一种基于客户行为习惯偏好的个性化酒店智能推荐算法的制作方法
本发明涉及酒店管理技术领域,具体涉及一种基于客户行为习惯偏好的个性化酒店智能推荐算法。
背景技术:
计算机网络技术的普及和电子商务的快速发展,人们已经进入信息社会和网络经济时代,电子商务网站给人们提供越来越多的选择。对于客户而言,由于个性爱好、文化水平和经济条件等因素不同,不同客户对商品的喜好也不同。基于电子商务发展起来的线上酒店订购成为人们预定酒店的主要方式。而面对众多商家和海量的酒店,客户往往难以找到符合自己兴趣偏好的合适酒店,商家也难以让自己提供的酒店在客户体验方面脱颖而出。因此,对于现有客户可选的众多商家酒店,如何按照客户行为习惯偏好,为客户推荐合适的酒店,成为亟待解决的难题。
在现有的推荐方法中,根据酒店的基本信息的介绍包括星级、房型、价格等,以及酒店图片和酒店的综合排名等信息将酒店推向客户是常用的方法,该方法无法结合客户的个人体验和偏好向客户推荐满足其兴趣的酒店,也谈不上个性化的服务,不能有效的与客户偏好契合,无法较大限度的提高客户对所推荐的酒店的认可,亟待改进。。
技术实现要素:
本发明的目的在于针对现有技术的缺陷和不足,提供一种结构简单,设计合理、使用方便的基于客户行为习惯偏好的个性化酒店智能推荐算法,解决衡量指标单一的问题;解决了针对客户个性化推荐的问题;增加第五个指标“相隔距离”在特殊情况下来辅助决策,使算法闭环。
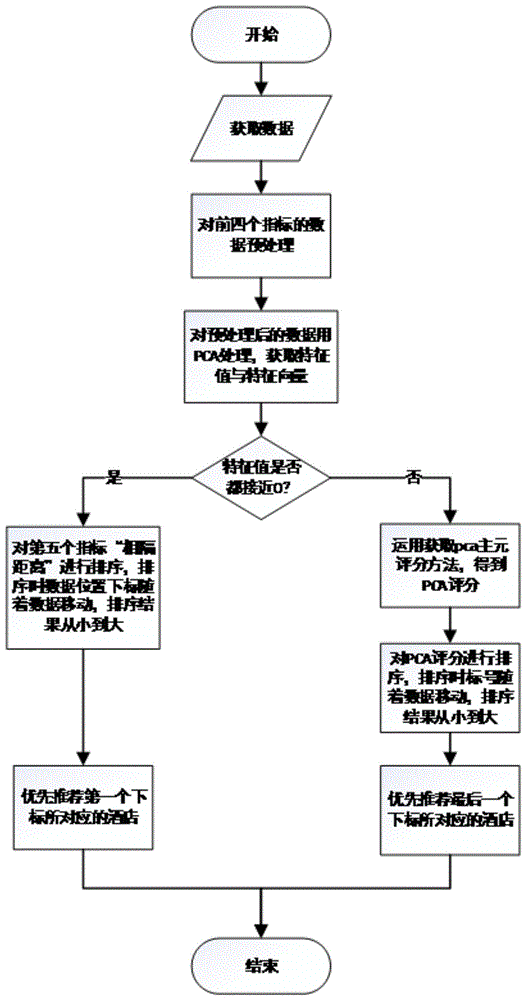
为实现上述目的,本发明采用的技术方案是:它的计算步骤如下:
1、确定针对客户的酒店推荐指标:
1.1、确定四个衡量酒店与客户的偏好契合程度的指标,即,客户入住时间;客户入住次数;客户入住单价;客户体验均分;
1.2、确定第五个指标,即,相隔距离,在上述四个指标都很相近的情况下,将会使用“相隔距离”来决定针对该顾客推荐哪个酒店,使算法闭环;
2、根据推荐指标构建算法输入矩阵:
在步骤1的描述中,每个酒店有五个指标,在此对每一个备选酒店构建一个5*1列向量,该5*1向量从上到下依次为客户入住时间、客户入住次数、客户入住单价、客户体验均分、相隔距离;如果有n个同类可选酒店,这里就有n个5*1向量,把这n个5*1向量从左到右拼接起来,就得到了一个5*n矩阵,到此,算法输入矩阵构建完毕;该输入矩阵从行来看,第一行表示该客户上一周年在可选的n个酒店中各酒店入住的具体天数;第二行表示该客户上一周年在可选的n个酒店中各酒店入住的具体次数;第三行表示该客户上一周年在可选的n个酒店中各酒店入住的平均单价;以此类推;同时,该输入矩阵的每一列都表示该顾客选择一个酒店时的5个指标;
3、获取推荐指标所需数据:
对可供选择的n个同类酒店,从数据库中取出步骤1中所描述的每个酒店与该顾客偏好的契合程度的五个指标,将取出的数据按照步骤2中的描述,构建一个5*n的矩阵,作为算法的输入矩阵;
4、对前四行数据进行预处理:
经过步骤1-步骤3之后,获得了一个5*n的矩阵作为算法输入,但是因为只有前四行数据表示的该客户在某一酒店的客户入住时间、客户入住次数、客户入住单价、客户体验均分要作为输入做pca处理(相隔距离是一个辅助决策的指标,不作pca处理),因此需要对5*n的算法输入矩阵进行处理,提取出前四行构成一个4*n矩阵;对于此4*n矩阵,因为其每一行所表示的各指标的意义不同,数量级也相差较大,故在做下一步处理之前,要对数据进行白化预处理;
5、对经过步骤4预处理后的前四个指标数据,用pca算法处理,获得相应的特征值与特征向量;
6、根据特征值的大小情况来选取推荐策略:若获得的四个特征值都接近0(不大于0.1则认为接近0),则根据第五个指标相隔距离的排序结果,优先推荐相隔距离较小的酒店;若获得的四个特征值并不都接近0(不大于0.1则认为接近0),该情况则根据前四个指标pca主元评分的排序结果,推荐pca主元评分较大的酒店(和客户个人行为偏好契合度更高);
7、使用快速排序作为具体排序方法:
根据特征值的大小情况选定推荐策略,假如此处选择的推荐策略是依据第五个指标相隔距离大小推荐时,则对所有可选酒店的第五个指标相隔距离进行排序,得出具体哪个酒店距离客户更近,从而决定向该客户推荐哪家酒店;假如此处选择的推荐策略是根据pca评分推荐,则算法的下一步是对所有可选酒店的pca评分进行排序,得出具体哪个酒店的pca评分更高,进而决定推荐哪个酒店;
8、确定排序后的相隔距离或者pca评分对应着原始数据中的哪家酒店:由于单纯的快速排序只是把相隔距离或者pca评分从小排到大,实际上哪一个相隔距离或者pca评分对应于原数据中哪一家酒店,在上述排序中并未表现出来;所以需要另外生成一个与酒店数量相等的顺序序列数组,代表原始数据矩阵的下标,在步骤7中的快速排序中跟随其对应的数据移动,最后输出两个数组,第一个数组是进行升序排序后的可选酒店的第五个指标“相隔距离”或者pca评分数据,第二个数组是排序后的数据的所对应的原始下标;
9、算法的输出以及推荐策略选择:经过上述步骤,算法的输出是步骤8中所描述的两个数组,第一个数组表示每个酒店的pca评分或者相隔距离;第二个数组表示第一个数组的pca评分或者相隔距离所对应的酒店的序号;在实际应用时,根据选择的推荐策略,若是根据第五个指标“相隔距离”的排序结果,则优先选择第二个数组中第一个元素的序号对应的酒店作为推荐目标;若是根据前四个指标pca主元评分的排序结果,则优先推荐第二个数组中最后一个元素的序号对应的酒店。
进一步地,所述的步骤1中的客户入住时间为上一个周年内该客户入注某酒店的天数(单位为天);客户入住次数为在上一个周年内,该客户入住某酒店的累积次数(单位为次数);客户入住单价为在上一个周年内,该客户入住某酒店的平均单价(单位为元);客户体验均分为在上一个周年内,该客户对入住酒店的平均评分;相隔距离为当前客户所在位置与酒店的距离(单位为千米)。
进一步地,所述的步骤4中的白化预处理,希望通过白化过程使得学习算法的输入具有如下性质,即,特征之间相关性较低,所有特征具有相同的方差;因此,令xj(i)为4*n矩阵中的确切指标元素,i表示第i列,j表示第j行,n表示每行总共有n个数据,具体操作步骤如下:
4.1、对数据进行零均值化处理,令数据均值为0;对每一行数据,先令
4.2、对数据进行归一化处理,令数据方差为1;对每一行数据,先令
进一步地,所述的步骤6中的pca主元评分,其获取方法如下:将步骤5中求出的4*4特征向量记为
进一步地,所述的步骤7中快速排序的实现步骤如下:
7.1、假设有一个待排序的数组a[n],n表示数组a[n]的元素个数;如果数组a[n]的长度n不大于1(matlab中可用“length”接口取得一个数组的长度),则结束本步骤;如果数组a[n]的长度大于1,则执行如下操作:以数组a[n]的第一个元素为基准,记为a,a的位置记为k,从数组a[n]的第二个元素开始,依次遍历数组a[n],如果遍历到的元素比基准元素a大,则直接跳过该元素继续遍历下一个元素直到所有元素遍历结束;如果遍历到的元素比基准元素a小,则令k+1作为新的k值,将该大于基准元素a的元素与新k值所对应的元素交换,然后继续遍历下一个元素直至结束;待数组a[n]遍历完毕后,将数组a[n]的第一个元素a与新k值对应元素交换完成一轮排序;至此,数组a[n]中a左边的元素均小于元素a,a右边的元素均大于元素a;
7.2、将数组a[n]中a左边的所有元素构成的数组看成一个新的数组,数组a[n]中a右边的元素同样看成另一个新的数组,继续重复步奏a的操作。
采用上述结构后,本发明有益效果为:本发明所述的一种基于客户行为习惯偏好的个性化酒店智能推荐算法,解决衡量指标单一的问题;解决了针对客户个性化推荐的问题;增加第五个指标“相隔距离”在特殊情况下来辅助决策,使算法闭环,本发明具有结构简单,设置合理,制作成本低等优点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是具体实施方式的流程图。
图2是具体实施方根据“相隔距离”进行推荐的策略图。
图3是具体实施方式根据pca打分推荐的策略图。
具体实施方式
下面结合附图对本发明作进一步的说明。
参看如图1-图3所示,本具体实施方式采用的技术方案是:它的计算步骤如下:
1、确定针对客户的酒店推荐指标:
1.1、确定四个衡量酒店与客户的偏好契合程度的指标,即,客户入住时间——上一个周年内该客户入注某酒店的天数(单位为天);客户入住次数——在上一个周年内,该客户入住某酒店的累积次数,单位为次数;客户入住单价——在上一个周年内,该客户入住某酒店的平均单价,单位为元;客户体验均分——在上一个周年内,该客户对入住酒店的平均评分;
1.2、确定第五个指标,即,相隔距离——当前客户所在位置与酒店的距离,单位为千米,在上述四个指标都很相近的情况下,将会使用“相隔距离”来决定针对该顾客推荐哪个酒店,使算法闭环;
2、根据推荐指标构建算法输入矩阵:
在步骤1的描述中,每个酒店有五个指标,在此对每一个备选酒店构建一个5*1列向量,该5*1向量从上到下依次为客户入住时间、客户入住次数、客户入住单价、客户体验均分、相隔距离;如果有n个同类可选酒店,本实施例中n取8,表示有8家酒店参与推荐,这里就有n个5*1向量,把这n个5*1向量从左到右拼接起来,就得到了一个5*n矩阵,到此,算法输入矩阵构建完毕;该输入矩阵从行来看,第一行表示该客户上一周年在可选的n个酒店中各酒店入住的具体天数;第二行表示该客户上一周年在可选的n个酒店中各酒店入住的具体次数;第三行表示该客户上一周年在可选的n个酒店中各酒店入住的平均单价;以此类推;同时,该输入矩阵的每一列都表示该顾客选择一个酒店时的5个指标;
3、获取推荐指标所需数据:
对可供选择的8个同类酒店,从数据库中取出步骤1中所描述的每个酒店与该顾客偏好的契合程度的五个指标,将取出的数据按照步骤2中的描述,构建一个5*n的矩阵,作为算法的输入矩阵;
4、对前四行数据进行预处理:
经过步骤1-步骤3之后,获得了一个5*n的矩阵作为算法输入,但是因为只有前四行数据表示的该客户在某一酒店的客户入住时间、客户入住次数、客户入住单价、客户体验均分要作为输入做pca处理(相隔距离是一个辅助决策的指标,不作pca处理),因此需要对5*n的算法输入矩阵进行处理,提取出前四行构成一个4*n矩阵;对于此4*n矩阵,因为其每一行所表示的各指标的意义不同,数量级也相差较大,故在做下一步处理之前,要对数据进行白化预处理;希望通过白化过程使得学习算法的输入具有如下性质,即,特征之间相关性较低,所有特征具有相同的方差;因此,令xj(i)为4*n矩阵中的确切指标元素,i表示第i列,j表示第j行,n表示每行总共有n个数据,具体操作步骤如下:
4.1、对数据进行零均值化处理,令数据均值为0;对每一行数据,先令
4.2、对数据进行归一化处理,令数据方差为1;对每一行数据,先令
5、对经过步骤4预处理后的前四个指标数据,用pca算法处理,获得相应的特征值与特征向量;
6、根据特征值的大小情况来选取推荐策略:推荐策略一:当所选的四个指标的特征值都接近于0,即都不大于0.1的时候,表示可选推荐的每个酒店四个指标的值都很接近,此时根据第五个指标“相隔距离”来决定优先推荐哪个酒店;如附图二所示,“data”表示获取的某顾客的入住酒店初始数据,“latent”表示前四行数据的特征值,此时前四行数据的特征值均接近于0,因此此时根据第五个指标“相隔距离”进行酒店推荐,由相隔距离排序可知,第5家酒店相隔距离最近,此时优先推荐第5家酒店。
推荐策略二:若上述所选的四个指标的特征值不都小于0.1的情况,则使用pca评分来决定优先推荐哪家酒店。如图三所示,“latent”表示的前四行数据的特征值并不都接近于0,此时采用pca评分进行推荐,由pca评分排序可知,第4家酒店pca评分最高,表示与顾客行为习惯偏好契合度最高,此时针对该顾客优先推荐第4家酒店;
获取pca主元评分的方法如下:将步骤5中求出的4*4特征向量记为
7、使用快速排序作为具体排序方法:
根据特征值的大小情况选定推荐策略,假如此处选择的推荐策略是依据第五个指标相隔距离大小推荐时,则对所有可选酒店的第五个指标相隔距离进行排序,得出具体哪个酒店距离客户更近,从而决定向该客户推荐哪家酒店;假如此处选择的推荐策略是根据pca评分推荐,则算法的下一步是对所有可选酒店的pca评分进行排序,得出具体哪个酒店的pca评分更高,进而决定推荐哪个酒店;快速排序的实现步骤如下:
7.1、假设有一个待排序的数组a[n],n表示数组a[n]的元素个数;如果数组a[n]的长度n不大于1(matlab中可用“length”接口取得一个数组的长度),则结束本步骤;如果数组a[n]的长度大于1,则执行如下操作:以数组a[n]的第一个元素为基准,记为a,a的位置记为k,从数组a[n]的第二个元素开始,依次遍历数组a[n],如果遍历到的元素比基准元素a大,则直接跳过该元素继续遍历下一个元素直到所有元素遍历结束;如果遍历到的元素比基准元素a小,则令k+1作为新的k值,将该大于基准元素a的元素与新k值所对应的元素交换,然后继续遍历下一个元素直至结束;待数组a[n]遍历完毕后,将数组a[n]的第一个元素a与新k值对应元素交换完成一轮排序;至此,数组a[n]中a左边的元素均小于元素a,a右边的元素均大于元素a;
7.2、将数组a[n]中a左边的所有元素构成的数组看成一个新的数组,数组a[n]中a右边的元素同样看成另一个新的数组,继续重复步奏a的操作;
8、确定排序后的相隔距离或者pca评分对应着原始数据中的哪家酒店:由于单纯的快速排序只是把相隔距离或者pca评分从小排到大,实际上哪一个相隔距离或者pca评分对应于原数据中哪一家酒店,在上述排序中并未表现出来;所以需要另外生成一个与酒店数量相等的顺序序列数组,代表原始数据矩阵的下标,在步骤7中的快速排序中跟随其对应的数据移动,最后输出两个数组,第一个数组是进行升序排序后的可选酒店的第五个指标“相隔距离”或者pca评分数据,第二个数组是排序后的数据的所对应的原始下标;
9、算法的输出以及推荐策略选择:经过上述步骤,算法的输出是步骤8中所描述的两个数组,第一个数组表示每个酒店的pca评分或者相隔距离(pca评分或者等待时间,如图三“scores”);第二个数组表示第一个数组的pca评分或者相隔距离所对应的酒店的序号;在实际应用时,根据选择的推荐策略,若是根据第五个指标“相隔距离”的排序结果,则优先选择第二个数组中第一个元素的序号对应的酒店作为推荐目标;若是根据前四个指标pca主元评分的排序结果,则优先推荐第二个数组中最后一个元素的序号对应的酒店。不论是根据“相隔距离”进行推荐,还是根据pca评分进行推荐,都需要对数据进行排序。本发明采用“发明内容”中步骤7所述的快速排序方法,以及步骤8所述的对原始数据下标的特殊处理,得到了图二和图三所示的仿真结果。该仿真结果中,“scores”表示升序排序的数据,“number”表示“scores”在原始数据矩阵中的下标,用以标识“scores”对应着实际的哪一个酒店。故可直接使用“number”中的下标推荐酒店,并且在此场景下,若确定的推荐策略是依据第五个指标“相隔距离”,则“scores”评分越小的酒店越被优先推荐,即“number”中越靠前的下标所对应的酒店越被优先推荐;若使用pca评分来决定优先推荐哪家酒店,则“scores”评分越大的酒店越被优先推荐,即“number”中越靠后的下标所对应的酒店越被优先推荐.
采用上述结构后,本具体实施方式有益效果为:
1、多指标衡量推荐酒店与客户行为习惯偏好的契合程度,解决衡量指标单一的问题;
2、合理选择客户入住时间、客户入住次数、客户入住单价、客户体验均分四个指标,从四个维度分析客户选择酒店的行为习惯偏好,解决了针对客户个性化推荐的问题;
3、增加第五个指标“相隔距离”在特殊情况下来辅助决策,使算法闭环。
以上所述,仅用以说明本发明的技术方案而非限制,本领域普通技术人员对本发明的技术方案所做的其它修改或者等同替换,只要不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!