中不存在。由于在将样本放置在载玻片上、对载玻片染色或在载玻片上放置盖玻片期间处理样本而导致撕裂。这种撕裂可能不会出现在来自组织块的相邻部分的图像中,因此在此区域中使用图像数据(以及来自没有撕裂的组织块的相邻部分的图像)可能会对学习或训练机器学习预测器模型产生不利影响。撕裂不是相邻部分之间唯一可能的物理边缘效应或差异。脆弱的组织样品有时可能在边缘处变形或损坏,从而导致在其他方面相似的图像之间出现局部差异。在更剧烈的情况下,这些可以是组织破裂或组织折叠的形式。即使对实验室技术人员给出指示以在分割、染色和成像样本时格外小心并最小化这些人工制品以建立训练图像数据,也会残留一些人工制品。在组织边缘处的另一潜在的不期望的人工制品是墨水,有时在实验室中使用墨水来指示应该在什么位置切割组织块。在图5中,区域52包含来自这些标记的墨水残留物。相邻部分中可能存在也可能不存在墨水残留物,但是墨水残留物不期望出现,并且墨水残留物可能会对模型训练产生不利影响。因此,在一个实施例中,在模型训练中不使用组织部分的边缘,以避免由于这种边缘效应而对模型进行不适当的训练。用于从模型训练中排除图像数据的某些部分的“边缘”的定义可以采取多个可能的形式,诸如在组织和载玻片的空白区域之间的边界之外的最小像素数。
一旦发生了根据图7的模型训练,就可以例如通过比较由模型生成的预测图像与给定组织样本的实际特殊染色的图像来评估模型的性能。例如,图6a-图6c是前列腺组织样本的三个不同图像:图6a是h&e染色的输入图像,图6b是图6a所示的组织样本的实际ihc(pin4)染色的图像,以及图6c是由机器学习预测器模型预测的、图6a所示的输入组织样本图像的虚拟ihc染色的(pin4)图像。尽管图6c的图像与图6b的实际ihc图像并不完全相同,但它足够接近以至于考虑图6c的病理医生可以合理估算出图6a中所示的样本的pin4(ihc)图像如何显现,并且因此处于更知情的位置以确定是否要订购患者的组织样本的pin4染色图像。图6c的虚拟图像还可以用于其他目的,诸如提供组织样本的可视化以及支持用于补充关于组织样本的预测,诸如组织样本的肿瘤检测、诊断或分类。
现在将结合图7描述模型训练。在本讨论中,我们将集中于用于给定类型的模型训练的大量(数千)组织图像对,诸如乳腺癌组织,其中一个图像是样本的h&e图像,另一个图像是同一样本的her2(特殊染色的)图像。对于其他类型的图像对、例如不同组织类型、不同染色等、或其中图像对中的第一图像是未染色图像的情况,训练的过程是相同的。
在图7的模型训练过程中,我们从步骤100开始,获得给定组织类型的大量(例如,数千)图像对,诸如例如乳腺癌组织的图像。图像对可以是未染色的+特殊染色的,或者染色的(例如,h&e染色的)+特殊染色的。这种图像对可以从一个或多个私有或公共可得的预先存在的组织图像数据库中获得,或者可选地,可以从成千上万个单独的组织样本中专门为模型训练练习而精选。理想地,图像对以各种不同的放大率提供,以便训练机器学习预测器模型来预测在输入图像的不同放大率下的特殊染色的图像。在精选的图像的集合的情况下,从公共或私人组织集合中获得处于各种健康状况下的患者的给定组织类型的数千个组织样本,并对样本进行分割、染色、然后成对地成像,如结合图3和图4以不同放大率的讨论所解释的那样。
在步骤120,大量图像对相对于彼此精确对齐或配准。使图像对彼此对齐或配准的过程是已知的并且在文献中进行了描述,例如,参见d.mueller等人的《用于数字病理学的多模式整体载玻片的实时可变形配准(real-timedeformableregistrationofmulti-modalwholeslidesfordigitalpathology)》,电脑医学成像与计算机制图(computerizedmedicalimagingandgraphics)35卷542-556页(2011);f.el-gamal等人,《医学图像配准和融合的当前趋势(currenttrendsinmedicalimageregistrationandfusion)》,《埃及信息学杂志(egyptianinformaticsjournal)》17卷99-124页(2016);j.singla等人,《使用图像配准的系统仿射变换方法(asystematicwayofaffinetransformationusingimageregistration)》,国际信息技术与知识管理学报(internationaljournalofinformationtechnologyandknowledgemanagement)2012年7月至12月,卷5,第2期,第239-243页;z.hossein-nejad等人,《基于sift特征和ransac变换的自适应图像配准方法(anadaptiveimageregistrationmethodbasedonsiftfeaturesandransactransform)》,计算机和电气工程(computersandelectricalengineering),卷62,5240537页(2017年8月);美国专利8,605,972和9,785,818,其描述通过引用并入本文。由于虚拟染色模型的训练数据将是h&e与特殊染色(或未染色与特殊染色)的(几乎)相同的图像小块对,因此需要尽可能完美地对齐图像。对于具有100,000x100,000像素的完整切片图像大小以及潜在的局部组织变形,配准不是仿射变换的琐碎任务,而是更有可能还需要局部变形。一种可能的方法是经由缩略图级别上的旋转和变换执行粗略的全局匹配,然后匹配图像小块对。该方法使用现成的图像处理功能与ransac(随机样本共识(一种已知的图像对齐算法,请参阅https://en.wikipedia.org/wiki/random_sample_consensus和hossein-nejad论文))相结合进行对齐。此外,这种方法可以处理例如无法匹配的小块的情况(例如,由于一个图像而不是另一图像中的组织损伤)。
在步骤130,对组织图像的边缘区域进行掩蔽,并且将这种掩蔽区域中的像素值归零,以出于前述原因将这些边缘区域从模型训练中去除。
在步骤140,将精确对齐的图像对作为训练数据提供给机器学习预测器模型。训练数据用于指导模型从第一或输入图像(h&e图像)预测虚拟染色的图像(在此示例中为her2图像)。对于像显微组织图像这样的千兆像素图像,此预测器模型可能不会一次在整个图像上运行(即学习),而是一次一个地在图像的小块上学习,或者可能逐像素地在图像上学习。或者,基于形态或对比度值,预测器模型可以对单个细胞进行操作——即在输入(h&e)图像中识别单个细胞,并学习以预测细胞的相应的ihc图像。使用训练图像对执行像素到像素、细胞到细胞、或小块到小块的映射。给定两个相应的切片,任何密集的预测算法都应该能够以类似l2损失的方式执行映射。
一些非常适合本公开的机器学习预测器模型包括:
1)生成式对抗网络(gan)。这种神经网络方法在k.bousmalis等人的文章《使用生成式对抗网络进行无监督像素级别域自适应(unsupervisedpixel–leveldomainadaptationwithgenerativeadversarialnetworks)》(https://arxiv.org/pdf/1612.05424.pdf(2017年8月))中进行了描述,其通过引用并入本文。当前的问题可以被视为域自适应算法,其中一种是尝试从源域重新映射图像以使其看起来好像来自目标域。本领域技术人员将扩大在bousmalis等人的论文中描述的现有技术的模型以应用于更大的图像(诸如千兆像素病理图像),并将其应用于大规模数据集的语义分割。
2)自我监督学习神经网络(例如,当示出图像的其他部分时被训练以预测图像的部分的模型)。
3)卷积神经网络,用于计算机视觉问题中且在科学文献中已有很好的描述的神经网络的综合性类别。
4)用于密集分割的卷积神经网络(例如u-net)。见论文o.ronneberger等人,u-net:用《于生物医学图像分割的卷积网络(convolutionalnetworksforbiomedicalimagesegmentation)》,https://arxiv.org/abs/1505.04597(2015),其内容通过引用合并。
该训练利用了模型能够提取第一图像中但是人类不容易提取的细微的细节或形态特征的特性这些特性。模型的输入是rgb图像,输出是取决于所预测的各个特殊染色剂的、具有相同组织形态但不同颜色和对比模式的rgb图像。鉴于ihc与非常特定的抗原结合并且是局部蛋白表达的指示剂(例如,在erbb2乳腺癌突变的情况下为her2),因此,预先并不清楚h&e图像甚至包含关于ihc图像进行真实预测的信息。基本假设是组织中的形态特征与局部蛋白质表达模式之间存在因果关系或关联。有证据表明这种预测是可能的:首先,在相关工作中,本发明的受让人成功地以非常高的准确度从明场灰度图像中预测了荧光细胞显微图像,其次,病理医生证实了他们可以经常在看到相应的ihc图像后检测到h&e图像中的细微肿瘤特征——即使他们最初在看到ihc图像之前错过了h&e中的那些特征。这证实了h&e图像中存在很容易被人眼忽略的一些细微的信息。然而,本公开的模型训练编码或固定了机器学习预测器模型识别这种信息并使用它来生成虚拟染色图像的能力。
如果可得到足够大的训练数据组,则机器学习预测器模型将从给定组织样本和ihc染色剂类型(在此示例中为乳腺癌和her2染色剂)的h&e图像来学习预测ihc图像。
在步骤150,可以对相同的组织类型但是不同的特殊染色剂类型进行训练。如果需要这种训练、以例如增加预测器模型的通用性和实用性,则该过程如160所示循环回到步骤100,并获得图像对的组,其中图像对中的一个是第二特殊染色剂类型。例如,在习惯对前列腺癌组织样品采用4种不同类型的特殊染色剂的情况下,在循环160的第一次迭代中,在步骤100中,将ihc染色剂#1用作图像对中的第二图像,在步骤100中,通过循环160的第二次迭代,将ihc染色剂#2用作图像对中的第二图像,在步骤100中,在第三次迭代中,将染色剂ihc#3用作图像对中的第二图像,并且在步骤100中,在第四次迭代中,将ihc染色剂#4用作图像对中的第二图像。如果需要训练模型从未染色图像预测特殊染色的图像,则通过步骤160指示的过程的附加循环也是可能的,在这种情况下,在步骤100的图像对中的第一图像是未染色的图像,第二图像是特殊染色的图像。如果需要针对未染色的图像的给定组织类型的不同染色剂上训练模型,则针对n种不同类型的染色剂进行经过步骤160的n个循环,其中n是大于或等于2的某个整数。
在实践中,在160处指示的循环可能会导致可用于多个特殊染色剂的单个模型(例如,通过包括针对每个相应特殊染色剂的不同2d输出阵列的输出层,从而使相同的隐藏层用于在输出层处生成多个图像)。备选地,通过循环160的每次迭代可以得到单独的模型,每个特殊染色剂类型一个模型,其中每个模型由不同的参数组、常数等来定义。
在步骤170,如果需要以不同的组织类型训练预测器模型,则过程如180所示循环回到步骤100,并且根据需要重复步骤100、120、130、140、150和160以训练预测器模型用于其他组织类型的、以及用于此类组织类型或用于如在步骤100处输入的未染色图像的可能的其他特殊染色剂,,如通过执行循环160一次或多次来指示的。例如,可能需要创建和训练一套机器学习预测器模型,其中大量组织类型的每一个组织类型一个模型。取决于根据图7训练的系统的潜在需求或用途,可能并且希望对当代病理学实践中使用的所有各种类型的组织和染色剂训练预测器模型,假设可以获得组织样本并且可以获得精确对齐的训练图像对,从而可以实现图7的方法。
一旦获得了所有组织类型并且已经根据需要执行了循环180,则在步骤170处不进行分支,然后将根据图7生成的机器学习预测器模型存储在计算机系统中。如本领域技术人员将理解的,预测器模型的精确配置、例如作为模型参数、常量、可执行代码、算法等的集合将取决于如上所述的模型类型的选择而变化。
此外,如上所述,可以在图像对的不同放大率级别(例如,10x、20x和40x)下执行模型训练。因此,在步骤100,可以针对输入图像对的不同放大率多次执行图7的过程。特别地,还可以针对图像对的第一图像和第二图像的不同放大率级别,例如在5x,10x,20x和40x时,对特殊染色剂的类型的每一个以及组织类型的每一个来执行通过图7的训练过程的附加循环。在一种可能的配置中,给定的机器学习预测器模型可以应付所有放大率级别下针对输入图像的特殊染色剂图像的预测,但是也有可能训练不同的模型,其中每一种放大率一个模型。
使用
根据图7,一旦对(一个或多个)机器学习预测器模型进行了训练,就会向该模型提供对所述模型进行训练的该类型的输入图像,并生成与输入图像对应的预测或虚拟特殊染色的图像。在该示例中,如果训练该模型以从20x的乳腺癌组织的输入h&e图像中预测乳腺癌组织的her2图像,则模型将为20x的输入图像预测her2图像。然后将预测的图像显示给用户。
作为一个例子,参考图8,病理医生获取乳房组织的样本,然后将其分割并用h&e染色,用全玻片扫描仪扫描,然后接收用h&e染色的组织的全玻片图像200。该图像可以与元数据、诸如患者身份、组织类型、染色剂类型、放大率级别等相关联。病理医生想要查看样本的her2或样本的其他特殊染色的图像可能如何显现。通过工作站上的简单用户界面工具,他们将h&e图像的输入引导到经训练的机器学习预测器模型202,并且该模型返回预测的特殊染色图像204,然后将其显示在工作站上。虚拟染色的图像也可以显示为样本的h&e染色的图像上的覆盖图,例如,在用户查看h&e染色的图像并激活工作站显示器上的图标以在不同虚拟染色剂之间切换的模式下,实质上是将h&e图像重新着色为相应的染色图像。
作为另一示例,从h&e染色的肺癌组织样本和在四个不同的染色协议或方案(n=4)中的相同组织样本的相应特殊染色的图像(诸如用四个不同的特殊染色剂染色的组织样本的一套图像)中训练模型202。在使用中,考虑肺样本的h&e染色的图像200的病理医生将图像提供给模型202,并且其返回用一套四个不同特殊染色剂204染色的肺样本的四个不同的虚拟染色图像。病理医生咨询这四个虚拟染色图像204,并决定订购肺样本的特殊染色图像中的一个。可替代地,基于虚拟染色图像204的质量、以及特殊染色图像与h&e染色图像200的比较,病理医生确定样本是非癌的,并且不对肺样本订购任何特殊染色图像。虚拟染色的图像将附加到病理医生准备的诊断病理报告中。
图9示出了病理工作站的示例,其中示出了显示在工作站250显示器上的输入图像200。工具220列出了可用于查看特定样本类型的各种不同类型的虚拟染色图像。用户通过使用滚动条222导航到不同的染色类型。当他们已经导航到他们想要看到的特定染色类型时,他们激活选择图标224,并且该染色类型的虚拟染色图像被显示在显示器上。在这种情况下,已经选择了两种染色类型,并且相应的虚拟染色图像在204a和204b处示出。虚拟染色的图像可以并排显示或叠加在原始输入图像200上。该图像200可以是未染色的图像,也可以是染色的图像,例如用h&e染色的图像,这取决于如何使用图7的过程训练模型。
图10示出了可以在其中实践本公开的方法的一种可能的计算环境。计算机系统300(可以采取各种形式,包括实现机器学习预测器模型、服务器或其他子系统的经过特殊编程的gpu)与数据存储302通信,数据存储302存储组织样本的图像对以便进行模型如图7所示的训练。计算机300提供有处理器,该处理器执行用于实现机器学习模型的软件指令,包括模型参数、算法等。在使用中,经由应用编程接口,操作工作站250的用户选择来自存储器的本地输入图像或工作站本地的数据存储,并且图像与相关联的元数据(例如,指示组织类型)一起通过计算机网络304被提供给实现机器学习预测器模型的计算机系统300。然后,适用于输入图像的组织类型的经过训练的预测器模型将预测工作站用户(在元数据中指定,或经由api作为特殊指令)需要的特殊染色的图像。然后,通过网络304提供预测的虚拟特殊染色的图像,然后将其显示在工作站250上。计算机系统300可以作为收费服务或以某些其他商业模型来操作。
除了由本公开内容表示的重大科学突破之外,从h&e染色的图像预测ihc染色的能力将对临床诊断产生重大影响。特别是:
1.节省成本——每个ihc染色剂的成本目前约为50美元。仅在美国每年就使用大量的ihc染色剂,这意味着每年的总支出确实是巨大的。因此,能够实际上仅虚拟地进行几种类型的ihc染色而不是实际进行染色,将可以为医疗保健行业(和患者)节省大量资金。
2.增加访问权限——一些实验室和诊所没有执行ihc染色的能力。如果需要完成,则将它们外包,从而导致额外的延迟。
在执行h&e染色后、并且在不具备ihc功能的设施中,几乎无需等待时间即可进行虚拟染色。
3.组织的可用性——组织通常很稀少,病理医生通常必须决定要使用可用组织用于哪些ihc染色剂上。尤其是如下这种情况
用于组织非常有限的活检,例如在肺活检中。通过虚拟染色,将不会被组织的可用性限制用于案例诊断的潜在相关染色的数量。
4.实际染色剂优先排序——即使将仍然执行实际的真实染色,
预测染色可能如何显现的方式可能有助于优先排序什么染色剂将是最有价值的。
5.丰富我们的ml训练组——根据本公开内容的方法生成的虚拟染色的图像可构成用于开发分类模型的附加训练数据。
6.缩短周转时间。订购ihc图像通常会使最终的诊断时间延迟一天左右。本技术可以通过以下方式缩短该时间,(1)不需要实际的物理ihc染色的图像,或者(2)预先提供相关信息来决定是否应该订购实际的物理ihc染色的图像。
有人可能会问虚拟染色图像的有用性。可以说,如果h&e图像包含足够的信号来预测该组织上ihc染色剂将如何显现,那么我们也可以立即预测诊断并跳过虚拟ihc图像的“可视化”。然而,即使这是可能的,与仅用于诊断的h&e图像相比,生成虚拟ihc图像也具有明显的优势。
特别是:
1.由于人为失误,与未染色/h&e染色的图像相比,如果执行此操作的人员使用虚拟染色的图像,则可以提高识别存在某些条件的可靠性。
2.可解释性-几乎不能高估向病理医生示出导致诊断的染色剂的可视化的重要性。它有助于建立对本公开的方法以及虚拟染色图像所随附的任何特定预测的信任。如果我们可以将虚拟ihc与组织样本的实际的h&e图像或未染色图像叠加在一起,则此尤其强大。
3.形态学信息——肿瘤及其微环境的形态是诊断中的重要信号。诸如肿瘤大小、结构和空间的信息、或者入侵淋巴细胞的位置直接有助于诊断和考虑治疗方案。所有这些空间信息将在没有染色剂可视化的纯分类预测中丢失。
隐私注意事项
模型训练中使用的所有图像都将是去除患者标识的。从获得训练图像的每个机构都获得了道德审查和机构审查委员会豁免。如果训练图像是从组织块伦理审查中获得的,则可以从每个提供组织块的机构获得机构审查委员会豁免,并且这些块是去除患者标识的。患者数据未链接到任何google用户数据。此外,根据法规,数据许可和/或数据使用协议,我们的系统还包括保持每个图像数据集彼此分离的沙箱基础架构。每个沙箱中的数据均已加密;所有数据访问均在单个级别上进行控制、记录和审核。
- 还没有人留言评论。精彩留言会获得点赞!