基于多参数优化生成对抗网络的SAR目标识别方法与流程
本发明属于通信
技术领域:
,更进一步涉及一种合成孔径雷达sar目标型号识别方法,可用于对合成孔径雷达sar目标中静止目标的型号进行识别。
背景技术:
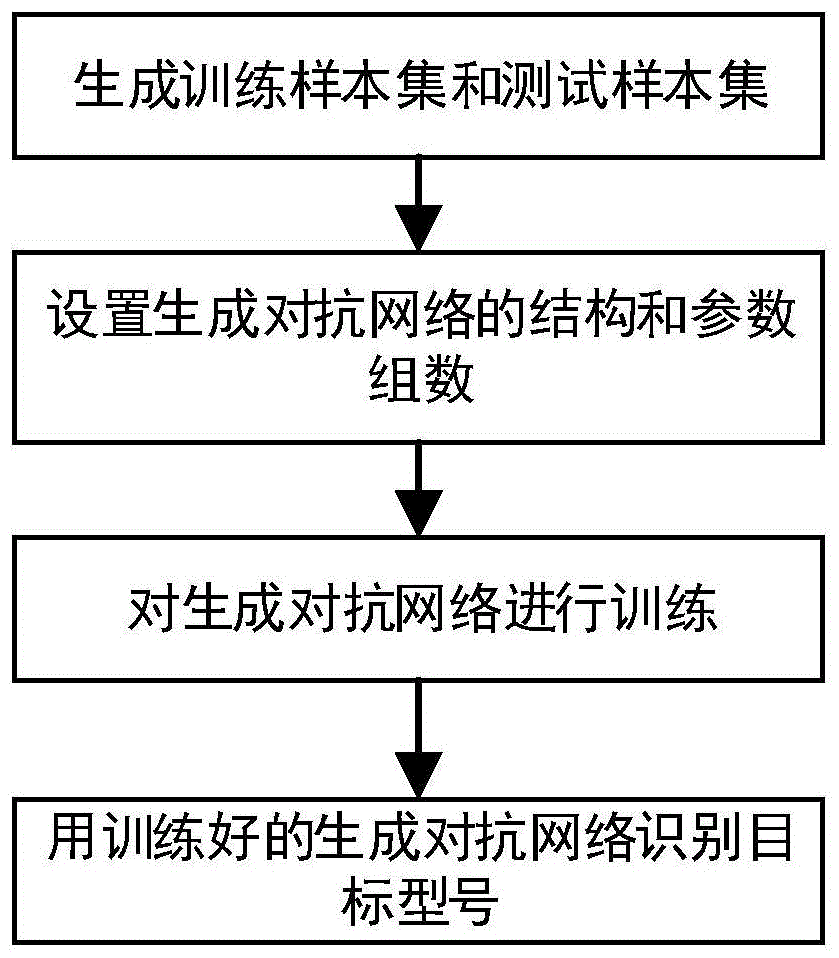
:合成孔径雷达sar具有全天候、全天时、分辨率高以及穿透力强等特点,成为目前对地观测和军事侦察的重要手段,合成孔径雷达sar图像自动目标识别受到越来越广泛的关注。目前,合成孔径雷达sar目标识别方法在训练分类器时大多只采用原始训练数据;在分类器设计上采用深度模型大多会求得局部最优解。电子科技大学在其申请的专利文献“一种sar图像识别方法”(专利申请号cn201210201460.1,公开号cn102737253a)中提出了一种基于稀疏表示的sar目标识别方法。该方法的实现方法是:利用稀疏表示理论将目标数据表示为训练样本的线性组合,通过求解最优化问题得到了具有可区分能力的近似非负稀疏系数,然后基于各类别系数和的大小确定样本的类别。该方法利用目标数据与训练样本的相似性程度来作为分类的依据,以体现目标数据的真实类别。该方法的不足之处是,只简单利用了原始训练数据来训练分类模型。西安电子科技大学在其申请的专利文献“基于cnn的sar目标识别方法”(专利申请号cn201510165886.x,申请公开号cn104732243a)中提出一种基于cnn的sar目标识别方法。该方法的实现步骤为:对每个训练图像进行多次随机平移变换,得到扩充数据扩充到训练样本集中;搭建卷积神经网络cnn结果;将扩充后的训练样本集输入到cnn中训练网络模型;对测试样本做多次平移变换得到扩充后的测试样本集;将测试样本集输入到训练好的cnn网络模型中测试,得到其识别率。该方法存在的不足之处是,深度学习方法不可避免的会陷入局部最优解当中,得到的训练后模型不能保证是最优解,不同的先验设置和初始化方式训练得到的结果并不稳定。技术实现要素:本发明的目的在于针对上述现有技术存在的不足,提出一种基于多参数优化生成对抗网络的sar目标识别方法,以稳定识别性能,提高识别率。本发明的技术思路是,通过利用生成模型,生成与训练样本集相似的样本图像,增加训练分类器时的可利用数据和信息;通过在训练生成对抗模型时,同时联合训练多组参数,利用多组参数所得的平均结果作为最终预测结果,避免模型陷入局部最优解的问题,提高的模型识别的稳定性和准确度,其实现方案包括如下:(1)生成训练样本集和测试样本集:(1a)在合成孔径雷达sar图像集的所有类别中,任意获取每类至少200个图像,组成初始训练样本集,用所有剩余样本,组成测试样本集;(1b)将初始训练样本集中的每张图像经过平移,旋转和翻转进行数据扩充,得到扩充训练样本集,由初始训练样本集和扩充训练样本集共同组成最终的训练样本集;(2)设置生成对抗网络的结构和参数组数:在tensorflow软件中分别设置生成对抗网络中的生成器和判别器层数及每一层的卷积核个数,并根据需要的精度设置网络参数的组数;(3)对生成对抗网络进行训练:(3a)固定判别器的参数,随机生成一组噪声向量,将该噪声向量输入到生成器中得到一组生成的伪样本,再将伪样本输入到判别器中,通过最小化生成器的目标函数更新生成器的参数;(3b)固定生成器的参数,随机生成一组噪声向量,将该噪声向量输入到生成器中得到一组生成的伪样本,再将伪样本和训练数据集共同输入到判别器中,通过最大化判别器的目标函数更新判别器的参数;(3c)判断生成器和判别器的目标函数是否收敛:若目标函数没有收敛,则返回第(3a)步;若目标函数收敛,则停止网络训练,得到训练好的生成对抗网络;(4)用训练好的生成对抗网络识别目标型号:(4a)将测试样本集中的所有样本,分别输入到训练好的每组参数所对应的判别器中,得到每个判别器的输出向量ym;(4b)对每个判别器的输出向量ym进行相加再取平均,该平均向量中值最大的一维所对应的型号类别即为测试样本的型号识别结果。本发明与现有的技术相比具有以下优点:第一,由于本发明在训练分类网络,即生成对抗网络中的判别器时,除了训练集样本外还利用到了生成器生成的伪样本,克服了现有技术中分类器训练时只利用到训练样本,导致识别率不高的问题,使得本发明的分类器训练利用到的信息更多,训练更充分,对图像的分类能力更强,提高了sar目标识别的正确率。第二,由于本发明采用了多组网络参数交叉训练的方法训练生成对抗网络,将多组参数得到的平均结果作为目标型号识别的最终结果,克服了现有技术中分类器不可避免的会陷入局部最优解当中,其训练后网络参数不能保证是最优解的问题,不仅具有对不同初始化方式的稳健性特点,而且提高了sar图像的目标识别率。附图说明图1是本发明的实现流程图;图2是本发明所用sar图像的示意图;图3是用本发明中的生成器生成的伪样本仿真图。具体实施方式下面结合附图对本发明作进一步的描述。参照图1,本实例的实现步骤如下。步骤1,生成训练样本集和测试样本集。在合成孔径雷达sar图像集的所有类别中,任意获取每类至少200个图像,组成初始训练样本集,用所有剩余样本,组成测试样本集;将初始训练样本集中的每张图片分别向上、向下、向左和向右移动30个像素点,得到4倍的平移扩充样本;将初始训练样本集中的每张图片分别按照顺时针45°,90°,135°,180°,225°,270°和315°进行图像旋转,得到7倍的旋转扩充样本;将初始训练样本集中的每张图片分别按照从左到右和从上到下进行图像翻转,得到2倍的翻转扩充样本;将初始训练样本集,平移扩充样本,旋转扩充样本和翻转扩充样本共同组成最终的训练样本集。步骤2,设置生成对抗网络的结构和参数组数。现有的生成对抗网络是由生成器和判别器两部分组成的深度网络模型。本实例在tensorflow软件中分别设置生成对抗网络中的生成器和判别器层数及每一层的卷积核个数,并根据需要的精度设置网络参数的组数,将生成器的网络参数设置为n组,将判别器的网络参数设置为m组;生成器网络的精度与n成正比,即n越大,生成器网络的精度越高,判别器网络的精度与m成正比,即m越大,判别器网络的精度越高,n>0,m>0。步骤3,对生成对抗网络进行训练。3.1)训练生成器的网络参数:固定判别器的参数,随机生成一组噪声向量,将该噪声向量输入到生成器中得到一组生成的伪样本,再将伪样本输入到判别器中,通过最小化生成器的目标函数更新生成器的参数;所述生成器的目标函数,表示如下:其中,g表示生成器网络,d表示判别器网络,z为噪声,pz(z)为z的先验分布,e(·)表示计算期望值,g(z)表示将噪声z输入生成器网络g后输出的伪样本,k为训练样本集的总类别数,k+1为伪样本对应的类别标号,p(y=k+1|g(z),d)表示判别器网络d在输入为g(z)时,输出向量的第k+1维的值;对n组生成器网络参数,其分别对应的生成器的目标函数如下:其中表示生成器网络的参数,gn表示由生成器网络参数分别构成的生成器网络,dm表示由m个判别器网络参数分别构成的判别器网络,n=1,2,...,n,m=1,2,...,m;3.2)训练判别器的网络参数:固定生成器的参数,随机生成一组噪声向量,将该噪声向量输入到生成器中得到一组生成的伪样本;再将伪样本和训练数据集共同输入到判别器中,通过最大化判别器的目标函数更新判别器的参数;所述判别器的目标函数,表示如下:其中,g表示生成器网络,d表示判别器网络,x表示真实样本,y=l表示真实样本的标签,l=1,2,...,k,k为训练样本的总类别数,pdata(x,y)表示样本与标签的联合分布,p(y=l|x,d)表示将真实样本x输入判别器网络后,判别器网络输出的第l维的值,z为噪声,pz(z)为z的先验分布,e(·)表示计算期望值,g(z)表示将噪声z输入生成器网络g后输出的伪样本,k+1为伪样本对应的类别标号,p(y=k+1|g(z),d)表示判别器网络d在输入为g(z)时,输出向量的第k+1维的值;对m组判别器网络参数,其分别对应的判别器的目标函数如下:其中,表示判别器网络的参数,gn表示由n个生成器网络参数分别构成的生成器网络,dm表示由判别器网络参数分别构成的判别器网络,n=1,2,...,n,m=1,2,...,m;3.3)判断生成器和判别器的目标函数是否收敛:若目标函数没有收敛,则返回3.1);若目标函数收敛,则停止网络训练,得到训练好的生成对抗网络。步骤4,用训练好的生成对抗网络识别目标型号。4.1)将测试样本集中的所有样本,分别输入到训练好的每组参数所对应的判别器中,得到每个判别器的输出向量ym;4.2)对每个判别器的输出向量ym进行相加再取平均,该平均向量中值最大的一维所对应的型号类别即为测试样本的型号识别结果,其表示如下:其中,ym表示第m个判别器的k维输出向量,每一维代表该判别器将测试样本分类为该型号类别的概率大小;为ym相加取平均后得到的平均向量,m=1,2,...,m,m为判别器参数组数,findmax(·)表示查找向量最大值对应第几维,表示向量最大值所在的维度,即测试样本的型号识别结果。下面结合仿真实验对本发明的效果做进一步的描述。1.仿真实验条件。本发明的仿真实验的硬件平台为:处理器intelxeoncpu,处理器主频为2.20ghz,内存为128gb,显卡为nvidiagtx1080ti,操作系统为ubuntu16.04lts,所使用软件为python2.7,tensorflow。使用的现有方法为:基于线性支持向量机分类器的目标识别方法svm、基于自编码器的目标识别方法ae、基于限制玻尔兹曼机的目标识别方法rbm。2.仿真实验内容。仿真实验1,采用本发明方法,用运动与静止目标的获取与识别mstar数据集的实测数据训练网络参数,用训练好的两组参数构成的生成器生成伪样本,结果如图3,其中:图3(a)是用第一组训练好的参数构成的生成器在输入一组噪声后生成的伪样本图像;图3(b)是用第二组训练好的参数构成的生成器在输入一组噪声后生成的伪样本图像。仿真实验2,采用本发明方法和三个现有方法对运动与静止目标的获取与识别mstar数据集中的实测数据进行目标型号识别,得到各种方法对测试样本的识别结果。为了评价仿真实验结果,利用下式,计算上述仿真实验中每种方法的测试样本识别率:其中,accuracy表示测试样本的识别率,t表示识别正确的测试样本个数,q表示测试样本的总个数。accuracy值越大,说明识别性能越好。上述仿真实验采用的三种方法的识别率,如表1所示。表1不同识别方法对应的mstar测试样本识别率对比表实验方法本发明方法svmaerbm识别率95.47%88.64%86.81%87.84%3.仿真结果分析。分析本仿真实验1的对比参考标准为图2所示的sar图像,其中:图2(a)是由是从mstar数据集中,随机选取的一幅bmp2装甲车实测数据图像;图2(b)是由是从mstar数据集中,随机选取的一幅btr70装甲车实测数据图像;图2(c)是由是从mstar数据集中,随机选取的一幅t72主战坦克实测数据图像。通过比较图3(a)与图2(a),图2(b)及图2(c),可以看出第一组训练好的参数构成的生成器在输入一组噪声后生成的伪样本图像与真实的mstar样本非常接近;通过比较图3(b)与图2(a),图2(b)及图2(c),可以看出第二组训练好的参数构成的生成器在输入一组噪声后生成的伪样本图像与真实的mstar样本非常接近。比较结果表明,将图3(a)与图3(b)所示伪样本加入到判别器的训练中,可以增加判别器所能利用到的有用信息。分析仿真实验2,由表1可以看出,本发明的识别率可以达到95.47%,相比于现有技术方法,具有最高的识别率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1