一种鉴别信息提取式噪声聚类的茶叶品种分类方法与流程
本发明涉及茶叶分类技术领域,尤其涉及一种鉴别信息提取式噪声聚类的茶叶品种分类方法。
背景技术:
茶是深受广大人民群众的饮品。饮茶已经成为人们的生活习惯,也是很具特色的茶文化活动。随着出口贸易市场的开放和国内流通的增多,快速准确的茶叶品种类别鉴别方法变得至关重要。传统的茶叶鉴别方法一般需要具备丰富经验的专业人士人工鉴别,是一种依赖于专家的主观判别方法,其效率一般比较低下,不适合大规模生产。随着科学技术的不断发展,近红外光谱技术得到快速发展,逐渐应用于食品和农产品检测中,其检测速度快,可靠性和效率都比较高。
近红外光谱技术是一种快速无损检测技术,国内外学者在应用近红外光谱技术检测茶叶方面做了一些研究。比如:用于检测茶叶中茶多酚含量,茶叶溯源地判别,茶叶品种鉴别等。不同品种的茶叶,其内部组分不尽相同,其差异性隐含在茶叶样本近红外光谱中,利用合适的分类方法可实现茶叶品种的准确分类。
广义噪声聚类是一种模糊聚类方法,它适用于处理含噪声数据的聚类分析,广义噪声聚类将噪声数据看做一个类别进行处理,但是广义噪声聚类在计算噪声距离时需要事先运行模糊c均值聚类方法以计算参数。但是,广义噪声聚类方法和一种快速广义噪声聚类方法在聚类过程中无法提取样本鉴别信息,进行线性空间变换,为解决此问题,本发明设计一种鉴别信息提取式噪声聚类方法以实现在对茶叶样本近红外光谱聚类过程中动态提取茶叶样本近红外光谱的鉴别信息。
技术实现要素:
基于背景技术存在的技术问题,本发明提出了一种鉴别信息提取式噪声聚类的茶叶品种分类方法;
本发明提出的一种鉴别信息提取式噪声聚类的茶叶品种分类方法,包括:
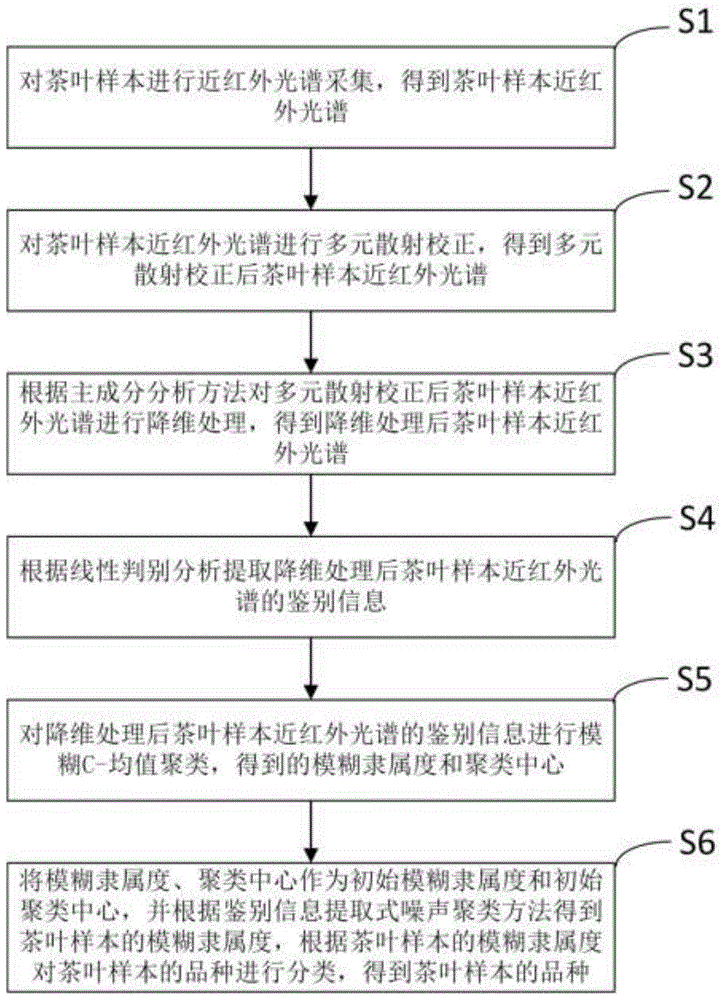
s1、对茶叶样本进行近红外光谱采集,得到茶叶样本近红外光谱;
s2、对茶叶样本近红外光谱进行多元散射校正,得到多元散射校正后茶叶样本近红外光谱;
s3、根据主成分分析方法对多元散射校正后茶叶样本近红外光谱进行降维处理,得到降维处理后茶叶样本近红外光谱;
s4、根据线性判别分析提取降维处理后茶叶样本近红外光谱的鉴别信息;
s5、对降维处理后茶叶样本近红外光谱进行模糊c-均值聚类,得到的模糊隶属度和聚类中心;
s6、将模糊隶属度、聚类中心作为初始模糊隶属度和初始聚类中心,并根据鉴别信息提取式噪声聚类方法得到茶叶样本的模糊隶属度,根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种。
优选地,步骤s6,具体包括:
s61、设置权重m,类别数c,茶叶训练样本数n,迭代次数初始值r和最大迭代次数rmax,迭代最大误差参数为ε;
s62、计算茶叶训练样本的协方差σ2:
s63、计算模糊类间散射矩sfb:
s64、计算模糊总体散射矩阵sft:
s65、计算特征向量
s66、将xk∈rq转化到特征空间:yk=xkt[ψ1,ψ2,...,ψp],其中,特征空间由ψ1,ψ2,...,ψp组成,yk∈rp,p、q为样本的维数,ψp为第p个特征向量;
s67、将
s68、计算参数
s69、在特征空间中计算模糊隶属度值:
s610、在特征空间中计算i类的类中心值:
s611、在
s612、根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种。
本发明通过对茶叶样本进行近红外光谱采集,对茶叶样本近红外光谱进行多元散射校正,对多元散射校正后茶叶样本近红外光谱进行降维处理,根据线性判别分析提取降维处理后茶叶样本近红外光谱的鉴别信息,对降维处理后茶叶样本近红外光谱进行模糊c-均值聚类,得到的模糊隶属度和聚类中心,将模糊隶属度、聚类中心作为初始模糊隶属度和初始聚类中心,并根据鉴别信息提取式噪声聚类方法得到茶叶样本的模糊隶属度,根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种,如此,在对茶叶样本近红外光谱进行聚类分析过程中采用模糊线性鉴别分析提取茶叶训练样本近红外光谱的鉴别信息,提高了的聚类准确率,其次,实现数据特征空间的转换,从而可以准确的对茶叶品种进行鉴别。
附图说明
图1为本发明提出的一种鉴别信息提取式噪声聚类的茶叶品种分类方法的流程示意图;
图2为本发明中茶叶样本近红外光谱;
图3为多元散射校正后茶叶样本近红外光谱;
图4为线性判别处理后的茶叶三维测试样本;
图5为模糊c均值聚类的模糊隶属度图;
图6为根据鉴别信息提取式噪声聚类方法得到的茶叶样本的模糊隶属度。
具体实施方式
参照图1至图6,本发明提出的一种鉴别信息提取式噪声聚类的茶叶品种分类方法,包括:
步骤s1,对茶叶样本进行近红外光谱采集,得到茶叶样本近红外光谱;
步骤s2,对茶叶样本近红外光谱进行多元散射校正,得到多元散射校正后茶叶样本近红外光谱;
步骤s3,根据主成分分析方法对多元散射校正后茶叶样本近红外光谱进行降维处理,得到降维处理后茶叶样本近红外光谱;
步骤s4,根据线性判别分析提取降维处理后茶叶样本近红外光谱的鉴别信息;
步骤s5,对降维处理后茶叶样本近红外光谱进行模糊c-均值聚类,得到的模糊隶属度和聚类中心;
步骤s6,将模糊隶属度、聚类中心作为初始模糊隶属度和初始聚类中心,并根据鉴别信息提取式噪声聚类方法得到茶叶样本的模糊隶属度,根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种。
本步骤s6具体包括:
s61、设置权重m,类别数c,茶叶训练样本数n,迭代次数初始值r和最大迭代次数rmax,迭代最大误差参数为ε;
s62、计算茶叶训练样本的协方差σ2:
s63、计算模糊类间散射矩sfb:
s64、计算模糊总体散射矩阵sft:
s65、计算特征向量
s66、将xk∈rq转化到特征空间:yk=xkt[ψ1,ψ2,...,ψp],其中,特征空间由ψ1,ψ2,...,ψp组成,yk∈rp,p、q为样本的维数,ψp为第p个特征向量;
s67、将
s68、计算参数
s69、在特征空间中计算模糊隶属度值:
s610、在特征空间中计算i类的类中心值:
s611、在
s612、根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种。
在具体实施例中:
茶叶样本近红外光谱的采集。
采集岳西翠兰、六安瓜片、施集毛峰、黄山毛峰四种安徽品牌茶叶,每种茶叶的样本数为65,合计260个样本,所有茶叶样本被研磨粉粹后经40目筛过滤;实验室温度和相对湿度保持相对不变,antarisii近红外光谱分析仪开机预热1个小时;采用反射积分球模式采集茶叶样本近红外光谱,近红外光谱分析仪扫描每个样品32次以获取样品的漫反射光谱均值;光谱扫描的波数为10000~4000cm-1,扫描间隔为3.857cm-1,采集到每个茶叶样品的光谱是1557维的数据;每个样本采样3次,取其平均值作为后续模型建立的实验数据。四种茶叶样本的近红外光谱如图2所示。
采用多元散射校正对茶叶样本近红外光谱进行处理,图2的茶叶红外光谱经过多元散射校正后的结果如图3所示。
采用主成分分析方法对茶叶样本近红外光谱的降维处理;
采用主成分分析方法对图3所示的茶叶近红外光谱进行降维处理,取前7个最大特征值(分别为:22.69,1.19,0.47,0.18,0.05,0.03,0.01)对应的7个特征向量,将260个茶叶样本的近红外光谱数据投影到这7个特征向量上,从而将近红外光谱从1557维压缩到7维。
根据线性判别分析提取降维处理后茶叶样本近红外光谱的鉴别信息;
将经过主成分分析方法处理后的茶叶样本近红外光谱数据分为两个部分:从每类茶叶样本中选取22个样本组成茶叶样本训练集,剩余43个样本组成茶叶样本测试集。用线性判别分析方法计算茶叶训练样本,可得前3个最大特征值(分别为:232.29,16.13,2.60)对应的3个特征向量,将茶叶样本测试集投影到这3个特征向量上得到如图4所示的三维数据;
设置模糊c-均值聚类的权重指数m=2.0,最大迭代数rmax=100,误差上限值ε=0.00001,对降维处理后茶叶样本进行模糊c-均值聚类,聚类终止后得到的模糊隶属度如图5所示,得到的聚类中心作为鉴别信息提取式噪声聚类方法的初始聚类中心v(0):
根据鉴别信息提取式噪声聚类方法得到茶叶样本的模糊隶属度,根据茶叶样本的模糊隶属度对茶叶样本的品种进行分类,得到茶叶样本的品种;:
(1)初始化:设置权重m=2.0,类别数c=4,测试样本数n=172;设置迭代次数初始值r=0和最大迭代次数rmax=100;设置迭代最大误差参数为ε=0.00001;
(2)计算测试样本的协方差:
(3)计算模糊类间散射矩阵sfb:
(4)计算模糊总体散射矩阵sft:
(5)计算特征向量:
(6)将xk∈rq转化到特征空间(由ψ1,ψ2,...,ψp组成):yk=xkt[ψ1,ψ2,...,ψp],
(yk∈rp),其中,p和q均为样本的维数,ψp为第p个特征向量。
(7)将
(8)计算参数
(9)在特征空间中计算模糊隶属度函数值:
(10)在特征空间中计算i类的类中心值
(11)增加迭代数r值,即r=r+1,直到
实验结果:迭代终止时r=10,模糊隶属度值如图6所示,根据图6的模糊隶属度值,若
迭代终止时聚类中心为:
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!