基于关联图谱表征学习的线上交易欺诈检测方法与流程
本发明涉及互联网金融网络交易的反欺诈检测。
背景技术:
随着移动互联网的兴起,各种传统的业务逐渐转至线上,互联网金融,电子商务迅速发展,网络在线交易的产生将带来大量的电子交易数据,同时伴随着在线支付欺诈交易数量的大量增加。攻击者通过窃取用户账户,盗取个人隐私信息,甚至恶意攻击服务器等方式来完成欺诈。为保障用户和公司业务安全,需要建立切实有效的网络交易欺诈检测系统。
目前传统的网络交易欺诈检测系统通常是基于传统的机器学习方式,检测欺诈的性能非常依赖与欺诈特征的设计。如何设计一组能够精准刻画欺诈特征的特征组合,往往需要依赖精通业务规则和掌握特征工程技巧,这需要耗费极大的人力成本,所以亟需一个可以自动学习的、自适应于数据变化的网络交易欺诈检测方法来解决这些问题。近年来,网络表征学习在数据挖掘和机器学习领域都引起极大关注,并取得不错的成果,这也为线上交易欺诈检测的发展带来新的契机。在互联网金融场景下,数据往往以关联大数据的形式存在,例如:交易卡号与交易卡号之间相互联系形成转账网络、交易中不同属性的频繁共同出现形成互联网金融网络大数据等。在上述场景中,网络的节点自然对应交易中的属性,具有强大灵活表征能力的网络结构成为关联大数据最自然和直接的表达方式。于是如何对网络结构进行分析与设计是需要研究的问题。同时,针对网络结构进行网络表征学习得到网络中节点的向量表示后,如何应用于后续的欺诈检测任务使得模型可以准确地区分异常交易,也是需要研究的问题。
为此,本发明研究基于关联图谱表征学习的线上交易欺诈检测方法。从而利用关联图谱和网络表征学习对线上交易数据重新表征,降低了拦截欺诈交易的专业性和成本,同时提高了欺诈检测模型的鲁棒性。
本发明是在《一种基于个体行为建模的面向线上交易欺诈检测方法》(申请号201811579237.4,申请日2018年12月24日)基础上进一步创新。
技术实现要素:
得益于当前互联网金融产生的丰富交易信息数据,我们可以分析并以此作为基础,设计反欺诈检测系统,保护用户和企业的安全。
在互联网金融中,业务数据是由一系列属性刻画的,不同的属性间往往存在关联关系,我们通过关联图谱技术将关系型的业务数据用图的形式表示,并在此基础上设计出可以用于异质网络表征学习的异质信息网络。然后利用异质网络表征方法针对异质信息网络学习到其每一个节点向量表示,这些向量保留原网络的结构特性并隐含有利于欺诈检测的潜在特性,实现了自动从数据中抽取特征的过程,减少了对相关业务专家和特征工程的依赖。相较于中国发明申请号201811579237.4《一种基于个体行为建模的面向线上交易欺诈检测方法》中个体模型方法检测一个主体(如卡号)下所带有行为的区别,即行为偏离自身正常行为的可能性。而本发明基于分类器的方法学习所有主体统一的行为模型,对新到来交易和现有所有行为对比,从而区分异常交易。
本发明基于交易属性中节点的向量表示,我们计算任意两个节点之间的相似度,进而将交易数据的特征由属性值转化为属性对应节点之间的相似度。通过将交易数据含有相似度应用到已有的分类器,简化了欺诈检测过程中的超参数设定(如:基于个体模型的方法往往需要设定大量的超参数),对比新到来的交易与模型学习到的异常交易和正常交易之间的区别,实现欺诈检测功能。本发明基于关联图谱设计异质信息网络和网络表征学习自动化表征属性节点,设计出一种基于关联图谱表征学习的线上交易欺诈检测方法,解决了传统欺诈检测系统存在专业性强、适应性弱的弊病,为互联网金融信息化时代网络交易安全问题的解决提供了新的思路和解决方法。
传统的机器学习方法依赖特征,需要耗费大量工作进行特征工程,对业务专家的依赖程度高。中国发明申请号201811579237.4《一种基于个体行为建模的面向线上交易欺诈检测方法》中,该基于个体模型的方案,个体的行为模型与数据存在一定的耦合性,当数据变化时,其模型参数也需对应变化,适应性较弱。
本发明在于克服传统欺诈检测方法的不足,节省了大量特征工程工作量,自动得到有利于欺诈检测的特征,对检测欺诈交易、拦截欺诈交易和保护用户和企业的资金安全有更好的保障。
本发明需要保护的技术方案表征为:
基于关联图谱表征学习的线上交易欺诈检测方法,其特征在于,包括两个步骤部分,
第一个部分利用关联图谱生成异质信息网络和利用异质网络表征学习自动抽取特征,得到交易属性的向量表示;
第二个部分在学习到交易属性的向量表示情况下,基于分类器实现预测交易异常可能性的过程。
具体说,
所述第一部分,关联图谱生成异质信息网络与异质网络表征学习,其过程如下:
输入:
用户网络支付交易的原始数据字段,
调节权重参数α,β,δ,
网络表征学习方法参数。
输出:
原始交易数据对应的节点ε与向量γ的映射关系γ=f(ε)。
步骤1.1根据用户当笔交易原始数据字段筛选有用字段,进行数据预处理:针对取值范围是连续的字段设定离散化规则,将连续的值离散化。执行步骤1.2。
步骤1.2将交易数据以交易单号为中心建立关联图谱,一笔交易中的字段在关联图谱中与交易单号存在边,则表示该字段出现在所连交易单号对应的交易中。在关联图谱中,不同的交易字段存在边表示两种交易字段存在额外用户指定的联系,关联图谱在不同笔交易之间建立联系,将关系型的交易数据转化为图结构表示。形成的关联图谱。执行步骤1.3。
步骤1.3构建异质信息网络时,在步骤1.2形成的关联图谱上提取关系,形成接近稠密图的网络结构,将关联图谱中形式为‘交易字段1—交易单号—交易字段2’的结构简化为‘交易字段1—交易字段2’,进而得到一个仅含有交易字段且结构稠密的异质信息网络。执行步骤1.4。
步骤1.4在步骤1.3所构建的异质信息网络中,边的类型由其两个端点的类型决定,针对每一种边类型,设定不同的权重值区分字段间的重要性。一条多次出现边的权重由该边的出现次数和对应的权重值之积表示;设计公式(1)来进行权重变换,将任意边的权重映射到区间[0,1],进而缩小权重之间的巨大差异。执行步骤1.5。公式(1)中w表示一条边所对应的权重值,
步骤1.5基于已构建的异质信息网络,采用现有的异质网络表征学习方法hin2vec来学习网络中节点的向量表示。将步骤1.4中的异质信息网络作为hin2vec算法的输入,可以得到网络中节点ε与其对应的向量表示γ,进而得到映射关系γ=f(ε)。
所述第二部分.基于节点的向量表示与分类器,实现预测交易异常可能性的过程,其过程如下:
输入:
节点ε与对应向量γ的映射关系γ=f(ε),
分类器参数集w
待检测交易数据的集合t。
输出:
交易数据为异常的概率p。
步骤2.1一笔含有n个可用原始字段的交易t(t∈t,t为待检测交易数据的集合)在异质信息网络中可对应n个相应的节点。基于上述n个节点和映射关系γ=f(ε),得到k
执行步骤2.2。
步骤2.2基于余弦相似度的集合{cos1,···,cosk},计算该集合的均值avg与方差var。将一笔交易数据由{交易字段,···,交易字段}的表示形式,通过表征学习转化为{cos1,···,cosk,avg,var}来表示一条交易数据。均值avg与方差var的计算方法如公式(3)和公式(4)所示。执行步骤2.3。
步骤2.3基于待检测交易数据的集合t,将交易数据按时间顺序排列,将发生交易时间据当前较远的交易数据作为训练集,将较后发生的交易数据作为测试集。分类器对模型进行训练,得到模型。
步骤2.4对实时检测一笔新来的在线交易数据时,执行步骤2.1与步骤2.2将数据处理为分类器能接受的特征组合,将待检测数据对应的特征放入步骤2.3所得的分类器模型中,进行判别预测,得到该笔交易存在欺诈的可能性。
附图说明
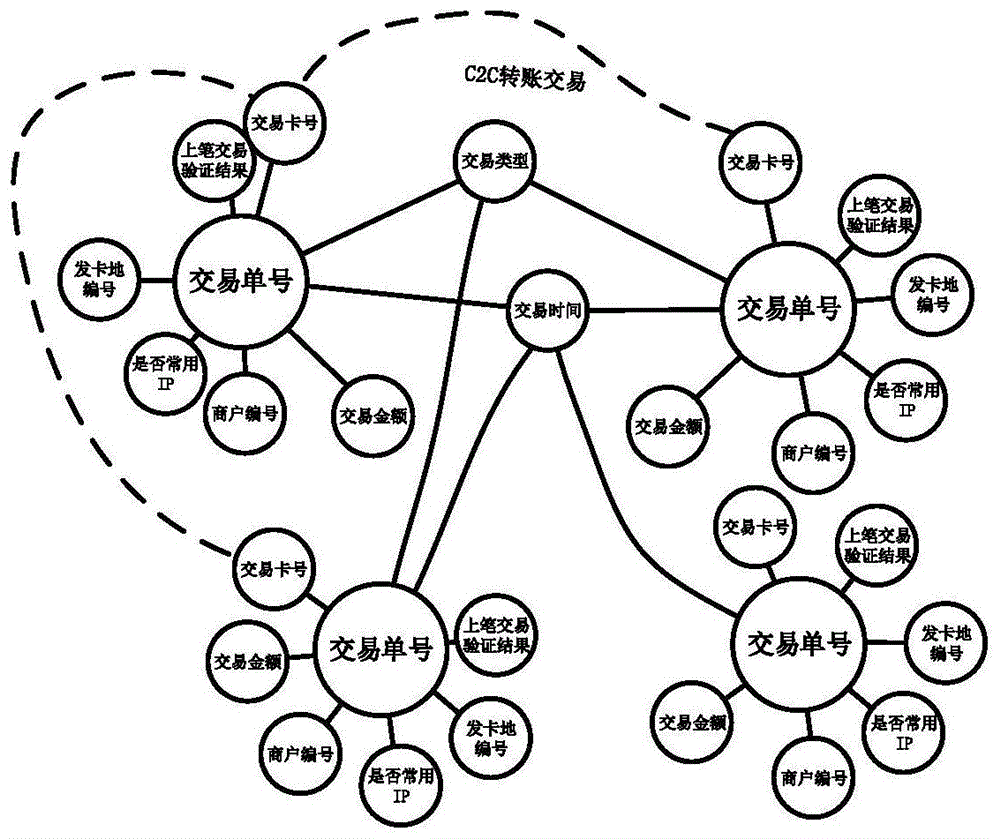
图1网络交易场景的关联图谱示例图。
图2本发明的基于关联图谱表征学习的线上交易欺诈检测方法系统结构图。
图3基于关系型数据生成异质信息网络示意图。
图4训练样本与测试样本划分示意图。
具体实施方式(案例)
基于关联图谱表征学习的线上交易欺诈检测方法系统结构图,如图2所示。整个方案分为两个部分:
第一个部分利用关联图谱生成异质信息网络和利用异质网络表征学习自动抽取特征,得到交易属性的向量表示;
第二个部分在学习到交易属性的向量表示情况下,基于分类器实现预测交易异常可能性的过程;
所述第一部分,关联图谱生成异质信息网络与异质网络表征学习,其过程如下:
输入:
用户网络支付交易的原始数据字段,
调节权重参数α,β,δ,
网络表征学习方法参数。
输出:
原始交易数据对应的节点ε与向量γ的映射关系γ=f(ε)。
步骤1.1根据用户当笔交易原始数据字段筛选有用字段(如表1可利用原始字段所示),进行数据预处理:针对取值范围是连续的字段设定离散化规则,将连续的值离散化。如:将交易时间字段划分为工作日、非工作日两种取值,将交易金额对100取模划分为有限数量的整值金额等。执行步骤1.2。
步骤1.2将交易数据以交易单号为中心建立关联图谱,一笔交易中的字段在关联图谱中与交易单号存在边,则表示该字段出现在所连交易单号对应的交易中。在关联图谱中,不同的交易字段存在边表示两种交易字段存在额外用户指定的联系,如:不同的交易卡号之间存在转账行为、不同的发卡地区在地理上相接触等潜在的联系。关联图谱在不同笔交易之间建立联系,将关系型的交易数据转化为图结构表示。基于表1可利用原始字段所示字段,形成的关联图谱示例如图1所示。执行步骤1.3。
步骤1.3构建异质信息网络时,无需考虑交易数据的异常与否,将正常数据、异常数据一起放入关系图谱中,得到包含所有交易数据的异质信息网络。(此处是本发明的创新之处。中国发明申请号201811579237.4《一种基于个体行为建模的面向线上交易欺诈检测方法》中个体模型使用交易数据需考虑数据标签,即针对异常数据和正常数据区别对待,本方法中无需考虑数据的区别。)在关联图谱中,交易中的字段大多与交易单号相连接,交易单号的唯一性导致关联图谱结构的稀疏性。为此,我们进一步在步骤1.2形成的关联图谱上提取关系,形成接近稠密图的网络结构。由于一笔交易中的任意字段均通过交易单号与其他字段相连接,我们将关联图谱中形式为‘交易字段1—交易单号—交易字段2’的结构简化为‘交易字段1—交易字段2’,进而得到一个仅含有交易字段且结构稠密的异质信息网络。执行步骤1.4。
步骤1.4在步骤1.3所构建的异质信息网络中,边的类型由其两个端点的类型决定,针对每一种边类型,设定不同的权重值(边的权重值越大,其对应端点拥有更相似的向量表示)区分字段间的重要性。一条多次出现边的权重由该边的出现次数和对应的权重值之积表示。由于不同的类型的边出现的频次存在较大差异,不利于在网络表征学习过程中自动化抽取特征。为此我们设计公式
步骤1.5基于已构建的异质信息网络,拟采用现有的异质网络表征学习方法hin2vec来学习网络中节点的向量表示,同时避免手动提取特征的麻烦,自动化抽取特征信息。(本发明技术方案创新后得到效果)方法hin2vec学习向量表示的主要参数如表2hin2vec主要参数所示,参数的设定与网络的结构有关,可参考文献[1]。将步骤1.4中的异质信息网络作为hin2vec算法的输入,可以得到网络中节点ε与其对应的向量表示γ,进而我们得到映射关系γ=f(ε)。
表1可利用原始字段
表2hin2vec主要参数
所述第二部分.基于节点的向量表示与分类器,实现预测交易异常可能性的过程,其过程如下:
分类器环境:
python,xgboost分类器
输入:
节点ε与对应向量γ的映射关系γ=f(ε),
分类器参数集w
待检测交易数据的集合t。
输出:
交易数据为异常的概率p。
步骤2.5一笔含有n个可用原始字段的交易t(t∈t,t为待检测交易数据的集合)在异质信息网络中可对应n个相应的节点。基于上述n个节点和映射关系γ=f(ε),我们可以得到k
执行步骤2.2。
步骤2.6基于余弦相似度的集合{cos1,···,cosk},我们计算该集合的均值avg与方差var。我们将一笔交易数据由{交易字段,···,交易字段}的表示形式,通过表征学习转化为{cos1,···,cosk,avg,var}来表示一条交易数据。均值avg与方差var的计算方法如公式(3)和公式(4)所示。执行步骤2.3。
步骤2.7基于待检测交易数据的集合t,将交易数据按时间顺序排列,将发生交易时间据当前较远的交易数据作为训练集,将较后发生的交易数据作为测试集。如图4所示,依据时间顺序划分数据集,可防止出现时间穿越问题(用未发生的数据训练模型,导致模型提前学习到现实中尚未发生的规则)。本方法中采用python开发环境下的xgboost库中的xgboost分类器对模型进行训练,得到模型。
步骤2.8对实时检测一笔新来的在线交易数据时,执行步骤2.1与步骤2.2将数据处理为分类器能接受的特征组合,将待检测数据对应的特征放入步骤2.3所得的xgboost分类器模型中,进行判别预测,可以得到该笔交易存在欺诈的可能性。
(此处第二部分主要基于现有分类器实现交易数据的异常检测,是本发明的创新之处,主要对数据重新组合得到新特征,放入分类器得到更好的结果,代替了特征工程中对特征重组的过程。而中国发明申请号201811579237.4《一种基于个体行为建模的面向线上交易欺诈检测方法》为个体模型需要自己设定建模的方法。)
本发明通过在真实互联网金融银行交易数据集上进行检测证明,得出在打扰率(误拦截率)小于1%,0.5%,0.1%和0.05%时的召回率(拦截率),并由此来评价系统的性能,该方法在此指标上和计算时间上都优于先前的研究,并且有着较好的鲁棒性。
本项目的创新点
1.通过建立线上交易的关联图谱,将交易属性之间的关系以图的形式表现,同时基于上述关联图谱构建异质信息网络并进行表征学习,实现自动从数据中抽取特征,优化了模型的适应性和鲁棒性,减少了模型对业务知识的依赖程度;
2.利用网络表征学习得到的向量,将节点之间的相似性作为交易数据新的特征,输入已有分类器返回交易数据的异常概率,设置阈值区分正常交易和异常交易,实现欺诈检测功能,对比传统方法大大简化了特征工程过程。
批注:本发明中的有关术语以及对于先前的主要技术可参见如下资料。
[1]fut,leewc,leiz.hin2vec:exploremeta-pathsinheterogeneousinformationnetworksforrepresentationlearning[c]//proceedingsofthe2017acmonconferenceoninformationandknowledgemanagement.acm,2017:1797-1806.
[2]dongy,chawlanv,swamia.metapath2vec:scalablerepresentationlearningforheterogeneousnetworks[c]//proceedingsofthe23rdacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.acm,2017:135-144.
[3]huangz,mamoulisn.heterogeneousinformationnetworkembeddingformetapathbasedproximity[j].arxivpreprintarxiv:1701.05291,2017.
[4]shangj,qum,liuj,etal.meta-pathguidedembeddingforsimilaritysearchinlarge-scaleheterogeneousinformationnetworks[j].arxivpreprintarxiv:1610.09769,2016.
[5]chenz,jiangf,chengy,etal.xgboostclassifierforddosattackdetectionandanalysisinsdn-basedcloud[c]//2018ieeeinternationalconferenceonbigdataandsmartcomputing(bigcomp).ieeecomputersociety,2018.
[6]sheny,wangg,karimihr.data-drivendesignofrobustfaultdetectionsystemforwindturbines[j].mechatronics,2014,24(4):298-306.
[7]perozzib,al-rfour,skienas.deepwalk:onlinelearningofsocialrepresentations[c]//proceedingsofthe20thacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.acm,2014:701-710.
- 还没有人留言评论。精彩留言会获得点赞!