一种基于监控视频的行人视力状况调查分析方法与流程
本发明涉及视频分析领域中的行人性别、戴眼镜与否的人脸属性分析问题,尤其是涉及一种基于监控视频的行人视力状况调查分析方法。
背景技术:
健康城市的发展以实现人的全面、健康发展为目标。视力是群体健康的重要指标,然而现代生活方式、环境等因素导致人群群体的视力障碍(包括常见的近视、远视、散光、弱视等)发生率呈现上升趋势。据调查到2050年,近视将对全世界50亿人造成不同程度的负面影响,近视不仅影响国防和航空等特殊人才的选拔,而且容易造成眼病给生活带来不便。调查城市群体的视力状况有助于掌握群体健康的基本情况,制定针对性的政策和措施,为健康城市的建设打下基础。人脸属性是表征人脸特征的一系列生物特性,具有很强的自身稳定性和个体差异性,标识了人的身份。本发明主要针对人脸属性中的性别、戴眼镜与否属性进行分析。
近些年统计视力健康的方法,主要采用以下几种:针对某一特定群体进行普查、在医院门诊收集视力信息、对某群体分层抽样收集视力信息、使用问卷调查的方式收集视力信息。以上方法,普查会耗费大量的人力物力;门诊中收集个人信息涉及隐私会带来诸多不便;分层随机抽样的方法需要对样本总体情况进行了解;问卷调查存在虚假填写的情况。视力障碍群体分布广泛、人数众多,使用上述方法调查难度大,取样困难。
深度学习在图像处理领域的广泛运用,促进了行人人脸属性分析的进一步发展。但是传统的行人识别技术仅仅将行人从监控视频中提取出来,并未对人物目标进一步分析,提取更为丰富的视觉信息。为了解决公共空间调查视力状况困难的问题,本发明利用视频分析技术识别监控视频中行人性别、戴眼镜与否的人脸属性,采用改进的人脸分析卷积神经网络提高性别识别和戴眼镜识别的准确率,最终经过数据量化,在web端进行数据可视化展示。该方法给研究人员调查群体健康节省了巨大的工作量,提供了重要的数据支撑,并为调查领域研究群体健康提供了新思路。
技术实现要素:
本发明的目的是提供一种监控视频中行人视力状况调查分析的方法,将深度学习与视频人脸属性相结合,充分发挥深度学习自我学习的优势,可以解决目前研究人员调查群体健康工作量大的问题。
为了方便说明,首先引入如下概念:
卷积神经网络(cnn):受视觉神经机制的启发而设计的,是为识别二维形状而设计的一种多层感知器,这种网络结构对平移、比例缩放、倾斜或者其他形式的变形具有高度不变性。
跨连的卷积神经网络(ccnn)模型:该模型是一个9层的网络结构,包含输入层、6个由卷积层和池化层交错构成的隐含层、全连接层和输出层,其中允许第2个池化层跨过两个层直接与全连接层相连接。
caffe框架:一个清晰而高效的深度学习框架。caffe中的网络都是有向无环图的集合,数据及其导数以blobs的形式在层间流动,主要应用在视频、图像处理方面。
mtcnn算法:一种三阶级联架构方式的快速卷积神经网络算法。该算法共有三个阶段:首先通过浅层cnn快速产生大量的候选框;然后利用更加复杂的cnn精炼候选框,丢弃大量无人脸的候选框;最后使用更加强大的cnn实现最终人脸候选框的选择,并输出五个人脸面部关键点位置。
angularjs:一款优秀的前端js框架,最为核心的是:mvw(model-view-whatever)、模块化、自动化双向数据绑定、语义化标签、依赖注入等等。
django:一个由python写成的开放源代码的web应用框架,采用了mtv的框架模式,即模型model,模板template和视图views。
数据集:其中包括性别数据集,戴眼镜与否数据集。
本发明具体采用如下技术方案:
提出了一种基于监控视频的行人视力状况调查分析方法,该方法的主要特征在于:
1).采用融合浅层信息与深层信息特征的思路改进跨连的卷积神经网络ccnn;
2).采用同一网络分别识别性别、戴眼镜与否这两种人脸属性;
3).采用web端进行数据可视化;
该方法主要包括以下步骤:
(1)将浅层卷积层特征与最后卷积层特征输出进行融合,并将中间池化层信息与深层池化层信息进行融合,即为改进的ccnn网络;
(2)使用一种三阶级联架构方式的快速卷积神经网络算法mtcnn检测行人人脸,制作相应的数据集,使用改进的ccnn网络分别进行性别、戴眼镜与否两种人脸属性的识别;
(3)将步骤(2)中所得到的人脸属性数据进行量化并存储在数据库中,其中包含数据信息表和人脸属性信息表;
(4)取出数据库中的数据信息,在web端分街道和区域进行数据可视化展示。
优选地,步骤(1)中采用融合的方式增强输入到全连接层的语义信息。
优选地,步骤(2)中性别识别和戴眼镜识别使用改进的ccnn网络分开训练,得到两种不同的训练模型,用训练好的模型对性别、戴眼镜与否进行识别。
优选地,步骤(3)中数据信息表用于记录关注街道摄像头的信息,包含摄像头的id号、地理位置经纬度、街道名、关注街道的时间和所属地区;人脸属性信息表用于记录当前摄像头数据经过处理量化后的相关信息,具体包含对应时间、对应时间的行人数量、对应时间的男性数量、对应时间的女性数量、对应时间的男性戴眼镜和未戴眼镜数量、对应时间的女性戴眼镜和未戴眼镜数量。
本发明的有益效果是:
(1)充分发挥深度学习的自我学习优势,机器自动学习良好的特征。当输入人脸图片时能够快速准确地提取特征,避免了人工提取特征的局限性,适应能力更强。
(2)改进的ccnn网络在自制数据集训练过程中,能从训练样本很好的学习到人脸的特征,并且训练取得较好的收敛效果,从而进一步提高性别识别和戴眼镜识别的准确率。
(3)将深度学习与行人人脸属性相结合,识别行人性别以及戴眼镜与否的人脸属性,可以减轻研究人员调查群体健康的工作量并为其提供重要的数据支撑。
(4)将行人的人脸属性信息量化后在地图上展示,地图服务能直观清楚的展示公共空间中行人的视力状况信息,推进了群体健康调查领域技术的发展,为调查工作提供了新思路。
附图说明
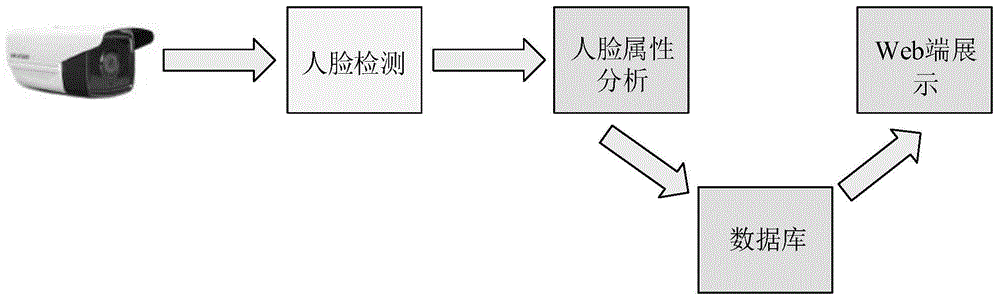
图1为本发明的系统方案示意图;
图2为人脸分析卷积神经网络结构示意图;
图3为标准数据集与自制数据集的对比图;
图4为本发明所提的自制数据集;
图5为本发明所提的一种web端整体展示效果图。
具体实施方式
下面通过实例对本发明作进一步的详细说明,有必要指出的是,以下的实施例只用于对本发明做进一步的说明,不能理解为对本发明保护范围的限制,所属领域技术熟悉人员根据上述发明内容,对本发明做出一些非本质的改进和调整进行具体实施,应仍属于本发明的保护范围。
图1中,基于监控视频的行人视力状况调查分析方法,具体包括以下步骤:
(1)获取监控视频,在ubuntu16.04系统下利用mtcnn算法对监控视频中的行人人脸进行检测,输出所检测人脸的面部关键点位置,保存人脸图像。
(2)由于人脸数量过多会影响处理效率,因此对跨连的卷积神经网络(cross-connectedcnn,ccnn)进行改进,将浅层卷积层的特征输出与最后卷积层特征输出结合,融合多层卷积的特征,再将融合层进行池化,将中间池化层的信息与深层池化层信息相连,利用融合的方式增强输入到全连接层的语义信息,最后经全连接层对融合的特征信息分类送至输出层。改进的网络包含3个卷积层,3个池化层,2个融合层,2个全连接层。
(3)在步骤(1)的基础上制作相应数据集,本发明自制的数据集与公开数据集相比,自制数据集分辨率低,且具有俯拍视角的特性。将数据集按8:1:1的比例分为训练集、测试集和验证集,并制作数据标签。
(4)对检测到的人脸进行性别、戴眼镜与否的人脸属性分析:在本发明所建立数据集的基础上进行训练,训练平台为ubuntu16.04,使用框架为caffe。改进的ccnn网络在自制数据集训练过程中,能从训练样本很好的学习到人脸特征,并且训练取得较好的收敛效果。
(5)将步骤(4)中分析所得人脸属性信息进行量化,量化后的信息存储在数据库中。人脸属性信息包括性别信息、戴眼镜与否的信息。
(6)从数据库中获取人脸属性分析量化后的信息,在web端对其进行展示,展示内容主要包括单条街道或者某区域的人群视力障碍数量和性别比例。
- 还没有人留言评论。精彩留言会获得点赞!