深度神经网络硬件加速器与其操作方法与流程
本发明有关于一种深度神经网络硬件加速器与其操作方法。
背景技术:
深度神经网络(deepneuralnetworks,dnn)属于人工神经网络(artificialneuralnetwork,ann)的一环,可用于深度机器学习。人工神经网络可具备学习功能。深度神经网络已经被用于解决各种各样的问题,例如机器视觉和语音识别等。
如何使得深度神经网络的内部数据传输速度最佳化进而加快其处理速度,一直是业界努力方向之一。
技术实现要素:
根据本发明一实施例,提出一种深度神经网络硬件加速器,包括:一网络分配器,接收一输入数据,根据一目标数据量的多个频宽比率来分配该目标数据量的多个数据类型的个别频宽;以及一处理单元阵列,耦接至该网络分配器,根据所分配的这些数据类型的个别频宽,该处理单元阵列与该网络分配器之间互相传输该目标数据量的这些数据类型的各自数据。
根据本发明又一实施例,提出一种深度神经网络硬件加速器的操作方法,该深度神经网络硬件加速器包括一网络分配器与一处理单元阵列,该处理单元阵列包括多个处理单元,该操作方法包括:分析一目标数据量;根据对该目标数据量的分析结果,设定该目标数据量的多个数据类型的多个频宽比率;根据相关于该目标数据量的这些数据类型的这些频宽比率所造成的一延迟,判断是否要重新设定该目标数据量的这些数据类型的这些频宽比率;根据该目标数据量的这些数据类型的这些频宽比率,初始化该网络分配器与该处理单元阵列的这些处理单元;以及由该处理单元阵列的至少一被选处理单元来处理一输入数据。
根据本发明另一实施例,提出一种深度神经网络硬件加速器,包括:一频宽与使用率分析单元,分析一目标数据量,以得到该目标数据量的多个数据类型的分布情况并设定该目标数据量的这些数据类型的个别传输频宽;一处理单元阵列,包括多个处理单元;多个第一多工器,耦接至该处理单元阵列,这些第一多工器接收一输入数据的一第一数据与一第二数据;以及一控制器,耦接至该频宽与使用率分析单元以及这些第一多工器,该控制器根据该频宽与使用率分析单元所设定的这些数据类型的这些传输频宽来控制这些多工器,其中,这些第一多工器的一多工器输出该输入数据的该第一数据与该第二数据中的一数据量较小者给该处理单元阵列,而这些第一多工器的另一多工器输出该输入数据的该第一数据与该第二数据中的一数据量较大者给该处理单元阵列。
根据本发明又一实施例,提出一种深度神经网络硬件加速器的操作方法,该深度神经网络硬件加速器包括一处理单元阵列与一网络分配器,该操作方法包括:接收一输入数据,根据一目标数据量的多个频宽比率来分配该目标数据量的多个数据类型的个别频宽;以及根据所分配的这些数据类型的个别频宽,该处理单元阵列与该网络分配器之间互相传输该目标数据量的这些数据类型的各自数据。
为了对本发明的上述及其他方面有更佳的了解,下文特举实施例,并配合所附附图详细说明如下:。
附图说明
图1显示根据本发明一实施例的深度神经网络(dnn)硬件加速器的功能方块图。
图2显示根据本发明一实施例的网络分配器的功能方块图。
图3显示根据本发明一实施例的处理单元的功能方块图。
图4显示根据本发明一实施例的深度神经网络硬件加速器的操作方法流程图。
图5显示根据本发明一实施例的深度神经网络硬件加速器的功能方块图。
图6显示根据本发明一实施例的处理单元的功能方块图。
图7显示根据本发明一实施例的深度神经网络硬件加速器的操作方法流程图。
【附图标记】
100:深度神经网络硬件加速器
110:网络分配器120:处理单元阵列
ri、rf、rip、rop:频宽比率
ifmap、filter、ipsum、opsum、ifmapa、filtera、ipsuma、opsuma、ifmapb、filterb、ipsumb、ifmapc、filterc:数据类型
122:处理单元
210:标签产生单元220:数据分配器
231、233、235与237:fifo
i_r_tag、f_r_tag、ip_r_tag:列标签
i_c_tag、f_c_tag、ip_c_tag:行标签
310:标签匹配单元320:数据选择与调度单元
330:频宽架构储存单元340:运算单元
352、354、356:fifo360:重整单元
i_c_id、f_c_id、ip_c_id:行辨别号
h_i、h_f与h_ip:命中参数
i_l、f_l、ip_l、op_l:频宽架构参数
341、343、345:内部暂存空间
347:乘加器
410-450:步骤
500:深度神经网络硬件加速器
512:频宽与使用率分析单元
514:控制器516、518:多工器
520:处理单元阵列522:处理单元
611与613:匹配单元621、623与625:fifo
631、633与635:重整单元
640:暂存器641:处理单元控制器
643与645:多工器650:运算单元
661与663:缓冲单元
d1:数据1col_tag:行标签
d2:数据2col_id:行辨别号
710-730:步骤
具体实施方式
本说明书的技术用语参照本技术领域的习惯用语,如本说明书对部分用语有加以说明或定义,该部分用语的解释以本说明书的说明或定义为准。本发明的各个实施例分别具有一个或多个技术特征。在可能实施的前提下,本技术领域技术人员可选择性地实施任一实施例中部分或全部的技术特征,或者选择性地将这些实施例中部分或全部的技术特征加以组合。
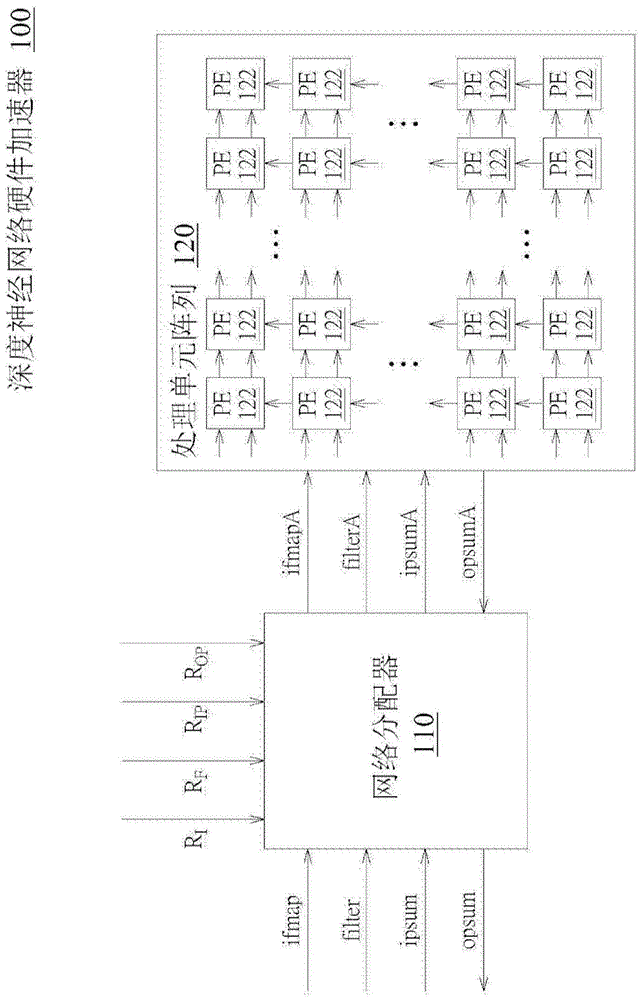
图1显示根据本发明一实施例的深度神经网络(dnn)硬件加速器的功能方块图。如图1所示,深度神经网络硬件加速器100包括网络分配器(networkdistribution)110与处理单元(processingelement,pe)阵列120。
在本发明的一实施例中,网络分配器110可以是硬件、固件或是储存在存储器而由微处理器或数位信号处理器所载入执行的软件或机器可执行程式码。若是采用硬件来实现,则网络分配器110可以是由单一整合电路晶片所完成,也可以由多个电路晶片所完成,但本发明并不以此为限制。上述多个电路晶片或单一整合电路晶片可采用特殊功能集成电路(asic)或现场可编程门阵列(fpga)来实现。而上述存储器可以是例如随机存取存储器、只读存储器或闪存存储器等等。处理单元122可例如被实施为微控制器(microcontroller)、微处理器(microprocessor)、处理器(processor)、中央处理器(centralprocessingunit,cpu)、数位信号处理器(digitalsignalprocessor)、特殊应用集成电路(applicationspecificintegratedcircuit,asic)、数位逻辑电路、现场可编程门阵列(fieldprogrammablegatearray,fpga)和/或其它具有运算处理功能的硬件元件。各处理单元122之间可以特殊应用集成电路、数位逻辑电路、现场可编程门阵列和/或其它硬件元件相互耦接。
网络分配器110根据目标数据量的多个频宽比率(ri,rf,rip,rop)来分配多个数据类型的各自频宽。在一实施例中,深度神经网络硬件加速器100处理完「目标数据量」后,可进行频宽调整。在此,「目标数据量」例如但不受限于,多个数据层、至少一数据层或一设定数据量。在下文的说明以「目标数据量」为多个数据层或至少一数据层为例来进行说明,但当知本发明并不受限于此。这些数据层例如卷积层(convolutionallayer)、池化层(poollayer)和/或全连接层(fully-connectlayer)等。数据类型包括:输入特征图(inputfeaturemap,ifmap)、滤波器(filter)、输入部分和(inputpartialsum,ipsum)与输出部分和(outputpartialsum,opsum)。在一实施例中,各数据层包括这些数据类型的任意组合。对于各数据层而言,这些数据类型的组合比例彼此不同,也即,对于某一数据层而言,可能数据ifmap所占的比重较高(例如数据量较多),但对于另一数据层而言,可能数据filter所占的比重较高。因此,在本发明一实施例中,可以针对各数据层的数据所占比重决定各数据层的频宽比率(ri、rf、rip和/或rop),进而调整和/或分配该数据类型的传输频宽(例如处理单元阵列120与网络分配器110之间的传输频宽),其中,频宽比率ri、rf、rip与rop分别代表数据ifmap、filter、ipsum与opsum的频宽比率,网络分配器110可根据ri、rf、rip与rop来分配数据ifmapa、filtera、ipsuma与opsuma的频宽。
处理单元阵列120包括排列成阵列的多个处理单元122。处理单元阵列120耦接至网络分配器110。根据所分配的这些数据类型的各自频宽,处理单元阵列120与网络分配器110之间互相传输这些数据类型的各自数据。
在本发明一实施例中,深度神经网络硬件加速器100还选择性地包括:频宽参数储存单元(未示出),耦接至网络分配器110,用以储存这些数据层的这些频宽比率ri、rf、rip和/或rop,并将这些数据层的这些频宽比率ri、rf、rip和/或rop传至网络分配器110。储存于频宽参数储存单元内的频宽比率ri、rf、rip和/或rop可以是离线(offiine)训练获得。
在本发明一实施例中,这些数据层的这些频宽比率ri、rf、rip和/或rop可以是即时(real-time)获得,例如这些数据层的这些频宽比率ri、rf、rip和/或rop由一微处理器(未示出)动态分析这些数据层而得,并传送至网络分配器110。在一实施例中,如果是微处理器(未示出)动态产生频宽比率ri、rf、rip和/或rop的话,则可以不需要进行获得频宽比率ri、rf、rip和/或rop的离线训练。
现请参照图2,显示根据本发明一实施例的网络分配器110的功能方块图。如图2所示,网络分配器110包括:标签产生单元(taggenerationunit)210、数据分配器220与多个先入先出缓冲器(firstin,firstout,fifo)231、233、235与237。
标签产生单元210根据这些频宽比率ri、rf、rip、rop以产生多个第一标签与多个第二标签。在此以这些第一标签为列标签(rowtag)i_r_tag、f_r_tag、ip_r_tag,而这些第二标签为多个行标签(columntag)i_c_tag、f_c_tag、ip_c_tag为例进行说明,但当知本发明并不受限于此。i_r_tag与i_c_tag分别代表数据ifmap的列标签与行标签,f_r_tag与f_c_tag分别代表数据filter的列标签与行标签,ip_r_tag与ip_c_tag分别代表数据ipsum的列标签与行标签。
处理单元122根据这些列标签与行标签来决定是否需要处理该笔数据。其细节将在下文进行说明。
数据分配器220,耦接至标签产生单元210,用以接收由这些fifo231、233与235所传来的数据(ifmap,filter,ipsum)和/或传送数据(opsum)到fifo237,并根据这些频宽比率ri、rf、rip和/或rop以分配这些数据(ifmap,filter,ipsum,opsum)的传输频宽,使得这些数据依据所分配的频宽以在网络分配器110与处理单元阵列120之间传输。
fifo231、233、235与237分别用以暂存数据ifmap、filter、ipsum与opsum。
在本发明一实施例中,网络分配器110以16位元频宽来接收这些输入数据ifmap、filter、ipsum,且也以16位元频宽来输出该输出数据opsum(输入数据至网络分配器110的输入传输频宽总和是固定的,网络分配器110输出至输出数据的输出传输频宽总和是固定的)。对于某一数据层而言,经数据分配器220处理输入数据(例如将8个16位元的数据集合为128位元,或将64位元的数据分开成为4个16位元的数据等)后,数据分配器220以64位元频宽传输数据ifmapa给处理单元阵列120,以128位元频宽传输数据filtera给处理单元阵列120,以16位元频宽传输数据ipsuma给处理单元阵列120,而数据分配器220以64位元频宽接收由处理单元阵列120所回传的数据opsuma。如此一来,可以更有效率地将数据传输于网络分配器110与处理单元阵列120之间,也即,如果数据filter所占比重较高,则以较高位元频宽来将数据filtera传输至处理单元阵列120;而如果数据ifmap所占比重较高,则以较高位元频宽来将数据ifmapa传输至处理单元阵列120。
现请参考图3,其显示根据本发明一实施例的处理单元122的功能方块图。如图3所示,处理单元122包括:标签匹配单元(tagmatchunit)310、数据选择与调度单元(dataselectinganddispatchingunit)320、频宽架构储存单元(bandwidthconfigurationregister)330、运算单元340、fifo352、354、356与重整单元(reshaper)360。
在本发明一实施例中,处理单元阵列120还选择性地包括一列解码器(未示出),用以解码由标签产生单元210所产生的这些列标签i_r_tag、f_r_tag、ip_r_tag,以决定哪一列要接收此笔数据。详细地说,假设处理单元阵列120包括12列的处理单元。如果这些列标签i_r_tag、f_r_tag、ip_r_tag是指向第一列(例如,i_r_tag、f_r_tag、ip_r_tag的值都为1),在列解码器解码后,列解码器将此笔数据送至第一列,其余可依此类推。
标签匹配单元310则用于匹配由标签产生单元210所产生的这些行标签i_c_tag、f_c_tag、ip_c_tag与行辨别号(col.id)i_c_id、f_c_id、ip_c_id,以决定该处理单元是否要处理该笔数据。具体而言,假设处理单元阵列120的每一列包括14个处理单元。对于第一个处理单元,其行辨别号i_c_id、f_c_id、ip_c_id都为1(其余可依此类推),如果这些行标签i_c_tag、f_c_tag、ip_c_tag的值都为1,则在标签匹配单元310的匹配后,第一个处理单元会决定要处理该笔数据。在一实施例中,根据标签匹配单元310的匹配结果,标签匹配单元310产生多个命中参数h_i、h_f与h_ip。如果这些命中参数h_i、h_f或h_ip为逻辑高,则代表匹配成功;如果这些命中参数h_i、h_f或h_ip为逻辑低,则代表匹配失败。数据选择与调度单元320可以根据这些命中参数h_i、h_f与h_ip来决定是否要处理该笔数据。如果命中参数h_i为逻辑高,则数据选择与调度单元320处理该笔数据ifmapa;如果命中参数h_f为逻辑高,则数据选择与调度单元320处理该笔数据filtera;以及如果命中参数h_ip为逻辑高,则数据选择与调度单元320处理该笔数据ipsuma。
频宽架构储存单元330储存这些数据类型ifmapa、filtera、ipsuma与opsuma所对应的多个频宽架构参数i_l、f_l、ip_l与op_l,其中,频宽架构参数i_l、f_l、ip_l与op_l分别代表由网络分配器110的数据分配器220所分配给这些数据ifmapa、filtera、ipsuma与opsuma的传输频宽(传输频宽的单位例如是位元数)。
数据选择与调度单元320根据由频宽架构储存单元330所传来的这些频宽架构参数i_l、f_l、ip_l以及由标签匹配单元所传来的这些命中参数h_i、h_f与h_ip而从fifo354中选择数据,以组成数据ifmapb、filterb与ipsumb,其中,由数据选择与调度单元320所组出的数据ifmapb、filterb与ipsumb的位元假设都为16位元。也即,由数据分配器220所传来的ifmapa、filtera与ipsuma位元假设是64位元、128位元与16位元(如图2所示),则经过数据选择与调度单元320的重组后,由数据选择与调度单元320所组出的数据ifmapb、filterb与ipsumb都为16位元。
运算单元340包括内部暂存空间(scratchpadmemory,spad)341、343、345与乘加器347。运算单元340例如但不受限于乘加运算单元。在本发明一实施例中,数据选择与调度单元320所组出的数据ifmapb、filterb与ipsumb(例如都为16位元)放入至内部暂存空间341、343与345内(如(1)所示)。接着,由乘加器(multiplyaccumulate,mac)347来作乘加运算,也即,乘加器347对数据ifmapb与filterb作乘法运算,所得到的乘法结果再与内部暂存空间345中的值作加法运算(如(2)所示)。作完上述乘加运算的值再写入至内部暂存空间345中,等待之后要再作加法运算时使用,之后,(2)与(3)循环进行。等到放在内部暂存空间341与343中的输入数据都已经完成运算且产生出对应的opsum后,再把opsum的值由内部暂存空间345输出至fifo356(如(4)所示)。如此即可完成乘加运算。当然,以上乃是用以举例说明,本发明并不受限于此。本发明其他实施例可依需要而让运算单元340执行其他运算,并据以调整运算单元340的组成单元,其都在本发明精神范围内。
fifo352用以暂存行标签i_c_tag、f_c_tag、ip_c_tag,并输出至标签匹配单元310。fifo354用以暂存数据ifmapa、filtera与ipsuma,并输出至数据选择与调度单元320。fifo356用以暂存由运算单元340所产生的数据,并输出至重整单元360。
重整单元(reshaper)360用以根据频宽架构参数op_l将由fifo356所传来的数据重整成数据opsuma(例如输出数据opsuma为64位元而由fifo356所传来的数据为16位元,则将4个16位元的数据重整为1个64位元的数据),并回传给网络分配器120的数据分配器220,以写入至fifo237中,且回传至存储器。
在本发明一实施例中,输入至网络分配器110的数据可能是来自深度神经网络硬件加速器100的一内部缓冲器(未示出),其中该内部缓冲器可能是直接耦接至网络分配器110。或者,在本发明另一可能实施例中,输入至网络分配器110的数据可能是来自通过系统总线(未示出)而连接的一存储器(未示出),也即该存储器可能是通过系统总线而耦接至网络分配器110。
图4显示根据本发明一实施例的深度神经网络硬件加速器100的操作方法流程图。如图4所示,于步骤410中,分析目标数据量。在步骤415中,根据对该目标数据量的分析结果,设定各数据类型的频宽比率(ri、rf、rip、rop)。在步骤420中,以目前所设定的频宽比率(ri、rf、rip、rop)来计算延迟。在步骤425中,判断延迟是否符合标准,也即,判断目前所设定的频宽比率(ri、rf、rip、rop)所造成的延迟是否符合标准。如果步骤425为否,则回到步骤415,重新设定各数据类型的频宽比率(ri、rf、rip、rop)。如果步骤425为是,则重复上述步骤,直到完成对该目标数据量的各数据类型的频宽比率(ri、rf、rip、rop)的设定(步骤430)。在一实施例中,也可在对一层数据层执行步骤410~425之后,即执行步骤435。在一实施例中,也可同时(例如平行处理)执行超过一层或所有数据层的步骤410~425。在本发明一实施例中,步骤410-430可以由一微处理器动态/即时执行。在本发明一实施例中,步骤410-430可以由离线获得。
在步骤435中,在处理目标数据量时,根据所设定好的该目标数据量的各数据类型的频宽比率(ri、rf、rip、rop)来初始化该网络分配器110与处理单元阵列120的各处理单元122。在一实施例中,针对该目标数据量的频宽比率(ri、rf、rip、rop),由网络分配器110来调整/分配该数据类型的传输频宽;以及将频宽架构参数i_l、f_l、ip_l、op_l写入至各处理单元122。在一实施例中,将储存于频宽参数储存单元的该目标数据量的频宽比率(ri、rf、rip、rop)写入标签产生单元210和/或数据分配器220,并设定各处理单元122中的标签匹配单元310的行辨别号ic_id、f_c_id、ip_c_id和/或频宽架构储存单元330的频宽架构参数i_l、f_l、ip_l、op_l。在步骤440中,将数据(ifmap,filter,ipsum)由网络分配器110送至处理单元阵列120。在步骤445中,由处理单元阵列120的一个或多个被选处理单元122来处理数据。在步骤450中,判断是否已处理完目标数据量。如果步骤450为否,则流程回至步骤435,重复步骤435-445,直到处理完目标数据量。如果步骤450为是,则代表处理已完成。
现请参考图5,其显示根据本发明一实施例的实施例的深度神经网络硬件加速器的功能方块图。如图5所示,深度神经网络硬件加速器500至少包括:频宽与使用率分析(bandwidthandutilizationanalysis)单元512、控制器514、多工器516、518与处理单元阵列520。处理单元阵列520包括多个处理单元522。
频宽与使用率分析单元512进行目标数据量剖析(profiling),在此,目标数据量可为多个数据层、至少一数据层或一设定数据量。同样地,下文的说明以目标数据量为多个数据层为例来进行说明,但当知本发明不受限于此。频宽与使用率分析单元512进行各数据层的剖析,以得到在各数据层的各数据类型的分布情况。如此一来,频宽与使用率分析单元512可以据此得到各数据类型的适当传输频宽。在一实施例中,频宽与使用率分析单元512可以根据各数据层的频宽比率(ri、rf、rip、rop)得到各数据层的各数据类型的分布情况。在一实施例中,网络分配器110包括频宽与使用率分析单元512。
控制器514耦接至频宽与使用率分析单元512与多工器516与518。控制器514根据频宽与使用率分析单元512所设定的各数据类型的适当传输频宽来控制多工器516与518。
多工器516、518耦接至处理单元阵列520。多工器516、518都接收数据ifmap与filter。在本发明图5实施例中,多工器516的输出频宽(假设但不受限于为16位元)小于多工器518的输出频宽(假设但不受限于为64位元)。
举例说明如下。假设由缓冲器(未示出)送至图5的多工器516、518的数据ifmap与filter的位元分别为64位元与16位元。对于某一数据层而言,经由频宽与使用率分析单元512的剖析,数据ifmap的数据量大于数据filter。所以,经由控制器514的控制,多工器516(其输出频宽较小)选择将数据量较小的数据filter送至处理单元阵列520,而多工器518(其输出频宽较大)选择将数据量较大的数据ifmap送至处理单元阵列520。
同样地,对于另一数据层而言,经由频宽与使用率分析单元512的剖析,数据ifmap的数据量小于数据filter。所以,经由控制器514的控制,多工器516选择将数据量较小的数据ifmap送至处理单元阵列520,而多工器518选择将数据量较大的数据filter送至处理单元阵列520。
也即,在控制器514的控制下,多工器516固定输出输入数据的数据ifmap与filter中的数据量较小者给处理单元阵列520,而多工器518固定输出输入数据的数据ifmap与filter中的数据量较大者给处理单元阵列520。
通过上述的方式,可以把目前数据量需求较大的数据类型以较大的频宽送至处理单元阵列520,以提高处理效率。
现请参考图6,其显示根据本发明图5实施例的处理单元522的功能方块图。处理单元522包括匹配单元611与613,fifo621、623与625,重整单元631、633与635,暂存器640,处理单元控制器641,多工器643与645,运算单元650,以及缓冲单元661与663。
匹配单元611与613用以将数据1d1的行标签col_tag与数据2d2的行标签col_tag匹配于行辨别号col_id,其中数据1d1与数据2d2分别是数据ifmap与filter的其中一者与另一者。或者说,数据1d1由多工器516所传送,而数据2d2由多工器518所传送。如果行标签col_tag与行辨别号col_id两者匹配,则代表该笔数据需要该处理单元522处理,所以,数据1d1与数据2d2分别输入至fifo621与623。相反地,如果行标签col_tag与行辨别号col_id两者不匹配,则代表该笔数据不需要该处理单元522处理,所以,不需将数据1d1与数据2d2输入至fifo621与623。在一实施例中,数据1d1由图5的多工器516而来,数据2d2由图5的多工器518而来,数据1d1为16位元,数据2d2为64位元。
重整单元631、633耦接至fifo621、623与多工器643与645。重整单元631、633将由fifo621与623的输出数据给予重整,以输入至多工器643与645;重整单元可以将多位元数数据重整为少位元数数据,也可以将少位元数数据重整为多位元数数据。例如数据2d2为64位元,在将数据2d2存进fifo623后,以64位元输出到重整单元633,重整单元633将64位元的数据重整为16位元的数据输出到16位元的多工器643和多工器645;数据1d1为16位元,将数据1d1存进fifo621后,以16位元输出到重整单元631,重整单元631将16位元的数据重整为16位元的数据输出到16位元的多工器643和多工器645。在一实施例中,若是输入处理单元522的数据与输入运算单元650的数据的位元数相同,则可以省略重整单元,例如数据1d1为16位元,数据2d2为64位元,输入运算单元的数据为16位元,则重整单元631可以省略。
处理单元控制器641耦接至暂存器640与多工器643与645。处理单元控制器641根据暂存器640所暂存的频宽架构参数i_l、f_l来控制多工器643与645。详细地说,如果频宽架构参数i_l、f_l指示数据ifmap的传输频宽低于数据filter的传输频宽,则在处理单元控制器641的控制下,多工器643选择输出数据1d1(由传输频宽较小的多工器516所传来的数据)成为数据ifmapc且多工器645选择输出数据2d2(由传输频宽较大的多工器518所传来的数据)成为数据filterc。
相反地,频宽架构参数i_l、f_l指示指示数据ifmap的传输频宽高于数据filter的传输频宽,则在处理单元控制器641的控制下,多工器643选择输出数据2d2(由传输频宽较大的多工器518所传来的数据)成为数据ifmapc且多工器645选择输出数据1d1(由传输频宽较小的多工器516所传来的数据)成为数据filterc。
运算单元650耦接至多工器643与645。其组成与操作原则可相同或类似于图3的运算单元340,故其细节在此省略。
fifo625耦接至运算单元650与重整单元635。fifo625用以暂存由运算单元650所产生的数据。重整单元635用以将由fifo625所传来的数据重整成数据opsum(数据opsum可送至下一级处理单元522作累加,之后由最后一级处理单元522(如图5中的最右边的处理单元522)送至深度神经网络硬件加速器500的外部)。
缓冲单元661与663用以缓冲前一级处理单元522所送来的数据1及其行标签(d1,col_tag)与数据2及其行标签(d2,col_tag),并送至下一级处理单元522。缓冲单元661与663例如可以暂存器(register)实现。
图7显示根据本发明一实施例的深度神经网络硬件加速器的操作方法,包括:分析目标数据量(步骤710),以得到目标数据量的多个数据类型的分布情况并设定目标数据量的这些数据类型的个别传输频宽;由多个第一多工器接收一输入数据的一第一数据与一第二数据(步骤720);以及根据所设定的这些数据类型的这些传输频宽来控制这些第一多工器(步骤730),其中,这些第一多工器的一多工器输出该输入数据的该第一数据与该第二数据中的一数据量较小者给该深度神经网络硬件加速器的一处理单元阵列以进行处理,而这些第一多工器的另一多工器输出该输入数据的该第一数据与该第二数据中的一数据量较大者给该处理单元阵列以进行处理。至于步骤710-730的细节可参考图5与图6的说明,其细节在此省略。
在本发明一实施例中,对于同一数据层,可以使用相同的频宽分配与频宽比率,也可以使用不同的频宽分配与频宽比率,例如可以动态调整频宽分配与频宽比率,其细节在此省略,其也在本发明精神范围内。在本发明一实施例中,不同数据层可以使用不同的频宽分配与频宽比率,也可以使用相同的频宽分配与频宽比率。
本发明实施例可用于终端装置(例如但不受限于,智能型手机)上的人工智能(ai)加速器,也可用于服务器等级装置。
由上述可知,在本发明上述二个实施例中,通过离线或即时分析各数据层的数据类型的分布情况,使目前数据需求量大的数据类型以较大的频宽输入至处理单元阵列,如此可以使处理单元阵列可以较有效率的方式获得运算所需的输入数据,减少处理单元阵列因等待输入数据所造成的闲置情况。
综上所述,虽然本发明已以实施例公开如上,然其并非用以限定本发明。本发明的本领域的普通技术人员,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。
- 还没有人留言评论。精彩留言会获得点赞!