一种基于大数据的小型企业失信预测方法与流程
本发明涉及机器学习领域,具体而言,涉及一种基于大数据的小型企业失信预测方法。
背景技术:
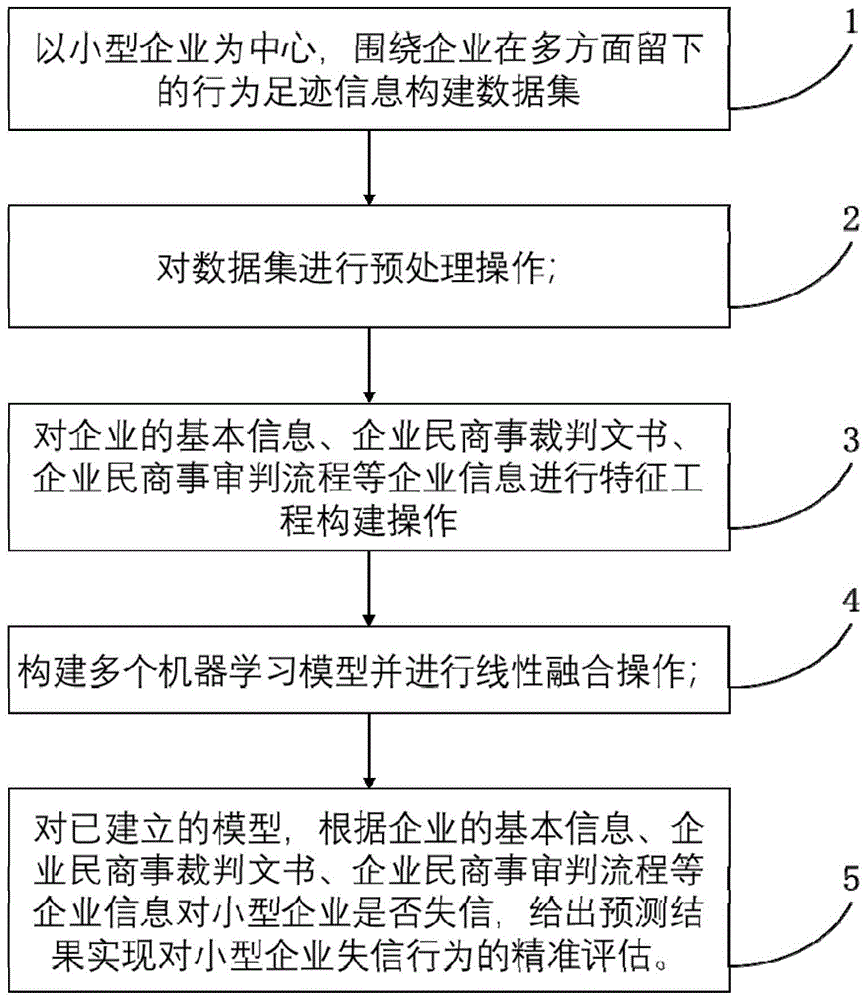
:近年来,我国小型企业正处于飞速发展的阶段,小型企业的影响力逐渐扩大并成为社会经济发展的重要推动力。信用是整个社会的基础,市场交易中所有的经济活动与信用信息息息相关。为加强融资市场的风险管理与处理能力,降低小型企业的融资风险,促进融资市场的发展,建立完善的融资风险评测体系迫在眉睫,企业的失信与否关乎着整个企业的命运。本发明旨在利用大数据和人工智能、机器学习等相关技术,实现对小型企业是否会出现失信的精准识别,进一步提升金融机构防范欺诈和降低不良率的能力。现有技术中,只有对企业失信行为进行预测,未过多关注小型企业失信问题,同时当前技术中缺乏结合实际小型企业失信问题进行分析与预测。技术实现要素:针对小型企业是否失信问题,本发明提出一种基于大数据的小型企业失信预测方法,包括:s1、根据企业的行为足迹信息构建数据集;s2、对数据集进行预处理操作;s3、对数据集中的企业信息进行特征工程构建操作,构建统计特征、离散特征;s4、构建多个机器学习模型并进行线性融合操作;s5、对已建立的模型,根据企业的基本信息、企业民商事裁判文书、企业民商事审判流程等企业信息对小型企业是否失信,给出预测结果实现对小型企业失信行为的精准评估。进一步的,所述企业的行为足迹信息包括企业基本信息、企业民商事裁判文书、企业民商事审判流程、企业的行政违法记录、欠税信息、纳税信息以及限制高消费信息。进一步的,企业基本信息包括小微企业id、注册资金、注册资本币种、企业类型、行业门类代码、许可经营项目、一般经营项目、经营范围、成立日期、从业人数、投资总额、投资总额币种;企业民商事裁判文书信息包括小微企业id、诉讼地位、审理机关、涉案事由、涉案金额、文书类型、审理程序、结案时间;企业民商事审判流程信息包括小微企业id,诉讼地位、审理机关、涉案是由、审理进度、具体日期;企业违法记录信息包括小微企业id、违法信息、具体日期;企业欠税信息包括小微企业id、欠税金额、所欠税种、具体日期;企业纳税信息包括小微企业id、主管税务机关、所欠税种、欠税属期、欠税金额、具体日期;企业限制高消费信息小微企业id、是否被限制高消费。进一步的,预处理操作包括对数据集的信息按照结案时间或者具体日期进行排序,对企业基本信息注册资金、投资总额进行单位统一以及对缺失值的填充。进一步的,统计特征包括企业欠税次数、企业违法次数、企业所欠税种排名前10的税种的欠税次数、企业被告排名前10的被告原因的被告次数以及企业民商事涉案金额。进一步的,离散特征的筛选包括将注册资本和行业门类代码属性列分别进行one-hot编码并筛选出现次数过少的特征作为离散特征。进一步的,对缺失值的填充包括根据欧式距离分析来确定距离缺失数据最近的k个样本,将这k个值加权平均来估计该样本的缺失数据。进一步的,步骤s4包括建立多个模型,包括支持向量机svm机器学习模型、lightgbm模型、xgboost模型、catboost模型。进一步的,步骤s4中进行线性融合操作包括:y=x1×w1+x2×w2+x3×w3+x4×w4;其中,y表示预测结果;x1表示svm机器学习模型,w1表示svm机器学习模型的权值;x2表示lightgbm模型,w2表示lightgbm机器学习模型的权值;x3表示xgboost模型,w3表示xgboost机器学习模型的权值;x4表示catboost模型,w4表示catboost机器学习模型的权值。进一步的,svm机器学习模型的权值w1为0.05;lightgbm机器学习模型的权值w2为0.5;xgboost机器学习模型的权值w3为0.25;catboost机器学习模型的权值w4为0.2。本发明以小型企业为中心,围绕小型企业在多方面的行为足迹信息,通过构建数据集,数据预处理、特征工程、多个模型线性融合以及利用构建的模型对小型企业是否失信,给出预测结果实现对小型企业失信行为的精准评估。附图说明图1是本发明实施例提供的算法流程图;图2是本发明实施例提供整个算法的的流程图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本大明提出一种基于大数据的小型企业失信预测方法,如图1,包括:s1、根据企业的行为足迹信息构建数据集;s2、对数据集进行预处理操作;s3、对数据集中的企业信息进行特征工程构建操作,构建统计特征、离散特征;s4、构建多个机器学习模型并进行线性融合操作;s5、对已建立的模型,根据企业的基本信息、企业民商事裁判文书、企业民商事审判流程等企业信息对小型企业是否失信,给出预测结果实现对小型企业失信行为的精准评估。在本实施例中,如图2,以小型企业为中心,围绕企业在多方面留下的行为足迹信息构建数据集,包括企业基本信息、企业民商事裁判文书、企业民商事审判流程、企业的行政违法记录、企业欠税信息、企业纳税信息以及限制高消费信息;其中企业基本信息数据表字段如表1,企业基本信息包括小微企业id、注册资金(万元)、注册资本(金)币种、企业(机构)类型、行业门类代码、许可经营项目、一般经营项目、经营(业务)范围、成立日期、从业人数、投资总额(万元)、投资总额币种等;表1企业基本信息表字段名称type小微企业idvarchar(50)注册资金(万元)int(10)注册资本(金)币种varchar(50)企业(机构)类型varchar(50)行业门类代码varchar(50)许可经营项目varchar(255)一般经营项目varchar(255)经营(业务)范围varchar(255)成立日期datetime(10)从业人数int(10)投资总额(万元)int(10)投资总额币种varchar(50)企业民商事裁判文书信息的数据表字段如表2,业民商事裁判文书信息包括小微企业id、诉讼地位、审理机关、涉案事由、涉案金额(元)、文书类型、审理程序、结案时间等。表2企业民商事裁判文书字段名称type小微企业idvarchar(50)诉讼地位varchar(50)审理机关varchar(50)涉案事由varchar(50)涉案金额(元)int(10)文书类型varchar(50)审理程序varchar(50)结案时间datetime(10)企业民商事审判流程信息的数据表字段如表3,企业民商事审判流程信息包括小微企业id,诉讼地位、审理机关、涉案是由、审理进度、具体日期等。表3企业民商事审判流程信息字段名称type小微企业idvarchar(50)诉讼地位varchar(50)审理机关varchar(50)涉案事由varchar(50)审理进度varchar(50)具体日期datetime(10)企业的行政违法记录数据表字段如表4,企业的行政违法记录信息包括小微企业id、违法信息、具体日期等。表4企业行政违法记录信息企业的欠税信息数据表字段如表5,企业的欠税信息包括小微企业id、欠税金额(元)、所欠税种、具体日期等。表5企业欠税信息字段名称type小微企业idvarchar(50)欠税金额(元)int(10)所欠税种varchar(50)具体日期datetime(10)企业欠税信息的数据表字段如表6,企业欠税信息包括小微企业id、主管税务机关、所欠税种、欠税属期、欠税金额(元)、具体日期等。表6企业纳税信息字段名称type小微企业idvarchar(50)税种类别varchar(50)纳税金额(元)int(10)具体日期datetime(10)企业限制高消费信息数据表如表7,企业限制高消费信息包括小微企业id、是否被限制高消费等表7企业限制高消费信息字段名称type小微企业idvarchar(50)是否被限制高消费bool(2)对数据集进行预处理操作,包括所有的数据集按照结案时间或者具体日期列进行排序,对企业基本信息注册资金(万元)以及投资总额(万元)进行单位统一,其中注册资金(万元)以及投资总额(万元)单位包括“人民币元”、“美元”以及“日元”等,统一按照汇率转换成人民币元。在进行k近邻缺失值填充时,对缺失值字段先根据欧式距离分析来确定距离缺失数据最近的k个样本,将这k个值加权平均来估计该样本的缺失数据。其中d(x,y)为缺失样本数据到最近的k个样本的欧式距离,x、y将其看作两个向量,xi是x向量的第i个元素,yi是y向量的第i个元素;其欧式距离d(x,y)如下:对企业的基本信息、企业民商事裁判文书、企业民商事审判流程等企业信息进行特征工程构建操作,构建统计特征、离散特征等;具体包括:统计特征:企业欠税次数、企业违法次数、企业所欠税种排名前10的税种的欠税次数、企业被告排名前10的被告原因的被告次数以及企业民商事涉案金额统计等;离散特征:注册资本独热one-hot编码并筛选出现次数过少的特征,行业门类代码one-hot编码;构建多个机器学习模型并进行线性融合操作,判断企业失信问题属于分类问题,所以采用有效的分类器构建svm、lightgbm、xgboost、catboost四个机器学习模型,并进行线性融合操作;其中线性融合关系如下所示:y=x1×w1+x2×w2+x3×w3+x4×w4;其中,y表示预测结果;x1表示svm机器学习模型,w1表示svm机器学习模型的权值;x2表示lightgbm模型,w2表示lightgbm机器学习模型的权值;x3表示xgboost模型,w3表示xgboost机器学习模型的权值;x4表示catboost模型,w4表示catboost机器学习模型的权值。线性加权的权重如表8所示,这些权重经过多次试验和总结,其中svm的效果略差,一般svm机器学习模型的权值不超过0.1,优选的,本实施例将svm机器学习模型的权值w1设置为0.05;lightgbm的表现最好,一般将lightgbm机器学习模型的权值不小于0.4,优选的,本实施例将lightgbm机器学习模型的权值w2设置为0.5;catboost的预测准确率与xgboost效果相似,一般将其权值设置在0.2~0.3,优选的,本实施例将w3表示xgboost机器学习模型的权值为0.25;catboost的预测准确率与xgboost效果相似将w4表示catboost机器学习模型的权值为0.2。表8机器学习模型的权值模型权重ωlsvm0.05xgboost0.5lightgbm0.25catboost0.2第五步,对已建立的模型,根据企业的基本信息、企业民商事裁判文书、企业民商事审判流程等企业信息对小型企业是否失信,给出预测结果实现对小型企业失信行为的精准评估。尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1