一种深度强化学习加速训练的方法与流程
本发明属于计算机领域,特别涉及一种基于cpu+fpga平台的深度强化学习训练加速方法。
背景技术:
深度强化学习算法,是一种将深度学习的感知能力和强化学习的决策能力相结合的算法,通过端对端的学习方式实现从原始输入到输出的控制。该算法在工业制造、仿真模拟、机器人控制、优化与调度、游戏博弈等领域有广泛应用。
文献(mnihv,kavukcuogluk,silverd,etal.playingatariwithdeepreinforcementlearning//proceedingsofworkshopsatthe26thneuralinformationprocessingsystems2013.laketahoe,usa,2013:201-220)首次提出深度强化学习(deepreinforcementlearning)的概念,并发明了首个深度强化学习算法dqn。随着使用深度强化学习技术的alphago在围棋领域大杀四方,越来越多的研究被投入到该领域中,许多优异的深度强化学习算法被陆续提出,算法的复杂度也与日俱增,需要强大的计算能力的支持。
在dqn算法中,q网络为深度神经网络用于评价状态s下的动作q值,q值即评价该动作的值,通过ε-贪婪策略与环境交互产生数据放入经验池中,从中随机抽取数据进行训练,可以打破数据间的关联;设置目标网络计算td值来训练评价网络,提升了算法的稳定性。
目前,业界普遍使用cpu+gpu的硬件架构完成深度学习和深度强化学习的训练与部署,cpu用于数据的传输控制,gpu用于大吞吐量的并行计算,但是gpu存在能耗高的缺点,且难以在终端设备中部署。越来越多的研究投入到低功耗、高效率的计算设备中。
fpga(fieldprogrammablegatearrays),即现场可编程门阵列,是一种高性能、低功耗、可编程的数字电路芯片。fpga既有像专用集成电路(asic)的高速稳定的优势,又有可重复定制电路结构的灵活性。fpga内部含有大量可编程逻辑块(clb)和金属互连线,此外还包含数字信号处理单元(dsp)、块随机存储器(bram)等模块。fpga作为一种新兴的加速设备,拥有低功耗、可重配置等优点,特别适合用于深度强化学习的加速训练。
文献(j.su,j.liu,d.b.thomas,andp.y.cheung.neuralnetworkbasedreinforcementlearningaccelerationonfpgaplatforms//acmsigarchcomputerarchitecturenews,vol.44,no.4,pp.68-73,2017)提出了一种用于神经网络q学习的fpga加速系统设计,通过神经演化算法动态地重构网络,该系统只针对fpga平台,将网络参数和梯度存放在bram中,限制了网络的深度,且没有使用目标网络。文献(梁明兰,王峥,陈名松.基于可重构阵列架构的强化学习计算引擎//集成技术,vol.7,no.6,nov.2018)提出了基于粗粒度可重构阵列架构的强化学习神经网络计算引擎,具有功耗低、处理速度快的优点,但是没有涉及对经验池的优化加速和使用目标网络。
技术实现要素:
本发明的目的在于针对上述现有问题,提出一种深度强化学习的训练方法,能够在cpu+fpga的异构计算平台上,完成对深度强化学习算法的训练以及验证,同时加入经验池和目标网络的方法。
本发明提供一种深度强化学习算法在cpu+fpga平台下的训练方法,所述方法包括:
1)在cpu+fpga平台下,cpu运行强化学习交互环境同时作为控制设备,fpga作为计算设备,分别运行评价网络、目标网络以及为采集数据使用的动作网络,fpga通过数据传输总线与cpu和内存进行通信。
2)分配cpu和fpga都可以访问的共享内存,内存中包括网络参数和经验池数据,其中fpga读写网络参数,cpu读写经验池数据。
3)其中fpga包含三种网络,动作网络只用来做前向计算,评价网络用于前向计算和反向传播计算,评价网络的输入为batch规模的状态(s),batch规模指多个样本组成一个batch,动作网络的输入为单个状态,评价网络与动作网络共享相同的权重参数(ω),动作网络仅读取该参数,评价网络需读写该参数。目标网络与评价网络结构相同,输入为batch规模数据,用于前向计算,需要读取内存中的权重(ω-)。
4)cpu同时运行两个进程,进程一用于环境交互与数据采集,进程二用于神经网络的训练,两个进程可以完全并行执行。
5)进程一运行强化学习的交互环境,将当前状态输入至动作网络,返回动作q值选择动作(a),输入动作至交互环境返回新状态值(s’)和奖励值(r),将数据以<s,a,r,s’>保存至内存中的经验池。
6)进程二从内存中抽取batch规模的数据,输入状态s’至目标网络返回目标q值,通过贝尔曼方程计算目标td值,将状态s作为输入,目标td值作为标签去训练评价网络参数,其中目标q值的计算和评价网络的训练均在fpga上进行实现。
7)在fpga上运行的神经网络可以为多种形式的神经网络,如全连接神经网络(fully-connectednetwork,fc)、卷积神经网络(convolutionalneuralnetwork,cnn)、循环神经网络(recurrentneuralnetwork,rnn),根据不同网络的前向和反向传播计算方式,通过硬件语言描述或者通过高级综合工具使用高级语言进行描述,这些描述方法不在本发明的范围内。
本发明的优点主要包括:
1.本发明方法具备通用性,能够适用多种基于dqn的深度强化学习算法的加速;
2.本发明能高效利用内存,能够运行于低功耗终端设备;
3.本发明将采集数据与训练并行执行,实现了经验池和目标网络方法。
附图说明
图1为本发明的技术方案实施流程图;
图2为fpga中运行的网络结构示意图;
图3为cpu、fpga、内存的数据交互示意图;
图4为内存的分配示意图;
图5为cpu与fpga内的神经网络数据交互示意图;
具体实施方式
以下结合附图对本发明的方法做进一步说明:
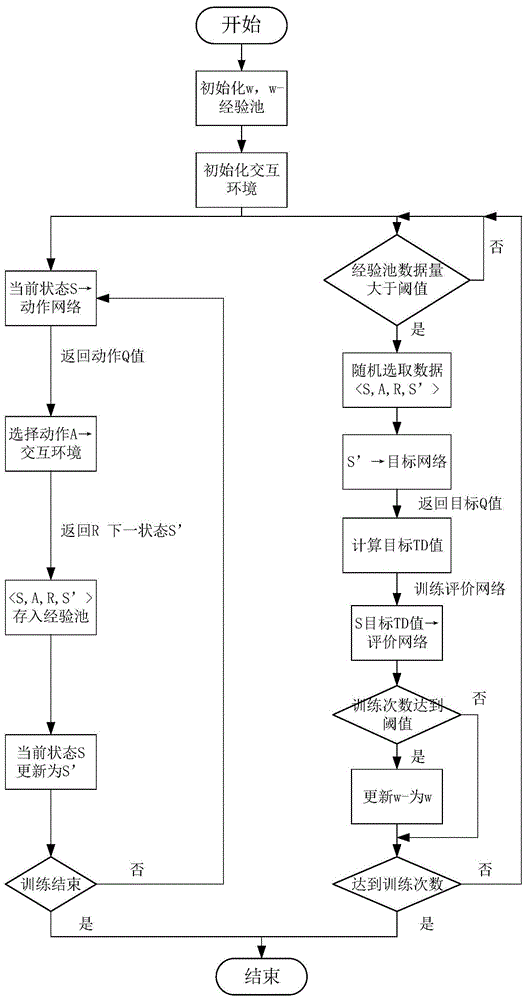
图1所示为本发明实施的基于cpu+fpga平台的深度强化学习训练方法实现流程,包括以下步骤:
1)首先,在内存中固定位置开辟空间存放参数ω、ω-以及经验池,使用cpu产生随机数对内存中的神经网络参数ω和ω-进行初始化,然后对运行在cpu中的交互环境初始化,产生初始状态s为当前状态;
2)然后,计算平台运行两个进程并行进行,图2为运行于fpga的网络结构示意图。进程一用于强化学习中的探索与利用进行数据集的采集,将当前状态输入到运行于fpga的动作网络,根据返回的动作q值,使用ε-贪婪策略(ε-greedy)选取动作a输入至交互环境,交互环境返回奖励值r及下一状态s’,将数据<s,a,r,s’>的顺序为一个样本存入内存中的经验池中;
3)进程二进行对评价网络参数的训练,当经验池中的数据量大于预定的阈值时,cpu从经验池中随机抽取出batch规模数据,将状态s’输入至运行于fpga的目标网络,返回目标q值,根据贝尔曼方程在cpu中计算出
4)每训练达到预定的次数,将内存中的参数ω-更新为ω,参数ω为动作网络和评价网络所使用,目标网络使用的参数为ω-,图4所示为内存的分配方式,参数ω和ω-使用固定位置,fpga可以直接通过数据传输总线进行参数的读写;
5)达到指定的训练次数或交互环境返回的奖励值达到预期,则任务结束。
对于一些在fpga内部无法完成的操作,如神经网络的初始化、从经验池选取数据,均需要产生随机数,因此将这部分操作放在cpu上进行。此外,对于位于内存固定位置的参数ω-的更新,通过fpga可编程逻辑电路完成。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!