一种学生信息素养测评试卷的自动生成方法及系统与流程
本发明涉及教育信息化评价技术领域,具体涉及一种学生信息素养测 评试卷的生成算法。
背景技术:
设计、开发一套可用于测量我国学生信息素养水平的评估工具,对学 生的信息素养水平进行科学、可靠的评估十分必要。目前,学生信息素养 评估多采用自陈式的李克特量表进行评估,缺少对学生信息素养进行客观 测评的试卷。
技术实现要素:
针对现有技术的迫切技术需求,本发明提供了一种学生信息素养测评 试卷的自动生成方法及系统,可自动生成信息素养测评试卷,并不断优化 题目,使得试卷与测试指标相匹配,试卷难度与学生能力相匹配,为实施 学生信息素养测评提供科学、有效的工具。
为实现本发明的技术目的,本发明提供了如下技术方案:
一种学生信息素养测评试卷生成方法,包括以下步骤:
(1)构建学生信息素养测试指标与测试题目的关联数据库;
(2)从关联数据库中随机抽取试题生成测试试卷;
(3)使用测试试卷初次测试,根据初次测试结果初步优化试卷:计算 题目间的相关矩阵,求取相关矩阵特征值及对应的单位特征向量,依据特 征值及对应的单位特征向量计算因子载荷;将测试题目得分采用因子载荷 展开表示并观察展开式,若相同指标的题目都可以用相同的因子解释,并 且不同指标的题目因子不同,则表明因子与指标相符,无需对试题修改; 若因子数与指标有冲突,多个指标的题目能被同一组因子解释,则增大这 几组指标间题目的差异;
(4)对初步优化后的试卷进行再次测试,根据测试结果再次优化试卷: 计算试卷的信效度,若试卷信度小于第二预定阈值,则修改题目使题目考 察内容更加一致;计算试卷题目效度,若试卷效度小于第三预定阈值,则 提高题目难度以提高区分度;计算试卷难度值和考生能力值,比较两者之 间的差异,若差异值在设定范围内,表明试卷难度与考生能力相当,无需 修改题目;否则修改试题难度以使得试卷难度与考生能力匹配。
进一步的,所述根据初次测试结果初步优化试卷的具体实现过程为:
(31)计算题目间的相关矩阵R:其中,ρij为题目i、j之间的相关系数:
n为题目数;Xi为题目i的得分向量,cov(Xi,Xj)为Xi,
Xj之间的得分协方差,DXi为Xi的方差,E为其期望;
(32)依据题目i、j之间的相关系数ρij计算KMO值,若KMO值低于第 一预定阈值,则增加试题;其中,
ρij为题目i、j之间的相关系数,sij为题目i、j之间的偏相关系数;
设i=t,j=t-k,则有:
为排除其他变量影响后Xt的期望;
(33)求相关矩阵R的n个特征值λ1≥λ2≥λ3≥…λn≥0及对应的单 位特征向量μ1,μ2,μ3,…μn;计算因子载荷azc,得到因子载荷阵A:
因子z=1..n,c=1..n;uzc为第z个特征向量的第c个元素;
(34)各题分数可表示为X=AF+ε,X为题目向量,F=[f1,f2,...,fn]T为因 子向量,ε=[ε1,ε2,...,εn]T为误差项,展开后可表示为:
观察展开式,若相同指标的题目均用相同的因子解释,并且不同指 标的题目因子不同,则表明因子与指标相符,无需对试题修改;若因子数 与指标有冲突即多个指标的题目能被同一组因子解释,修改题目增大这几 组指标间题目的差异。
进一步的,所述计算试卷信度的具体实现过程为:
B表示试卷的信度,n表示题目总数,Si表示第i题得分标准差,s2表 示试卷得分方差。
进一步的,所述计算试卷题目效度的具体过程为:
R表示试卷的效度,Di表示第i题的区分度,n表示试题总数。
进一步的,所述计算试卷难度值和考生能力值的具体实现过程为:
试卷难度值=Y*k题目i;
考生能力值=X*k考生;
其中,试卷难度扩展因子
考生能力扩展因子
M为考生人数,n为题目数,
Logiti=题目正确率/(1-题目正确率),
Logit考生q=考生答题正确率/(1-考生答题正确率),
考生均值校正值
题目均值校正值
题目初始校准值k题目i=Logit题目i-t题目,
考生初始校准值k考生q=Logit考生q-t考生。
进一步的,在测试试卷初步优化的步骤(31)前进行测谎分析优化, 具体为:判定试卷中同一道题在先后出现时的答题结果是否一致,若一致, 则试卷有效,否则,试卷无效,摒弃无效试卷。
进一步的,在测试试卷初步优化的步骤(31)前进行项目分析优化, 具体为:统计题目的测试结果,根据总分高低将试卷分为高分组和低分组, 采用t检验方法分析高分组、低分组在各题上的差异,删除差异不显著的 题目。
一种学生信息素养测评试卷生成系统,包括:
关联数据构建模块,用于构建学生信息素养测试指标与测试题目的关 联数据库;
测试试卷随机生成模块,用于从关联数据库中随机抽取试题生成测试 试卷;
试卷初步优化模块,用于使用测试试卷初次测试,根据初次测试结果 初步优化试卷:计算题目间的相关矩阵,求取相关矩阵特征值及对应的单 位特征向量,依据特征值及对应的单位特征向量计算因子载荷,进而将测 试题目得分采用因子载荷展开表示;观察展开式,若相同指标的题目都可 以用相同的因子解释,并且不同指标的题目因子不同,则表明因子与指标 相符,无需对试题修改;若因子数与指标有冲突,多个指标的题目能被同 一组因子解释,则增大这几组指标间题目的差异;
试卷再次优化模块,用于对初步优化后的试卷进行再次测试,根据测 试结果再次优化试卷:计算试卷的信效度,若试卷信度小于第二预定阈值, 则修改题目使题目考察内容更加一致;计算试卷题目效度,若试卷效度小 于第三预定阈值,则提高题目难度以提高区分度;计算试卷难度值和考生 能力值,比较两者之间的差异,若差异值在设定范围内,表明试卷难度与 考生能力相当,无需修改题目;否则修改试题难度以使得试卷难度与考生 能力匹配。
进一步的,所述试卷初步优化模块的具体实现过程为:
(31)计算题目间的相关矩阵R:其中,题目i、j之间的相关系数ρij:
n为题目数;
Xi为题目i的得分向量,cov(Xi,Xj)为Xi,Xj之间的得分协方差,DXi为 Xi的方差,E为其期望;
(32)依据题目i、j之间的相关系数ρij计算KMO值,若KMO值低于第 一预定阈值,则增加试题;其中,
ρij为题目i、j之间的相关系数,sij为题目i、j之间的偏相关系数;
设i=t,j=t-k,则有:
为排除其他变量影响后Xt的期望;
(33)求相关矩阵R的n个特征值λ1≥λ2≥λ3≥…λn≥0及对应的单 位特征向量μ1,μ2,μ3,…μn;计算因子载荷azc,得到因子载荷阵A:
因子z=1..n,c=1..n;uzc为第z个特征向量的第c个元素;
(34)各题分数可表示为X=AF+ε,X为题目向量,F=[f1,f2,...,fn]T为因 子向量,ε=[ε1,ε2,...,εn]T为误差项,展开后可表示为:
观察展开式,若相同指标的题目均用相同的因子解释,并且不同指标的题 目因子不同,则表明因子与指标相符,无需对试题修改;若因子数与指标 有冲突即多个指标的题目能被同一组因子解释,修改题目增大这几组指标 间题目的差异。
进一步的,所述试卷再次优化模块的具体实现过程为:
计算试卷信度:
B表示试卷的信度,n表示题目总数,Si表示第i题得分标准差,s2表 示试卷得分方差;
计算试卷题目效度:
R表示试卷的效度,Di表示第i题的区分度,n表示试题总数;
计算试卷难度值和考生能力值:
试卷难度值=Y*k题目i;
考生能力值=X*k考生q;
其中,试卷难度扩展因子
考生能力扩展因子值
M为考生人数,n为题目数,
Logiti=题目正确率/(1-题目正确率), Logit考生q=考生答题正确率/(1-考生答题正确率),
考生均值校正值
题目均值校正值
题目初始校准值k题目i=Logit题目i-t题目,
考生初始校准值k考生q=Logit考生q-t考生。
总体而言,通过结合专家咨询法、项目分析、信效度检验、Rasch模型 分析,提出了一种学生信息素养试卷的生成方法即系统,结合主观与客观 分析方法,使生成的试卷更加准确、科学。
附图说明
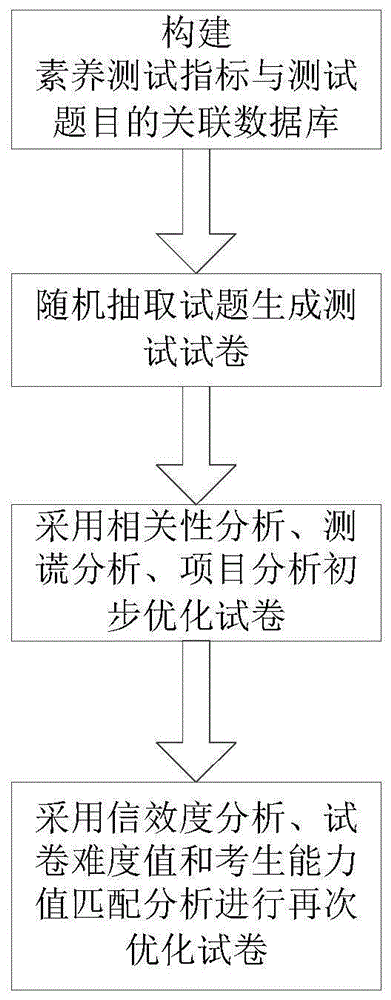
图1为本发明方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图 及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体 实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的 本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可 以相互组合。
图1为本发明方法流程图,一种学生信息素养测评试卷生成方法,包 括以下步骤:
(1)构建学生信息素养测试指标与测试题目的关联数据库。
确定评价指标体系,为每一评价指标编制足够的试题,并标注试题与 指标的关联度。
确定指标体系前可以参考国内外已有的指标体系,如澳大利亚高等教 育信息素养标准框架,北京地区高等教育信息素养能力指标体系等。根据 测量目标,指标体系可以兼顾各方面,也可以有所侧重只测量部分素质。 先通过咨询专家确定指标体系的合理性,在得到试测数据后,根据因子分 析的结果修正指标。作为一个示例,学生信息素养测试指标为三级指标, 包括一级指标、二级指标与指标释义,具体为:
根据指标释义,结合学生信息课程大纲,参考相关测试问卷,编制试 题,使每道试题都与一个二级指标或指标释义相对应,并确保每个指标都 有足够的试题与之对应。
试题与指标的关联度可采用专家打分方式确定。将学生信息素养测试 题专家咨询表发给相关专家,专家依据咨询表给各题评分。质量评价包括 得分与意见,譬如得分包括五个等级,“5”表示很好,“4”表示较好,“3” 中等,“2”表示较差,“1”表示很差。计算出专家打分的均值,即为试题 与指标的关联度分值。
(2)从关联数据库中随机抽取试题生成测试试卷;
从关联数据库中随机抽取试题生成测试试卷,选题应覆盖所有指标并 保证每个指标有足够的试题对应。试卷应包括1至2道的测谎题。测谎题 是指在试卷中出现多次的同一道题,通过对该题前后作答的一致性来判断 试卷是否无效。如果一致,则有效,反之无效。对测谎题,可以对其表现 形式进行微调,比如调整答案顺序。
(3)使用测试试卷初次测试,根据初次测试结果初步优化试卷:
(31)对测试结果进行测谎分析优化。
测谎分析即分析测试中随意作答的无效试卷并剔除。测谎分析主要 通过前后作答的一致性来判断试卷是否无效。若同一道题与之后其稍作变 换之后的变体答案不一致可认为试卷无效。无效试卷应从结果中排除。
(32)对有效测试结果进行项目分析优化
若试题选项缺失、异常(不在选项范围内)则该题分析时记为错误。 求出所有正确的题目数目记为量表总分。根据量表总分排序并分组,将总 分在前的试卷分为高分组,总分在后的分为低分组,高分低分的界定值可 试验整定。
用t检验分析高分组、低分组在各题上的差异。当p值小于某一预 定阈值时,即可认为差异并不显著即区分度不高,删除差异不显著的题目。
若删除后指标对应试题数量不足,则返回步骤(21)扩充试题。
(33)对有效测试结果进行因子分析优化。
计算题目间的相关矩阵R。
n
为题目数;Xi为题目i的得分向量,cov(Xi,Xj)为Xi,Xj之间的得分协方差,DXi为Xi的方差,E为其期望;
求相关矩阵R的p个特征值λ1≥λ2≥λ3≥…λp≥0及对应的单位特征 向量μ1,μ2,μ3,…μp。计算因子载荷aij,得到因子载荷阵A。
计算KMO(Kaiser-Meyer-Oklin Measure of Smapling Adequacy)值。
rij为题目i、j之间的相关系数,sij为题目i、j之间的偏相关系数。
设i=t,j=t-k则有:
为排除其他变量影响后Xt的期望。
KMO值达到0.9以上为非常好,0.8-0.9为好,0.7-0.8为一般,0.6-0.7 为差,0.5-0.6为很差。如果KMO测度的值低于0.5时,表明题目偏少,需 要增加题目。
从A中选出特征根λ>1的因子,观察因子在各题目上的分布。若因子 分布不整齐可对其进行因子旋转,使因子在各维度上分布均匀。根据旋转 后的矩阵解释题目与指标符合度。若相同指标的题目都可以用相同的主要 因子解释,并且不同指标的题目主要因子不同则可以断言因子与指标相符。 主要观察因子解释与一级指标是否相符。否则因子与指标有冲突。相同指 标的题目不能被相同的主要因子解释,则这些题考察的范围不够一致;若 不同指标的题目能被相同的因子解释,则不同指标题目的区别不够明显。 若因子数与指标有冲突,回到步骤1修改题目。
(4)对初步优化后的试卷进行测试,根据测试结果再次优化试卷。
(41)对试卷进行信效度检测,根据信效度检测结果优化试卷。
根据以下公式计算试卷信度:
B表示试卷的信度,n表示试题总数,Si表示第i题标准差,s2表示试 卷方差。
式中,m表示考生人数,Xij表示第j个学生第i题的成绩,表示全 部考生第i题的平均分。
式中,m表示考生人数,Xj表示第j个学生试卷的总分,表示全部考 生试卷的平均分。
当B<0.5时,试卷信度为“较差”;当0.5<B<0.8时,试卷信 度为“良好”;当B>0.8时,试卷信度为“非常好”。若试卷信度较差, 可适当增加题目数目,增加题目间的同质性,使题目难度与考生能力相当。
根据以下公式计算试卷题目效度。试卷的效度可以通过试卷的平均区 分度来衡量,因此得到:
其中,R表示试卷的效度,Di表示第i题的区分度,n表示试题总数。
以总分前27%为高分组,以总分后27%为低分组,分别计算第i题高分 组学生的平均成绩和低分组学生的平均成绩设第i题的满分为Wi。
R>0.4时,试卷的效度较好,即可以有效地实现考试的目标。若 试卷区分度不足,则应适当提高试卷难度以提高区分度。
(32)对优化后的试卷进行Rasch分析优化
建立二元反应矩阵。行表示题目,列表示学生,答对为1,答错为0。 消除异常值并剔除全对与全错的题目与学生。
根据以下公式计算题目与考生初始校准值:
题目Logit=ln(题目答对率/题目答对率)
考生Logit=ln(考生答对率/考生答对率)
题目均值校正值=全部题目Logit之和/题数
题目初始校准值=Logit-均值校正值
考生均值校正值=全部考生Logit之和/人数
考生初始校准值=Logit-均值校正值
根据以下公式计算计算扩展因子:
题目难度扩展因子值的计算公式是:
考生能力扩展因子值的计算公式是:
V=(全部Logit的平方和-人数*考生均值校正值平方)/(人数-1)
U=(全部Logit的平方和-题数*题目均值校正值平方)/(题数-1)
最后计算试题与考生最终值:
最终值=扩展因子*初始校准值
比较试卷难度均值、难度范围和学生能力均值、能力范围。试题难度 范围需要覆盖考生能力范围并且两者均值因相近。若试卷难度没有覆盖学 生能力则将添加部分难题或简单题使难度范围扩大;若两者均值不等,则 调高或调低部分试题难度,使其与考生能力相近。
实例:
本例以石映辉等人编制的《中小学生信息信息素养评价指标体系》为 指标体系,详细指标见图1。根据三级指标编制试题,确保每个指标都有3 个及以上的题目与之对应。试题应清楚、规范、易于理解。
请专家对题目与指标的相关性进行打分。
淘汰得分不合格的试题,编制新题补充。
如下题,
小明在某航空公司网站上查询武汉到北京的航班信息,该网站是用数 据库来管理这些信息的。下列关于数据库管理优势的说法中,不正确的是 (D)
A.管理操作方便、快捷,数据维护简单、安全
B.检索统计准确
C.数据共享应用,提高数据的使用效率
D.存储数据少
与指标信息的获取与识别无关,可换为:
搜索引擎存在的问题与缺陷有哪些?(D)
A.Web网页数目较少,增长迅速查全率高。
B.过期信息较少,不会有死链接
C.索引更新较快,很快找到最新信息
D.同义词的大量存在,查准率不高
再次进行专家评分。循环以上步骤直至试题评分合格且数量充足。
对试题进行试测时,应确保被试样本充足且具有代表性。试测试卷可 加入一定数目的测谎题,如:
16.对计算机软件正确的认识应该是(D)
A.使用盗版软件合法
B.计算机软件受法律保护是多余的
C.正版软件太贵,软件能复制不必购买
D.受法律保护的计算机软件不能随便复制
和
37.对计算机软件正确的认识应该是(B)
A.正版软件太贵,软件能复制不必购买
B.受法律保护的计算机软件不能随便复制
C.使用盗版软件合法
D.计算机软件受法律保护是多余的
当两题选项不一致时可判定为无效。
对结果进行项目分析。编制如下题目-学生表(以下数据仅为部分示 例,不一定满足之后的计算)。
表1 原始题目-学生表
题目1 题目2 题目3 题目4
学生1 C A D C
学生2 C B B D
学生3 A A D D
根据测谎题筛选问卷,删除没有通过测谎的样本,并删除测谎题。修正 缺失值、错误值、无效值。将题目-学生表中的选项转化为0、1标志(1代 表正确,0代表错误或没有作答),如下:
表2 转换后的学生表
题目1 题目2 题目3 题目4
学生1 1 1 1 0
学生2 1 0 0 1
学生3 0 1 1 1
求出每个学生的总分并排序、分组,以总分前27%为高分组,以总分后 27%为低分组。用t检验验证高低组在各题上的差异,若p<0.05表示两者 差异不显著,即该题区分度不佳,则删掉该题重新编制。
计算题目间的相关矩阵R并估计因素负荷量。
表3 相关性矩阵
题目1 题目2 题目3 题目4
相关性题目1 10 0.146 0.146
题目2 01 -0.064 0.127
题目3 0.146 -0.0641 0.09
题目4 0.146 0.127 0.091
求R的特征值λ1≥λ2≥λ3≥…λp≥0及对应的单位特征向量μ1, μ2,μ3,…μp。计算因子载荷aij,得到因子载荷阵A。
计算KMO值。rij为题目i、j之间的相关系数,sij为题目i、j之 间的偏相关系数。KMO值达到0.9以上为非常好,0.8-0.9为好,0.7-0.8 为一般,0.6-0.7为差,0.5-0.6为很差。如果KMO测度的值低于0.5时, 表明题目偏少,需要增加题目。
表4 提取成分特征值、方差百分比及累计百分比
成分初始特征值
总计方差百分比累积%
1 1.12 28.004 28.004
2 1.043 26.065 54.069
3 0.941 23.531 77.6
4 0.896 22.4 100
根据特征根λ大小确定公因子F个数,选出公因子(选λ>1的为公因 子)。
表5 成分矩阵
题目成分
12
题目1 0.546 -0.479
题目2 0.665 0.294
题目3 -0.047 0.835
题目4 -0.615 -0.172
因子转轴。
表6 旋转后的成分矩阵
题目成分
12
题目1 0.346 -0.639
题目2 0.725 0.044
题目3 0.246 0.799
题目4 -0.636 0.052
所选题目来自两个指标,提取两个因子与其指标数量相符说明题目良 好。若因子数量与指标数量有冲突,修改指标。若题目有问题,则修改题 目。
对试题进行实测,实测要保证样本充足。
对试题进行信效度检测。
根据信度公式计算信度,公式如下:
B表示试卷的信度,n表示试题总数,Si表示第i题标准差,s2表示 试卷方差。
式中,m表示考生人数,Xij表示第j个学生第i题的成绩,(X_i)-表 示全部考生第i题的平均分。
式中,m表示考生人数,X_j表示第j个学生试卷的总分,(X_)-表 示全部考生试卷的平均分。
当B>0.5时,试题信度为“较差”;当0.5<B<0.8时,试题信度 为“良好”;当B>0.8时,试题信度为“非常好”。
试卷的效度可以通过试卷的平均区分度来衡量,因此得到:
其中,R表示试卷的效度,Di表示第i题的区分度,n表示试题总数。
以总分前27%为高分组,以总分后27%为低分组,分别计算第i题高分 组学生的平均成绩和低分组学生的平均成绩设第i题的满分为Wi。
表7 题目区分度
题目区分度
1 0.33
2 0.18
3 0.29
4 0.27
R=(0.33+0.18+0.29+0.27)/4=0.25
R>0.4时,试卷的效度较好,即可以有效地实现考试的目标。示例题目 区分度并较差,需要进一步改进。
用Rasch模型对试题进行分析,在进行Rasch模型分析之前需要将全 对和全错的题目与考生都删去。
根据以下公式计算题目难度初始校准值。
Logit=ln(答对率/答对率)
题目均值校正值=全部题目Logit之和/题数
题目初始校准值=Logit-均值校正值
考生均值校正值=全部考生Logit之和/人数
考生初始校准值=Logit-均值校正值
表8 题目难度矫正计算表
题目答对人数正确率Logit均值矫正难度初始矫正值
1 20.25 -1.09861 -0.13733 -0.961285753
2 40.50 -0.13733 0.137326536
3 50.625 0.510826 -0.13733 0.64815216
4 30.375 -0.51083 -0.13733 -0.373499088
表9 考生能力矫正计算表
考生答对题目正确率Logit均值矫正能力初值矫正值
1 50.625 0.510826 -0.38057 0.891390928
2 30.375 -0.51083 -0.38057 -0.130260319
3 60.75 1.098612 -0.38057 1.479177593
4 70.875 1.94591 -0.38057 2.326475454
根据以下公式计算扩展因子。
题目难度扩展因子值的计算公式是:Y=√((1+V/2.89)/(1-U*V/8.35)) 考生能力扩展因子值的计算公式是:X=√ ((1+U/2.89)/(1-U*V/8.35))
V=(全部Logit的平方和-人数*考生均值校正值平方)/(人数-1)
U=(全部Logit的平方和-题数*题目均值校正值平方)/(题数-1)
U=0.225,V=0.081,X=1.015,Y=1.039。
根据以下公式计算最终值。
最终值=扩展因子*初始校准值
表10 题目最总难度计算表
题目难度初始矫正值最终值
1 -0.96 -0.97
2 0.13 0.13
3 0.64 0.65
4 -0.37 -0.37
表11 考生最终能力计算表
考生能力初值矫正值最终值
1 0.89 0.92
2 -0.13 -0.13
3 1.47 1.5
4 2.32 2.4
比较试卷难度均值、难度范围和学生能力均值、能力范围。试题难度 需要覆盖学生能力并且两者均值在同一水平线上。若不满足上述条件,因 对试卷做出修改,重新测试。
当所有过程都合格,试卷完成。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已, 并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等 同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!