一种适用于无标签不平衡数据流的在线主动学习方法与流程
本发明涉及在线学习和半监督学习技术领域,具体涉及一种适用于无标签不平衡数据流的在线主动学习方法。
背景技术:
近年来,人工智能及相关产业正迅速发展壮大,成为学术界、工业界以及世界各国政府关注的焦点。最近,国务院发布了《新一代人工智能发展规划》,突出了人工智能研究和产业的国家战略地位。在互联网行业,在线学习技术得到了飞速发展,并在多个应用领域取得了长足进展。然而,现有在线学习技术尚存在诸多挑战。首先,原始流数据是无标签的,并且数据的标注代价往往非常高昂。如何在标注预算受限的情况下,选择最具判别力的数据进行标注,并训练一个性能良好的学习器是在线学习及其工业应用的重要问题。其次,大量实际任务场景中,数据的类别往往是不平衡的,即正类数据远远少于负类数据。如何解决样本的类别不平衡问题也是工业应用亟待解决的关键问题。
技术实现要素:
有鉴于此,为解决上述现有技术中的问题,本发明提供了一种适用于无标签不平衡数据流的在线主动学习方法,针对不平衡数据提出非对称访问策略,动态地决定需要标注标签的样本;为有效更新模型,该方法进一步提出非对称更新策略,并利用样本的二阶信息高效地更新模型;同时对实际分类应用中所存在的标注数据稀疏、样本不平衡、流数据等问题具有较好的解决能力。
为实现上述目的,本发明的技术方案如下。
一种适用于无标签不平衡数据流的在线主动学习方法,包括以下步骤:
步骤1、无标签数据流时序地输入线性分类器中进行预测,其中数据流的类别具有高度不平衡问题,通常设定正类样本为类别稀少样本;
步骤2、根据提出的非对称访问策略,线性分类器针对无标签不平衡数据,时序地决定需要被标注标签的样本;
步骤3、根据提出的非对称更新策略,线性分类器利用错误预测的标注数据更新线性分类器,并利用样本的二阶信息提高学习效率。
进一步地,所述步骤1中,所述无标签数据流可表示为
步骤11、所述线性分类器表示为
步骤12、所述线性分类器的分类预测表示为
步骤13、所述线性分类器的预测结果表示为:若
进一步地,所述步骤2中非对称访问策略的步骤如下:
步骤21、基于样本的二阶信息σ(即线性分类器的方差),计算线性分类器对当前样本的置信度;
步骤22、基于置信度,计算当前样本的非对称访问参数;
步骤23、基于非对称访问参数,进行伯努利采样,获取其采样值;
步骤24、如果该采样值为1,则判定需要访问该样本的标签;反之,则不需要。
进一步地,所述步骤3中非对称更新策略的步骤如下:
步骤31、获取错误预测的有标签数据;
步骤32、基于错误预测的有标签数据,计算该数据的非对称损失函数值;
步骤33、基于非对称损失函数值和优化策略,更新线性分类器的方差σ:
其中,γ代表正则化系数;
步骤34:基于非对称损失函数值和优化策略,更新线性分类器的均值μ:
μt+1=μt-ησt+1gt
其中,η代表线性分类器的学习率,gt代表非对称损失函数值lt的梯度,对损失函数求导即可得。
进一步地,通过以下公式计算置信度:
其中,η代表线性分类器的学习率,γ代表正则化系数,ρmax=max(1,ρ),ρ代表正类样本的误分类代价;此外,
基于置信度ct,通过以下公式计算当前样本的非对称访问参数:
qt=|pt|+ct
其中,
基于非对称访问参数qt,进行伯努利采样,获取采样值;对于不同类别的样本设定不同的采样系数,通过以下表示采样概率:
其中,δ+为正类预测(即pt≥0)的采样系数,δ_为负类预测(即pt<0)的采样系数;通过该采样概率进行伯努利采样,获取采样值zt。
进一步地,通过以下公式计算非对称损失函数值:
其中,ρ代表正类样本的误分类权重;
基于该非对称损失函数值lt和优化策略,通过步骤3.3和步骤3.4的公式更新线性分类器的方差σ和均值μ:
与现有技术比较,本发明的一种适用于无标签不平衡数据流的在线主动学习方法具有以下优点和技术效果:
本发明利用样本的二阶信息,提出了新的非对称策略;该非对称策略同时考虑样本的标注和模型的更新,能够更好地解决样本的类别不平衡问题,并提升基于流数据的主动学习模型的分类性能。
附图说明
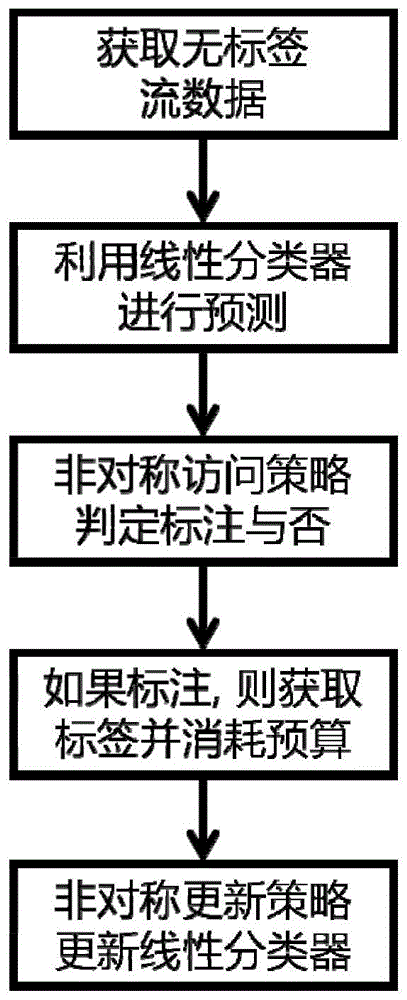
图1为实施例中一种适用于无标签不平衡数据流的在线主动学习方法的流程示意图。
图2为实施例中非对称访问策略的流程示意图。
图3为实施例中非对称更新策略的流程示意图。
图4为实施例中该在线主动学习方法的验证结果。
具体实施方式
下面将结合附图和具体的实施例对本发明的具体实施作进一步说明。需要指出的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1所示,为本实施例的一种适用于无标签不平衡数据流的在线主动学习方法的流程示意图,包括以下步骤:
步骤1、无标签数据流时序地输入线性分类器中进行预测,其中数据流的类别具有高度不平衡问题,通常设定正类样本为类别稀少样本;
步骤2、根据提出的非对称访问策略,线性分类器针对无标签不平衡数据,时序地决定需要被标注标签的样本;
步骤3、根据提出的非对称更新策略,线性分类器利用错误预测的标注数据更新线性分类器,并利用样本的二阶信息提高学习效率。
所述步骤1中,所述无标签数据流可表示为
步骤11、所述线性分类器表示为
步骤12、所述线性分类器的分类预测表示为
步骤13、所述线性分类器的预测结果表示为:若
如图2所示,为本发明的非对称访问策略的流程示意图,所述步骤2中非对称访问策略的步骤如下:
步骤21、基于样本的二阶信息σ(即线性分类器的方差),计算线性分类器对当前样本的置信度:
其中,η代表线性分类器的学习率,γ代表正则化系数,ρmax=max(1,ρ),ρ代表正类样本的误分类代价;此外,
步骤22、基于置信度ct,通过以下公式计算当前样本的非对称访问参数:
qt=|pt|+ct
其中,
步骤23、基于非对称访问参数qt,进行伯努利采样,获取采样值;对于不同类别的样本设定不同的采样系数,通过以下表示采样概率:
其中,δ+为正类预测(即pt≥0)的采样系数,δ-为负类预测(即pt<0)的采样系数;通过该采样概率进行伯努利采样,获取采样值zt;
步骤24、如果该采样值zt为1,则判定需要访问该样本的标签,则消耗预算获取其标签;反之如果zt为0,则判定不需要访问其标签。
如图3所示,为本发明的非对称更新策略的流程示意图,所述步骤3中非对称更新策略的步骤如下:
步骤31、获取错误预测的有标签数据
步骤32、基于错误预测的有标签数据,通过以下公式计算非对称损失值:
其中ρ代表正类样本的误分类权重;
步骤33、基于非对称损失函数值lt和优化策略,通过以下公式更新线性分类器的方差σ:
其中,γ代表正则化系数;
步骤34、基于非对称损失函数值lt和优化策略,过以下公式更新线性分类器的均值μ:
μt+1=μt-ησt+1gt
其中,η代表线性分类器的学习率,gt代表非对称损失函数值lt的梯度,对损失函数求导即可得。
图4展示了该适用于无标签不平衡数据流的在线主动学习方法在网络安全数据集w8a上取得的性能,该方法在图4中的名字为oa3和oa3_diag,其中oa3_diag是本方法的一个简单变体,不详细描述。其他比较方法,如paa,oaal,csoal,soal为该问题上经典的解决办法,作为所提出方法的实验参照。
w8a数据集是一个经典开源数据集,用于判别网页是否异常。该数据集具有64700个样本,300个特征值。其正常网页数量远远多于异常网页,即属于不平衡数据,其不平衡度为1:32.5。本实例设定异常网页为正类样本(少数类),正常网页为负类样本(多数类)。
在实验时,所有训练样本时序到来且无标签。所提出的主动学习方法将针对每一时刻到来的网页根据步骤2判断是否需要标注。若需要,则以一定得金钱作为标注代价获取标签,并根据步骤3更新模型。
详细实验结果如图4所示,所提出的适用于无标签不平衡数据流的在线主动学习方法取得了最为优异的性能。
本实施例的一种适用于无标签不平衡数据流的在线主动学习方法,针对不平衡数据提出非对称访问策略,动态地决定需要标注标签的样本;为有效更新模型,该方法进一步提出非对称更新策略,并利用样本的二阶信息高效地更新模型;同时对实际分类应用中所存在的标注数据稀疏、样本不平衡、流数据等问题具有较好的解决能力。
- 还没有人留言评论。精彩留言会获得点赞!