一种新型的群智能游牧算法的制作方法
本发明涉及智能技术领域,特别是涉及一种新型的群智能游牧算法。
背景技术:
自然界经历了长久的演化,拥有强大的适应性。人通过对大自然的观察和思考获得灵感,构建出各类算法模型解决复杂的实际问题,这就是基于仿生思想的元启发式智能算法。复杂的优化问题曾经只能通过确定性的数学优化方法求解,但随着问题复杂性提升、维度增加,传统算法求解难度剧增且仅能保证局部最优。直到智能算法的出现才大大缓解了这些缺陷,智能算法带有随机性,模仿自然界的行为或现象,在求解过程中展现出强大的自适应能力,面对复杂问题有较好的表现。按着模仿来源主要可分为自然现象、生物行为、物理过程三类。自然现象启发算法启发于大自然演化,如最先提出的遗传算法,模拟dna进化过程中选择、重组、变异,进化到一个最佳状态即最优解,花授粉算法模拟花朵传粉繁殖找到最适宜生存的位置;生物行为启发算法如粒子群算法受鸟群联合捕食启发、人工蜂群算法受蜜蜂分工寻蜜采蜜启发;物理过程启发算法的灵感来自于物理现象,如著名的退火算法模拟固体退火过程、烟花算法模拟烟花爆炸的过程。
现存的智能算法数量庞大,在特定问题上能表现出较强的优化能力,这些算法广泛应用在工程、经济、工业设计等领域的优化。但他们往往过于复杂而难以理解和选择,尤其是考虑到优化算法的使用者通常并非是计算机专业算法领域的研究者。由于“没有免费午餐”定理的存在,对于特定问题需要选择特定的算法,算法思想、算法选择、参数调整需要专业的分析,真正使用算法的非计算机专业的工程人员无法发挥算法的优化性能。
本发明提出了一种称为游牧算法(nomadalgorithm,以下简称na)的全新智能算法,并附收敛性分析(收敛证明见实施例2所示),其灵感来自于草原上游牧部落逐水草而居的迁徙策略。游牧算法的原理生动简单易于理解,需要调整的参数少便于使用,良好的平衡了局部搜索和全局搜素,使得算法在保证全局搜索能力的同时还能迅速得到较高的收敛精度。na的强大优化能力使其可以广泛应用于工业设计、工程优化、经济模型优化等多种领域。
技术实现要素:
针对现有大多数智能算法流程复杂,敏感参数众多,收敛精度与收敛全局性难以平衡的问题,本专利受草原上游牧部落逐水草而迁徙的种群行为启发,提出了一种全新的群智能算法;
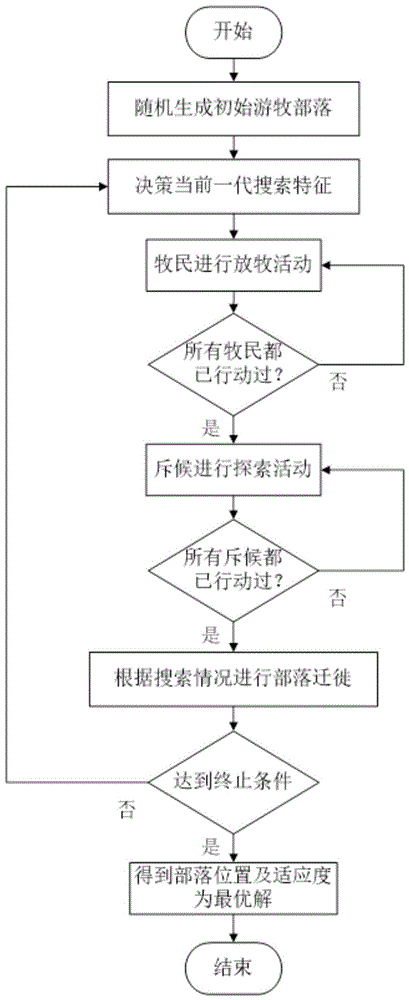
游牧算法(na)将待优化问题的搜索空间当作一片草原,游牧部落总是向着水草更加丰茂即适应度更好的地方迁徙,将部落成员,即搜索代理,划分为牧民和斥候(斥候指行动迅捷负责侦察的人,本算法中指负责全局搜索的搜索代理)。牧民和斥候以部落为中心,分别以不同的策略进行搜索作业,对应算法的局部开采和全局勘探。
na依据当前一轮搜索的结果,决定下一轮搜索范围与强度,达到面对不同复杂问题能够自适应的效果。
牧民在以部落为中心的小范围均匀搜索,局部搜索能力较强,保障了算法收敛的高精度。
斥候则从部落出发,探索远方是否有更宜居的地方,但越远的地方概率会变小,有较强全局搜索能力,保障算法能够收敛于全局最优解,避免陷入局部最优。
当游牧部落的人口即种群数目固定时,通过调整牧民和斥候的比例,决定全局搜索和局部搜索的强度,实现收敛精度与全局性的良好平衡。算法通过牧民放牧活动、斥候探索活动、部落迁徙及决策活动三个过程组成。具体的步骤如下:
步骤1:初始化na算法参数;
确定种群个数m,最大迭代次数max_ite。由待优化问题确定维度n,搜索空间的范围的下界xmin,上界xmax。经试验比较,牧民在整个种群中所占比例的上限maxp=0.9,比例下限minp=0.4时搜索效果较好。在搜索空间中,随机生成m个点,分别计算其适应度,适应度值最小的点保留,作为当前部落所在。
步骤2:牧民放牧活动;
根据公式(1)计算牧民的数量mh,其中t=1,2,3...max_ite,为当前迭代次数:
牧民在第t轮迭代时的搜索范围r(t)按公式(2)计算:
其中,α是大于1的增长因子,β是大于0小于1的凋萎因子。这两个系数应接近于1,防止搜索范围骤变而导致算法不稳定。α分别取1.05、1.1、1.15、1.2,β分别取0.8、0.85、0.9、0.95,通过网格搜索的方法确定最终系数。经验证,取α=1.1,β=0.9时算法效果较好。ftribe(t)表示在第t轮迭代时,部落所在的位置的适应度值。即当前一轮迭代发现了更好的位置,则牧民活动的范围可增长,未找到更好的位置,随着资源消耗,牧民应缩小活动范围。
最终牧民放牧活动伪代码描述如下列算法(1):
xk表示种群中一个成员x在第k维度上的坐标位置,k=1,2,3...n。xtribek为部落所在的位置在第k维度的坐标。rand(a,b)表示生成在a和b之间均等概率分布的一个随机数。
步骤3:斥候探索活动;
根据公式(3)计算斥候的数量ms:
ms=m-mh公式(3)
斥候以部落为中心,以高斯分布概率探索一定的范围,斥候的位置可用公式(4)描述:
xscout~n(xtribe,σ2)公式(4)
上式中xscdut为斥候探索的位置,服从高斯分布n(xtribe,σ2),其数学期望值为xtribe,方差为σ2。方差σ2即斥候探索的幅度,直接决定探索范围,第t轮迭代时探索幅度σ(t)由公式(5)计算:
斥候探索活动的最终形式用伪代码描述如算法(2):
步骤4:部落迁徙及决策
至此第t轮搜索已全部完成;评估部落中的所有成员,即所有的牧民和斥候。计算每一个成员所在位置的适应度并与部落位置的适应度比较,随后部落迁徙至适应度最佳的位置并保留其适应度值,即更新xtribe和ftribe(t)。
步骤5:终止算法并返回最优解
如果不满足算法终止条件,则返回步骤2继续执行迭代。
算法的终止条件为:迭代次数达到上限max_ite或当前最优解ftribe(t)达到指定精度。
综上所述,游牧算法的完整过程以伪代码描述如下算法(3):
本发明的有益效果:
(1)提出了一种全新的智能优化算法,且结构简单,原理生动易懂,主观控制参数少;
(2)算法较好的平衡了局部挖掘能力和全局勘探能力,在保障全局性的前提下,还能得到较高的精度;
(3)算法的收敛精度和收敛速度,较其他经典智能算法有明显优势;
算法的搜索很公平,不同于部分智能算法仅对特定位置搜索有奇效的“伪智能”,无论最优解位于未知搜索空间的什么位置,游牧算法均能给出可接受的优化结果。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明所述算法的流程图;
图2为实施例1所述的schaffer函数图像;
图3(a)-(f)为实施例1所述的六种算法在基准函数f1-f6上的收敛过程曲线;
(a)sphere函数
(b)axisparallelhyperellipsoid函数
(c)rotatedhyperellipsoid函数
(d)schwefel-u函数
(e)griewank函数
(f)rosenbrock函数
图4(a)-(f)为实施例1所述的六种算法在基准函数f7-f12上的收敛过程曲线;
(a)ackley函数
(b)schwefel函数
(c)rastrigin函数
(d)schaffer函数
(e)dropwave函数
(f)easom函数
具体实施方式
实施例1
为验证本申请中游牧算法的性能,现选取12个业界公认的经典基准测试函数。这12个基准测试函数的名称、表达式和特征在表(1)中详细列出:
表(1)12个基准测试函数
其中f1-f4为单峰高维度函数,可考察算法的局部挖掘能力。f5-f9为多峰高维度函数,综合考察算法的全局勘探能力和局部挖掘能力。f10-f12为多峰固定维度函数,重点考察算法避免陷入局部最优的全局搜索性能。
由于多数基准函数最优解恰好位于原点,使得一些算法有所针对,在测试时表现出极好的性能,而算法本身优化能力并不强大,在实际应用中效率低下。为避免这种现象并增加搜索难度,拉大不同算法对比差距,我们将所有基准函数的最优解位置在每个维度都进行偏移,偏移幅度为搜索空间范围的20%。为统一标准,所有函数的最优解值被纵向偏移至0,使得优化结果可直接看作优化的误差,方便比较。
同时,选取5个经典智能算法与我们提出的算法进行比较,分别是粒子群算法(pso)、引力搜索算法(gsa)、花授粉算法(fpa)、鲸鱼算法(woa)、乌鸦搜索算法(csa)。其中pso为最早的群智能算法,被引过万次,gsa为近十年认可度较高的算法,论文被引超过三千次。fpa、woa、csa为近年来较新且知名的算法,分别于2013年、2016年、2017年被提出。所有算法的参数按该算法作者论文原著中给出的建议值设定。游牧算法及5种对比算法的参数设定见表(2):
表(2)六种算法的参数设定
由于各个算法的种群规模不同,不同算法一轮迭代的计算量不同,这里采用函数评估次数代替迭代次数作为评判标准,所有算法进行30,000次评估,实验环境为windows10操作系统matlabr2016软件,硬件配置为:英特尔i5-2400@3.10ghz处理器,4gb内存;为了避免偶然性,使实验具有统计意义,每个实验独立运行30次取平均值(mean)和标准差(std),每个测试函数上6种算法表现最好的结果被加粗标出。实验结果见表(3):
表(3)六种算法在12个基准函数上的优化结果
可以看出,在所有的基准函数上,游牧算法均达到了6个优化算法中最高的收敛精度,即误差最小。而在标准差方面,除了在函数f10,其他测试函数优化结果均为游牧算法的标准差最小。这意味着游牧算法在绝大多数函数优化问题上波动不大,具有较高的稳定性。
na在f10函数上标准差的异常,是因为f10为密集多峰的schaffer函数,经偏移后用于测试的函数图像如图2所示。其局部最优解数量极多且大小相近,很容易陷入广泛分布于整个搜索空间不同位置局部最优。其他算法在多次执行中反复陷入局部最优解,所以每次执行结果标准差波动不大,精度却不高。而na以强大的全局能力多次找到全局最优解,偶尔陷入局部最优得到与之前全局最优不同的答案,所以平均精度很高,标准差却不是最小。这种波动性更说明na有着强大的全局优化能力。
为了进一步直观地考察游牧算法的收敛性能,我们执行更多次数的评估,所有算法最大评估次数设为300,000,并绘制出收敛过程曲线。通过比较6种算法在12个基准函数上收敛过程曲线,从收敛速度与最终收敛精度两个方面来评价算法的性能,收敛过程曲线见图3和图4:
比较收敛过程曲线可发现,游牧算法收敛精度极高,远超过其他算法。在收敛速度方面,除了低维度的schaffer和dropwave函数上收敛速度不是最快,在其他问题上均比对比算法快的多。这是因为schaffer函数和dropwave函数都是简单函数,维度低、搜索空间小(搜索空间仅2维,远低于其他测试函数的30维),在这种简单问题上各个算法不相上下,如同“1+1=?”的简单问题无法检验不同计算机的算力。
由此可以得出结论:本发明提出的全新智能算法——游牧算法,是一种高效的全局优化算法。较之经典的粒子群、引力搜索、花授粉、鲸鱼、乌鸦搜索算法,游牧算法在优化精度、收敛速度、稳定性上均有明显优势,对于复杂的优化问题可以较快地以很高的精度搜索到全局最优解。是一种很有潜力的智能算法,可用于各类工程优化问题。
实施例2游牧算法(na)全局收敛性证明
游牧算法(以下简称na)的随机模型中,目标函数f在解空间s上的基本下确界α被定义成如下公式(6):
α=inf(t∶υ[x∈s|f(x)<t]>0)公式(6)
其中的v[a]表示集合a(最优解的潜在空间)的勒贝格测度(lebesguemeasure),t为任意常数。
给出na的随机过程
定理1:给定一个吸收马尔可夫随机过程
则
引理1:na的随机过程
引理1证明:
引理2给定游牧算法一个吸收马尔可夫过程
引理2证明:当t=1时,有
假设
基于上述推导进行数学归纳,p{xt∈y*}≥1-(1-d)t对一切t≥1.引理2证明完毕。
引理3:na以1的概率收敛于全局最优解。
引理3证明:na全局搜索过程是在整个搜索空间的高斯变异。为简化问题,不妨假设该变异是一种简单随机变异。用pse(t)表示在第t代一个搜索代理通过斥候探索过程,从非最优区域达到最优区域y*的概率,即
υ(s)是问题搜索空间s的勒贝格测度,ms是算法进行到第t代时的斥候数量。
由于υ(y*)>0,所以pse>0.
na的随机马尔可夫过程
phe(t)表示第t代一个搜索代理通过牧民放牧过程,从非最优区域达到最优区域y*的概率。因此,
λ(t)=p{xt∈y*}≥1-(1-pse(t))t公式(10)
经化简后,即limt→∞λ(t)=1,公式(7)中等式成立。
至此,定义1满足成立,na的马尔可夫过程
- 还没有人留言评论。精彩留言会获得点赞!