一种基于图像输入的机器人主动学习方法与流程
本发明属于人工智能技术领域,更具体地,涉及一种基于图像输入的机器人主动学习方法。
背景技术:
近些年来,随着计算力的提高和深度学习算法的不断发展,数据驱动的方法在机器人领域中大放异彩。数据驱动的方法通常需要采集大量的数据,才能较好地训练深度神经网络模型,控制机器人完成相应的任务。不同于其他领域,使用真实机器人采集数据不仅代价高昂,耗时耗力,还会不可避免出现物理损耗,甚至可能产生危险。受限于实际条件,通常不可能使用真实的机器人在现实环境中采集大量的数据。因此急需找到一些方法来减少数据驱动方法所需的真实环境数据的数据量,或者用仿真环境数据代替真实环境数据来训练模型,最后再迁移到真实机器人上。
机器人学习领域的研究方向主要分为监督学习和强化学习两个方向。监督学习通过采集大量的数据并进行标注,用来训练网络,按照标注数据的方法,又可以细分为自监督学习、模仿学习等方向;强化学习方法是通过机器人在环境中进行大量的随机探索来学会完成指定的任务。
主动学习通过对未标注的数据进行筛选,可以利用少量的标注数据取得较高的学习准确度。主动学习通过某种选择策略从数据集中寻找未标注的数据让专家进行标注,被选中的数据是最具有学习价值的数据,用这样的标注样本进行学习,是最高效的学习。通过不断的选择数据、进行标注和训练网络,直至满足终止条件,能够以最少的标注样本得到效果优良的模型。
a.zengetal.roboticpick-and-placeofnovelobjectsinclutterwithmulti-affordancegraspingandcross-domainimagematching通过人工来标注真实环境采集的图片数据,对于每张rgb-d的图像,手动地标注出可供抓取的位置。使用这些数据训练全卷积深度神经网络,测试时输入rgb-d图片,输出对应的相应图(responsemap),在图中亮度最高的点即为应当执行抓取的点。该方法使用可受性(affordace)的概念来解决抓取问题,对见过和未见过的物体都有较高的抓取成功率,在物体堆叠的情况下也有较高的抓取成功率,泛化能力强。
konyushkovaetal.learningactivelearningfromdata首次提出了学习一个选择策略来选择标注数据的方法,而不是使用手工设计的特征。该方法将选择策略看作一个回归问题,通过数据集来学习一个效果良好的回归网络,通过网络来选择需要标注的数据,并且证明了该方法适用于多个领域.
监督学习需要采集大量的数据并进行标注来训练网络,缺点是对大量的数据进行标注耗时耗力,而且对于多解的问题不可能标注所有的解;自监督学习往往需要机械臂进行大量的试错实验,采集的样本成功率较低,效率不高,需要大量的人力物力;强化学习方法是通过机器人在指定的环境中进行大量的探索来学会完成指定的任务,缺点是需要的探索次数非常多,且随机的探索容易产生危险,在现实中几乎不可能完成。
a.zengetal.roboticpick-and-placeofnovelobjectsinclutterwithmulti-affordancegraspingandcross-domainimagematching采集大量真实环境的图片,通过人工来标注数据,需要花费大量的时间和资源;该方法需要一套带有四个摄像头的rgb-d图片采集系统,对抓取的环境有较高的要求;该方法是一种开环的抓取方法,没有充分利用信息实现闭环抓取;该方法对于模型不能抓取的物体没有提出进一步的解决方法,不能持续地提高成功率。
在机器人领域上,现有的主动学习方法的选择策略大多是手工设计的特征,通过这些特征让机器人判断当前状态是否需要示教。手工设计的特征泛化性能较差,不仅无法多种任务通用,对于同一个任务也容易出现虚警和漏警。k.konyushkovaetal.learningactivelearningfromdata提出的学习一个回归网络来作为选择策略的方法无法直接应用在机器人领域。在真实的机器人操作中,机器人与环境是不断地进行实时交互的,选择策略所面对的数据集并不是一个已存在的确定的数据集,任务不是从已有的数据集中挑选数据进行标注;而是面对一个动态增长的数据集,任务是判断一个全新的场景是否需要标注。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于图像输入的机器人主动学习方法,以提高机器人主动学习的效果。
为解决上述技术问题,本发明采用的技术方案是:一种基于图像输入的机器人主动学习方法,包括以下步骤:
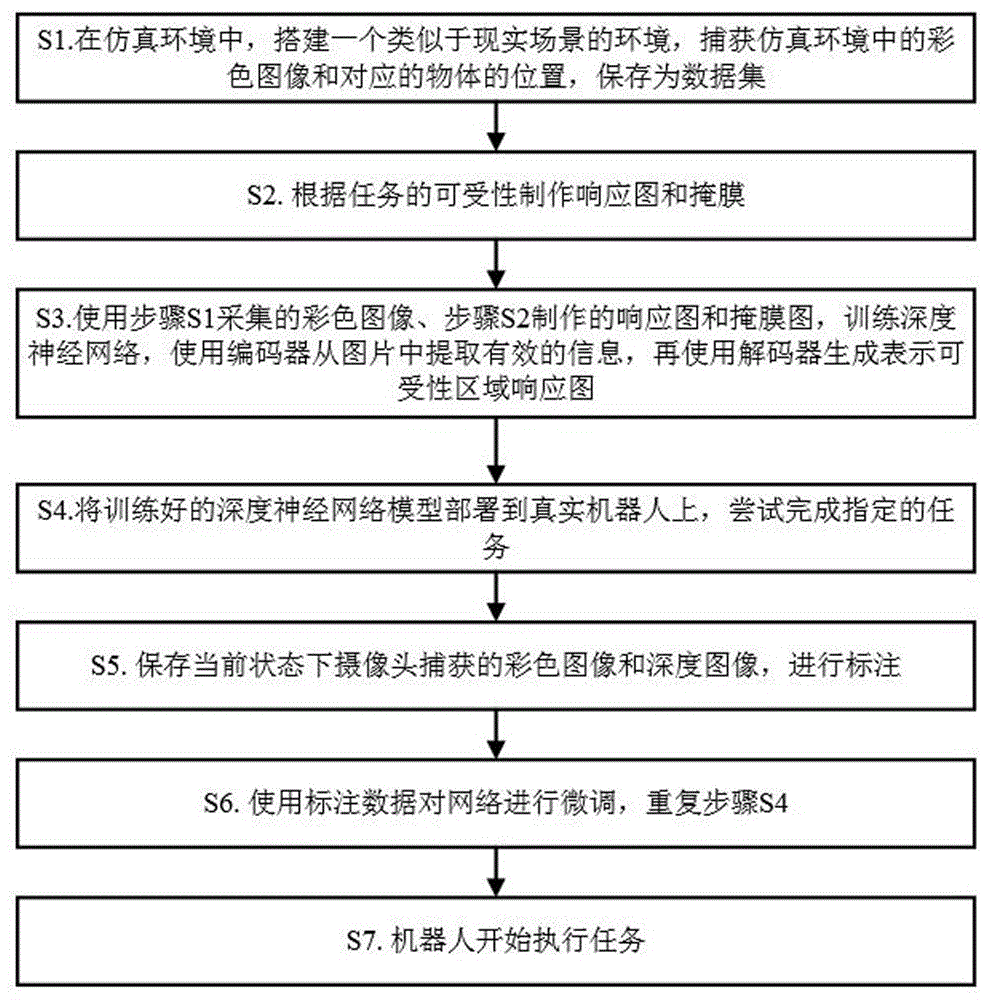
s1.在仿真环境中,搭建一个类似于现实场景的环境,捕获仿真环境中的彩色图像和对应的物体的位置,保存为数据集;
s2.根据任务的可受性制作响应图和掩膜;
s3.使用步骤s1采集的彩色图像、步骤s2制作的响应图和掩膜图,训练深度神经网络,使用编码器从图片中提取有效的信息,再使用解码器生成表示可受性区域响应图;
s4.将训练好的深度神经网络模型部署到真实机器人上,尝试完成指定的任务;
s5.保存当前状态下摄像头捕获的彩色图像和深度图像,进行标注;
s6.使用标注数据对网络进行微调,重复步骤s4;
s7.机器人开始执行任务。
进一步的,所述的s1步骤具体包括:
s11.在场景中放置一张桌子,桌子上摆放了机器人、摄像头和一些物体;
s12.在仿真器中,随机设置桌子和地板的颜色,随机选择一个或多个物体摆放在桌子上,随机产生物体摆放的位置,随机改变物体的颜色和纹理,随机改变环境的光照强度;
s13.记录摄像头捕获的彩色图像和对应的物体的位置,保存为数据集。
进一步的,所述的s2步骤具体包括:
s21.根据任务的特点,计算对于指定任务下物体的可受性区域,对于抓取任务,可受性区域为物体的几何中心点;对于推动任务,可受性区域为终点物体与起点物体的连线的延长线某一区域处;
s22.根据可受性区域,制作响应图,在图上表示为一个服从高斯分布的高亮圆形,圆心的位置即为可受性区域的中心位置;
s23.根据可受性区域,制作掩膜图,在图上表示为一个服从高斯分布的高亮圆形,圆心的位置即为可受性区域的中心位置,半径比响应图的圆形要大。
进一步的,所述的s3步骤具体包括:
s31.对输入到网络的图片进行归一化,归一化后图像像素值的范围是(-1,1);
s32.网络使用adam优化器进行梯度下降,学习率设定为10e-4,mini-batch设定为32,所有参数均随机初始化;
s33.编码器由4个卷积层组成,在每个卷积层后均跟有池化层和批标准化层;每个卷积层都使用4*4的卷积核,步长为2,使用leaky_relu函数作为激活函数;解码器由4个反卷积层组成,在每个反卷积层后均跟有批标准化层;反卷积层使用4*4的卷积核,步长为2;最后一个反卷积层使用tanh作为激活函数,其余层均使用leaky_relu函数作为激活函数;
s34.网络输出的响应图记为o,制作的响应图记为y,掩膜图记为m,网络的损失函数定义为:
进一步的,所述的s4步骤具体包括:
s41.摄像头拍摄当前场景的彩色图像,将该图像进行步骤s31所述的归一化后输入到网络中;网络将会输出对应的响应图;
s42.计算输出的响应图的交叉熵,比较交叉熵和阈值大小的关系,判断能否完成任务;若交叉熵的值大于阈值,机器人能执行该任务,跳到步骤7;若交叉熵的值小于阈值机器人无法执行任务,跳到步骤5。
进一步的,所述的s5步骤具体包括:
s51.将未摆放物体的场景深度图记为d1,已摆放物体的场景深度图记为d2,通过d=d2-d1可以得到物体的位置信息;使用中值滤波、膨胀、腐蚀方法对d进行处理,去除噪声;
s52.寻找d中所有面积较大的轮廓,并计算轮廓的矩,得到轮廓的中心点位置,即为物体的位置。使用轮廓信息和中心点信息,可以描述物体的形状和位置。
进一步的,所述的s6步骤具体包括:
s61.通过步骤s5的标注,使用与步骤s2相同的方法制作响应图和掩膜图;
s62.使用步骤s5的彩色图像、步骤s61制作的响应图和掩膜图,训练深度神经网络,使用编码器从图片中提取有效的信息,再使用解码器生成表示可受性区域响应图;
s63.对输入到网络的图片进行归一化,归一化后图像像素值的范围是(-1,1);
s64.网络使用adam优化器进行梯度下降,学习率设定为10e-5,mini-batch设定为32,所有参数均随机初始化;
s65.编码器由4个卷积层组成,在每个卷积层后均跟有池化层和批标准化层;每个卷积层都使用4*4的卷积核,步长为2,使用leaky_relu函数作为激活函数;解码器由4个反卷积层组成,在每个反卷积层后均跟有批标准化层;反卷积层使用4*4的卷积核,步长为2;最后一个反卷积层使用tanh作为激活函数,其余层均使用leaky_relu函数作为激活函数;
s66.网络输出的响应图记为o,制作的响应图记为y,掩膜图记为m,网络的损失函数定义为:
进一步的,所述的s7步骤具体包括:
s71.寻找响应图上亮度最高的点,该点的位置表示物体可受性区域的位置;将该点的坐标映射到机器人坐标空间中,该位置即为机器人坐标系中物体的可受性区域的位置;
s72.机械臂移动到指定位置,执行指定任务。
与现有技术相比,有益效果是:
1.本发明在仿真环境中采集数据,避免了在现实环境中采集数据时可能遇到的问题:耗时耗力、出现物理损耗、可能出现危险。在仿真环境中采集数据,速度很快、不需要人工进行标注,能够避免使用真实机器人导致的物理损耗和潜在不安全因素,可以制作足够大的数据集;
2.本发明运用可受性区域(affordance)的概念,使深度模型不再过于关注物体的形状、纹理和颜色等表面特征,而是把更多的注意力放在发掘完成任务的affordance上。通过制作响应图作为标签,使得深度网络能够学会affordance的概念,对于不同的物体、不同的场景,都能完成指定的任务,泛化能力非常强。本发明仅使用仿真数据训练模型,训练后模型可以直接迁移到真实环境中;其他使用仿真数据训练的方法,在迁移到真实环境中往往需要加入一些真实数据,对模型进行微调。
3.本发明将主动学习的方法应用于机器人领域,通过主动学习来采集数据非常高效,可以有效地减少深度学习所需要的数据量。主动学习的机制不仅使机器人具备了增量学习和终身学习的能力,也从另一方面提升了机器人的安全性能。本发明通过响应图作为主动学习的选择策略,判断当前情况下是否需要示教。使用响应图的交叉熵作为选择策略,比其他方法使用手工设计的特征作为选择策略更为准确,减少了误警和虚警。本发明的现实环境数据标注方法可以大大加快标注速度,减少人力物力的消耗,能够全自动地完成标注。本发明的主动学习方法不仅适用于机器人领域,也适用于其他计算机视觉相关领域。
附图说明
图1是本发明方法流程图。
图2是本发明实施例中的网络结构是示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本发明的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本发明的限制。
实施例1:
本发明提出一种基于图像输入的机器人主动学习方法,可以通过在仿真环境中采集少量的数据,训练一个效果良好的深度神经网络,并且能够直接迁移到真实环境之中。在真实环境执行任务时,机器人能够自行准确判断自己能否完成该任务,如果不能完成,将申请专家进行示教,通过示教信息微调模型,实现增量学习,直至能够完成所有相似的任务。包括以下阶段:
1.仿真数据采集:
在仿真环境中,搭建一个类似于现实场景的环境。在桌面上随机放置物体,在桌面上方设置摄像头,记录下摄像头捕获的图像和物体的坐标。然后计算完成某个指定任务时机械臂需要到达的可受性区域(affordance)。假设机械臂的任务是把物体a推动到物体b所在的位置使它们互相接触,在该任务中应当到达的可受性区域(affordance)是a物体和b物体的连线的延长线上距离a物体较近的一点。制作标签图像时,将该点标为高亮,其余点标为黑色;制作掩膜图像时,将该点附近标为高亮,其余点标为黑色。采集数据时,需要随机指定物体的位置,需要更换多种不同形状的物体,需要更换桌子背景的颜色。
2.网络结构和训练方法:
本发明使用编码器从图片中提取有效的信息,再使用解码器恢复成响应图(responsemap)。本发明中,编码器由4个卷积层组成,在每个卷积层后均跟有池化层和批标准化层(batchnormalization)。每个卷积层都使用4*4的卷积核,步长为2,使用leaky_relu函数作为激活函数。解码器由4个反卷积层组成,在每个反卷积层后均跟有批标准化层。反卷积层使用4*4的卷积核,步长为2。最后一个反卷积层使用tanh作为激活函数,其余层均使用leaky_relu函数作为激活函数。输入到编码器的图片需要提前进行归一化。
本发明使用掩膜图像对损失函数进行加权,以此将网络的注意力更多地集中在响应图高亮的部分,减少背景图像的影响。假设标签响应图记为y,网络输出的图片记为i,掩膜图片记为m,网络的损失函数可表示为:
网络使用adam优化器进行梯度下降,学习率设定为10e-4,mini-batch的大小是32,所有参数均随机初始化。
3.主动学习阶段——真实机器人测试与真实数据采集:
使用仿真产生的数据训练网络,训练完毕后,输入真实环境的图片,能够准确地预测响应图。响应图表示的是网络模型认为机器人应该移动到图中的哪个位置去执行当前任务,亮度越大的位置表示置信度越高,亮度越低的表示置信度越低。因此,可以根据响应图的亮度,来判断网络模型对于该场景下执行该任务的自信程度。根据响应图的交叉熵与训练数据集中的响应图交叉熵的大小关系,执行不同的操作。如果当前响应图的交叉熵大于阈值,本次预测是置信度高的一次预测,机器人会移动到响应图最亮的点的位置,执行相应的任务;如果响应图的交叉熵小于阈值,本次预测是置信度较低的预测,机器人会主动停下,记录下当前的彩色图和深度图,请求标注。阈值可以是训练数据集的响应图的交叉熵平均值。通过改变实验的场景,机器人会做出一些置信度较低的预测,采集到一定数量的彩色图和深度图。
4.主动学习阶段——真实环境数据自动标注方法:
将未摆放物体的场景深度图记为d1,已摆放物体的场景深度图记为d2,通过d=d2-d1可以得到物体的位置信息。使用中值滤波、膨胀、腐蚀等方法对d进行处理,去除噪声。寻找d中的轮廓,并计算轮廓的矩,得到轮廓的中心点位置,即为物体的位置。使用轮廓信息和中心点信息,可以描述物体的形状和位置。将形状和位置信息从深度图映射到彩色图,在彩色图上进行标注。
5.主动学习阶段——网络微调:
使用标注后的真实环境图片对原来训练好的模型进行微调(finetune)。微调时按照原网络结构,使用已训练好的网络参数作为初始化参数,使用adam优化器进行几次梯度下降即可。微调后的模型可以很好地完成原来不能完成的任务。
通过主动学习,模型可以实现增量学习,学会绝大部分相似的任务。
如图1所示,一种基于图像输入的机器人主动学习方法,包括以下步骤:
步骤1.在仿真环境中,搭建一个类似于现实场景的环境,捕获仿真环境中的彩色图像和对应的物体的位置,保存为数据集;
s11.在场景中放置一张桌子,桌子上摆放了机器人、摄像头和一些物体;
s12.在仿真器中,随机设置桌子和地板的颜色,随机选择一个或多个物体摆放在桌子上,随机产生物体摆放的位置,随机改变物体的颜色和纹理,随机改变环境的光照强度;
s13.记录摄像头捕获的彩色图像和对应的物体的位置,保存为数据集。
步骤2.根据任务的可受性制作响应图和掩膜;
s21.根据任务的特点,计算对于指定任务下物体的可受性区域,对于抓取任务,可受性区域为物体的几何中心点;对于推动任务,可受性区域为终点物体与起点物体的连线的延长线某一区域处;
s22.根据可受性区域,制作响应图,在图上表示为一个服从高斯分布的高亮圆形,圆心的位置即为可受性区域的中心位置;
s23.根据可受性区域,制作掩膜图,在图上表示为一个服从高斯分布的高亮圆形,圆心的位置即为可受性区域的中心位置,半径比响应图的圆形要大。
步骤3.使用步骤s1采集的彩色图像、步骤s2制作的响应图和掩膜图,训练深度神经网络,使用编码器从图片中提取有效的信息,再使用解码器生成表示可受性区域响应图;
s31.对输入到网络的图片进行归一化,归一化后图像像素值的范围是(-1,1);
s32.网络使用adam优化器进行梯度下降,学习率设定为10e-4,mini-batch设定为32,所有参数均随机初始化;
s33.编码器由4个卷积层组成,在每个卷积层后均跟有池化层和批标准化层;每个卷积层都使用4*4的卷积核,步长为2,使用leaky_relu函数作为激活函数;解码器由4个反卷积层组成,在每个反卷积层后均跟有批标准化层;反卷积层使用4*4的卷积核,步长为2;最后一个反卷积层使用tanh作为激活函数,其余层均使用leaky_relu函数作为激活函数;
s34.网络输出的响应图记为o,制作的响应图记为y,掩膜图记为m,网络的损失函数定义为:
步骤4.将训练好的深度神经网络模型部署到真实机器人上,尝试完成指定的任务;
s41.摄像头拍摄当前场景的彩色图像,将该图像进行步骤s31所述的归一化后输入到网络中;网络将会输出对应的响应图;
s42.计算输出的响应图的交叉熵,比较交叉熵和阈值大小的关系,判断能否完成任务;若交叉熵的值大于阈值,机器人能执行该任务,跳到步骤7;若交叉熵的值小于阈值机器人无法执行任务,跳到步骤5。
步骤5.保存当前状态下摄像头捕获的彩色图像和深度图像,进行标注;
s51.将未摆放物体的场景深度图记为d1,已摆放物体的场景深度图记为d2,通过d=d2-d1可以得到物体的位置信息;使用中值滤波、膨胀、腐蚀方法对d进行处理,去除噪声;
s52.寻找d中所有面积较大的轮廓,并计算轮廓的矩,得到轮廓的中心点位置,即为物体的位置。使用轮廓信息和中心点信息,可以描述物体的形状和位置。
步骤6.使用标注数据对网络进行微调,重复步骤s4;
s61.通过步骤s5的标注,使用与步骤s2相同的方法制作响应图和掩膜图;
s62.使用步骤s5的彩色图像、步骤s61制作的响应图和掩膜图,训练深度神经网络,使用编码器从图片中提取有效的信息,再使用解码器生成表示可受性区域响应图;
s63.对输入到网络的图片进行归一化,归一化后图像像素值的范围是(-1,1);
s64.网络使用adam优化器进行梯度下降,学习率设定为10e-5,mini-batch设定为32,所有参数均随机初始化
s65.编码器由4个卷积层组成,在每个卷积层后均跟有池化层和批标准化层;每个卷积层都使用4*4的卷积核,步长为2,使用leaky_relu函数作为激活函数;解码器由4个反卷积层组成,在每个反卷积层后均跟有批标准化层;反卷积层使用4*4的卷积核,步长为2;最后一个反卷积层使用tanh作为激活函数,其余层均使用leaky_relu函数作为激活函数;
s66.网络输出的响应图记为o,制作的响应图记为y,掩膜图记为m,网络的损失函数定义为:
步骤7.机器人开始执行任务。
s71.寻找响应图上亮度最高的点,该点的位置表示物体可受性区域的位置;将该点的坐标映射到机器人坐标空间中,该位置即为机器人坐标系中物体的可受性区域的位置;
s72.机械臂移动到指定位置,执行指定任务。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!