一种基于大数据的用户搜索匹配方法与流程
本发明涉及大数据、人工智能、机器学习领域,具体而言,涉及一种基于大数据的用户搜索匹配方法。
背景技术:
随着互联网应用的普及推广以及对人们生活的渗透,越来越多的用户习惯于从互联网获取其所需的信息,例如通过互联网关注某热点问题等;因而需要大量的使用到搜索相关的引擎;在搜索业务下有一个场景被称作实时搜索(instancesearch),即在用户不断输入过程中,实时返回查询结果。用户在实时搜索时,搜索引擎会根据用户的输入自动联想,例如用户输入“大数据”,搜索引擎会联想到“大数据分析”、“大数据预测”、“大数据概念”等条目,搜索匹配方法就是正确匹配到用户将要点击的条目;即搜索匹配方法是指将用户输入的条目与搜索引擎联想的条目进行正确匹配,意在解决搜索输入与联想条目的语义匹配问题。搜索匹配方法可以为搜索引擎联想条目的排序提供参考,可以发掘出用户点击联想条目的潜在偏好。
令用户的输入为prefix,联想的条目为query_prediction,将要点击的条目为title,搜索匹配方法就是意在解决prefix-title语义匹配的问题。
传统的技术有基于关键字匹配、基于点击量匹配等。基于关键字匹配比较简便,首先提取出输入prefix的关键字,直接与联想条目query_prediction进行字符串匹配。该方法未用到大数据相关的知识,效果较差。基于点击量匹配是统计历史点击量进行语义匹配,且该方法基于传统的机器学习,只能匹配到一个联想条目。
技术实现要素:
基于现有技术存在的问题,本发明提出一种能够较为全面的使用各类特征,且用到了机器学习较前沿的多标签分类算法,从而能更精确地匹配到多个联想条目。本发明提出了一种基于大数据的用户搜索匹配方法,所述方法包括以下步骤:
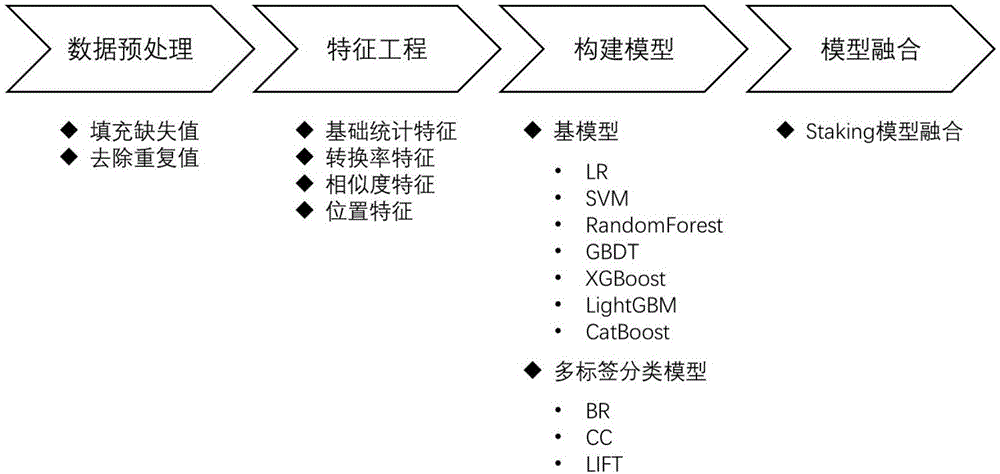
s1、对数据进行预处理操作,包括填充缺失值和去除重复值;
s2、对预处理后的数据集进行特征工程构建操作,提取各类单标签数据集特征包括基础统计特征、转换率特征、相似度特征以及位置特征;
其特征在于,
s3、将特征工程构建后的数据集转换为多标签数据集并训练多个机器学习模型;转换为多标签数据集后其特征定义为多标签数据集特征;包括以逻辑回归lr、支持向量机svm、随机森林randomforest、梯度提升决策树gbdt、极限梯度提升树xgboost、轻量级gbm梯度提升机lightgbm、具有分类特征支持的梯度增强catboost作为基模型分别调用多标签分类算法模型,并预测结果;
s4、对多个机器学习模型进行stacking模型融合操作,确定出用户搜索匹配的最终概率;其中,多标签分类模型包括二元关联模型br、分类器链模型cc以及基于标签特定特征的多标签模型lift。
进一步的,所述填充缺失值包括对数值型属性的缺失值使用中位数填充;对非数值型属性的缺失值使用众数填充;所述重复值处理包括记录样本的重复次数作为特征,删除重复的样本;具体包括:
将缺失值的数值型属性的列按照从小到大排序后依次为:
attr1、attr2、attr3、…、attrl,则缺失值attr_null填充为:
将缺失值的非数值属性的列取值的个数依次为:
attr1_ns、attr2_ns、attr3_ns、…、attrl_ns,则缺失值attr_null填充为:
attr_null=argmax(attr1_ns,attr2_ns,…,attrl_ns);
其中,l表示属性列的长度或个数。
进一步的,对预处理后的数据集进行特征工程构建操作包括构建基础统计特征、转换率特征、相似度特征以及位置特征这些单标签数据集特征;具体包括:
基础统计特征:分别统计各个用户点击的各类统计参数;统计各种联想的所有条目query_prediction被点击的各类参数;统计各个用户点击各种query_prediction的各类参数;其中,所述各类参数包括总次数、均值、方差、标准差、众数、中位数、最大值、最小值、偏度以及峰度;
转换率特征:计算各个用户点击的转换率;计算各种联想的所有条目被点击的转换率;计算各个用户点击各种query_prediction的转换率;
相似度特征:计算各个用户输入prefix和当前条目title的1-2gram的余弦相似度;计算prefix针对于title的召回率、准确率以及精度;
位置特征:输入prefix判断其是否出现在query_prediction中,并定位其出现的位置。
进一步的,所述步骤s3包括将用户搜索的点击的多个联想条目转换为机器学习的多标签问题,转换为多标签数据集后其特征定义为多标签数据集特征,以lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost作为基模型调用多标签分类算法br、cc、lift,训练得到多个机器学习模型。
进一步的,所述步骤s4包括对步骤s3得到的多个机器学习模型进行stacking模型融合,分别用线性回归以三折交叉训练子模型,拟合每一折后得到三个系数,以这三个系数的均值作为该子模型的融合系数作为stacking的第一层,再以这多个子模型进行训练,得到每个子模型的预测结果,将预测结果乘上各自的融合系数,求和得到最终概率。
进一步的,分别对每个模型调用线性回归得到每一折的预测结果包括:
将多个模型的预测值作为x,训练集每一折的真实值作为y,再次调用线性回归模型,:
则多个模型最终的融合系数为:
其中mo表示第o个模型,yo_mpred表示第o个模型第m折的预测值,m∈{1,2,3};wo_m_n表示第o个模型的第m折的第n个系数,n∈{1,2,...,k};k表示提取的多标签数据集特征个数;xz表示第z个多标签数据集特征;ymf表示第m折的真实标签,wm_n表示第m折的第n个线性回归系数。
本发明的有益效果:
本发明通过采用对数据进行预处理操作,包括填充缺失值与去除重复值;对预处理后的数据集进行特征工程构建操作,提取基础统计特征、转换率特征、相似度特征、位置特征这四大类特征;将特征工程构建后的数据集转换为多标签数据集并训练多个机器学习模型,包括以lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost作为基模型调用的多标签分类算法模型br、cc、lift,并预测结果;对多个机器学习模型进行stacking模型融合操作,从而得出搜索匹配的概率。与基于关键词匹配的方法相比,本方法用到了大数据相关的技术,其性能远远优于未使用到大数据相关技术的基于关键词匹配;与基于点击量匹配的方法相比,本方法使用的特征比较全面,且用到了机器学习较前沿的多标签分类算法,能更精确地匹配到多个联想条目。
附图说明
图1是本发明提供整个方法的流程图;
图2是本发明实施例提供br模型的图形说明图;
图3是本发明实施例根据cc模型的图形说明图;
图4是本发明实施例提供lift模型的图形说明图;
图5表示发明实施例提供转换为多标签数据集的图形说明图;
图6表示发明实施例提供stacking模型融合图形说明。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
本发明的目的是提供一种基于大数据的用户搜索匹配方法,为搜索引擎联想条目的排序提供参考,发掘出用户点击联想条目的潜在偏好。本发明提出的一种基于大数据的用户搜索匹配方法,如图1所示,本发明主要包括四个部分数据预处理、特征工程、构建模型以及模型融合;具体步骤参考以下步骤:
s1、对数据进行预处理操作:
(1)缺失值处理:
①对数值型属性的缺失值使用中位数填充。
假设含有缺失值的属性列从小到大排序后依次为attr1、attr2、attr3、…、attrl,则缺失值attr_null填充为:
②对非数值型属性的缺失值使用众数填充。
假设含缺失值的属性列取值的个数依次为attr1_ns、attr2_ns、attr3_ns、…、attrl_ns,则缺失值attr_null填充为:
attr_null=argmax(attr1_ns,attr2_ns,…,attrl_ns)
(2)重复值处理:
先记录样本的重复次数作为特征,然后删除重复的样本。
s2.对预处理后的数据集进行特征工程构建操作:
(1)基础统计特征
统计各个用户点击的总次数、均值、方差、标准差、众数、中位数、最大值、最小值、偏度、峰度;统计各种query_prediction被点击的总次数、均值、方差、标准差、众数、中位数、最大值、最小值、偏度、峰度;统计各个用户点击各种query_prediction的总次数、均值、方差、标准差、众数、中位数、最大值、最小值、偏度、峰度。
(2)转换率特征
计算各个用户点击的转换率;计算各种query_prediction被点击的转换率;计算各个用户点击各种query_prediction的转换率。
(3)相似度特征
计算各个prefix和title的1-2gram的余弦相似度等;计算prefix针对于title的召回率、准确率、精度等。
(4)位置特征
输入prefix是否出现在query_prediction中,并定位其出现的位置(前、中、后)
s3.将特征工程构建后的数据集转换为多标签数据集,训练多个机器学习模型并预测结果:
(1)多标签处理:
数据来源于日常搜索真实用户点击数据,数据集内同一搜索词对应多个点击是真实存在的,即用户对于某个搜索词可能会点击多个联想的条目。将其转换为机器学习中的多标签问题。转换为多标签数据集后其特征定义为多标签数据集特征。
作为一种可选方式,本发明采用以下三种标签分类算法:
(2)br模型:
如图2所示,二元关联(binaryrelevance,br)是最基本的多标签分类算法,它假设标签之间相互独立,直接把m个多标签转换为m个二分类问题,其中x表示训练集的特征,yi表示训练集的第i个标签,hi表示训练得到的第i个基模型(lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost),xq表示测试集的第q个样本的特征,
(3)cc模型:
如图3所示,分类器链(classifierchain,cc)首先确定一条标签链,依次预测链上的标签。对于链上的第一个标签,训练预测时只使用到原始的特征;对于链上的第二个标签,训练预测时使用到了原始的特征和链上第一个标签的预测值;其中x表示训练集的特征,yi表示训练集的第i个标签,hi表示训练得到的第i个基模型(lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost),xq表示测试集的第q个样本的特征,
(4)lift模型:
如图4所示,lift在训练预测时,对每个标签分正负样本分别聚类,以样本与各个聚类中心点的距离作为新特征代替原始特征训练模型,其中x表示训练集的特征,yi表示训练集的第i个标签,di+(x)表示第i个标签为正的样本,di-(x)表示第i个标签为负的样本,ci表示第i个标签的聚类中心点(总共有2×k个,其中k=min(||p+||×ratio,||p-||×ratio),ratio∈(0,1],ratio是输入的控制特定特征规模的参数,||p+||表示该目标下正样本的个数,||p-||表示该目标下负样本的个数),dist表示求欧式距离,xis表示第i个标签的特定特征,hi表示训练得到的第i个基模型(lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost),xq表示测试集的第q个样本的特征,
对转换为多标签的数据集,以lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost作为基模型调用多标签分类算法br、cc、lift,训练得到多个机器学习模型。
s4.对多个机器学习模型进行模型融合操作:
对第3步得到的多个机器学习模型进行stacking模型融合,用线性回归以3折交叉训练子模型拟合每一折得到3个系数,以这3个系数的均值作为该子模型的融合系数作为stacking的第一层,再以这多个子模型进行训练,得到每个子模型的预测结果,将预测结果乘上各自的融合系数,求和得到最终概率。过程如下:
(1)分别对每个模型调用线性回归得到每一折的预测结果。其中mo表示第o个模型,yo_mpred表示第o个模型第m折的预测值,m∈{1,2,3};wo_m_n表示第o个模型的第m折的第n个系数,xz表示第z个特征:
(2)将多个模型的预测值作为x,训练集每一折的真实值作为y,再次调用线性回归模型,其中ymf表示第m折的真实标签,wm_n表示第m折的第n个线性回归系数:
(3)wo表示第o个模型的融合系数,则多个模型最终的融合系数为:
实施例2
在实施例1的基础上,本实施例结合具体数据,对本发明的实施方案进行进一步的阐述,本实施例给定用户输入prefix(用户输入,查询词前缀)以及文章标题、文章类型等数据,预测用户是否点击。数据来源于日常搜索真实用户点击数据,数据集内存在重复、同一搜索词对应多个点击的样本。
训练数据有5个属性,包括user_id(用户id)、prefix(用户输入)、query_prediction(联想的所有条目)、title(当前条目)、label(是否点击)。测试数据只有4个属性,包括user_id、prefix、query_prediction和title,不含label。本发明需要对训练数据进行训练得到模型预测测试集的label。
训练数据的格式具体如表1:
表2实施例1采用的训练数据的格式
训练集的样本数据如表2:
表2实施例2采用的训练集样本数据
本发明提出的一种基于大数据的用户搜索匹配方法,包括以下步骤:
1.对数据进行预处理操作:
(1)缺失值处理:
①对数值型属性的缺失值使用中位数填充。
对于query_prediction属性中统计概率的缺失值,将该prefix下query_prediction的统计概率从小到大排序,依次为attr1、attr2、attr3、…、attrl,则缺失值attr_null填充为:
②对非数值型属性的缺失值使用众数填充。
对于title属性中的缺失值,若该prefix下title各个取值的个数依次为attr1_ns、attr2_ns、attr3_ns、…、attrl_ns,则缺失值attr_null填充为:
attr_null=argmax(attr1_ns,attr2_ns,…,attrl_ns)
(2)重复值处理:
先记录样本的重复次数作为特征,然后删除重复的样本。
2.对预处理后的数据集进行特征工程构建操作:
以user_id、prefix、query_prediction、title及其部分两两组合作为主键,提取基础统计特征(总次数、均值、方差、标准差、众数、中位数、最大值、最小值、偏度、峰度)、转换率特征(点击转换率、被点击转换率)、相似度特征(余弦相似度、召回率、准确率、精度)、位置特征(前、中、后)。
3.将特征工程构建后的数据集转换为多标签数据集,训练多个机器学习模型并预测结果:
首先按照query_prediction的统计概率大小顺序(总共10个),将特征工程构建后的数据集转换为多标签数据集(10个标签),如图5所示,假设有k个子模型,子模型也即多个机器模型中每一个模型;对每个子模型分别进行三折交叉后进行线性回归处理,最后得到每个子模型的融合系数;其中1foldw1表示w1_1,其余参数同理;转换为多标签数据集后其特征定义为多标签数据集特征;再以lr、svm、randomforest、gbdt、xgboost、lightgbm、catboost作为基模型调用多标签分类算法br、cc、lift,训练得到多个机器学习模型。
4.对多个机器学习模型进行模型融合操作:
对第3步得到的多个机器学习模型进行stacking模型融合,用线性回归以3折交叉训练子模型拟合每一折得到3个系数,以这3个系数的均值作为该子模型的融合系数作为stacking的第一层,再以这多个子模型进行训练,得到每个子模型的预测结果,将预测结果乘上各自的融合系数,求和得到最终概率,如图6所示。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!