归一化相关图像模板匹配多核并行高效实现方法和装置与流程
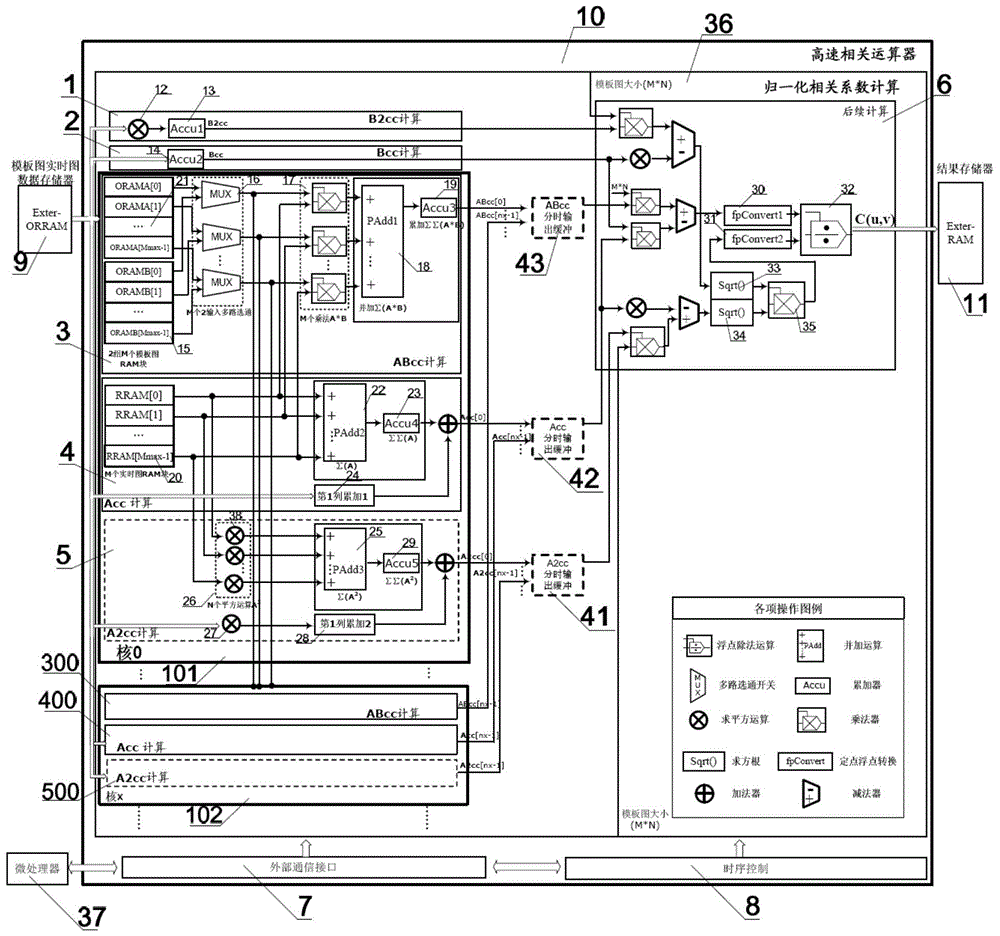
本发明涉及归一化相关图像模板匹配多核并行高效实现方法和装置,特别是涉及一种能够多核并行计算出归一化相关系数的高精度、高实时性图像模板匹配方法。可用于根据一个已知的模板图在一幅动态实时图像中定位目标,在自动目标识别、基于双目立体视觉的测量、医疗图像融合、卫星图像监控等领域具有广泛用途。
背景技术:
模板匹配主要用来定位图像中的一个目标,它已经广泛应用于图像配准、双目立体视觉等图像处理领域,并且这些图像处理手段已经在如自动目标识别、基于双目立体视觉的测量、医疗图像融合、卫星图像监控等军用民用领域中得到广泛应用。
模板匹配通过计算已知表征目标的模板图与实时图中搜索区域内所有位置的相似性测度来进行目标定位,该目标同模板图有类似的尺寸和图像。由于归一化相关系数对亮度和对比度变化具有不变性,因此它是模板匹配中广泛应用的一种测度。假定实时图和模板图分别由a、b表示,其尺寸分别为k×l和m×n个像素。在任一搜索位置(u,v),0≤u≤k-m,0≤v≤l-n,归一化相关系数(ncc-normalizedcross-correlation)定义为:
此处,∑∑表示
为了获得精确定位,模板匹配需要在实时图中搜索与模板图相重合的每一个区域,因此对于一个通常的应用,需要搜索的位置数目往往非常多。因此对于像自动目标识别、跟踪等实时应用领域,基于归一化相关系数的模板匹配计算量相对还是太大从而导致其应用受到很大限制。
已经提出许多技术来加速模板匹配计算,由于这些技术不需要对所有位置进行匹配,因此大幅度的降低了计算量,但是这些技术通常由于局部的极值点干扰导致错误的匹配。实际上,由于模板匹配计算是针对图像各个像素进行相关运算,因此该算法本身能够通过并行的方法来加速。此外已经提出了一些多处理器并行计算方法来加速模板匹配的计算。但是对于很多小型化、微功耗需求的嵌入式应用,多处理器并行计算方法仍无法满足实际应用的要求。
近年来,随着电子技术和制造工艺的快速发展,现场可编程门阵列(fpga)的容量越来越大、速度越来越快,这使得fpga具有了一般微处理器所无法比拟的强大的并行性,因此fpga同样特别适用于实现模板匹配计算。
申请号为200910069272.6和201310208097.0的专利给出了一种实现高速图像匹配方法及装置,这两个专利主要基于早期资源较少的fpga,其实时性较差。现在的fpga的芯片制程采用了更先进的工艺,同时具有更多的内部逻辑资源。为了能够充分的利用这些内部资源,采用多核实现是一个有效的策略,如何采用多核并行的方式高效实现归一化相关图像模板匹配是本专利要解决的主要问题。
技术实现要素:
本发明是为了解决上述现有技术存在的问题而提供归一化相关图像模板匹配多核并行高效实现方法和装置,该方法可由超大规模集成电路(vlsi)或现场可编程门阵列(fpga)通过多核并行的方式高速高精度的计算归一化相关系数,可进一步提高归一化相关计算速度、提高实时性、降低总功耗;同时,采用该方法的设备能够实现精度高、参数设置灵活、实时性强的高速图像模板匹配。
本发明采用如下技术方案:一种归一化相关图像模板匹配多核并行高效实现方法,所述方法包括有如下步骤:
(1)根据核的数目q,设定每个核处理的实时图的数据块行间距为d=ceil((k-m+1)/q),其中ceil()为向上取整运算,k、m分别为实时图和模板图的行数;
(2)从外部存储器中读取每一行模板图数据分别存储到a组对应的每一个内部ram缓冲块中,同时进行模板图灰度值总和
(3)选通第a组模板图内部ram缓冲块,所有核同时计算第u行(对于核x,u从0开始,针对每个核对应块的行数)第0列(v=0)模板图实时图灰度值乘积总和
(4)每一个核x采用一加一减两步操作同步计算搜索位置第u行第1列(v=1)的实时图灰度值总和
(5)由步骤3和4相同的方式,所有核同步依次计算出模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,并且同步存储到相应的分时输出缓冲中,在下一列计算模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和的同时,按核的顺序依次从分时输出缓冲中同时输出各个核的模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,同时计算当前行后续各列v归一化相关系数直到每一个核所有列计算完成;
(6)与步骤3到步骤5同时进行模板图数据重排,即按所有同步进行运算的核下一行(u+1)搜索时其实时图数据内部ram缓冲块的计算行顺序从外部存储器中读取模板图数据并存储到对应的b组模板图内部ram缓冲块中;
(7)在步骤3到步骤6中所有核同步进行的相关计算及同时进行的模板图数据重排都完成后,按核的顺序依次读入每一个核x下一行(u+1)实时图数据存储到每一个核x数据已经无效的内部实时图ram缓冲块,同时计算每一个核x当前行u+1第0列(v=0)的实时图灰度值总和
(8)对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出相应数据块后续各行各列归一化相关系数。
进一步地,所述的模板匹配方法用的是归一化相关系数,公式如下:
a、b分别表示实时图和模板图,其尺寸分别为k(行数)×l(列数)、m(行数)×n(列数)个像素,(u0,v)为任一搜索位置,0≤u0≤k-m,0≤v≤l-n。∑∑表示
进一步地,步骤1的根据核的数目q,设定每个核处理的实时图的数据块行间距为d=ceil((k-m+1)/q),相当于将实时图搜索区域分成了q-1个搜索行数大小为d的块和一个搜索行数大小为(k-m+1)-d*(q-1)的块,其中ceil(x)为向上取整运算,即取当前值趋向于正无穷的正整数,根据核的数目q,由外部处理器设定每个核处理的实时图的数据块行间距,然后由外部处理器作为参数输入到相关计算处理单元。
进一步地,步骤2中的从外部存储器中读入模板图数据到a组内部ram缓冲块,是将每一行n列的灰度值存储到一个ram块中,共存入m行,即采用了m个ram块,每个ram块包含n个存储单元;模板图对应的内部ram缓冲块分为两组:a组和b组;依次读入每个核实时图数据到对应的内部ram缓冲块,是将每一行l列的灰度值存储到一个ram块中,每个核共存入m行,同样每个核采用了m个ram块,每个ram块包含l个存储单元;
所述步骤2中的模板图灰度值总和
所述步骤2中的模板图灰度值平方总和
所述步骤2中在读取时同时进行的每一个核x对应的第(x-1)*d行第0列搜索位置(u=0,v=0)处的实时图灰度值总和
所述步骤2中的在读取时同时进行的每一个核x对应的第(x-1)*d行第0列搜索位置(u=0,v=0)处的实时图灰度值平方总和
所述步骤2、4、5、7、3中的实时图灰度值总和、实时图灰度值平方总和、模板图实时图灰度值乘积总和分时输出缓冲为所有并行核按核的顺序分时共用后续计算模块而设,即如步骤5所述,在下一列计算模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和的同时,按核的顺序依次从分时输出缓冲中同时输出各个核的模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,同时依次计算所有核当前行后续各列v的归一化相关系数。
所述步骤2、4、5、7、3中的实时图灰度值总和分时输出缓冲,由q个分别对应每个核的实时图灰度值总和的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的实时图灰度值总和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续计算模块的实时图灰度值总和输入端。
所述步骤2、4、5、7、3中的实时图灰度值平方总和分时输出缓冲,由q个分别对应每个核的实时图灰度值平方总和的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的实时图灰度值平方总和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到计算处理模块的实时图灰度值平方总和输入端。
所述步骤2、4、5、7、3中的模板图实时图灰度值乘积总和分时输出缓冲,由q个分别对应每个核的模板图实时图灰度值乘积总和的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的模板图实时图灰度值乘积总和和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续计算模块的模板图实时图灰度值乘积总和输入端。
进一步地,步骤3和步骤5中的每一个核x模板图与实时图当前搜索位置的灰度值乘积总和
进一步地,步骤4和步骤5中每一个核x第u行第1列开始后续各列v每一个实时图灰度值总和
步骤4和步骤5中每一个核x第u行第1列开始后续各列v每一个实时图灰度值平方总和
进一步地,步骤5的搜索位置当前行归一化相关系数的计算,是模板图像第0到m-1行与每个核x实时图第(x-1)*d到(x-1)*d+m-1行数据对应计算,搜索位置第0列归一化相关系数的计算为模板图像第0到n-1列与每个核x实时图第0到n-1列数据对应计算,搜索位置第1列归一化相关系数的计算为模板图像第0到n-1列与每个核x实时图像第1到n列数据对应计算,计算每一个核x的
步骤5计算归一化相关系数是在每一个核x的
进一步地,步骤6按所有同步进行运算的核下一行搜索位置处实时图数据块的计算行顺序从模板图外部存储器中读取数据分别到对应的b组模板图内部缓冲块中,是指所有同步进行运算的核下一行搜索前按核的顺序从实时图外部存储器中依次读入每一个核x下一行新的实时图数据分别覆盖每个核不用的实时图ram块数据,导致当前组的模板图ram缓冲块与每个核的实时图ram缓冲块输出顺序不再对应,通过在当前行计算同时预先重新从模板图外部存储器中按所有同步进行运算的核下一行搜索计算时实时图数据块的行顺序读取数据分别到对应的另一组模板图内部缓冲块中,下一行相关系数计算时通过2选1多路选择器选通该组模板图内部缓冲ram块使其与之对应,该步骤与步骤3到步骤5同时进行。
进一步地,步骤7按核的顺序从外部存储器依次读入每一个核x下一行的实时图数据到相应的内部ram缓冲块中,为步骤3到步骤6中所有核同步进行的计算及同时进行的模板图数据重排都完成后,按核的顺序依次读入每一个核x下一行新的实时图数据覆盖不用的实时图ram缓冲块数据,在后续所有核同步进行的各行计算时需要通过时序控制模块控制2选1多路选择器选通相应组的模板图ram缓冲块输出与所有核同步进行计算所需的实时图ram缓冲块输出顺序变化对应;
步骤7中按核的顺序依次读入每一个核x对应的实时图下一行数据时,同时由步骤2中每一个核x的同一模块以相同方式计算出当前行(u)第0列的实时图灰度值总和
步骤7中按核的顺序依次读入每一个核x对应的实时图下一行数据时,同时由步骤2中每一个核x同一模块以相同方式计算出当前行(u)第0列的实时图灰度值平方总和
步骤8所有核计算出后续各行归一化相关系数,是指每一个核x计算实时图像第(x-1)*d(u=0)行至第(x-1)*d+m-1(u=d-1)行归一化相关系数。相应于每一个核x的第0行(对应整个实时图搜索行u0=(x-1)*d)的所有核同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算和数据重排完成后,按核的顺序依次读入每一个核x的下一行新的实时图数据覆盖不用的实时图ram缓冲块数据,并且通过时序控制模块通过2选1多路选择器重新选择相应组模板图ram缓冲块输出使其与之对应,这样相当于模板图像在待匹配实时图像中下移一行,因此在所有核下一行同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算前,需要对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,即如果对于每一个核前一行并行计算时选择输入a组内部ram缓冲块中模板图数据,此时并行计算选择输入b组;步骤6数据重排中模板图外部存储器数据读入选择存储到a组,与此类似,若对于每一个核前一行并行计算时选择输入b组,此时并行计算选择输入a组;步骤6数据重排中模板图外部存储器数据读入选择存储到b组,这样,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出后续各行各列归一化相关系数。
本发明还采用如下技术方案:一种归一化相关图像模板匹配多核并行高效实现装置,由高速相关运算器、模板图实时图数据外部存储器、结果存储器和微处理器构成,高速相关运算器分别与模板图实时图数据外部存储器、结果存储器、微处理器相连,模板图实时图数据外部存储器、结果存储器与微处理器相连,所述高速相关运算器由归一化相关系数计算模块、外部通信接口模块以及时序控制模块组成,所述归一化相关系数计算模块用于归一化相关系数的计算,所述外部通信接口模块通过寄存器与处理器进行参数输入输出、指令输入、状态查询输出,所述时序控制模块基于上述步骤控制整个归一化相关系数计算的工作流程,它与各个模块中的ram的地址及控制线、多路选择器的选通地址、寄存器的使能端等控制和地址信号相连,所述模板图实时图数据外部存储器、结果存储器分别存储原始图像数据以及运算结果,微处理器由高速相关运算器的外部通信接口模块通过寄存器访问的方式进行参数输入输出、指令输入和状态查询输出,从而命令高速相关运算器进行相应的操作,同时也进行原始图像数据的准备工作,所述高速相关运算器把结果存储到结果存储器中,并且从模板图实时图数据外部存储器中读取数据。
进一步地,所述高速相关运算器的归一化相关系数计算模块包括模板图灰度值求和模块,模板图灰度值平方求和模块,后续计算模块、实时图灰度值总和分时输出缓冲模块、实时图灰度值平方总和分时输出缓冲模块、实时图模板图灰度值乘积总和分时输出缓冲模块,以及核1模块、核x模块总计q个类似并行运算核模块组成,所述模板图灰度值求和模块由一个累加器组成,模板图灰度值平方求和模块由一个平方运算模块和一个累加器相连而成,后续计算模块包括乘法器、平方运算模块、加、减法器和两个分子分母定点浮点转换模块、两个分母方根运算模块以及浮点除法运算模块。
所述实时图灰度值总和分时输出缓冲模块由q个分别对应每个核的实时图灰度值总和的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的实时图灰度值总和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续计算模块的实时图灰度值总和输入端,所述实时图灰度值平方总和分时输出缓冲模块、实时图模板图灰度值乘积总和分时输出缓冲模块的组成与实时图灰度值总和分时输出缓冲模块类似。
所述核1模块包括实时图灰度值求和模块、实时图灰度值平方求和模块和实时图模板图灰度值乘积求和模块,实时图灰度值求和模块由与实时图灰度值平方求和模块共用的mmax路实时图数据缓冲ram块、第1列累加模块、并加器、累加器和加法器组成,实时图灰度值平方求和模块由与实时图灰度值求和模块共用的mmax路实时图数据缓冲ram块、第1列累加模块、平方运算阵列、平方运算模块、并加器、累加器和加法器组成,所述实时图模板图灰度值乘积求和模块由与实时图灰度值求和模块共用的mmax路实时图数据缓冲ram块、所有核(x=1,…,q)中实时图模板图灰度值乘积求和模块共用的a组mmax路模板图ram缓冲块(21)和b组mmax路模板图ram缓冲块(15)及mmax路2选1多路选择器、mmax路乘法器、并加模块和累加器组成。
所述核x模块包括实时图灰度值求和模块、实时图灰度值平方求和模块和实时图模板图灰度值乘积求和模块,实时图灰度值求和模块由与实时图灰度值平方求和模块共用的mmax路实时图数据缓冲ram块、第1列累加模块、并加器、累加器和加法器组成,实时图灰度值平方求和模块由与实时图灰度值求和模块共用的mmax路实时图数据缓冲ram块、第1列累加模块、平方运算阵列、平方运算模块、并加器、累加器和加法器组成,所述实时图模板图灰度值乘积求和模块由与实时图灰度值求和模块共用的mmax路实时图数据缓冲ram块、所有核中实时图模板图灰度值乘积求和模块(包括核1模块(101)实时图模板图灰度值乘积求和模块(3))共用的a组m路模板图ram缓冲块和b组m路模板图ram缓冲块、mmax路2选1多路选择器,mmax路乘法器、并加模块和累加器组成。
所述其它q-2个并行运算核模块采用与核x类似的组成形式,与核1和核x同步运算实现总计q核的实时图灰度值总和、实时图灰度值平方总和、模板图实时图灰度值乘积总和的并行计算。
本发明具有如下有益效果:本发明通过合理的设计归一化相关图像模板匹配多核并行高效实现逻辑架构,可以更有效的充分利用逻辑资源,减少逻辑资源消耗,降低总功耗;相对于单核,提高归一化相关图像模板匹配的运算速度,进一步提高了实时性。同时,采用该方法的设备能够实现精度高、参数设置灵活、实时性强的高速图像模板匹配。由于基于归一化相关的模板匹配还广泛应用于图像对齐、双目立体视觉、视频编码等领域,因此该实现方法和装置具有广阔的应用前景。
附图说明:
图1是归一化相关图像模板匹配多核并行高效实现方法的原理结构框图。
图2是核x实现方法的原理结构框图。
图3是归一化相关图像模板匹配多核并行高效实现方法的工作流程。
图4是图1中第1列累加模块实现原理结构图。
图5是实时图灰度值总和分时输出缓冲模块实现原理结构图。
图6是模板匹配原理示意图。
图7是归一化相关图像模板匹配多核并行高效实现装置原理结构框图。
图8是归一化相关图像模板匹配多核并行高效实现装置结构框图。
具体实施方式:
下面结合附图给出具体实例,进一步说明本发明归一化相关图像模板匹配多核并行高效实现方法和装置是如何实现的。
本发明所用的归一化相关系数公式如下:
a表示实时图,b表示模板图,其尺寸分别为k×l和m×n个像素。(u,v)为任一搜索位置,0≤u≤k-m,0≤v≤l-n。∑∑表示
为了简单起见,进行下述变量定义:bcc=∑∑b(i,j),b2cc=∑∑(b(i,j)2,acc(u,v)=∑∑a(i+u,j+v),a2cc(u,v)=∑∑a(i+u,j+v)2,abcc(u,v)=∑∑a(i+u,j+v)b(i,j),即bcc表示模板图灰度值总和,b2cc表示模板图灰度值平方总和,acc(u,v)表示当前搜索位置实时图灰度值总和,a2cc(u,v)表示当前搜索位置实时图灰度值平方总和,abcc(u,v)表示当前搜索位置实时图模板图灰度值乘积总和。归一化相关系数可进一步简写为:
由上式的分子和分母我们可以看出,归一化相关系数的计算需要大量的乘累加操作,因此非常适合并行实现。为简便起见,此处的定义和缩写在下文的描述、图形及表中同样有效。
实时图像以及模板图像的行数和列数(即,k≤kmax,l≤lmax,m≤mmax,n≤nmax)都是可以由外部微处理器输入的可变的参数,其中kmax、lmax、mmax、nmax为由任务需求决定的最大可输入的行列数,也是本发明所采用的并行通道数目。本发明所提出的归一化相关图像模板匹配多核并行高效实现方法的原理结构框图如图1所示。归一化相关系数计算完成以后取最大值、阈值处理等操作由微处理器37来完成。为了清晰起见,图1主要给出了数据流相关的结构图,各个操作符号的功能说明已经在图例中给出。图中,时序控制模块8主要用于控制整个归一化相关系数计算的工作流程。外部通信接口模块7主要用于与微处理器37进行通信,即进行参数(包括k、l、m、n)、命令输入及状态输出。归一化相关系数计算模块36为核心运算模块,包括模板图灰度值求和(bcc)模块2,模板图灰度值平方求和(b2cc)模块1,后续计算模块6、实时图灰度值总和(acc)分时输出缓冲模块42、实时图灰度值平方总和(a2cc)分时输出缓冲模块41、实时图模板图灰度值乘积总和(abcc)模块分时输出缓冲模块43,以及核1模块101、核x模块102等总计q个类似的并行运算核组成,图2给出了核x模块102的具体原理结构框图。
如图3所示,本发明归一化相关图像模板匹配多核并行高效实现方法包括如下几步。下面具体结合原理结构框图说明这些步骤中子模块的实现方法及工作流程。
(1)根据核的数目q,设定每个核处理的实时图的数据块行间距为d=ceil((k-m+1)/q)。
根据核的数目q,设定每个核处理的实时图的数据块行间距为d=ceil((k-m+1)/q),相当于将实时图搜索区域分成了q-1个搜索行数大小为d的块和一个搜索行数大小(k-m+1)-d*(q-1)的块,其中ceil(x)为向上取整运算,即取当前值趋向于正无穷的正整数,例如小数4.5、4.1、4.8取ceil运算为5。根据核的数目q,由外部处理器设定每个核处理的实时图的数据块行间距,然后由外部处理器作为参数输入到相关计算处理单元。
(2)从外部存储器中读取每一行模板图数据分别存储到a组对应的每一个内部ram缓冲块中,同时进行模板图灰度值总和
由于每一行中每一个位置上的归一化相关系数的计算只需模板图行数(m)行的实时图,因此对于核1我们采用两组(a组和b组)mmax个大小为1×nmax的模板图ram缓冲块21和15(如图1中的orama[0],...,orama[mmax-1]和oramb[0],...,oramb[mmax-1])及mmax个大小为1×lmax的实时图ram缓冲块20(如图1中的rram[0],...,rram[mmax-1]),其中两组模板图ram缓冲块是为了后续的计算和数据对应重排同时进行而设。在开始计算时,首先从外部存储器中读取每一行模板图数据分别存储到a组对应的每一个内部ram缓冲块中,按核的顺序依次读入每一个核x对应的(x-1)*d到(x-1)*d+m-1行数的实时图数据分别依次存储到核x对应的内部实时图数据ram缓冲块。具体是将每一行n列的灰度值存储到一个ram块中,共存入m行,即采用了m个ram块,每个ram块包含n个存储单元;模板图对应的内部ram缓冲块分为两组:a组和b组;依次读入每个核实时图数据到对应的内部ram缓冲块,是将每一行l列的灰度值存储到一个ram块中,共存入m行,同样采用了m个ram块,每个ram块包含l个存储单元。
对于一个固定的模板图,在每一个模板匹配位置(u,v),bcc和b2cc在整幅图搜索空间内只计算一次。因此我们可以在模板图数据从外部存储器(图1中的exter-roram)9中输入到内部的ram缓冲块21(orama[0],...,orama[m-1])的同时把bcc和b2cc计算出来。
bcc由bcc计算模块2实现,该模块包括一个累加器14。累加器14的输入端连接到模板图实时图数据外部存储器9的输出端,在读入模板图数据时通过时序控制其输出即为模板图灰度值总和。
b2cc由b2cc计算模块1实现,该模块包括一个平方运算模块12和一个累加器13。平方运算模块12的输入端连接到模板图实时图数据外部存储器9的输出端,平方运算模块12的输出连接到累加器13的输入端,在读入模板图数据时通过时序控制累加器13的输出即为模板图灰度值平方总和。
在读取时同时进行的每一个核x对应的整个实时图第(x-1)*d行第0列(u=0,v=0)搜索位置处的实时图灰度值总和
因此,本发明在实时图数据从外部存储器9(图1中的exter-roram)读入到内部ram缓冲块20(rram[0],...,rram[m-1])的过程中计算acc(u,0)。
在读取时同时进行的每一个核x对应的整个实时图第(x-1)*d行第0列(u=0,v=0)搜索位置处的实时图灰度值平方总和
其中实时图灰度值总和、实时图灰度值平方总和以及后续步骤中的模板图实时图灰度值乘积总和分时输出缓冲为所有并行核按核的顺序分时共用后续计算模块而设,即如步骤5所述,在下一列计算模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和的同时,按核的顺序依次从分时输出缓冲中同时输出各个核的模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,同时计算当前行后续各列v的归一化相关系数。
其中实时图灰度值总和分时输出缓冲,如图5所示,由q个分别对应每个核的实时图灰度值总和的数据缓冲器601、多入单出选通器602组成,数据缓冲器的输入与每个核的实时图灰度值总和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续计算模块的实时图灰度值总和输入端。
步骤2、4、5、7、3中所述的实时图灰度值平方总和分时输出缓冲、模板图实时图灰度值乘积总和分时输出缓冲与前述的实时图灰度值总和分时输出缓冲除数据外结构相同,都是有由q个分别对应每个核的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的相应的输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续计算模块的相应输入端。
(3)选通第a组模板图内部ram缓冲块,所有核同时计算第u行(对于核x,u从0开始,针对每个核对应块的行数)第0列(v=0)模板图实时图灰度值乘积总和
对于核1(x=1)(101)的模板图与实时图当前搜索位置的灰度值乘积总和
对于一个核,由归一化相关系数公式,采用模板图最大的行数(mmax)个并行的乘法通道来进行并行运算。因此,通过合理的时序控制在一个时钟周期内就可以计算m(m≤mmax)个乘累加,这样,在n个时钟周期以后,就可以得到一个搜索位置上的abcc。
对于核1(101),在开始计算时,首先从外部存储器中读入实时图数据和模板图数据到对应的内部ram缓冲块中。若只采用a组模板图数据内部ram缓冲块,当开始进行第1行(从0开始算起)搜索时,新来的一行实时图数据覆盖已经不用的第0个缓冲块,此时实时图第0个ram缓冲块(rram[0])已经和模板图中的第0块(orama[0])不对应,而是与模板图的最后一块(orama[m-1])相对应,此时第1个实时图缓冲块对应模板图的第0个缓冲块,以此类推。当进行第2行(从0开始算起)搜索时,新来的一行实时图数据覆盖第1个已经不用的ram缓冲块,此时第0个实时图缓冲块对应第m-2个模板图缓冲块(orama[m-2]),第1个实时图缓冲块对应第m-1个模板图缓冲块(orama[m-1]),第2个才对应模板图的第0个缓冲块(orama[0]),以此类推。由此为了使实时图和模板图的每个ram缓冲块数据能够对应上,采用额外增加一组(b组)模板图数据内部ram缓冲块的方式,这样后续只采用了2选1多路选择器(mux)在a组和b组模板图数据内部ram缓冲块之间切换,当a组用于计算时,b组用于为下一行数据的对应做准备(重排),即从实时图模板图外部存储器中按照下一行搜索位置处实时图数据内部ram缓冲块的计算行顺序从模板图外部存储器中读取数据分别到对应的b组模板图内部缓冲块中,这样下一行模板图实时图灰度值乘积总和计算时通过选通b组模板图内部缓冲块使其与实时图ram缓冲块对应,此时a组切换为用于为新的一行数据的对应做准备(重排),以此类推。对于核1,如果第0行计算时,如上所述,按行顺序m-1,0,1,…,m-2从外部存储器中读入模板图数据分别到第0,1,…m-1个b组模板图内部缓冲块中,这样第1行计算时,第0,1,…m-1个b组模板图、实时图内部ram缓冲块的数据是对应的。因此,换行时用于并行计算输入的模板图内部ram缓冲块输出通过2选1多路选择器在a组和b组之间进行切换,不用于计算的一组用于为下一行计算作数据准备,从而实现模板图实时图灰度值乘积总和计算时模板图实时图数据的对应。
对于核1,实时图模板图灰度值乘积求和(abcc计算)模块3由与实时图灰度值求和模块4共用的mmax路实时图数据缓冲ram块20、所有核共用的a组和b组mmax路模板图ram缓冲块21和15及mmax路2选1多路选择器16、mmax路乘法器17、并加模块18和累加器19组成。a组与b组mmax个模板图像ram缓冲块(21,15)的所有输出端分别对应连接到mmax个2选1多路选择器16的输入端上,每一个2选1多路选择器的输出对应连接到乘法器17中的一个乘法器的一输入端,乘法器的另一输入端对应连接到实时图像ram缓冲块20的输出端,通过采用模板图最大的行数(mmax)个这样的并行通道进行并行运算,然后各个通道输出端(mmax路乘法器17的输出端)连接到一个并加模块18(padd1),最终连接到一个累加模块19(accu3)上。
在具体计算时,时序控制模块8控制2选1多路选择器选通当前组模板图像内部ram缓冲块使得对应的模板图数据与实时图数据进行乘积运算,改变模板图像和核x的实时图像ram缓冲块的地址,逐列输出模板图和核x的实时图的对应数据进行乘积运算,然后经过并加模块对当前列各行数据进行求和,而后由累加模块对并加模块输出的结果逐列求和后,获得当前行各个搜索位置的
(4)每一个核x采用一加一减两步操作同步计算搜索位置第u行第1列(v=1)的实时图灰度值总和
a)后续acc计算
核x当前第u行第1列开始后续各列v(v≥1,包括第1列)每一个实时图灰度值总和
由具体的模板匹配过程图6可以看出,对于一个核,当前位置(u,v0+1)的acc计算和前一位置(u,v0)只是多了一列新的数据(图5中的新列)和少了一列旧的数据(图5中的旧列),因此在当前给定搜索位置(u,v0+1),可以通过时序控制逻辑同时控制所有实时图ram缓冲块(核1为20,核x为420),依次输出实时图中模板图重叠区域相对于前一个搜索位置(u,v0)新进的一列数据(对应实时图中第v0+n列)和刚移出的一列数据(对应实时图中第v0列),经过并加器后,由累加器累加新进的一列数据并加结果(对于核1为
因此后续列的实时图灰度值总和acc(u,v)由acc计算模块(核1为4,核x为400)中的与a2cc(u,v)计算模块(核1为5,核x为500)共用的内部实时图数据ram缓冲块(核1为20,核x为420)、并加模块(核1为22,核x为422)(padd2)、累加器(核1为23,核x为423)(accu4)和第1列累加1模块(核1为24,核x为424)实现。所有内部实时图数据ram缓冲块输出端对应连接到并加模块的输入端,并加模块的输出端连接到累加器的输入端。累加器的输出加上第1列累加1模块的输出即可得到后续列的实时图灰度值总和acc(u,v)。
b)后续a2cc计算
从每一行的第1个搜索位置开始,a2cc(u,v)以acc(u,v)同样的方式同时实现。从搜索位置第1列开始,每一个核x通过时序控制模块同时控制所有核对应的实时图数据缓冲ram块依次输出实时图中模板图重叠区域相对于前一列搜索位置新进的一列数据和刚移出的一列数据,每一行数据分别由平方运算模块求平方,经过并加器并加后,由累加器在当前输出值的基础上,累加新进的一列数据平方并加结果减去刚移出一列数据平方并加结果,最后由加法器与已经计算出的当前行第0列搜索位置处的
因此后续列的实时图灰度值平方总和a2cc(u,v)由a2cc计算模块(核1为5,核x为500)中的与acc计算模块(核1为4,核x为400)共用的内部实时图数据ram缓冲块(核1为20,核x为520)(rram[0],...,rram[m-1])、各行1个平方运算模块(核1为26,核x为526)、并加器(核1为25,核x为525)(padd3)、累加器(核1为29,核x为529)(accu5)、平方模块(核1为27,核x为527)和第1列累加2模块(核1为28,核x为528)组成。所有内部实时图数据缓冲ram块(rram[0],...,rram[m-1])的输出端对应连接到各行平方运算输入端,各行平方运算输出端连接到并加器的输入端,并加器的输出端连接到累加器的输入端。累加器的输出加上第1列累加2模块的输出即可得到后续列的实时图灰度值平方总和a2cc(u,v)。
每一个核x都包含有相应上述运算的实时图数据缓冲ram块、并加器、累加器以同时进行相应的运算。
(5)由步骤3和4相同的方式,所有核同步依次计算出模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,并且同步存储到相应的分时输出缓冲中。在下一列计算模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和的同时,按核的顺序依次从分时输出缓冲中同时输出各个核的模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,同时计算当前行后续各列v归一化相关系数直到每一个核所有列计算完成。
归一化相关系数后续计算是由后续计算模块6实现的,在每一个核x的
搜索位置当前行(第0行)归一化相关系数的计算,是模板图像第0到m-1行与每个核x实时图第(x-1)*d到(x-1)*d+m-1行数据对应计算,搜索位置第0列归一化相关系数的计算为模板图像第0到n-1列与每个核x实时图第0到n-1列数据对应计算;搜索位置第1列归一化相关系数的计算为模板图像第0到n-1列与每个核x实时图像第1到n列数据对应计算,计算该处每一个核x的
(6)与步骤3到步骤5同时进行模板图数据重排,即按所有同步进行运算的核下一行(u+1)搜索时其实时图数据内部ram缓冲块的计算行顺序从外部存储器中读取模板图数据并存储到对应的b组模板图内部ram缓冲块中。
由前述,所有同步进行运算的核下一行搜索前按核的顺序从实时图外部存储器中依次读入每一个核x下一行新的实时图数据分别覆盖每个核不用的实时图ram块数据(参考步骤7),导致当前组(核x当前第0行为a组)的模板图ram缓冲块与每个核的实时图ram缓冲块输出顺序不再对应,为了解决这个问题,采用了增加了一组(b组)模板图数据内部ram缓冲块方式,这样当前行搜索时,只需采用2选1多路选择器在a组和b组模板图数据对应内部ram缓冲块之间切换选通一组用于并行计算,另一组用于为下一行数据的对应做准备(重排),即按下一行搜索位置处实时图数据内部ram缓冲块的计算行顺序从模板图外部存储器中读取数据分别到对应的b组(当前第0行a组用于计算)模板图内部缓冲块中,这样下一行相关系数计算时通过选通b组模板图内部缓冲块与对应实时图内部ram缓冲块数据进行计算,此时a组切换为用于为下一行数据的对应做准备(数据重排),以此类推。这样,通过在当前行计算同时预先重新从模板图外部存储器中按所有同步进行运算的核下一行搜索计算时实时图数据块的行顺序读取数据分别到对应的另一组(b组)模板图内部缓冲块中,下一行相关系数计算时通过2选1多路选择器选通该组(b组)模板图内部缓冲ram块使其与之对应。
(7)在步骤3到步骤6中所有核同步进行的相关计算及同时进行的模板图数据重排都完成后,按核的顺序依次读入每一个核x下一行(u+1)实时图数据存储到每一个核x数据已经无效的内部实时图ram缓冲块,同时计算每一个核x当前行u+1第0列(v=0)的实时图灰度值总和
按核的顺序从外部存储器依次读入每一个核x下一行的实时图数据到相应的内部ram缓冲块中,为步骤3到步骤6中所有核同步进行的计算及同时进行的模板图数据重排都完成后,按核的顺序依次读入每一个核x下一行(u+1)新的实时图数据覆盖不用的实时图ram缓冲块数据,在后续所有核同步进行的各行计算时需要通过时序控制模块控制2选1多路选择器选通相应组(在步骤6中已经预先准备好对应数据)的模板图ram缓冲块输出与所有核同步进行计算所需的实时图ram缓冲块输出顺序变化对应。所有核的实时图数据读入覆盖方式能够保证模板图的重排后多路选择器选通的数据与所有核的实时图数据对应。
按核的顺序依次读入每一个核x实时图下一行数据时,同时由步骤2中每一个核x的同一模块以相同方式计算出当前行(u)第0列的实时图灰度值总和
(8)对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出相应数据块后续各行各列归一化相关系数。
每一个核x计算实时图像第(x-1)*d+1行至第(x-1)*d+m-1行归一化相关系数,相应于每一个核x的第0行(对应所有实时图搜索行u0=(x-1)*d)的所有核同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算和数据重排完成后,按核的顺序依次读入每一个核x的下一行新的实时图数据覆盖不用的实时图ram缓冲块数据,并且通过时序控制模块通过2选1多路选择器重新选择相应组(已经预先准备好对应数据)模板图ram缓冲块输出使其与之对应,这样相当于模板图像在待匹配实时图像中下移一行。因此在所有核下一行同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算前,需要对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,即如果对于每一个核前一行并行计算时选择输入a组内部ram缓冲块中模板图数据,此时并行计算选择输入b组;步骤6数据重排中模板图外部存储器数据读入选择存储到a组。与此类似,若对于每一个核前一行并行计算时选择输入b组,此时并行计算选择输入a组;步骤6数据重排中模板图外部存储器数据读入选择存储到b组。这样,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出相应数据块后续各行各列归一化相关系数,从而完成所有相关系数的计算。
其中本发明中外部实时图和模板图数据存储在了一块存储器(exter-roram)中,此时读取分为两步;也可考虑分别存储在两块ram中,此时可同时进行读取,可根据实际情形对上述实现方法和步骤进行适量合并。
由上述实现方法和步骤,我们可以看出,归一化相关系数计算需要(k-m-q)*l+q*m*l+m*n+d*t1r个时钟周期,其中当(l-n)*(n+2)+n>m*n时,t1r=(l-n)*(n+2)+n;当(l-n)*(n+2)+n<=m*n时,t1r=m*n。因此总的计算时间为((k-m-q)*l+q*m*l+m*n+d*t1r)/fclk,这儿fclk为系统工作频率。
图7为归一化相关图像模板匹配多核并行高效实现装置原理结构框图,多核并行高效实现装置由高速相关运算器10、模板图实时图数据外部存储器9、结果存储器11和微处理器37构成,高速相关运算器10分别与模板图实时图数据外部存储器9、结果存储器11、微处理器37相连,模板图实时图数据外部存储器9、结果存储器11也与微处理器37相连。如图1所示高速相关运算器10由归一化相关系数计算模块36、外部通信接口模块7以及时序控制模块8组成。归一化相关系数计算模块36主要用于归一化相关系数的计算。外部通信接口模块7主要通过寄存器与处理器进行参数输入输出、指令输入、状态查询输出。时序控制模块8主要基于上述步骤控制整个归一化相关系数计算的工作流程,它与各个模块中的ram的地址及控制线、多路选择器的选通地址、寄存器的使能端等控制和地址信号相连。模板图实时图数据外部存储器9、结果存储器11分别存储原始图像数据以及运算结果,微处理器37由高速相关运算器10的外部通信接口模块7通过寄存器访问的方式进行参数输入输出、指令输入和状态查询输出,从而命令高速相关运算器10进行相应的操作,同时也进行原始图像数据的准备工作。高速相关运算器10把结果存储到结果存储器11中,并且从模板图实时图数据外部存储器9中读取数据。
如图1所示,归一化相关图像模板匹配多核并行高效实现装置中高速相关运算器10的归一化相关系数计算模块36包括模板图灰度值求和模块2,模板图灰度值平方求和模块1,后续计算模块6、实时图灰度值总和分时输出缓冲模块42、实时图灰度值平方总和分时输出缓冲模块41、实时图模板图灰度值乘积总和分时输出缓冲模块43,以及核1模块101、核x模块102等总计q个类似并行运算核组成。模板图灰度值求和模块2由一个累加器14组成;模板图灰度值平方求和模块1由一个平方运算模块12和一个累加器13相连而成。后续计算模块6包括乘法器、平方运算模块、加、减法器和分子分母定点浮点转换模块(30、31)、分母方根运算模块(33、34)、浮点除法运算模块32等。
实时图灰度值总和分时输出缓冲模块42,由q个分别对应每个核的实时图灰度值总和的数据缓冲器、多入单出选通器组成,数据缓冲器的输入与每个核的实时图灰度值总和输出连接,每个核的数据缓冲器的输出分别与多入单出选通器的输入相连,其输出连接到后续处理模块的实时图灰度值总和输入端。实时图灰度值平方总和分时输出缓冲模块41、实时图模板图灰度值乘积总和模块分时输出缓冲模块43的组成与实时图灰度值总和分时输出缓冲模块42类似。
核1模块101包括实时图灰度值求和模块4、实时图灰度值平方求和模块5和实时图模板图灰度值乘积求和模块3,实时图灰度值求和模块4由与实时图灰度值平方求和模块5共用的mmax路实时图数据缓冲ram块20、第1列累加模块24、并加器22、累加器23和加法器组成。实时图灰度值平方求和模块5由与实时图灰度值求和模块4共用的mmax路实时图数据缓冲ram块20、第1列累加模块28、平方运算阵列26、平方运算模块27、并加器25、累加器29和加法器组成。实时图模板图灰度值乘积求和模块3由与实时图灰度值求和模块4共用的mmax路实时图数据缓冲ram块20、所有核中实时图模板图灰度值乘积求和模块共用的a组和b组mmax路模板图ram缓冲块21和15、mmax路2选1多路选择器16、mmax路乘法器17、并加模块18和累加器19组成。其中,mmax为由任务需求决定的模板图最大可输入行数。
核x模块102包括实时图灰度值求和模块400、实时图灰度值平方求和模块500和实时图模板图灰度值乘积求和模块300。实时图灰度值求和模块400由与实时图灰度值平方求和模块500共用的mmax路实时图数据缓冲ram块420、第1列累加模块424、并加器422、累加器423和加法器组成。实时图灰度值平方求和模块500由与实时图灰度值求和模块400共用的mmax路实时图数据缓冲ram块420、第1列累加模块528、平方运算阵列526、平方运算模块527、并加器525、累加器529和加法器组成。实时图模板图灰度值乘积求和模块300由与实时图灰度值求和模块400共用的mmax路实时图数据缓冲ram块420、所有核中实时图模板图灰度值乘积求和模块(包括核0模块(101)实时图模板图灰度值乘积求和模块(3))共用的a组和b组m路模板图ram缓冲块21和15及mmax路2选1多路选择器16、mmax路乘法器317、并加模块318和累加器319组成。
其它q-2个并行运算核模块组成与核x模块102类似。
高效实现装置工作流程如下。首先微处理器37把原始模板图和实时图数据存入模板图实时图数据外部存储器9中,然后向高速相关运算器10输入图像的尺寸参数、各核实时图数据块行间距,而后输入启动命令启动归一化相关运算,高速相关运算器10会将运算结果存储到结果存储器。在运算过程中通过寄存器访问的方式查询运算的进程状态。在运算完成以后,微处理器37会从高速相关运算器10收到完成的中断信号,为可靠起见,微处理器37进一步查询高速相关运算器10的完成标志,在确保完成以后从结果存储器11读取归一化相关系数计算结果进行后续处理工作。
高效实现装置中所包含的高速相关运算器可以利用fpga实现,也可利用vlsi实现。高速相关运算器中实时图像以及模板图像的行数、列数、各核实时图数据块行间距,都是可以由外部微处理器输入的可变的参数,而最终实现的每一个核的并行通道数目,包括内部实时图和模板图ram缓冲块的数目,是由任务要求确定的最大的行数。
下面是算法的具体实施实例。
本发明的实施例是以altera公司的现场可编程门阵列stratixii系列fpgaep2s90f780i4芯片为平台。图像灰度值为8位,模板图和实时图的大小参数是可变的:2≤m≤80,2≤n≤80,2≤k≤512,2≤l≤512,相应的,我们采用模板图最大的行数80作为每个核并行通道数,总计采用3核。当前针对最大图像参数进行实施。采用quartusii8.0sp1软件作为基本的逻辑分析、综合、逻辑布局布线工具,采用verilog和vhdl语言混合硬件编程的方式进行逻辑设计。系统的全局时钟频率采用70mhz,由pll根据外部输入的20mhz时钟产生。具体采用32位浮点归一化相关系数输出。
依据本发明,具体实例图像模板匹配的实施如下。
1)依据两个图像的具体大小,搭建图像匹配系统,
高速相关运算器按照图1在fpga芯片上实现,完成归一化相关系数的计算。模板图实时图的ram缓冲块、多路选择器、乘法运算、平方运算、加法运算、减法运算、求方根运算、定点浮点转换、浮点除法运算都由qartusii根据所用的fpga相应进行综合实现。时序控制模块通过状态机的方式实现,从而控制整个系统的运行。在分母求方根运算和分子转化为浮点数之前,所有的数据计算都进行了位扩展以保证不出现精度损失。
2)采用verilog和vhdl语言混合编程的方式进行逻辑设计
步骤1:根据核的数目q,设定每个核处理的实时图的数据块行间距为d。这儿q=3,实时图的数据块间距为d=145。
步骤2:读入模板图像80*80个数据到a组对应的每一个内部ram缓冲块中,对于3个核,同时计算bcc和b2cc;分别读入前80行实时图像512*80个数据分别存储到对应的内部ram缓冲块,计算第0行第0列搜索位置上的acc和a2cc。按核的顺序依次读入每一个核x对应的(x-1)*d到(x-1)*d+79行数的实时图数据分别依次存储到核x对应的内部实时图数据ram缓冲块,同时计算核x对应的第(x-1)*d行第0列(u=(x-1)*d(从0开始),v=0)搜索位置处实时图灰度值总和
对于模板图像,设置了两组(a组和b组)80个ram缓冲块;对于每个核实时图像设置1组80个ram缓冲块,每一行信息存储到一个ram缓冲块中。由于灰度值为8位二进制数据,每个模板图ram缓冲块的大小为80*8(位),每个实时图ram缓冲块的大小为512*8(位)。对于核1实时图,在开始时读入的是第0至79行数据,前80行实时图像依次存入实时图数据缓冲ram块中,总计80*512*8(位)。核x对应的读入(x-1)*d到(x-1)*d+79行的实时图数据存入核x的实时图数据缓冲ram块中,bcc在模板图像数据读入过程中通过bcc计算模块计算出来,同时b2cc也在模板图像数据读入过程中通过b2cc计算模块计算出来。核1第0行第0列搜索位置上的acc和a2cc分别由第1列累加1模块和第1列累加2模块实现。同样其它所有核对应的acc和a2cc分别由其第1列累加1模块和第1列累加2模块实现
步骤3:计算每个核的abcc(m,n),并且将结果存储到模板图实时图灰度值乘积总和分时输出缓冲中;
对于所有核abcc的计算,时序控制模块会控制当前计算组模板图和所有核实时图每一个ram缓冲块地址同时输出一列数据,同时控制多路2选1选择器使得对应的模板图与所有核实时图数据进行乘积运算,然后经过对所有行乘积结果同时求和的并加和对并加结果逐列求和的累加后获得,并且存储到模板图实时图灰度值乘积总和分时输出缓冲中。
步骤4:同步计算所有核的acc(m,n)和a2cc(m,n),同时存储到实时图灰度值总和、实时图灰度值平方总和分时输出缓冲中。
对于每个核每一行从第1列(0为起始序号)开始,acc和a2cc可由时序控制模块控制acc计算模块和a2cc计算模块实现,具体为每个核从实时图数据ram缓冲块中依次读出新进的一列数据和移出的旧的一列数据,对这两列数据进行并加且对前后的并加结果做差,对结果值进行累加而后和当前行第0列的acc(m,0)求和计算得到acc(m,n);同时对这两列输出数据的每一行首先分别进行平方,然后进行并加且对前后的并加结果做差,对结果值进行累加而后和当前行第0列的a2cc(m,0)求和计算得到a2cc(m,n),同时存储到当前核实时图灰度值总和、实时图灰度值平方总和分时输出缓冲中。所有核的acc(m,n)和a2cc(m,n)是同步计算得到的。
步骤5:由步骤3和4相同的方式,所有核同步依次计算出模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,并且同步存储到相应的分时输出缓冲中。在计算下一列模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和的同时,按核的顺序依次从分时输出(后续计算)缓冲中同时输出各个核的模板图实时图灰度值乘积总和、实时图灰度值总和、实时图灰度值平方总和,同时计算当前行后续各列v归一化相关系数直到每一个核所有列计算完成。
步骤6:与步骤3到步骤5同时进行模板图数据重排,即按所有同步进行运算的核下一行(u+1)搜索时其实时图数据内部ram缓冲块的计算行顺序从外部存储器中读取模板图数据并存储到对应的b组模板图内部ram缓冲块中。
步骤7:在步骤3到步骤6中所有核同步进行的相关计算及同时进行的模板图数据重排都完成后,按核的顺序依次读入从外部存储器读入每一个核x下一行的实时图数据到每一个核x相应的内部ram缓冲块中,同时计算当前行第0列的acc(m,0)和a2cc(m,0)值,并且存储到实时图灰度值总和、实时图灰度值平方总和分时输出缓冲中。
对于实时图像,当核1开始进行第1(从0开始)行搜索时,新来的第m行实时图数据覆盖已经不用的第0个缓冲块,此时第0个实时图缓冲块对应当前a组第m-1个模板图缓冲块(orama[m-1]),第1个才对应a组模板图的第0个缓冲块(orama[0]),以此类推。因此此时通过在当前行运算时,按下一行搜索时实时图数据缓冲块的计算行顺序从模板图外部存储器中读取数据分别存储到对应的另一组模板图内部ram缓冲块中;当进行下一行计算时,时序控制模块控制2选1多路选择器选通切换到另一组模板图内部ram缓冲块使其与新读入一行数据后实时图数据内部ram缓冲块对应。
每一个核当前行第0列搜索位置上acc(m,0)和a2cc(m,0)由相应的第1列累加1模块和第1列累加2模块在新一行实时图数据读入过程中同时计算出来。
步骤8:对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出相应数据块后续各行各列归一化相关系数。
每一个核x计算实时图像第u=(x-1)*d+1行至第u=(x-1)*d+d-1行归一化相关系数,相应于每一个核x的第0行(对应所有实时图搜索行u=(x-1)*d)的所有核同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算和数据重排完成后,按核的顺序依次读入每一个核x的下一行新的实时图数据覆盖不用的实时图ram缓冲块数据,并且通过时序控制模块通过2选1多路选择器重新选择相应组(已经预先准备好对应数据)模板图ram缓冲块输出使其与之对应,这样相当于模板图像在待匹配实时图像中下移一行。因此在所有核下一行同步进行的模板图实时图灰度值乘积求和、实时图灰度值求和、实时图灰度值平方求和计算前,需要对步骤3、步骤6中用于并行计算输入和数据重排的a组和b组模板图内部ram缓冲块进行功能互换,即如果对于每一个核前一行并行计算时选择输入a组内部ram缓冲块中模板图数据,此时并行计算选择输入b组;步骤6数据重排中模板图外部存储器数据读入选择存储到a组。与此类似,若对于每一个核前一行并行计算时选择输入b组,此时并行计算选择输入a组;步骤6数据重排中模板图外部存储器数据读入选择存储到b组。这样,采用步骤3到步骤7相同的方式进行类似操作,所有核计算出相应数据块后续各行各列归一化相关系数。直到核1~核2计算出145行、核3计算出143行总计433行归一化相关系数并且存储到外部存储器中。
3)资源消耗、内核速度及时间消耗
由qartusii编译报告,资源利用情况如表1所示。可见,在包含了求平方根、定点到浮点转换、浮点除法等运算情况下,整个fpga芯片占用的逻辑资源不多,因而本发明所提方案是完全可以实现的。
表1资源利用情况
对于大小为80×80的模板图和大小为512×512的实时图,采用3核情况下,采用70mhz系统全局时钟频率,模板图和实时图分别读入的情况下,包含外部存储器数据读取时间,由于(l-n)*(n+2)+n>m*n,高速相关运算器完成所有搜索位置归一化相关系数运算所用计算时间为78.7ms。
每个核采用80个并行通道,在70mhz系统全局时钟频率下,3核高速相关运算器仅用78.7ms就可以完成归一化相关系数计算,因此在可编程逻辑器件上并行实现基于归一化相关系数的模板匹配可大大节约时间,提高匹配速度,可以达到实时匹配的要求。
4)实际的实验结果
在实际系统中,归一化相关图像模板匹配多核并行高效实现装置的基本构成如图8所示。图中,exter-roram、exter-ram分别为缓存模板图实时图数据和运算结果的外部存储器。微处理器采用adi公司的dsp芯片ts201。addr和data为地址和数据总线,rd、wr、cs为外部存储器读写控制信号。
首先ts201作为核心处理器把模板图实时图数据存入外部双端口ram(exter-roram)中,然后向fpga输入图像的尺寸参数和核数,其后输入启动命令启动模板匹配运算。在运算完成以后,ts201会收到完成的中断信号,为可靠起见,ts201需要查询fpga的完成标志,在确保完成以后进行后续工作。
在不同参数情况下用不同实际图像数据对该装置进行了长期的稳定性测试,归一化相关系数计算的结果与理论计算值相一致,并且能够稳定可靠的工作。
同时我们也利用ts201对系统运算时间进行了评估,处理时间和前面的理论计算结果一致。对于大小为80×80的模板图和大小为512×512的实时图,70mhz系统全局时钟频率下,采用3核情况下,所用时间为78.7ms。
因为fpga通常用作vlsi专用集成电路的验证和开发平台,因此所提出的高速相关运算器可以同样进一步由vlsi实现和验证。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!