一种基于关系正则化的视觉场景图生成系统及方法与流程
本发明涉及视觉场景图生成技术,具体涉及一种基于关系正则化的视觉场景图生成系统及方法。
背景技术:
视觉场景图(visualscenegraph)是对图像内容的高度概括,它由一系列结点(图像中的实体)和边(实体与实体之间的关系)组成。视觉场景图生成任务是指输入一张图片,模型不仅要探测出图像所包含的物体(边框以及类别),还要探测出物体与物体之间的关系。
因为视觉场景图生成需要探测图像中包含的物体,所以大多数方法都使用了一个很有效的物体检测模型—fasterr-cnn去检测物体的边框以及类别。但是之前的工作都只是利用fasterr-cnn的检测结果再去判断物体间的关系,很少有人去考虑物体间的关系对物体检测的影响。而且之前的工作也揭示了一个现象:如果已知两物体间的确存在关系,那么判断具体是什么关系就会容易许多。所以如何判断物体间是否存在关系以及如何利用这种信息去增强模型的效果就成为了一个问题。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于关系正则化的视觉场景图生成系统及方法,快速有效地判断物体间是否存在关系,有利于增强物体检测模型的探测效果。
本发明解决上述技术问题所采用的技术方案是:
基于关系正则化的视觉场景图生成系统,包括:
物体检测器、物体标签精练器和物体关系生成器;
所述物体检测器,用于探测图像中的物体,获得物体的标签、物体边框特征和联合边框特征;
所述物体标签精练器,包括关系正则化的标签编码器和标签解码器;
所述关系正则化的标签编码器,用于编码物体检测器探测出的物体边框特征,获得全局特征,并基于全局特征获得关系仿射矩阵,融合物体间的仿射关系获得关系正则化的特征;所述标签解码器,用于基于关系正则化的标签编码器的输出来解码物体的标签,获得精练后的标签;
所述物体关系生成器,包括关系正则化的关系编码器和关系解码器;
所述关系正则化的关系编码器,用于编码标签解码器的输出,获得关系正则化的关系特征:所述关系解码器,对关系特征进行解码,获得物体间的关系。
作为进一步优化,所述关系正则化的标签编码器和关系正则化的关系编码器中均包括bi-lstms网络以及gcns网络;通过bi-lstms网络来获取包含全局上下文信息的特征,再利用这种特征获取物体间的仿射关系来判断任意物体间存在关系的可能性;最后利用gcns网络融合仿射关系来获得关系正则化的特征。
作为进一步优化,所述关系正则化的标签编码器采用拼接关系正则化的特征和全局特征作为输出。
此外,本发明还提供了一种基于关系正则化的视觉场景图生成方法,其包括:
a.探测物体:
探测图像中的物体,获得物体的标签、物体边框特征和联合边框特征;
b.对物体的标签进行精练:
编码探测出的物体边框特征,获得全局特征,并基于全局特征获得关系仿射矩阵,融合物体间的仿射关系获得关系正则化的特征;基于关系正则化的标签编码器的输出来解码物体的标签,获得精练后的标签;
c.获取物体间的关系:
编码标签解码器的输出,获得关系正则化的关系特征;对关系特征进行解码,获得物体间的关系。
作为进一步优化,步骤a中,采用基于resnet101的fasterr-cnn网络探测图像中的物体,所述fasterr-cnn网络为在视觉基因数据集上预训练获得。
作为进一步优化,步骤b具体包括:
b1.采用带有高速连接的bi-lstm网络编码fasterr-cnn探测出的物体边框特征,获得全局特征h={h1,...,hn};hi表示物体i融合全局信息后的特征;
b2.基于全局特征h获得一个图的关系仿射矩阵
b3.通过两个全连接层将hi映射到一个主体空间和一个客体空间:
b4.利用distmult模型来构建仿射矩阵:
其中,
b5.调整仿射矩阵
b6.使用gcns网络编码全局特征h生成关系正则化的特征
o={o1,...,on}:
o=relu(dsashwg)
relu表示线性整流函数;wg是模型需要学习的参数;
b7.拼接h和o作为关系正则化编码器的输出:
o′i=[oi,hi]
b8.采用lstm网络来解码每个物体的标签:
lstm表示标准的长短期记忆网络;
作为进一步优化,步骤c具体包括:
c1.采用关系正则化的关系编码器编码上层的输出:
{ar,z}=r2_encoder([o′,wlld]|wz);
c2.获得关系正则化后的关系特征:
z={z1,…,zn};
c3.采用两个全连接层将z映射到主体空间和客体空间:
c4.使用distmult模型生成关系分数:
r′m,i,j是指以物体i作为主体,以物体j作为客体属于关系m的分数;
c5.使用softmax函数将分数映射到0至1:
dr是数据集中包含的表示关系单词的数量;
最终获得映射到0至1的关系分数
本发明的有益效果是:
在很好地利用全局上下文信息的同时,能够充分地发掘并利用物体间的仿射关系。模型将仿射关系通过gcns融合,得到了关系正则化的特征,从而同时增强了物体标签识别以及场景图生成的效果。
附图说明
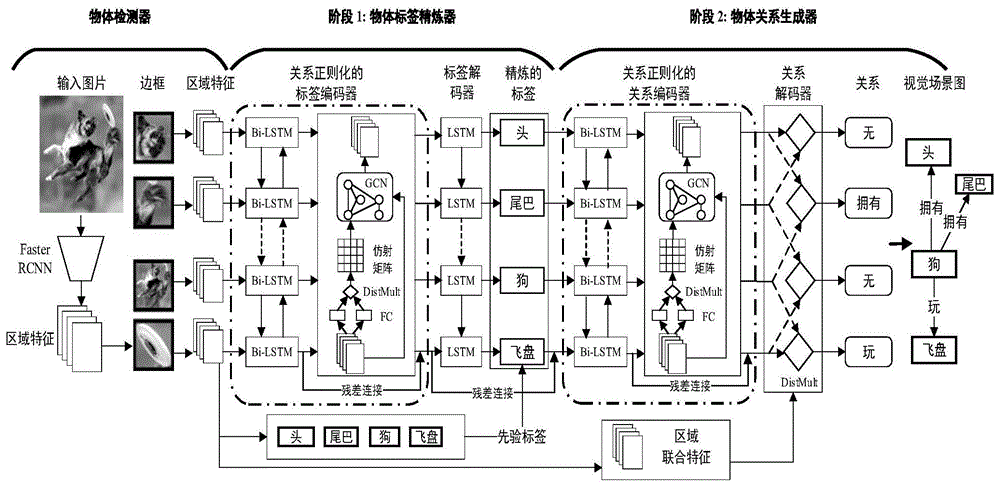
图1为本发明中的基于关系正则化的视觉场景图生成系统原理图。
具体实施方式
本发明旨在提出一种基于关系正则化的视觉场景图生成系统及方法,快速有效地判断物体间是否存在关系,有利于增强物体检测模型的探测效果。
为了实现上述目的,本发明设计了基于关系正则的网络来生成视觉场景图。由于之前有工作证明了物体的标签对最后的场景图有非常大的影响,所以我们提出了物体标签精炼模块用来改善fasterr-cnn生成的物体标签。之后又使用了关系生成模块用来生成最终的视觉场景图。每个模块都由双向长短时记忆模型(bi-lstms)以及图卷积网络(gcns)构成,通过bi-lstms来获取包含全局上下文信息的特征,再利用这种特征获取一个关系矩阵来判断任意物体间存在关系的可能性,最后利用gcns将这种信息融合来获得关系正则化的特征。通过这种方式来判断物体间是否存在关系并且利用这种信息去增强模型效果。
如图1所示,本发明中的基于关系正则化的视觉场景图生成系统整体框架包括三个部分:物体检测器、物体标签精炼器以及物体关系生成器。
下面将详细介绍各个部分的功能及实现方案。
由于视觉场景图生成任务中,首先需要尽可能多地探测出图像的物体。所以与其他工作类似,我们使用了一种在物体检测任务中非常有效的模型fasterr-cnn来探测图像中的物体。我们首先在视觉基因(visualgenome)数据集上预训练了基于resnet101的fasterr-cnn。之后使用这种fasterr-cnn来处理图像(如图1的物体检测器部分所示),从而获得物体的以下信息:
a)一系列标签的分布l={l1,...,ln},此处
b)对应物体边框特征f={f1,...,fn},此处
c)以及一系列联合边框的特征u={u1,1,...,un,n},此处
正如其他工作中的实验所展示的,物体的标签对最终场景图的生成有很大影响。所以,我们首先使用物体标签精炼器来改善从fasterr-cnn生成的标签。如图1所示物体标签精炼器包含两部分:关系正则化的标签编码器和标签解码器。
由于fasterr-cnn是孤立地探测每个区域出现的物体,并没有考虑图像中的全局上下文信息,所以我们使用带有高速连接(highway)的bi-lstm(双向长短期记忆模型)去编码fasterr-cnn探测出的物体边框特征f:
此处xk,t是指第k层的lstm的第t步输入。ik,t、sk,t、ok,t、ck,t、hk,t分别表示第k层中第t步输入门、遗忘门、输出门、记忆单元和隐藏状态。σ表示sigmoid函数,tanh表示双曲函数。
此处的ft是指第t步的输入。由于我们使用的是双向的lstm,所以模型对输入的顺序不敏感,简单起见我们按照物体从左到右的顺序去排列物体特征f并将其作为bi-lstm的输入。
图卷积网络(gcns)能够根据图(graph)的邻接矩阵优化图中结点的特征。而且我们认为探索物体间的关系对物体的识别是有帮助的。所以我们首先利用物体特征f作为bi-lstm的输入,获得全局特征h={h1,...,hn},此处hi表示物体i融合全局信息后的特征。再基于全局特征h获得一个图的关系仿射矩阵
其中
之后我们就可以使用gcns编码全局特征h用来生成我们的关系正则化的特征o={o1,...,on}:
o=relu(dsashwg)(7)
relu表示线性整流函数,其中wg是模型需要学习的参数,
最后我们拼接h和o作为我们关系正则化编码器的输出:
o′i=[oi,hi](9)
为了简便起见我们表示我们的关系正则化的标签编码器如下:
{ae,o′}=r2_encoder(f|wo)(10)
r2_encoder表示从公式(1)到公式(9)整个模型。f表示输入的特征,ae表示我们获得的放射矩阵,o′表示关系正则化后的物体特征,wo代表编码模块中的所有需要学习的参数。
最后我们使用了一层lstm来解码每个物体的标签,从而改善fasterr-cnn生成的标签:
lstm表示标准的长短期记忆网络,
至此,我们已经得到了精炼后的物体标签ld,之后我们就进入第二阶段--物体关系生成器来生成图像中物体与物体的关系。如图1所示物体关系生成器也包含两部分:关系正则化的关系编码器和关系解码器。我们使用了关系正则化的关系编码器编码上层的输出:
{ar,z}=r2_encoder([o′,wlld]|wz)(12)
此处
最后我们就进入了关系解码阶段,同样我们还是要用两个全连接层将z映射到主体空间和客体空间:
之后再次使用distmult模型去生成关系分数:
此处r′m,i,j是指以物体i作为主体,以物体j作为客体属于关系m的分数。
r′m,i,j是指初始化的分数如公式(14)描述,e是自然对数函数的底数,此处dr是数据集中包含的表示关系单词的数量。最后我们得到了映射到0至1的关系分数r={r1,1,1,...,rdr,n,n}。
对于损失函数的构建,首先在标签精炼阶段,我们构建了标签损失函数和第一个仿射矩阵损失函数,两者形式都是交叉熵:
在关系生成阶段:
其中ld、ae、ar以及r分别是公式(11)、(5)、(12)以及(15)的输出。lg、ag、以及rg分别是数据集中真实的物体标签、邻接矩阵以及关系标签。我们构建真实邻接矩阵的方式是判断两物体间是否存在关系若存在就为1,若不存在关系就为0。最后我们将四个损失函数求和作为模型整体的损失函数。
- 还没有人留言评论。精彩留言会获得点赞!