基于MINMAX局部优化结构化网格负载平衡方法与流程
本发明涉及提高结构化网格并行计算时的负载平衡方法,尤指基于遗传算法和minmax(最大最小)局部优化的并行负载平衡方法。
背景技术:
计算已经与理论和实验相并列成为人类认识世界三种主要研究手段,主要用来解决不可能进行实验的问题或者进行实验代价太大的问题。近几十年以来,随着对物理规律认识的深入和工程应用的需要,工程计算已发展成为一门专门学科,在航空航天、汽车、环境工程、材料、物理学和船舶等方面得到广泛应用。工程计算过程主要是对网格上的特征量进行迭代计算,网格数目与计算量直接相关。当网格数目多时整个计算量非常大,往往需要在高性能计算机进行大规模并行计算。
良好的负载平衡是达到高并行效率的基础。结构化网格工程常用的并行计算技术一般基于分区并行,分区并行的数学基础是区域分解算法。区域分解算法将问题的求解区域划分成多个子区域,这些子区域相互包含相邻区域的拟边界信息,相互迭代共同求解同一问题。并行计算与区域分解算法相结合,将各个网格块分配给多个处理器核完成,迭代过程中一般采用mpi(messagepassinginterface)消息传递接口在不同处理器核之间进行通信。由于分区并行的网格块一般比较大,计算通信比高,影响并行效率的决定性因素是负载平衡。由于数值离散迭代求解的特点,一次迭代的计算量与网格量成正比。实际工程设计中外形各异,根据计算模型几何上的特性进行分区,整个网格会事先分割成大小不同的很多个网格块。负载平衡的核心思想是把全部网格块映射到各个进程上,在进程数确定的情况下尽可能使总计算时间少。
结构化网格并行计算时,可以近似认为迭代求解过程中的计算量正比于网格量。在高性能计算机系统进行并行计算时,实际应用中一般采用同构系统,即各个计算节点/核的计算能力是一样的。各个进程的每次迭代的计算时间由其所负责的网格数目总和决定是合理的。在不考虑通信的前提下,结构化网格并行计算时间由网格数目总和最大的进程决定。
结构化网格工程并行计算负载平衡主要可以分成不带剖分和带剖分两种方式。带剖分方法指通过在其他方法的基础上,对生成的网格块进行进一步剖分来达到负载平衡。带剖分方法存在三个缺点:
(1)过细的分块会导致额外的通讯开销大量增加而降低并行计算效率。
(2)过多的子区域(分块)会增加迭代求解次数,影响计算效率,这是由区域分解算法本身的特性决定的。
(3)工程计算不仅是一门科学,也是一门艺术,不但与数值计算方法相关,也与网格相关,不适当的分块有可能导致计算发散。
不带剖分方法指网格分块确定的情况下,采用确定性或者智能优化算法来达到负载平衡。不带剖分方法能够避免带剖分方法存在的缺点,但是有时候会存在负载平衡率低和计算效率低的缺点。
对于结构化网格并行计算不带剖分方法的负载平衡算法研究主要集中在以下三个方面:
(1)确定性方法,主要指基于组合优化排和排序理论设计了lpt(largestprocessingtime)近似负载平衡算法。
(2)智能优化算法,主要指基于全局优化的遗传算法等算法设计的智能优化负载平衡算法。
(3)混合算法,主要指结合确定性方法和智能优化算法的负载平衡算法,包括二步。第一步使用确定性方法得到初步解,第二步在此基础上使用智能优化算法力图得到负载平衡率更高的网格块分配方法。
基于遗传算法的结构化网格负载平衡方法是智能优化算法的一种。
结构化网格并行负载平衡问题模型可以定义如下:
遗传算法是一种模拟自然界优胜劣汰的进化算法,具有较高的全局搜索能力。结构化网格并行负载平衡中的遗传算法中染色体采用二级编码。
基因定义为e中一个网格块。基因值为该网格块的网格数目,为正整数,为e1到en中的一个值。所以共有n个基因。
染色体片段定义为p中单个进程处理的所有网格块的集合,所以共有m个染色体片段。染色体片段值定义为染色体片段中对应基因代表的网格块的网格数目之和,为非负整数。如染色体片段{e1,e2,e3}的染色体片段值为e1+e2+e3。
染色体定义为染色体片段的集合,每一条染色体代表一种负载平衡分配方案,即为网格块分配到进程的一种分配方案。每一条染色体包含m个染色体片段,每个染色体片段包含若干个网格块(基因)。染色体片段的长度即为所包含的基因的个数。如10个网格块{e1,e2,…,e10}、3个进程,进程序号为第1、第2、第3,一条染色体可以表示为{{e1,e2,e3},{e4,e5,e6,e7},{e8,e9,e10}},就表示一种负载平衡模式。{e1,e2,e3}为一个染色体片段,长度为3。e1,e2,…,e10为基因。1-3个网格块分配给第1个进程,4-7个网格块分配给第2个进程,8-10个网格块分配给第3个进程。
种群定义为染色体的集合,即一个种群包含正整数条染色体。种群大小popnum为种群中染色体的数目。
种群大小popnum为种群中染色体的数目,表示有popnum个负载平衡策略。一个染色体中有n个基因,m个染色体片段,表示有n个网格块,m个进程。一个染色体代表一个把n个网格块分配给m个进程的策略。
适应度函数f定义如下:
f=1/max{|p1|,...,|pm|,...,|pm|}(1)
max{|p1|,...,|pm|,...,|pm|}表示对|p1|,...,|pm|,...,|pm|取最大值。对于任何一个负载平衡分配方案,f值越大表示负载平衡方案越好。
全局最优染色体(bestpop)表示种群中适应度值最大的染色体(也即最好的负载平衡模式)。
输入文件为包含所有网格块的文件。这里,文件中的一个正整数表示一个网格数目为该正整数的网格块。
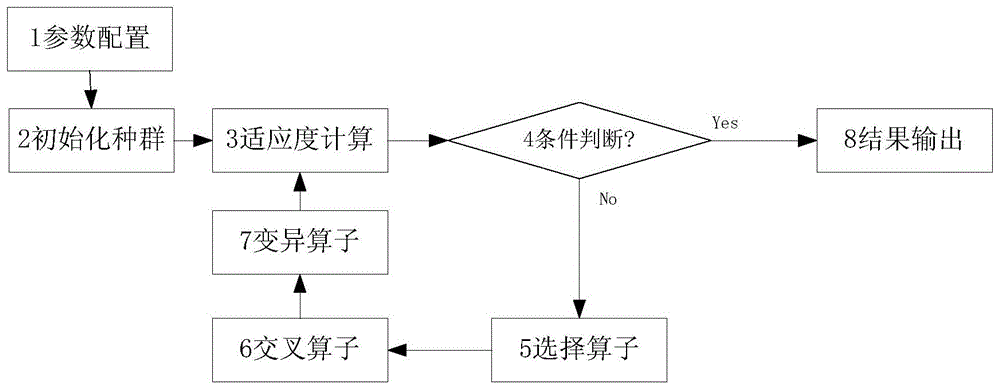
基于遗传算法的结构化网格负载平衡方法(简称背景技术1)总体流程如图1所示,包括参数配置、初始化种群、适应度计算、条件判断、选择算子、交叉算子、变异算子和结果输出8个步骤。具体步骤如下:
第一步,参数配置。从配置文件获得输入文件位置、种群大小popnum、最大迭代次数itemax、平衡率阀值ε、交叉概率pcross、变异概率pvari这些参数。ε可取0.1、0.01或者0.01。popnum可取基因数的10-100倍,itemax可取基因数的5倍。交叉概率pcross、变异概率pvari为0到1之间的实数,pcross可取0.8,pvari可取0.1。
第二步,初始化种群。
2.1从输入文件中读取所有网格块,把所有网格块随机分配到各个进程,生成含popnum条染色体的种群popa,popa={r1,..,rn...,rpopnum},popnum为popa中染色体条数,1≤n≤popnum且n为正整数,rn表示第n条染色体。所有染色体均有m个片段,对应m个进程。
2.2初始化迭代次数itenum=0。
第三步,适应度计算
3.1对popa中的r1,...,rr,...rpopnum采用式(1)分别进行适应度计算,得到popnum个适应度值,表示为f1,...,fr,...fpopnum。
3.2找出f1,...,fr,...fpopnum中的最大值,表示为fopt,并将fopt对应的全局最优染色体记为bestpop。
3.3itenum=itenum+1。
第四步,条件判断。
4.1若itenum>itemax,迭代终止,转第八步。若itenum<=itemax,转4.2。
4.2若fopt满足式(2)的条件,迭代终止,表示已找到最优染色体,转第八步。否则,转第五步。
abs(κ-1/fopt)/κ<ε(2)
其中κ为平均负载,ε为平衡率阀值。abs(κ-1/fopt)表示对κ-1/fopt取绝对值。
第五步,选择算子。
5.1生成空的临时种群poptemp;
5.2将bestpop插入poptemp。此处为精英保留策略,即保留最好的染色体;
5.3从种群popa中随机复制一条染色体到poptemp,这样随机复制执行popnum-1次,获得含popnum条染色体的poptemp。
5.4令popa=poptemp。
第六步,交叉算子。
6.1n=1。
6.2生成[0,1]区间的随机数q,若q>pcross,转6.10步,否则转6.3步。
6.3从popa随机选择两条父代染色体ra和rb,ra和rb的各染色体片段中的进程按进程号从小到大把基因依次组合成第一基因集合a和第二基因集合b。a、b均含有n个基因,编号为1至n。假如ra为{{e1,e2,e3},{e4,e5,e6,e7},{e8,e9,e10}},则集合a为{e1,e2,e3,e4,e5,e6,e7,e8,e9,e10}。假如rb为{{e1,e6,e7,e3},{e4,e2},{e8,e5,e9,e10}},则集合b为{e1,e6,e7,e3,e4,e2,e8,e5,e9,e10}。
6.4随机生成两个整数n1,n2,1≤n1≤n2≤n。复制a中第n1个到第n2个基因,得到第一基因子集合a1,复制b中第n1个到第n2个基因,得到第二基因子集合b1。这样集合a包含三个子集合,大小分别为n1-1,n2-n1+1,n-n2,大小为n2-n1+1的子集合正好是b1。
6.5把a中属于b1中的基因全部删掉(即删除掉a中大小为n2-n1+1的子集合),剩下n1-1+n-n2个基因,把剩下n1-1+n-n2个基因,分割成新集合c、d。c、d分别包含n1-1个和n-n2个基因。
6.6把c、b1和d按顺序拼成新的集合a2,a2包含n个基因。对应ra中染色体片段的长度,把a2分割成第一子代染色体sa。sa中m个染色体片段的长度与ra中m个染色体片段的长度一样。
6.7把b中属于a1中的基因全部删掉,剩下n1-1+n-n2个基因,分割成新集合e、f。e、f分别包含n1-1个和n-n2个基因。
6.8把e、a1和f按顺序拼成新的集合b2,b2包含n个基因。对应rb中染色体片段的长度,把b2分割成第二子代染色体sb。sb中m个染色体片段的长度与rb中m个染色体片段的长度一样。
6.9更新种群popa:令ra=sa,rb=sb。
6.10n=n+1。
6.11若n>popnum转第七步,否则转第6.2步。
第七步,变异算子。
7.1n=1。
7.2生成[0,1]区间的随机数q,若q>pvari,转7.7步,否则转7.3步。
7.3选择popa的第n条染色体r,r中m个染色体片段按照进程号从小到大把基因依次顺序组合成a。a有n个基因。
7.4随机生成两个整数n1,n2,1≤n1≤n2≤n。把集合a中n1和n2位置处的基因进行交换。
7.5根据r中m个染色体片段的长度,把a分割成第三子代染色体r1。r1中第1到第m个染色体片段的长度和r中第1到第m个染色体片段的长度相同。
7.6更新种群中第n条染色体:令r=r1。
7.7n=n+1。
7.8若n>popnum,转第三步;否则转第7.2步。
第八步,输出最优染色体bestpop(即最好的负载平衡模式),结束。
上述方法都各有优缺点:
(1)确定性方法速度快,但是负载平衡效果不确定,有时效果特别好,但大多数效果欠佳。
(2)智能优化算法比较原始,没有考虑相应智能优化算法的鲁棒性差和计算效率低的问题。
(3)混合算法效果较好,但是仍然存在计算效率低和负载平衡优化效果不明显的问题。确定性方法产生的种群很多时候会导致智能优化算法得不到优良的解。
因此研究计算效率高和效果好的智能负载平衡方法非常有意义。
技术实现要素:
本发明要解决的技术问题是针对现有负载平衡方法,提供一种基于minmax局部优化结构化网格负载平衡方法,提高负载平衡率和计算速度。
本发明具体技术方案为:
第一步,参数配置:
1.1从配置文件获得输入文件位置、种群大小popnum、最大迭代次数itemax、平衡率阀值ε、交叉概率pcross、变异概率pvari、最大重复次数samemax。ε可取0.1、0.01或者0.01。popnum可取基因数的10-100倍,itemax可取基因数的5倍。交叉概率pcross、变异概率pvari为0到1之间的实数,一般pcross可取0.8,pvari可取0.1。samemax可取15。
1.2令最优适应度值重复次数nsame=0,令旧最优适应度值
第二步,初始化种群。
2.1从输入文件中读取所有网格块,把所有网格块随机分配到m个进程。一个网格块对应一个基因,网格块中网格数目为基因的值。生成含popnum条染色体的种群popa,popa={r1,..,rn...,rpopnum},popnum为popa中染色体条数,1≤n≤popnum且n为正整数,rn表示第n条染色体。所有染色体均有m个染色体片段,对应m个进程。
2.2令迭代次数变量itenum=0。
第三步,适应度计算。
3.1根据式(1)对popa中的r1,..,rn...,rpopnum分别进行适应度计算,得到popnum个适应度值,表示为f1,...,fn,...fpopnum。
3.2找出f1,...,fn,...fpopnum中的最大值,表示为全局最优染色体的适应度值fopt,并将fopt对应的全局最优染色体记录为bestpop。
3.3itenum=itenum+1。
第四步,minmax局部优化。采用minmax方法对每个染色体中最大和最小的两个染色体片段进行迁移优化,得到适应度更好的染色体。
4.1令n=1。
4.2对种群popa中第n条染色体中的m个染色体片段中的基因进行累加,得到m个染色体片段值。
4.3根据4.2步得到的m个染色体片段值,找出第n条染色体中染色体片段值最大的染色体片段
4.4执行如下操作,对seg_max和seg_min进行基因迁移优化:
4.4.1令i=1。
4.4.2计算网格数目和sum:
4.4.3若sum≤κ,把seg_max中的
4.4.4令i=i+1。
4.4.5若i>h,转第4.5步;否则转4.4.2步。
4.5令n=n+1。
4.6若n>popnum,转第五步;否则,转第4.2步。
第五步,条件判断。
5.1若itenum大于itemax,迭代终止,转第十一步。若itenum小于等于itemax,itenum=itenum+1,执行5.2。
5.2若fopt满足式(2)的条件,表示已找到最优染色体,迭代终止,转第十一步。若全局最优染色体的适应度值fopt不满足式(2)的条件,执行5.3。
5.3若fopt满足式(3)的条件,迭代终止,转第十一步。式(3)表示fopt的倒数等于最大基因,这意味着一个染色体片段(命名为seg)只包含一个基因,即一个进程只处理一个网格数目最大的网格块。其它染色体片段值均小于seg的值。因为本发明针对的是不对网格进行剖分,所以不可能找到比当前与fopt对应的bestpop更加优良的染色体,迭代终止。若fopt不满足式(3)的条件,转第六步。
1/fopt=max{e1,e2,…,en}(3)
第六步,更新判断。
6.1若
6.2若nsame>samemax,令nsame=0,转第七步;否则转第八步。
第七步,种群更新。
7.1从输入文件中读取所有网格块,把所有网格块随机分配到m个进程。生成含popnum条染色体的种群poptemp,poptemp={r1,..,rn...,rpopnum},poptemp中有popnum条染色体。所有染色体均有m个片段,对应m个进程。
7.2用步骤3.2得到的bestpop替换种群poptemp中的第一个染色体r1。
7.3令popa=poptemp。
第八步,选择算子。
8.1生成空的临时种群poptemp;
8.2将bestpop插入poptemp。此处为精英保留策略,即保留最好的染色体;
8.3从种群popa中随机复制一条染色体到poptemp,这样随机复制执行popnum-1次,获得含popnum条染色体的poptemp。
8.4令popa=poptemp。
第九步,交叉算子。
9.1令n=1。
9.2生成[0,1]区间的随机数q,若q>pcross,转9.10步,否则执行9.3步。
9.3从popa随机选择两条父代染色体ra和rb,ra和rb的各染色体片段中的进程按进程号从小到大把基因依次组合成第一基因集合a和第二基因集合b。a、b均含有n个基因,编号为1至n。假如ra为{{e1,e2,e3},{e4,e5,e6,e7},{e8,e9,e10}},则集合a为{e1,e2,e3,e4,e5,e6,e7,e8,e9,e10}。假如rb为{{e1,e6,e7,e3},{e4,e2},{e8,e5,e9,e10}},则集合b为{e1,e6,e7,e3,e4,e2,e8,e5,e9,e10}。
9.4随机生成两个整数n1,n2,1≤n1≤n2≤n。复制a中第n1个到第n2个基因,得到第一基因子集合a1,复制b中第n1个到第n2个基因,得到第二基因子集合b1。这样集合a包含三个子集合,大小分别为n1-1,n2-n1+1,n-n2,大小为n2-n1+1的子集合正好是b1。
9.5把a中属于b1中的基因全部删掉(即删除掉a中大小为n2-n1+1的子集合),剩下n1-1+n-n2个基因,把剩下n1-1+n-n2个基因,分割成新集合c、d。c、d分别包含n1-1个和n-n2个基因。
9.6把c、b1和d按顺序拼成新的集合a2,a2包含n个基因。对应ra中染色体片段的长度,把a2分割成第一子代染色体sa。sa中m个染色体片段的长度与ra中m个染色体片段的长度一样。
9.7把b中属于a1中的基因全部删掉,剩下n1-1+n-n2个基因,分割成新集合e、f。e、f分别包含n1-1个和n-n2个基因。
9.8把e、a1和f按顺序拼成新的集合b2,b2包含n个基因。对应rb中染色体片段的长度,把b2分割成第二子代染色体sb。sb中m个染色体片段的长度与rb中m个染色体片段的长度一样。
9.9更新种群popa:令ra=sa,rb=sb。
9.10令n=n+1。
9.11若n>popnum,转第十步,否则转第9.2步。
第十步,变异算子。变异算子采用二级择优变异方式:
10.1第一级变异。
10.1.1令n=1。
10.1.2生成[0,1]区间的随机数q,若q>pvari,转10.1.7步,否则转10.1.3步。
10.1.3选择popa的第n条染色体rn,rn各染色体片段中按进程号从小到大把基因依次组合成基因集合a。a有n个基因。假设rn={{e1,e6,e7,e3},{e4,e2},{e8,e5,e9,e10}},则a={e1,e6,e7,e3,e4,e2,e8,e5,e9,e10}。
10.1.4随机生成两个整数n1,n2,1≤n1≤n2≤n。把集合a中n1和n2位置处的基因进行交换。假设n1=2,n2=5,则基因交换后的集合a={e1,e4,e7,e3,e6,e2,e8,e5,e9,e10}。
10.1.5对应rn中染色体片段的长度,把集合a分割成第三子代染色体r1。r1中m个染色体片段的长度与rn中m个染色体片段的长度一样。rn染色体片段的长度分别为4、2、4。集合a分割成子代染色体r1为r1={{e1,e4,e7,e3},{e6,e2},e8,e5,e9,e10},rn染色体片段的长度也分别为4、2、4。
10.1.6计算r1的适应度f1,计算rn的适应度f。若f1>f,则更新种群popa中第n条染色体:即令rn=r1。
10.1.7令n=n+1。
10.1.8若n>popnum,转第10.2步;否则转第10.1.2步。
10.2第二级变异。
10.2.1令n=1。
10.2.2生成[0,1]区间的随机数q,若q>pvari,转10.2.7步,否则转10.2.3步。
10.2.3选择popa的第n条染色体rn,复制染色体r1=rn。随机选择r1中两个染色体片段seg1,seg2。设seg1,seg2中基因的个数分别为k1,k2。seg1,seg2中的基因组成新的集合b,则b中基因个数为k1+k2。
10.2.4随机产生分割点k0,k0为1至k1+k2中的一个正整数。从位置k0处,把集合b分割成两个新的染色体片段seq1a,seg2a。seg1a包含b中第1个到第k0个基因,seg2a包含b中第k0+1个到第k1+k2个基因。
10.2.5更新r1:令seg1=seq1a,seg2=seg2a。
10.2.6计算r1的适应度f1,计算rn的适应度f。若f1>f,则更新种群popa中第n条染色体:令rn=r1。
10.2.7令n=n+1。
10.2.8若n>popnum,转第三步;否则转第10.2.2步。
第十一步,输出第3.2步得到的最优染色体bestpop,得到最好的负载平衡模式。
与现有技术相比,采用本发明计算速度快、适应度值高,能够快速得到较好的负载平衡率。
1.由于本发明第四步对每个染色体中最大和最小的两个染色体片段进行了迁移优化,使得染色体适应度更好,因此使得收敛速率和负载平衡率得以提高。
2.由于本发明第七步进行了种群更新,使得种群不容易早熟导致程序过早终止,而能得到全局较优解,使得整个结构化网格并行计算负载平衡率得以提升。
附图说明
图1为背景技术1总体流程图;
图2是本发明的总体流程图。
具体实施方式
图2是本发明的总体流程图。如图2所示,本发明包括以下步骤:
第一步,参数配置:
1.1从配置文件获得输入文件位置、种群大小popnum、最大迭代次数itemax、平衡率阀值ε、交叉概率pcross、变异概率pvari、最大重复次数samemax。
1.2令最优适应度值重复次数nsame=0,令旧最优适应度值
第二步,初始化种群。
2.1从输入文件中读取所有网格块,把所有网格块随机分配到m个进程。一个网格块对应一个基因,网格块中网格数目为基因的值。生成含popnum条染色体的种群popa,popa={r1,..,rn...,rpopnum},popnum为popa中染色体条数,1≤n≤popnum且n为正整数,rn表示第n条染色体。所有染色体均有m个染色体片段,对应m个进程。
2.2令迭代次数变量itenum=0。
第三步,适应度计算。
3.1根据式(1)对popa中的r1,..,rn...,rpopnum分别进行适应度计算,得到popnum个适应度值,表示为f1,...,fn,...fpopnum。
3.2找出f1,...,fn,...fpopnum中的最大值,表示为全局最优染色体的适应度值fopt,并将fopt对应的全局最优染色体记录为bestpop。
3.3itenum=itenum+1。
第四步,采用minmax方法对每个染色体中最大和最小的两个染色体片段进行迁移优化,得到适应度更好的染色体。
4.1令n=1。
4.2对种群popa中第n条染色体中的m个染色体片段中的基因进行累加,得到m个染色体片段值。
4.3根据4.2步得到的m个染色体片段值,找出第n条染色体中染色体片段值最大的染色体片段
4.4执行如下操作,对seg_max和seg_min进行基因迁移优化:
4.4.1令i=1。
4.4.2计算网格数目和sum:
4.4.3若sum≤κ,把seg_max中的
4.4.4令i=i+1。
4.4.5若i>h,转第4.5步;否则转4.4.2步。
4.5令n=n+1。
4.6若n>popnum,转第五步;否则,转第4.2步。
第五步,条件判断。
5.1若itenum大于itemax,迭代终止,转第十一步。若itenum小于等于itemax,itenum=itenum+1,执行5.2。
5.2若fopt满足式(2)的条件,表示已找到最优染色体,迭代终止,转第十一步。若全局最优染色体的适应度值fopt不满足式(2)的条件,执行5.3。
5.3若fopt满足式(3)的条件,迭代终止,转第十一步。若fopt不满足式(3)的条件,转第六步。
1/fopt=max{e1,e2,…,en}(3)
第六步,更新判断。
6.1若
6.2若nsame>samemax,令nsame=0,转第七步;否则转第八步。
第七步,种群更新。
7.1从输入文件中读取所有网格块,把所有网格块随机分配到m个进程。生成含popnum条染色体的种群poptemp,poptemp={r1,..,rn...,rpopnum},poptemp中有popnum条染色体。所有染色体均有m个片段,对应m个进程。
7.2用步骤3.2得到的bestpop替换种群poptemp中的第一个染色体r1。
7.3令popa=poptemp。
第八步,选择算子。
8.1生成空的临时种群poptemp;
8.2将bestpop插入poptemp。
8.3从种群popa中随机复制一条染色体到poptemp,这样随机复制执行popnum-1次,获得含popnum条染色体的poptemp。
8.4令popa=poptemp。
第九步,交叉算子。
9.1令n=1。
9.2生成[0,1]区间的随机数q,若q>pcross,转9.10步,否则执行9.3步。
9.3从popa随机选择两条父代染色体ra和rb,ra和rb的各染色体片段中的进程按进程号从小到大把基因依次组合成第一基因集合a和第二基因集合b。a、b均含有n个基因,编号为1至n。
9.4随机生成两个整数n1,n2,1≤n1≤n2≤n。复制a中第n1个到第n2个基因,得到第一基因子集合a1,复制b中第n1个到第n2个基因,得到第二基因子集合b1。这样集合a包含三个子集合,大小分别为n1-1,n2-n1+1,n-n2,大小为n2-n1+1的子集合正好是b1。
9.5把a中属于b1中的基因全部删掉,剩下n1-1+n-n2个基因,把剩下n1-1+n-n2个基因,分割成新集合c、d。c、d分别包含n1-1个和n-n2个基因。
9.6把c、b1和d按顺序拼成新的集合a2,a2包含n个基因。对应ra中染色体片段的长度,把a2分割成第一子代染色体sa。sa中m个染色体片段的长度与ra中m个染色体片段的长度一样。
9.7把b中属于a1中的基因全部删掉,剩下n1-1+n-n2个基因,分割成新集合e、f。e、f分别包含n1-1个和n-n2个基因。
9.8把e、a1和f按顺序拼成新的集合b2,b2包含n个基因。对应rb中染色体片段的长度,把b2分割成第二子代染色体sb。sb中m个染色体片段的长度与rb中m个染色体片段的长度一样。
9.9更新种群popa:令ra=sa,rb=sb。
9.10令n=n+1。
9.11若n>popnum,转第十步,否则转第9.2步。
第十步,变异算子。变异算子采用二级择优变异方式:
10.1第一级变异。
10.1.1令n=1。
10.1.2生成[0,1]区间的随机数q,若q>pvari,转10.1.7步,否则转10.1.3步。
10.1.3选择popa的第n条染色体rn,rn各染色体片段中按进程号从小到大把基因依次组合成基因集合a。a有n个基因。
10.1.4随机生成两个整数n1,n2,1≤n1≤n2≤n。把集合a中n1和n2位置处的基因进行交换。
10.1.5对应rn中染色体片段的长度,把集合a分割成第三子代染色体r1。r1中m个染色体片段的长度与rn中m个染色体片段的长度一样。rn染色体片段的长度分别为4、2、4。集合a分割成子代染色体r1为r1={{e1,e4,e7,e3},{e6,e2},e8,e5,e9,e10},rn染色体片段的长度也分别为4、2、4。
10.1.6计算r1的适应度f1,计算rn的适应度f。若f1>f,则更新种群popa中第n条染色体:即令rn=r1。
10.1.7令n=n+1。
10.1.8若n>popnum,转第10.2步;否则转第10.1.2步。
10.2第二级变异。
10.2.1令n=1。
10.2.2生成[0,1]区间的随机数q,若q>pvari,转10.2.7步,否则转10.2.3步。
10.2.3选择popa的第n条染色体rn,复制染色体r1=rn。随机选择r1中两个染色体片段seg1,seg2。设seg1,seg2中基因的个数分别为k1,k2。seg1,seg2中的基因组成新的集合b,则b中基因个数为k1+k2。
10.2.4随机产生分割点k0,k0为1至k1+k2中的一个正整数。从位置k0处,把集合b分割成两个新的染色体片段seq1a,seg2a。seg1a包含b中第1个到第k0个基因,seg2a包含b中第k0+1个到第k1+k2个基因。
10.2.5更新r1:令seg1=seq1a,seg2=seg2a。
10.2.6计算r1的适应度f1,计算rn的适应度f。若f1>f,则更新种群popa中第n条染色体:令rn=r1。
10.2.7令n=n+1。
10.2.8若n>popnum,转第三步;否则转第10.2.2步。
第十一步,输出第3.2步得到的最优染色体bestpop,得到最好的负载平衡模式。
- 还没有人留言评论。精彩留言会获得点赞!