基于强化学习的行为识别视频帧采样方法及系统与流程
本发明涉及计算机视觉和模式识别技术领域,特别涉及一种基于强化学习的行为识别视频帧采样方法及系统。
背景技术:
由于深度学习在图像识别领域取得的巨大成功,近年来,行为识别方法主要通过设计深度网络来从大量有标签的视频数据中学习视频的深度特征表达。
这些工作主要分为以下几类:基于双流模型的方法,基于循环神经网络的方法,基于3d卷积神经网络的方法以及他们之间的结合。在这些方法中,由于能够高效的利用视频信息,基于双流模型的方法起到了最重要的推动作用。为了高效的对视频中的行为进行识别,这些方法首先对视频均匀地、稀疏地采样,然后对采样得到的每一帧进行识别,最后将所有帧的行为预测融合得到整个视频的行为预测,输出行为类别。
然而在一段视频中,由于行为显著性、图像质量的原因,具有判别力的行为可能只稀疏地分布在视频的少数帧中,并且其他的帧大多与行为无关,其引入的噪声甚至可能导致行为识别的结果出现错误。
技术实现要素:
为了解决现有技术中的上述问题,即为了准确确定关键帧,降低噪声,本发明提供了一种基于强化学习的行为识别视频帧采样方法及系统。
为解决上述技术问题,本发明提供了如下方案:
一种基于强化学习的行为识别视频帧采样方法,所述行为识别视频帧采样方法包括:
从待测试视频提取待测视频帧序列,并从所述待测视频帧序列中均匀采样t帧待测图像;
基于行为识别的基础模型,根据各帧待测图像,确定对应帧待测图像的待测特征向量和待测行为预测;
针对每帧待测图像,将所述待测特征向量和待测行为预测级联,得到待测状态序列;
根据基于长短时记忆网络的智能体及所述待测状态序列,确定每帧待测图像的待测重要性得分;
按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧;
根据各关键帧的待测行为预测,得到所述待测视频的行为预测;
根据所述待测视频的行为预测,确定识别结果。
可选的,所述基于长短时记忆网络的智能体通过策略梯度进行训练得到。
可选的,所述基于长短时记忆网络的智能体通过策略梯度进行训练,具体包括:
从训练集中提取任意训练视频,并从所述训练视频中均匀采样t帧训练图像;
基于行为识别的基础模型,根据各帧训练图像,确定对应帧训练图像的训练特征向量和训练行为预测,计算所有训练图像的训练行为预测取平均值得到视频的初始行为预测p0:
其中,
针对每帧训练图像,将所述训练特征向量与训练行为预测级联,组成训练状态序列;
根据所述训练状态序列及基于深度神经网络的智能体,确定该训练图像的动作的概率分布,基于深度神经网络的智能体对每帧训练图像的采用的动作有两种:丢弃和保留;
根据该训练图像的动作的概率分布进行采样,组成动作序列,对动作的采样过程可以形式化为:
其中,at∈{0,1}为基于深度神经网络的智能体对第t帧采取的动作,0表示丢弃动作,1表示保留动作;
根据动作序列挑选关键帧,并将关键帧的行为预测取平均值得到新行为预测:
根据所述初始行为预测和新行为预测,计算智能体获得的奖励;
根据各训练图像的动作序列和奖励,计算目标函数和基于深度神经网络的智能体参数的梯度,并更新基于深度神经网络的智能体的参数;
重复根据所述基于深度神经网络的智能体的参数,直至所述基于深度神经网络的智能体所获得的期望奖励最大或达到迭代次数,以得到所述基于长短时记忆网络的智能体。
可选的,所述根据所述初始行为预测和新行为预测,计算智能体获得的奖励,具体包括:
若初始视频行为预测p0和新视频行为预测p1对视频中行为类别判断相同,则奖励
若两次预测对视频行为类别的判断不同,且如果初始判断是错误的,智能体执行动作后,判断是正确的,则智能体获得较大奖励r=10;反之,智能体获得较大惩罚r=-10。
可选的,所述目标函数包括期望奖励损失函数j(θ)和采样损失函数lsampling,θ为基于深度神经网络的智能体的参数;
其中,根据以下公式,计算期望奖励损失函数:
其中,pθ(a1:t)为可能的动作序列的概率分布;
根据以下公式确定θ的梯度为:
其中,
根据以下公式,计算采样损失函数:
其中,m为智能体在测试阶段从视频中挑选的帧数,β为其权重系数,关于θ的梯度为
可选的,所述行为识别的基础模型为任意基于视频帧的行为识别模型。
可选的,所述按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧,具体包括:
将各待测重要性得分按照从大到小的顺序排列;
提取前m的待测重要性得分对应的待测图像为关键帧,得到m帧关键帧。
可选的,m=12。
可选的,所述根据各关键帧的待测行为预测,得到所述待测视频的行为预测,具体包括:
计算各关键帧的待测行为预测的平均值,所述平均值为所述待测视频的行为预测。
为解决上述技术问题,本发明提供了如下方案:
一种基于强化学习的行为识别视频帧采样系统,所述行为识别视频帧采样系统包括:
提取单元,用于从待测试视频提取待测视频帧序列,并从所述待测视频帧序列中均匀采样t帧待测图像;
确定单元,用于基于行为识别的基础模型,根据各帧待测图像,确定对应帧待测图像的待测特征向量和待测行为预测;
级联单元,用于针对每帧待测图像,将所述待测特征向量和待测行为预测级联,得到待测状态序列;
得分单元,用于根据基于长短时记忆网络的智能体及所述待测状态序列,确定每帧待测图像的待测重要性得分;
选取单元,用于按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧;
预测单元,用于根据各关键帧的待测行为预测,得到所述待测视频的行为预测;
识别单元,用于根据所述待测视频的行为预测,确定识别结果。
根据本发明的实施例,本发明公开了以下技术效果:
本发明基于行为识别的基础模型,确定待测图像的待测特征向量和待测行为预测,进而得到待测状态序列,进一步根据基于长短时记忆网络的智能体待测状态序列,确定每帧待测图像的待测重要性得分,并以此为根据选取关键帧,从而降低无关帧带来的负面影响,降低噪声。
附图说明
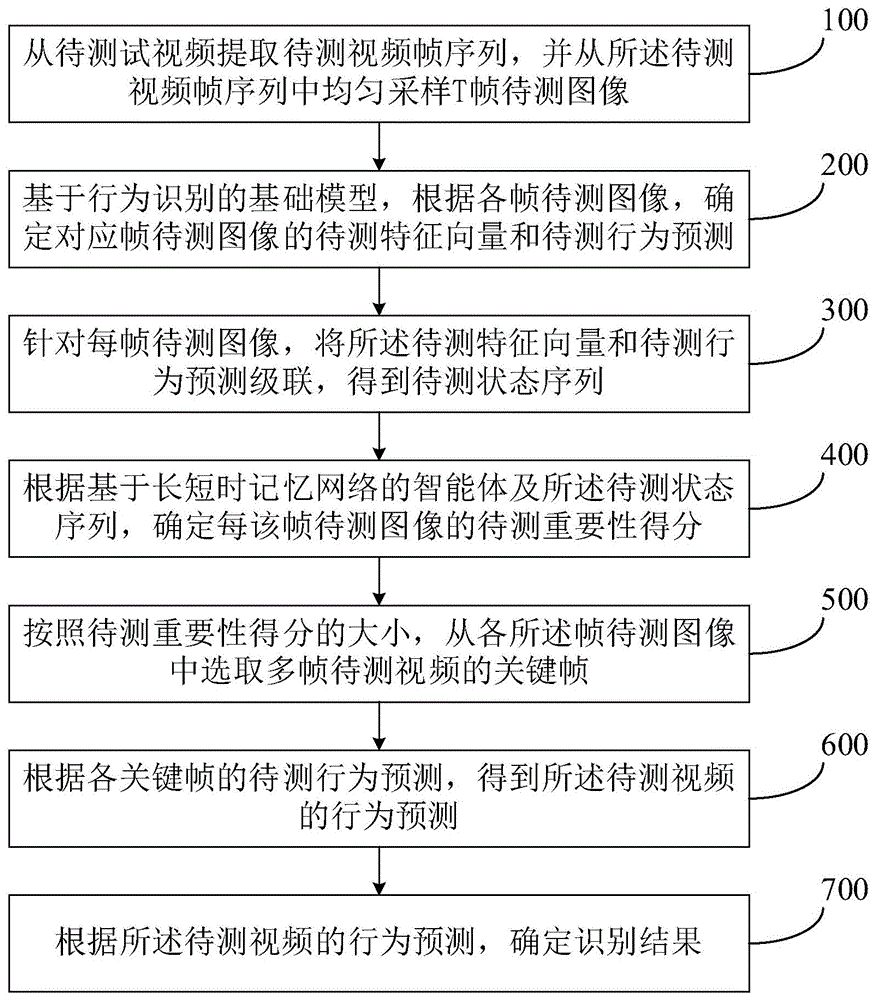
图1是本发明基于强化学习的行为识别视频帧采样方法的流程图;
图2是本发明基于强化学习的行为识别视频帧采样系统的模块结构示意图。
符号说明:
提取单元—1,确定单元—2,级联单元—3,得分单元—4,选取单元—5,预测单元—6,识别单元—7。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
本发明提供一种基于强化学习的行为识别视频帧采样方法,基于行为识别的基础模型,确定待测图像的待测特征向量和待测行为预测,进而得到待测状态序列,进一步根据基于长短时记忆网络的智能体待测状态序列,确定每帧待测图像的待测重要性得分,并以此为根据选取关键帧,从而降低无关帧带来的负面影响,降低噪声。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明一种基于强化学习的行为识别视频帧采样方法包括:
步骤100:从待测试视频提取待测视频帧序列,并从所述待测视频帧序列中均匀采样t帧待测图像。
在本实施例中,t=25。
步骤200:基于行为识别的基础模型,根据各帧待测图像,确定对应帧待测图像的待测特征向量和待测行为预测。
其中,所述行为识别的基础模型为任意基于视频帧的行为识别模型。
步骤300:针对每帧待测图像,将所述待测特征向量和待测行为预测级联,得到待测状态序列。
步骤400:根据基于长短时记忆网络的智能体及所述待测状态序列,确定每帧待测图像的待测重要性得分。
步骤500:按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧。
步骤600:根据各关键帧的待测行为预测,得到所述待测视频的行为预测。
步骤700:根据所述待测视频的行为预测,确定识别结果。
其中,所述基于长短时记忆网络的智能体通过策略梯度进行训练得到。
进一步地,所述基于长短时记忆网络的智能体通过策略梯度进行训练,具体包括:
步骤401:从训练集中提取任意训练视频,并从所述训练视频中均匀采样t帧训练图像。
步骤402:基于行为识别的基础模型,根据各帧训练图像,确定对应帧训练图像的训练特征向量和训练行为预测,计算所有训练图像的训练行为预测取平均值得到视频的初始行为预测p0:
其中,
步骤402:针对每帧训练图像,将所述训练特征向量与训练行为预测级联,组成训练状态序列。
步骤403:根据所述训练状态序列及基于深度神经网络的智能体,确定该训练图像的动作的概率分布,基于深度神经网络的智能体对每帧训练图像的采用的动作有两种:丢弃和保留。
步骤404:根据该训练图像的动作的概率分布进行采样,组成动作序列,对动作的采样过程可以形式化为:
其中,at∈{0,1}为基于深度神经网络的智能体对第t帧采取的动作,0表示丢弃动作,1表示保留动作;
步骤405:根据动作序列挑选关键帧,并将关键帧的行为预测取平均值得到新行为预测:
步骤406:根据所述初始行为预测和新行为预测,计算智能体获得的奖励。
所述根据所述初始行为预测和新行为预测,计算智能体获得的奖励,具体包括:
若初始视频行为预测p0和新视频行为预测p1对视频中行为类别判断相同,则奖励
若两次预测对视频行为类别的判断不同,且如果初始判断是错误的,智能体执行动作后,判断是正确的,则智能体获得较大奖励r=10;反之,智能体获得较大惩罚r=-10
步骤407:根据各训练图像的动作序列和奖励,计算目标函数和基于深度神经网络的智能体参数的梯度,并更新基于深度神经网络的智能体的参数。
所述目标函数包括期望奖励损失函数j(θ)和采样损失函数lsampling,θ为基于深度神经网络的智能体的参数;
其中,根据以下公式,计算期望奖励损失函数:
其中,pθ(a1:t)为可能的动作序列的概率分布;
根据以下公式确定θ的梯度为:
其中,
根据以下公式,计算采样损失函数:
其中,m为智能体在测试阶段从视频中挑选的帧数,β为其权重系数,关于θ的梯度为
步骤408:重复根据所述基于深度神经网络的智能体的参数,直至所述基于深度神经网络的智能体所获得的期望奖励最大或达到迭代次数,以得到所述基于长短时记忆网络的智能体。
在步骤500中,所述按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧,具体包括:
步骤501:将各待测重要性得分按照从大到小的顺序排列;
步骤502:提取前m的待测重要性得分对应的待测图像为关键帧,得到m帧关键帧。
优选地,m=12。
在步骤600中,所述根据各关键帧的待测行为预测,得到所述待测视频的行为预测,具体包括:
计算各关键帧的待测行为预测的平均值,所述平均值为所述待测视频的行为预测。
本发明基于强化学习的行为识别视频帧采样方法将挖掘视频中关键帧的过程形式化为马尔可夫决策过程,在不利用额外标签的条件下,利用一个经过训练的行为识别的基础模型提取训练视频序列的特征序列以及帧测试序列,并以此作为智能体的输入,通过强化学习训练智能体;在测试阶段,智能体以测试视频序列的特征序列及帧预测序列为输入,对测试视频的每一帧进行重要性评分,并以此为根据挑选视频中的关键帧,从而降低无关帧带来的负面影响。
此外,本发明还提供一种基于强化学习的行为识别视频帧采样系统,准确确定关键帧,降低噪声。
如图2所示,本发明基于强化学习的行为识别视频帧采样系统包括提取单元1、确定单元2、级联单元3、得分单元4、选取单元5、预测单元6及识别单元7。
具体地,所述提取单元1用于从待测试视频提取待测视频帧序列,并从所述待测视频帧序列中均匀采样t帧待测图像。
所述确定单元2用于基于行为识别的基础模型,根据各帧待测图像,确定对应帧待测图像的待测特征向量和待测行为预测。
所述级联单元3用于针对每帧待测图像,将所述待测特征向量和待测行为预测级联,得到待测状态序列。
所述得分单元4用于根据基于长短时记忆网络的智能体及所述待测状态序列,确定每帧待测图像的待测重要性得分。
所述选取单元5用于按照待测重要性得分的大小,从各所述帧待测图像中选取多帧待测视频的关键帧。
所述预测单元6用于根据各关键帧的待测行为预测,得到所述待测视频的行为预测。
所述识别单元7用于根据所述待测视频的行为预测,确定识别结果。
相对于现有技术被,本发明基于强化学习的行为识别视频帧采样系统与上述基于强化学习的行为识别视频帧采样方法的有益效果相同,在此不再赘述。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!