基于FHOG特征的络试卷分数自动统计方法和装置与流程
本发明涉及图像处理技术领域,具体为一种基于fhog特征的络试卷分数自动统计方法和装置。
背景技术:
专业认证是发达国家对高等教育进行专业评价的基本方式。某一专业通过专业认证,意味着其毕业生达到行业认可的质量标准。据悉,截至2017年底,教育部高等教育教学评估中心和中国工程教育专业认证协会共认证了全国198所高校的846个工科专业。通过专业认证,标志着这些专业的质量实现了国际实质等效,已进入全球工程教育的“第一方阵”。专业认证的三大理念包括:以学生为中心的教育理念;成果导向的教育取向;持续改进的质量文化。其中,持续改进的质量文化包括:建立常态性评价机制并不断改进;培养目标、毕业要求、教学环节都要进行评价;持续改进的效果通过学生的表现来体现。其中,教学环节的评价过程主要依据为开卷/闭卷考试,对试卷分数的精准统计结果能够有效的反映教学效果达成情况。因此,需要对试卷中每一题的得分情况进行统计,并给出最终的统计结果。采用手动的方式进行试卷分数统计,将增加额外的工作负担。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供一种基于fhog特征的络试卷分数自动统计方法,其应用空间金字塔的方式对分块cell的fhog特征进行处理,最终获得了试卷图像的整体特征和局部特征,特征描述性能得到进一步的增强,精度高,能够有效的进行试卷的分数统计。
本发明的目的之二在于提供一种基于fhog特征的络试卷分数自动统计装置,其应用空间金字塔的方式对分块cell的fhog特征进行处理,最终获得了试卷图像的整体特征和局部特征,特征描述性能得到进一步的增强,精度高,能够有效的进行试卷的分数统计。
为实现上述目的之一,本发明提供如下技术方案:
一种基于fhog特征的络试卷分数自动统计方法,包括以下步骤:
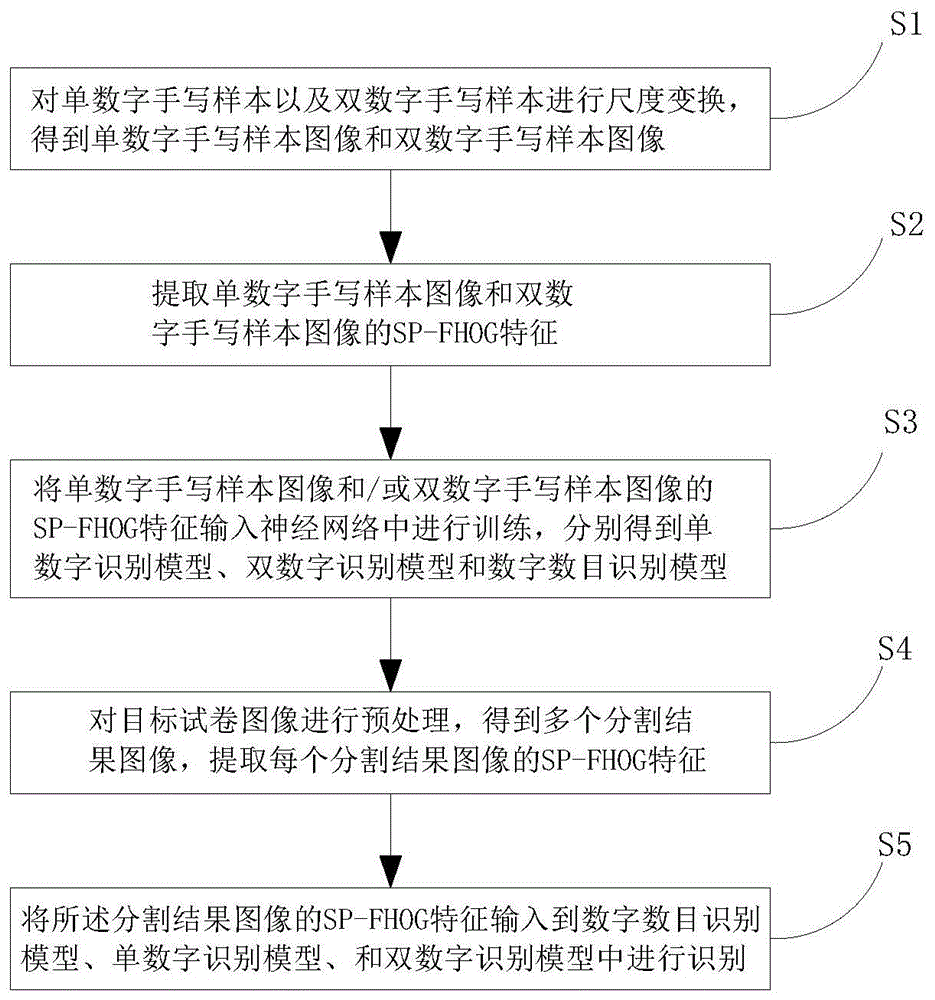
s1、对mnist样本数据库中的每个单数字手写样本以及nistsd19样本数据库中的每个双数字手写样本进行尺度变换,分别得到每个单数字手写样本对应的单数字手写样本图像和每个双数字手写样本对应的双数字手写样本图像;
s2、提取单数字手写样本图像和双数字手写样本图像的sp-fhog特征;
s3、将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征分别输入神经网络中进行训练,分别得到单数字识别模型和双数字识别模型,将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征同时输入神经网络中进行训练,得到数字数目识别模型;
s4、对目标试卷图像进行预处理,得到多个分割结果图像,提取每个分割结果图像的sp-fhog特征;
s5、将所述分割结果图像的sp-fhog特征输入到数字数目识别模型中进行识别,如果数字数目识别模型识别的结果为1,则将所述分割结果图像的sp-fhog特征输入至单数字识别模型进行识别,得到单数字识别结果;如果数字数目识别模型识别的结果为2,则将所述分割结果图像的sp-fhog特征输入至双数字识别模型进行识别,得到双数字识别结果;
其中,提取单数字手写样本图像或双数字手写样本图像或分割结果图像的sp-fhog特征的方法包括:
s11、对所述单数字手写样本图像或双数字手写样本图像或分割结果图像进行分割,得到3×3个cell,计算得到3×3个cell中每个cell的fhog特征,记为局部fhog特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括9个局部fhog特征;
s12、对所述3×3个cell,应用2×2大小步长为一个cell的重叠统计池化方法,将3×3个cell转换为2×2个cell,计算得到2×2个cell中每个cell的fhog特征,记为fhogr特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括4个fhogr特征;
s13、将所述2×2个cell作为一个整体,获得该整体的fhog特征,记为fhogall特征;
s14、将每个单数字手写样本图像或双数字手写样本图像或分割结果图像对应的9个局部fhog特征、4个fhogr特征以及1个fhogall特征进行串联,得到最终的sp-fhog特征。
优选地,所述神经网络采用dbn网络。
优选地,对mnist样本数据库中的每个单数字手写样本以及nistsd19样本数据库中的每个双数字手写样本进行尺度变换,包括:
对每个单数字手写样本的尺度进行变换,每个单数字手写样本尺度变换后得到的单数字手写样本图像均为6个,6个单数字手写样本图像的尺寸分别为16×16、32×32、48×48、64×64、80×80、96×96;
对每个双数字手写样本的尺度进行变换,每个双数字手写样本尺度变换后得到的双数字手写样本图像均为6个,6个双数字手写样本图像的尺寸分别为16×16、32×32、48×48、64×64、80×80、96×96。
优选地,对目标试卷图像进行预处理,得到多个分割结果图像,包括以下步骤:
s41、创建对比度求解所用的试卷样本,从所述试卷样本中选择前景目标区域和背景区域,得到前景目标区域图像和背景区域图像;
s42、将所述前景目标区域图像和背景区域图像从rgb空间转换为hsv空间,分别计算转换后的前景目标区域图像的色度空间直方图fhist和背景区域图像的色度背景区域直方图bhist,色度空间直方图fhist和色度背景区域直方图bhist均为为1*dims维的向量形式,dims为直方图的维度;
s43、计算基于色度的前景目标图像和背景图像的第i维的区分度l(i),i∈{0,2...dims-1};
其中,fhist(i)为第i维的色度空间直方图fhist的值,bhist(i)为第i维的色度背景区域直方图bhist的值,δ为非零极小值;
s44、将目标试卷图像由rgb空间转换成hsv空间,得到目标试卷图像对应的h通道图像,将所述h通道图像的像素值由0~1规范化到0~(dims-1)的范围内;
s45、将规划化后的h通道图像进行投影处理,得到投影图像,投影方式为:
f(i)=l(i)
其中,f(i)为像素值为i的h通道图像的像素点投影后的像素值;
s46、采用k均值算法对所述投影图像进行分割,得到分割结果图像。
优选地,在步骤s14之前还包括:
对每个单数字手写样本图像或双数字手写样本图像或分割结果图像对应的fhogall特征进行校准,校准的方法为:
对每个单数字手写样本图像或双数字手写样本图像或分割结果图像的sp-fhog特征中的方向敏感特征均进行循环左移或右移,以保证主元在方向敏感特征的起始位置。
为实现上述目的之二,本发明提供如下技术方案:
一种基于fhog特征的络试卷分数自动统计装置,其包括:
变换模块,用于对mnist样本数据库中的每个单数字手写样本以及nistsd19样本数据库中的每个双数字手写样本进行尺度变换,分别得到每个单数字手写样本对应的单数字手写样本图像和每个双数字手写样本对应的双数字手写样本图像;
第一获取模块,用于提取单数字手写样本图像和双数字手写样本图像的sp-fhog特征;
训练模块,用于将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征分别输入神经网络中进行训练,分别得到单数字识别模型和双数字识别模型,将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征同时输入神经网络中进行训练,得到数字数目识别模型;
第二获取模块,用于对目标试卷图像进行预处理,得到多个分割结果图像,提取每个分割结果图像的sp-fhog特征;
识别模块,用于将所述分割结果图像的sp-fhog特征输入到数字数目识别模型中进行识别,如果数字数目识别模型识别的结果为1,则将所述分割结果图像的sp-fhog特征输入至单数字识别模型进行识别,得到单数字识别结果;如果数字数目识别模型识别的结果为2,则将所述分割结果图像的sp-fhog特征输入至双数字识别模型进行识别,得到双数字识别结果;
其中,提取单数字手写样本图像或双数字手写样本图像或分割结果图像的sp-fhog特征的方法包括:
第一计算单元,用于对所述单数字手写样本图像或双数字手写样本图像或分割结果图像进行分割,得到3×3个cell,计算得到3×3个cell中每个cell的fhog特征,记为局部fhog特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括9个局部fhog特征;
第二计算单元,用于对所述3×3个cell,应用2×2大小步长为一个cell的重叠统计池化方法,将3×3个cell转换为2×2个cell,计算得到2×2个cell中每个cell的fhog特征,记为fhogr特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括4个fhogr特征;
第三计算单元,用于将所述2×2个cell作为一个整体,获得该整体的fhog特征,记为fhogall特征;
串联单元,用于将每个单数字手写样本图像或双数字手写样本图像或分割结果图像对应的9个局部fhog特征、4个fhogr特征以及1个fhogall特征进行串联,得到最终的sp-fhog特征。
与现有技术相比,本发明基于fhog特征的络试卷分数自动统计方法和装置,其有益效果在于:
1、应用空间金字塔的方式对分块cell的fhog特征进行处理,最终获得了试卷图像的整体特征和局部特征,特征描述性能得到进一步的增强,提高了识别效果,提高精度高,能够有效的进行试卷的分数统计;
2、在fhog特征的基础上,对fhog特征进行了主方向校准,校准后的fhog特征具有更强的旋转鲁棒性;
3、基于前景和背景区分度的分数区域确定,能够有效的定位试卷中分数区域;
4、对不同尺度手写数字的识别方法,其通过对数字区域提取sp-fhog特征,将不同尺度的手写数字图像归一化为固定的尺度,具有较强的识别鲁棒性。
附图说明
图1为本发明实施例一基于fhog特征的络试卷分数自动统计方法的流程图;
图2为单数字手写样本和双数字手写样本不同尺度对应的样本实例图像;
图3为提取sp-fhog特征的示意图;
图4为计算cell的fhog特征的示意图;
图5为sp-fhog特征的校准示意图;
图6为dbn网络结构示意图;
图7为前景背景区域选择图像示意图;
图8为前景报警图像色度直方图即对比度示意图;
图9为基于对比度的图像投影结果示意图;
图10为k均值分类定位结果示意图;
图11为本发明实施例二基于fhog特征的络试卷分数自动统计装置的结构示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
实施例一
本发明实施例一提出了一种基于fhog(fusedhistogramorientedgradient)特征的dbn(deepbeliefnets)网络试卷分数自动统计方法。2012年提出的lenet-5模型能够比较准确的识别出手写数字,但是该模型识别手写数字图像要求尺度固定(28*28)。该模型对数字旋转鲁棒性不强。对具有较大旋转角度的手写数字样本,识别率有一定的降低。在试卷分数的统计中,手写数字尺度不确定,旋转角度不确定。因此,本发明采用了具有与尺度无关的,对数字旋转具有更强鲁棒性的fhog特征替代原始的灰度图像信息。该方法首先在试卷原始图像中应用前景背景区分度函数进行分数区域确定。然后,在确定的分数区域中应用最邻近算法对区域进行分割,对分割的结果图像进行fhog特征提取,将提取到的特征结果输入训练好的dbn网络进行识别,输出最终的识别结果,依据定位的区域编号顺序存储识别结果;最终将识别结果按顺序进行相关的统计。
具体地,请参照图1所示,其包括以下步骤:
s1、对mnist样本数据库中的每个单数字手写样本以及nistsd19样本数据库中的每个双数字手写样本进行尺度变换,分别得到每个单数字手写样本对应的单数字手写样本图像和每个双数字手写样本对应的双数字手写样本图像。
对mnist样本数据库中的每个单数字手写样本进行随机尺度扩展,每个单数字手写样本的尺度进行变换,变换为6个尺度等级,即每个单数字手写样本均对应6个单数字手写样本图像,每个单数字手写样本均对应6个单数字手写样本图像的尺寸分别为16×16、32×32、48×48、64×64、80×80、96×96(均为像素点数)。原始的样本数数据库mnist中数字图像的尺寸为28×28,而nistsd19样本数据库中的每个双数字手写样本的尺度大小需要自行处理,在这里,也将nistsd19样本数据库中的每个双数字手写样本变换成6个双数字手写样本图像,每个双数字手写样本对应的6个双数字手写样本图像的尺寸而言分别为16×16、32×32、48×48、64×64、80×80、96×96。图2中给出了单数字手写样本和双数字手写样本不同尺度对应的样本实例图像。
s2、提取单数字手写样本图像和双数字手写样本图像的sp-fhog特征。
为了增强数字fhog特征对旋转的鲁棒性,本发发明提出了空间金字塔结构的手写数字的fhog特征——sp-fhog(spatialpyramidfusedhistogramorientedgradient)。
提取单数字手写样本图像或双数字手写样本图像的sp-fhog特征的方法请参照图3所示,包括以下步骤:
a、对所述单数字手写样本图像或双数字手写样本图像进行分割,得到3×3个cell,计算得到3×3个cell中每个cell的fhog特征,记为局部fhog特征;每个单数字手写样本图像或双数字手写样本图像共包括9个局部fhog特征,记为fhog1~fhog9。
计算每个cell的fhog特征的方法为现有常规技术,这里仅对其进行简单说明。
请参照图4所示,针对每个cell中的像素点,计算每个像素点的梯度和方向。(如果像素点位于分割区域的边界位置时采用线性插值的方式解决)。梯度的大小和方向分别表示为:r(x,y),θ(x,y)。将每个像素点的梯度方向进行离散化,可以将像素点的梯度方向离散化为对方向敏感的b1(0~360度)的p1个值中的一个(实际选择p1=18),对方向不敏感的b2(0~180度)的p2个值中间的一个(实际选择p2=9),具体的计算过程如式1,式2所示。当选择对方向敏感的p1=18时,也即是将0~360度分成了18个区间,也即是将每个像素的梯度方向规范化到0-17的18个离散的区间中,对于某一个像素点其b1值为0~17中间的某一个对应的数值位为1,b2的值为0~7之间某一位对应的值为1。对于p2=9则是将梯度方向规范化到0~7的8个离散的区间中。
定义了一个像素级的特征映射,指定每个像素梯度幅值的稀疏直方图。在像素点(x,y)处对方向敏感的稀疏直方图和对方向不敏感的稀疏直方图的计算如式3和式4所示。其中,fb1为1*18的向量,此向量中像素点(x,y)的特征即为与b1对应的位置值为r(x,y)的1*18的向量,该向量中只有b1对应的位置为非零,其他17个位置的值均为零。同理可以得到像素点(x,y)的方向不敏感特征fb2。
求得每个像素点的方向敏感特征fb1和方向不敏感特征fb2以后,对原始图像划分的3×3个的cell共9个区域进行特征求解。9个区域可以认为是将原始图像分成了9个cell,定义9个cell中每个cell的特征为该cell中所有像素的fb1和fb2的均值。为了增强梯度对偏执的改变具有不变性,对每个cell中的特征进行归一化,归一化的因子选择为:nδ,γ(i,j)。对于3×3共9个cell的归一化因子,i,j∈{1,2,3},δ,γ∈{1,-1}。归一化因子的计算如式5所示。每个因子都包含四个cell的能量。针对如公式5所计算的,可以产生4个归一化的因子,因子cell中的特征由于应用了4个归一化的因子,因此可以产生4个归一化的特征,所以每个cell对应的fhog特征有18维方向敏感特征、9维方向不敏感特征和4个归一化的因子共计31维向量。为了提高每个cell对目标特征描述的旋转鲁棒性,对整个图像的3×3共9个cell的方向敏感的18维特征进行循环移位,确保整个图像的方向梯度0方向为幅值最大的方向。具体的方向旋转示意图如图5所示。如图5所示,其中18维的方向敏感特征为整副图像的方向敏感特征。原始坐标系下的方向最大值的方向在离散方向梯度直方图的第二维度上,也即主方向不在x轴上,因此,对坐标轴进行旋转,确保最大值的方向在x轴的正半轴上,如图5所示。坐标轴的旋转反应在特征的向量上为18维特征的循环移位。如果坐标沿顺时针旋转,那么特征向量向右循环移位,移动的位数与旋转的角度有关。如果坐标轴沿逆时针的方向旋转,则特征向量向左循环移位,如图5所示。方向不敏感的9维特征的循环移位的方向和位数与方向敏感特征的循环移位方向和移动的位数相同。经过坐标平移标准化后的特征对原始图像特征的提取具有旋转鲁棒性。在原始图像的3×3共9个cell中的方向敏感和方向不敏感的归一化特征应用相同的方法进行循环平移。平移和归一化后的特征tα(v)表示向量v被α截断之后形成的向量(把向量v中大于α的值都设置为α)。截断结果特征如式6所示。将归一化并循环平移的方向敏感特征和方向敏感特征进行串联,最终求出该cell的fhog特征。
b、对所述3×3个cell,应用2×2大小步长为一个cell的重叠统计池化方法,将3×3个cell转换为2×2个cell,计算提取2×2个cell中每个cell的fhog特征(计算方法详见a步骤),记为fhogr特征;每个单数字手写样本图像或双数字手写样本图像共包括4个fhogr特征,记为fhogr1~fhogr4,每个fhogr特征均为1×31维的向量;
c、将所述2×2个cell进行归一化,即将2×2个cell作为一个整体,获得该整体的fhog特征(计算方法详见a步骤),记为fhogall特征,每个fhogall特征均为1×31维的向量;
d、将每个单数字手写样本图像或双数字手写样本图像对应的fhog1~fhog9、fhogr1~fhogr4以及1个fhogall特征进行串联(所谓的串联,即是将这些特征放置在一起组成一个向量),得到最终的sp-fhog特征,有此可知,每个单数字手写样本图像或双数字手写样本图像对应的sp-fhog特征为14×31维的向量。本发明提取的sp-fhog特征原始图像(单数字手写样本图像或双数字手写样本图像)的尺度无关,无论原始图像的尺度大小,最终提取的特征都为14×31维,使得特征的提取具有尺度的鲁棒性。
在sp-fhog求解过程中发现,该特征对原始图像(单数字手写样本图像或双数字手写样本图像)的旋转具备较弱的鲁棒性,因此,本发明提出了一种对sp-fhog进行校准的方法。该方法在提取的目标的sp-fhog特征的fhogall特征中方向敏感特征中寻找主元的方向,具体是:对fhogall中方向敏感特征进行循环左移或循环右移,确保主元在方向敏感特征的起始位置,移动时,fhogall中方向敏感特征进行循环左移或循环右移,同时,fhogall对应的fhog1~fhog9、fhogr1~fhogr4中方向敏感特征进也都需要按照fhogall的移动结果进行移动,即所有的单数字手写样本图像或双数字手写样本图像(目标试卷图像的sp-fhog特征提取,亦是如此操作)的sp-fhog特征中方向敏感特征均进行循环左移或循环右移,从而保证sp-fhog特征的旋转不变性,确保最终的sp-fhog特征具有旋转不变性。假设方向敏感特征需要循环移动的步数为s步,方向不敏感特征需要沿相同的方向移动
s3、将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征分别输入神经网络中进行训练,分别得到单数字识别模型和双数字识别模型,将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征同时输入神经网络中进行训练,得到数字数目识别模型。
这里的神经网络采用dnb网络模型,dnb网络模型的结构图如图6所示。将单数字手写样本图像的sp-fhog特征输入dnb网络模型中进行训练,得到单数字识别模型db1,将双数字手写样本图像的sp-fhog特征输入dnb网络模型中进行训练,得到双数字识别模型db2,将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征同时输入dnb网络模型中进行训练,得到数字数目识别模型db3。dbn1模型中的输入参数为[14×31,400,200,100,10],表示rbm1中的显层输入为14×31维,隐层为400维,rbm2隐层和显层分别为400和200,rbm3的显层和隐层参数为200和100,nn网络层的输入和输出为100和10。由于dbn2为识别双数字的,因此nn网络的输出结果应为90×1,即是表示10~99的90行一列的矩阵。dbn2的模型参数可以表示为[14×31,400,200,100,9]。dbn3为识别图像中数字个数的网络,因此dbn中的nn网络层的输出应为3×1矩阵,dbn3的模型参数可以表示为[14×31,400,200,100,3]。3×1的矩阵表示单数字、双数字、不是数字三种情况。所有dbn模型的输出层矩阵中的元素只能用0和1表示。1所在的位置表示对应的数值。
s4、对目标试卷图像进行预处理,得到多个分割结果图像,提取每个分割结果图像的sp-fhog特征。
为了实现试卷分数的笔迹颜色与背景颜色对比度的求解,首先创建对比度求解所用的试卷样本。试卷样本如图7所示。在图7中选择“前景f”区域作为计算区分度的前景目标区域;选择“背景b”作为背景区域。分别原始的前景区域图像和背景区域图像从rgb空间转换为hsv空间中。分别计算前景区域图像的色度空间直方图fhist和背景图像区域的色度背景区域直方图bhist,fhist和bhist均为1*dims维的向量形式。dims为直方图的维度。获得前景和背景的直方图后,通过公式7计算基于色度的前景图像和背景图像的区分度l(i),i∈{0,2...dims-1}。其中,为了避免求解过程中出现求解0的对数,δ选择为非零的极小值。前景图像区域的色度直方图和背景图像的色度直方图以及对比度的计算结果如图8所示。图8中的dims=128。由图8可以看出,部分像素值对应的区域的对比度为负值,部分区域的对比度为正值。
将目标试卷图像同样由rgb空间转换到hsv空间,提取h通道图像。将h通道图像中的像素值由0~1规范化到0~dims-1范围。将h通道图像进行投影处理,如果h通道图像中对应的像素值为i,i∈{0~dims-1},则该位置对应的像素值用f(i)的值进行替换,f(i)的计算如公式8所示。为了消除投影结果图像中的噪声点,首先对图像进行阈值处理,然后对投影图像进行腐蚀膨胀处理。原始图像经过色度的反向投影图像,处理的结果图像如图9所示。图9中输出的结果即为最终的分数数字区域处理结果。
f(i)=l(i),i∈{0~dims-1}(8)
确定数字区域中数字数目;
应用k均值算法对定位的数字区域进行分割,在目标试卷图像的数目已知的条件下,k均值变为已知,如图10所示。图10中已知试题数目为4题,加上总分,因此在k均值进行像素分类的过程中k=5。分类的结果如图10所示。
对分割结果图像进行sp-fhog特征提取的方法与单数字手写样本图像或双数字手写样本图像的sp-fhog特征的方法类似,这里不再赘述。
s5、将所述分割结果图像的sp-fhog特征输入到数字数目识别模型中进行识别,如果数字数目识别模型识别的结果为1,则将所述分割结果图像的sp-fhog特征输入至单数字识别模型进行识别,得到单数字识别结果;如果数字数目识别模型识别的结果为2,则将所述分割结果图像的sp-fhog特征输入至双数字识别模型进行识别,得到双数字识别结果。
将提取到的sp-fhog特征输入数字数目识别网络dbn3,识别出该结果图像区域中的数字数目,依据识别出的数字数目输入对应的数字识别网络,如果识别出的数字数目为1,则将该图像的sp-fhog特征输入dbn1网络进行识别,并记录识别的结果。如果dbn3识别的结果为2,则将该图像的sp-fhog特征输入dbn2网络进行识别,并记录识别的结果。如果dbn3给出的识别结果中判定该区域中不存在数字,则应用k均值算法对定位的数字区域进行重新的分割,重新识别,如果dbn3仍然不能识别,则认为该区域中不存在手写的单数和双数字。直至最终识别出所有的数字区域中的数字,然后根据在k均值中图像区域数字的顺序,在多个目标试卷图像的基础上,对识别结果数字进行统计。依据数字的统计结果,对每一题分数求解其均值和方差、最大值、最小值以及分数的分布规律,以及该多个目标试卷图像总分数的均值和方差、最大值、最小值以及分数的分布规律,为最终的教学调整提供有效的参考。
实施例二
请参照图11所示,一种基于fhog特征的络试卷分数自动统计装置,为实施例一的虚拟装置,其包括:
变换模块10,用于对mnist样本数据库中的每个单数字手写样本以及nistsd19样本数据库中的每个双数字手写样本进行尺度变换,分别得到每个单数字手写样本对应的单数字手写样本图像和每个双数字手写样本对应的双数字手写样本图像;
第一获取模块20,用于提取单数字手写样本图像和双数字手写样本图像的sp-fhog特征;
训练模块30,用于将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征分别输入神经网络中进行训练,分别得到单数字识别模型和双数字识别模型,将单数字手写样本图像的sp-fhog特征和双数字手写样本图像的sp-fhog特征同时输入神经网络中进行训练,得到数字数目识别模型;
第二获取模块40,用于对目标试卷图像进行预处理,得到多个分割结果图像,提取每个分割结果图像的sp-fhog特征;
识别模块50,用于将所述分割结果图像的sp-fhog特征输入到数字数目识别模型中进行识别,如果数字数目识别模型识别的结果为1,则将所述分割结果图像的sp-fhog特征输入至单数字识别模型进行识别,得到单数字识别结果;如果数字数目识别模型识别的结果为2,则将所述分割结果图像的sp-fhog特征输入至双数字识别模型进行识别,得到双数字识别结果;
其中,提取单数字手写样本图像或双数字手写样本图像或分割结果图像的sp-fhog特征的方法包括:
第一计算单元,用于对所述单数字手写样本图像或双数字手写样本图像或分割结果图像进行分割,得到3×3个cell,计算得到3×3个cell中每个cell的fhog特征,记为局部fhog特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括9个局部fhog特征;
第二计算单元,用于对所述3×3个cell,应用2×2大小步长为一个cell的重叠统计池化方法,将3×3个cell转换为2×2个cell,计算得到2×2个cell中每个cell的fhog特征,记为fhogr特征;每个单数字手写样本图像或双数字手写样本图像或分割结果图像共包括4个fhogr特征;
第三计算单元,用于将所述2×2个cell作为一个整体,获得该整体的fhog特征,记为fhogall特征;
串联单元,用于将每个单数字手写样本图像或双数字手写样本图像或分割结果图像对应的9个局部fhog特征、4个fhogr特征以及1个fhogall特征进行串联,得到最终的sp-fhog特征。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!