一种语音识别候选同音词的展示方法及设备与流程
本发明涉及语音识别技术领域,特别涉及一种语音识别候选同音词的展示方法及设备。
背景技术:
随着科技的发展,当前人们在智能设备(例如:各种移动设备、手持设备等)中使用应用程序时经常会用到语音识别的功能。但是,基于中文语言的博大精深,现有的语音识别准确率还不能达到99.99%。具体原因如下:
1.在机器软件中使用的中文编码一般都统一为gb2312编码。gb2312编码中共收录汉字6376个,其中不包括古代文字,而汉语有声母21个,韵母35个,声调四种,音节400个,可见,音节数量远小于汉字的数量。也就是说:汉语中包含大量的同音字和同音词。
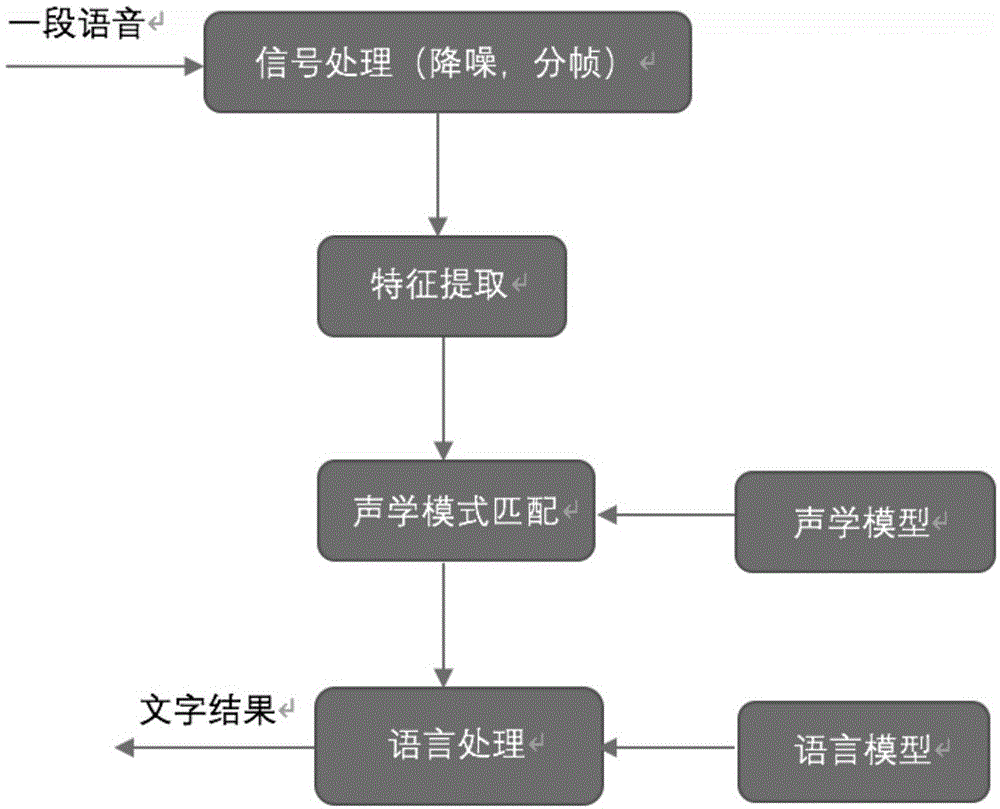
2.语音识别技术(autospeechrecognize,简称asr)是一种让机器能够“听懂”人类语音的技术。语音识别的主要流程如图1所示:
首先,对输入的一段语音进行信号处理,包括降噪、分帧等;
然后,基于信号处理的结果进行特征提取,再基于声学模型进行声学模式匹配;
最后,基于语言模型进行语言处理,得到对应于所述语音的文字结果。
根据图1所示流程,将语音具体转化成文字的功能是在语言处理阶段。语音处理的主要原理是:接收一段声学序列(可简单理解为拼音),根据大量经过文本训练的语言模型、上下文语义及统计规律给出对应于该声学序列的识别概率最大的结果,此结果即为最后识别出的文字。
下面通过一个简单举例说明上述过程:
第1步:语音录入:yuèfù。这里,由于专利文件需要用文字的方式进行表达,因而使用了拼音来表示,实际上输入的是对应于该拼音的声音信号。
第2步:对第一个音节yuè进行识别,识别出的文字可以有很多,例如:月、约、越、悦等等。因为还有下文录入,所以暂时先不返回结果。
第3步:对第二个音节fù进行识别,当结合上文就是yuèfù,此时,识别的结果将发生较大的变化,将排除日常使用中不成词的组合,例如:识别出的同音词选项可以有:岳父、月付、悦府、乐府等等。根据语言模型的判断,将在以上同音词中选择识别概率最高的词作为识别结果返回。
由于概率的算法是基于语言模型中大量的文本训练得出的。训练的文本越多,能够准确识别的概率就越高。但是,上述现有技术对于识别概率较少的上下文语义,以及在其他特殊情况中,识别的结果并不理想。
基于上述原因,在我们日常使用智能设备进行语音识别时,经常会遇到录入的语音是同音词,但是语音识别后显示的文字不是我们想要的目标词语。根据现有技术,当遇到这种情况时,通常都需要使用者用输入法手动重新输入文字,才能修改成目标词语。
可见,基于目前普遍的语音识别技术方案,如果有同音词语的语音录入的情况下,可能只能识别出使用率较高的词汇,而无法正确识别出录入者想要表达的词汇。如上举例,识别出的最高概率的词语是“月付”,但是录入者的本意却是“岳父”。如需要修改只能删除原有文字重新手动打字输入。当录入的文本较多时,还需要逐行寻找需要修改的部分。以上问题的存在,严重影响了智能设备的智能性。
技术实现要素:
本发明实施例提供了一种语音识别候选同音词的展示方法、设备及计算机可读存储介质,以避免语音识别中需要用户重新手动打字输入的问题。
本申请实施例公开了一种语音识别候选同音词的展示方法,包括:
从服务器接收语音识别后的数据;
对所述数据进行解析,判断所述数据中是否有候选词;
如果有候选词,则将识别概率最高的词作为主词以超链接的方式进行展示,所述主词可点击。
较佳的,该方法还包括:
在所述主词的下方加下划线;
或者,以不同于其他词的颜色展示所述主词;
或者,在所述主词的下方加下划线、且以不同于其他词的颜色展示所述主词。
较佳的,该方法还包括:
当检测到对所述主词的点击操作时,用候选词展示框展示所述主词的候选词。
较佳的,按照识别概率从高到低的顺序依次展示所述主词的候选词。
较佳的,该方法还包括:
当检测到对任一候选词的选择操作时,将所选择的候选词展示在主文本中,并隐藏候选词展示框。
较佳的,所述将所选择的候选词展示在主文本中包括:
以超链接的方式展示所选择的候选词,该候选词可点击。
较佳的,在所述展示在主文本中的候选词的下方加下划线;
或者,以不同于其他词的颜色显示所述展示在主文本中的候选词;
或者,在所述展示在主文本中的候选词的下方加下划线,且以不同于其他词的颜色显示所述展示在主文本中的候选词。
较佳的,该方法还包括:
当检测到对展示在主文本中的候选词的点击操作时,用候选词展示框展示所述主词和其他候选词。
本申请实施例还公开了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
从服务器接收语音识别后的数据;
对所述数据进行解析,判断所述数据中是否有候选词;
如果有候选词,则将识别概率最高的词作为主词以超链接的方式进行展示,所述主词可点击。
较佳的,所述处理器执行所述程序时还实现以下步骤:
在所述主词的下方加下划线;
或者,以不同于其他词的颜色展示所述主词;
或者,在所述主词的下方加下划线、且以不同于其他词的颜色展示所述主词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对所述主词的点击操作时,用候选词展示框按照识别概率从高到低的顺序依次展示所述主词的候选词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对任一候选词的选择操作时,将所选择的候选词以超链接的方式展示在主文本中,该候选词可点击,并隐藏候选词展示框。
较佳的,所述处理器执行所述程序时还实现以下步骤:
在所述展示在主文本中的候选词的下方加下划线;
或者,以不同于其他词的颜色显示所述展示在主文本中的候选词;
或者,在所述展示在主文本中的候选词的下方加下划线,且以不同于其他词的颜色显示所述展示在主文本中的候选词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对展示在主文本中的候选词的点击操作时,用候选词展示框展示所述主词和其他候选词。
本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现权利要求1-8任一项所述的方法步骤。
本发明实施例提出上述语音识别候选同音词的展示方法和设备,通过对现有智能终端的语音识别功能进行改进,对于有同音词的语音识别结果,同时展示识别出的多个候选同音词供用户选择,使得用户可以用点击选择的方式选择候选词,从而提高了智能设备在语音识别中的智能性,避免了语音识别中需要用户重新手动打字输入的问题。
附图说明
图1为现有语音识别的主要流程示意图;
图2为本发明实施例一中语音识别候选同音词的展示方法流程示意图;
图3为常用的json数据格式示例图;
图4为本发明实施例一中一示例性展示识别概率最高的词的界面示意图;
图5为本发明实施例二中语音识别候选同音词的交互选择方法流程示意图;
图6为本发明实施例二中一示例性展示候选词的界面示意图;
图7为本发明实施例二中展示用户选择的候选词的界面示意图;
图8为本发明实施例二中一展示候选词的候选词展示框的界面示意图;
图9为本发明实施例中一电子设备的组成结构示意图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明作进一步详细说明。
本发明实施例提出一种对智能终端的语音识别功能进行改进的技术方案,对于有同音词的语音识别结果,同时展示识别出的多个候选同音词供用户选择,使得用户可以用点击选择的方式进行选择,从而提高了智能设备在语音识别中的智能性,避免了语音识别中需要用户重新手动打字输入的问题。
本发明实施例提供的一种语音识别候选同音词的展示方法包括以下步骤:
首先,从服务器接收语音识别后的数据;
然后,对所述数据进行解析,判断所述数据中是否有候选词;
如果有候选词,则将识别概率最高的词作为主词以超链接的方式进行展示,所述主词可点击。
其中,可以通过在所述主词的下方加下划线,或者以不同于其他词的颜色展示所述主词,或者在所述主词的下方加下划线且以不同于其他词的颜色展示所述主词等方式来展示所述主词,以使主词区别于其他文字。
如前所述,主词可点击,当检测到对所述主词的点击操作时,用候选词展示框展示所述主词的候选词,从而将可供选择的候选词展示给用户。在对候选词进行展示时,可以按照识别概率从高到低的顺序依次进行展示。
此外,当检测到对任一候选词的选择操作时,表明用户希望将该词作为新的候选词,因此,将所选择的该候选词展示在主文本中,并隐藏之前显示的候选词展示框。其中,在展示所选择的候选词时,可以采用如前所述的以超链接的方式进行展示,并且该候选词可点击。
同样的,对于展示在主文本中的候选词,也可以采取在其下方加下划线,或者以不同于其他词的颜色,或者在其下方加下划线且以不同于其他词的颜色进行显示。
当检测到对展示在主文本中的候选词的点击操作时,用候选词展示框展示所述主词和其他候选词,从而将可供选择的其他候选词展示给用户。
下面通过三个较佳实施例对本申请技术方案进行进一步详细说明:
实施例一:
本发明实施例一提供的一种语音识别候选同音词的展示方法流程示意图如图2所示,包括以下步骤:
步骤1:客户端从服务器接收语音识别后的数据。
本实施例中,客户端是指智能设备中提供语音识别功能的应用程序客户端。
在服务器语音识别的过程中,根据现有的语音模型算法,服务器需要提取1-n个同音词返回给客户端,例如,常用的json数据格式示例如图3所示:
仍然以背景技术所举的“yuèfù”为例,服务器将返回月付、岳父和乐府这3个同音词给客户端,并分别给出这3个词的识别概率:0.87、0.67和0.32。
步骤2:客户端解析服务器返回的数据。
步骤3:客户端判断返回的数据中是否有候选词,如果有候选词,则执行步骤4;否则,按常规方式进行展示,结束。
步骤4:将识别概率最高的词作为词以类似超链接的方式进行展示,在该词下方加下划线,并且可点击。
较佳的,还可以对该词以不同于其他词的颜色进行展示。本实施例中,将识别概率最高的词称为“主词”,“主词”是相对于“候选词”而言的。
一示例性展示识别概率最高的词的界面如图4所示。根据本实施例步骤1,“月付”的识别概率最高,因此,本实施例在图4所示界面中,以超链接的方式显示“月付”,该主词可以点击,且“月付”为蓝色字体,并带有下划线。
实施例二:
按照实施例一对识别概率最高的词进行展示之后,可以进一步按照本发明实施例二提供的交互方法对候选同音词进行选择,如图5所示,包括:
步骤1:检测用户的点击操作。
步骤2:如果用户点击操作所对应的词可点击,则表明该词有候选词,执行步骤3,否则,结束。
步骤3:用候选词展示框展示该词的候选词。
一示例性展示候选词的界面如图6所示,图6所示界面展示了“月付”的两个候选词:“岳父”和“乐府”。较佳的,可以按照识别概率从高到低的顺序依次显示候选词,最多显示n个,例如:n等于3。如显示不下,可滑动查看。
步骤4:当检测到用户选择任一候选词时,执行步骤5。
步骤5:将用户选择的候选词作为新的主词,展示在主文本中,并隐藏候选词展示框。
较佳的,对于用户选择的候选词也可以以类似超链接的方式进行展示,在该词下方加下划线,并且可点击。假设用户选择的是“岳父”,展示界面如图7所示。
当用户再次点击当前的主词“岳父”时,原来的主词“月付”与其他候选词“乐府”一起展示在候选词展示框中,如图8所示。对于同一个词,可以通过重复点击切换候选词。
实施例三:
上述实施例二根据用户的选择以某候选词替换了原来的主词。对于展示在候选词展示框中的主词,也可以通过再次选择的方式将其恢复为主词,本实施例对此进行说明。
参见实施例二中的图8,继续按照以下步骤执行:
步骤1:当检测到用户点击当前的主词“岳父”时,将原来的主词“月付”与其他候选词“乐府”一起展示在候选词展示框中。
步骤2:当检测到用户选择候选词展示框中的“月付”时,执行步骤3。
步骤3:将用户选择的“月付”作为新的主词,展示在主文本中,并隐藏候选词展示框。
至此,原来的主词“月付”又重新成为了主词显示在主文本框中,而其他候选词隐藏起来。
对应于上述方法,本申请实施例还提供了一种电子设备,其组成结构如图9所示,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
从服务器接收语音识别后的数据;
对所述数据进行解析,判断所述数据中是否有候选词;
如果有候选词,则将识别概率最高的词作为主词以超链接的方式进行展示,所述主词可点击。
较佳的,所述处理器执行所述程序时还实现以下步骤:
在所述主词的下方加下划线;
或者,以不同于其他词的颜色展示所述主词;
或者,在所述主词的下方加下划线、且以不同于其他词的颜色展示所述主词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对所述主词的点击操作时,用候选词展示框按照识别概率从高到低的顺序依次展示所述主词的候选词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对任一候选词的选择操作时,将所选择的候选词以超链接的方式展示在主文本中,该候选词可点击,并隐藏候选词展示框。
较佳的,所述处理器执行所述程序时还实现以下步骤:
在所述展示在主文本中的候选词的下方加下划线;
或者,以不同于其他词的颜色显示所述展示在主文本中的候选词;
或者,在所述展示在主文本中的候选词的下方加下划线,且以不同于其他词的颜色显示所述展示在主文本中的候选词。
较佳的,所述处理器执行所述程序时还实现以下步骤:
当检测到对展示在主文本中的候选词的点击操作时,用候选词展示框展示所述主词和其他候选词。
本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本申请实施例所述语音识别候选同音词的展示方法的步骤。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!