一种混源软件自主可控性检测方法及系统与流程
本发明属于软件测试领域,具体涉及到一种混源软件自主可控性检测方法及系统。
背景技术:
随着开源软件越来越多,软件开发正在从“编写部分代码+调用系统库”向“编写少量代码+开源代码”的方式过渡,即混源软件。目前,混源软件已成为软件开发的一种新模式,借助于正规的开源软件,开发人员只需在此基础上经过少量改动,就可以完成软件开发工作,从而节省大量时间和经费,软件质量也得到了提高。
但是,很多开发人员使用了非正规的开源软件,或虽然使用了正规的开源软件,但他们并没有完全理解并掌握这些代码,只满足于能够实现特定的功能,而并不关心其中存在的大量冗余代码,所开发的软件虽然自称其具有自主可控性,但其中存在巨大的潜在风险,而软件使用人员完全无法发现其中隐藏的风险,从而埋下了风险隐患。如果开发人员能够完全理解并掌握所使用的开源软件,就可以发现其中潜在的风险,从而采取有效的措施加以防范,降低所开发的混源软件的潜在风险。
要使开发人员对所使用的开源软件完全理解、掌握并正确运用,可以通过对其所开发的混源软件进行检测来实现。现有技术中,在软件安全性检测方面已有很多研究成果,但在如何检验软件是否是自主开发的、开发人员是否真正理解并掌握了其提交的代码方面尚无切实可行的方法。
技术实现要素:
本发明针对现有技术中尚无针对混源软件自主可控性进行有效检测的问题,提出了一种混源软件自主开发检测方法及系统,从代码静态分析和动态执行两个方面入手,通过检查混源软件的代码与软件设计说明文档是否一致、代码中是否存在没有执行过的代码,从而验证代码是否是完全自主开发的,有效防范非自主软件带来的潜在风险。
根据本发明的一个方面,提供了一种混源软件自主可控性(开发)检测方法,所述方法包括:
对所述混源软件的代码进行静态分析,生成软件设计说明文档,并与提交的软件说明文档进行对比,通过代码与软件设计说明文档的一致性判断混源软件是否自主开发;当代码与软件设计说明文档不一致且开发人员无法合理解释时,判定为非自主开发;当代码与软件设计说明文档具备一致性或不具备一致性但是开发人员可以合理解释时,执行动态跟踪,通过测试用例对软件代码的覆盖程度来判断混源软件是否自主开发;当混源软件的代码不能被测试用例覆盖且开发人员不能合理解释时,判定为非自主开发;当混源软件的代码能够被测试用例覆盖或虽然不能被测试用例覆盖但是开发人员可以合理解释时,判定为自主开发。
上述方案中,所述方法包括如下步骤:
步骤s1,源代码导入;
步骤s2,源代码分析;
步骤s3,根据源代码分析生成软件设计说明文档;
步骤s4,将生成的软件设计说明文档与原始提交的软件设计说明文档进行对比,判断与原始提交的软甲设计说明文档是否一致;如果一致,则转入步骤s6;如果不一致,则转入步骤s5;
步骤s5,对于生成的软件设计说明文档与提交的软件设计说明文档不一致的方面,如果开发人员不能给出合理解释,则转入步骤s13;如果开发人员能给出合理解释,则转入步骤s6;
步骤s6,代码插装;
步骤s7,编译被测程序;
步骤s8,执行测试用例;
步骤s9,用例数据导入;
步骤s10,代码覆盖分析:判断是否存在未覆盖的语句、分支和数据流,如果不存在,则转入步骤s12;如果存在,则转入步骤s11;
步骤s11,对于未覆盖的语句、分支和数据流,如果开发人员可以给出合理解释,则转入步骤s12;如果开发人员不能给出合理解释,则转入步骤s13;
步骤s12,判断所述代码为自主开发代码;
步骤s13,判断所述代码为非自主开发代码。
上述方案中,所述步骤s2的源代码分析进一步包括:
步骤s21,预处理:读取源代码并对代码预先进行翻译,对源程序中的预处理命令进行识别,调整源代码文件的分析顺序,识别源代码文件编译指令;
步骤s22,词法分析:在预处理基础上对源代码文件进行解析,收集程序符号信息,包括函数信息、变量信息、作用域信息,同时生成程序的抽象语法树;
步骤s23,语法分析:通过迭代遍历语法树,查找函数、变量定义、typedef节点,为节点生成源代码结构静态模型中的实体;
步骤s24,模型生成:使用控制流分析和数据依赖分析中的数据,填充完整的源代码静态结构模型实例和依赖关系模型实例,形成被测软件静态结构模型。
上述方案中,所述静态结构模型包括:工程版本模块、源代码文件模块、函数定义模块、变量定义模块、typedef定义模块、函数声明模块、块对象模块、函数调用表达式模块、赋值表达式模块及基类模块其中,
所述工程版本模块与源代码文件模块、函数定义模块、变量定义模块、typedef定义模块关联,并构成引用关系,具体为源代码文件模块、函数定义模块、变量定义模块、typedef定义模块引用工程版本模块;函数声明模块和块对象模块引用函数定义模块,变量定义模块和typedef定义模块,同时引用块对象模块;函数调用表达式模块、赋值表达式模块引用块对象模块;
基类模块是模型类的共同基类,表示一个语法元素,提供公共方法用于获取语法元素所对应的源代码段、符号流、抽象语法树信息。
上述方案中,所述依赖关系模型包括三个模块:语法元素依赖图、语法元素节点及节点间的有向边;其中,
所述语法元素节点包括函数、变量定义,语法元素对应有向图中的节点;
所述节点间的有向边对应于引用、调用关系;
所述语法元素依赖图提供数个通用方法用于遍历有向图,通过在所述依赖图上上溯和下溯从而进行查询。
上述方案中,所述遍历语法树,进一步包括:
控制流分析,查找函数调用节点生成函数调用列表,在迭代完成且全部列表生成后,利用列表中的调用-被调用对中的函数标识与实体模型中的函数元素实体关联;
数据依赖分析,查找程序中的赋值表达式和带参数传递的函数调用,形成定义-引用对(d-upair)列表。在迭代完成且全部列表生成后,利用变量标识与实体模型中的变量定义实体关联。
上述方案中,所述步骤s10的代码覆盖分析,进一步包括:语句覆盖分析、分支覆盖分析、数据流覆盖分析。
根据本发明的另一个方面,还提供了一种混源软件自主可控性检测系统,所述系统包括:前端、后端及数据访问接口;其中,所述数据访问接口同时与前端和后端相连,用于前端和后端的数据传输;所述前端用于对源代码进行分析形成统一的数据模型,所述后端用于在数据模型的基础上完成自主可控性检测分析。
上述方案中,所述前端包括:源代码分析模块、源代码管理模块、动态执行跟踪模块;其中,
所述源代码管理模块,用于源代码导入;
所述源代码分析模块与源代码管理模块相连,通过加载源代码管理模块导入的源代码,对所导入的源代码进行分析;
所述动态执行跟踪模块,与所述源代码管理模块相连,用于跟踪测试用例的执行轨迹,查找其中未执行到的程序代码。
上述方案中,所述后端包括:工程数据模型模块、一致性分析模块、覆盖分析模块、模型可视化模块;其中,
所述工程数据模型模块,包括工程静态结构子模块和用例集子模块,所述工程静态结构子模块,根据所述源代码分析模块的分析结果生成工程静态结构,包括静态结构模型和依赖关系模型;所述用例集子模块,与前端的动态执行跟踪模块相连,用于根据动态执行结果生成并保存用例集;
所述一致性分析模块与所述工程数据模型模块相连,用于根据所述工程数据模型模块中的模型数据,生成混源软件的设计说明文档,并与开发人员编写的设计说明文档进行一致性比较,找出两者之间的差异,从而得出所述混源软件是否具备自主可控性;
所述覆盖分析模块与所述工程数据模型模块中的用例集子模块相连,用于对用例集覆盖源代码的情况进行计算,找出其中未被覆盖的代码;
模型可视化模块用于展示分析结果,便于用户更加直观、方便地掌握分析结果。例如,通过有向图显示和/或代码着色来进行源代码分析结果的展示。
本发明具有如下有益效果:
本发明的混源软件自主可控性检测方法及系统,从代码静态分析和动态执行两个方面入手,一方面,通过检查软件代码是否与软件设计说明文档一致,找出软件代码中与软件设计不一致的地方;另一方面,通过检查测试用例所覆盖的软件代码,找出软件代码中的多余代码。对于这些不一致的地方和多余代码,如果软件开发人员不能给出合理的解释,则判定开发人员没有完全理解和掌握软件代码,即该软件不是完全自主开发的。该方法和系统操作简单,实用性强,能够快速、准确地检测软件是否是自主开发的,从而找出那些披着自主可控外衣的软件,有效防范非自主软件带来的潜在风险,同时,也可以为软件计价、软件维护等提供技术支持。
附图说明
图1为本发明第一实施例的所述混源软件自主可控性检测方法流程示意图;
图2为本发明第一实施例的步骤s2中所述源代码分析流程示意图;
图3为本发明第一实施例的静态结构模型结构示意图;
图4为本发明第一实施例的依赖关系模型结构示意图;
图5为本发明第一实施例的代码与设计说明文档一致性分析流程示意图;
图6为本发明第一实施例的代码插装流程示意图;
图7为本发明第一实施例的语句和分支覆盖分析方法流程示意图;
图8为本发明第一实施例的数据流覆盖分析流程示意图;
图9为本发明第二实施例的混源软件自主可控性检测系统结构示意图;
图10为本发明第二实施例以c语言开发的业务传输设备软件为例所构建的静态模型示意图;
图11为本发明第二实施例对业务传输设备软件进行自主可控性检测的一致性分析结果示意图;
图12为本发明第二实施例对业务传输设备软件进行自主可控性检测的预设插装函数代码片段;
图13为本发明第二实施例对业务传输设备软件进行自主可控性检测的插装后代码片段;
图14为本发明第二实施例对业务传输设备软件进行自主可控性检测的未执行的代码段及所在程序位置的分析结果图。
具体实施方式
通过参考示范性实施例,本发明技术问题、技术方案和优点将得以阐明。然而,本发明并不受限于以下所公开的示范性实施例;可以通过不同形式来对其加以实现。说明书的实质仅仅是帮助相关领域技术人员综合理解本发明的具体细节。
本发明针对如何检验软件是否是自主开发的、开发人员是否真正理解并掌握了其提交的混源软件的问题,提出了一种混源软件自主可控性检测方法及系统,从代码静态分析和动态执行两个方面入手,通过检查代码与软件设计说明文档是否一致、代码中是否存在没有执行过的代码,从而验证混源软件是否是完全自主开发的,是否具备自主可控性。这里的自主可控性,即指自主开发。具备自主可控性,为自主开发;不具备自主可控性,为非自主开发。
下面通过具体的实施例对本发明的技术方案进行详细说明。
第一实施例
本实施例提供了一种混源软件自主可控性(开发)检测方法,对所述混源软件的代码进行静态分析,生成软件设计说明文档,并与提交的软件说明文档进行对比,通过代码与软件设计说明文档的一致性判断混源软件是否自主开发;当代码与软件设计说明文档不一致且开发人员无法合理解释时,判定为非自主开发;当代码与软件设计说明文档具备一致性或不具备一致性但是开发人员可以合理解释时,执行动态跟踪,通过测试用例对软件代码的覆盖程度来判断混源软件是否自主开发;当混源软件的代码不能被测试用例覆盖且开发人员不能合理解释时,判定为非自主开发;当混源软件的代码能够被测试用例覆盖或虽然不能被测试用例覆盖但是开发人员可以合理解释时,判定为自主开发。
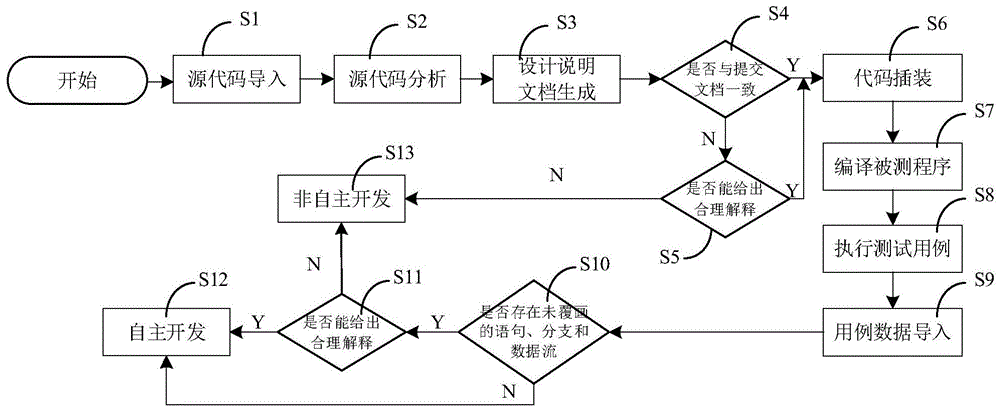
图1所示为本实施例的所述混源软件自主可控性检测方法流程示意图。如图1所示,混源软件自主可控性检测方法包括如下步骤:
步骤s1,源代码导入。
定位源代码所在的目录,并将目录中的源代码文件进行编目索引,形成源代码文件结构树。
步骤s2,源代码分析。
分析源代码的静态逻辑结构,识别出源代码中包含的变量及函数定义、内外部接口,分析各个语法元素之间的调用关系,分析结果以函数调用和数据依赖热点图的形式进行展示。源代码分析主要包括文件依赖分析和逻辑结构分析;其中,文件依赖分析主要用于找出文件间的依赖关系,设定源代码分析的顺序;逻辑结构分析主要对源代码进行语法和词法分析,分析源代码中变量、函数等语法元素的定义和相互间的引用关系,生成源代码逻辑模型。
步骤s3,根据源代码分析生成说明文档。
步骤s4,将生成的说明文档与原始提交的说明文档进行对比,判断与原始提交的说明文档是否一致;如果一致,则转入步骤s6;如果不一致,则转入步骤s5;
步骤s5,对于生成的说明文档与提交的说明文档不一致的方面,如果开发人员不能给出合理解释,则转入步骤s13;如果开发人员能给出合理解释,则转入步骤s6;
步骤s6,代码插装。
本步骤中,通过在函数体前后插入桩函数,实现对软件运行轨迹的跟踪,是在执行动态跟踪前对代码进行的处理,插装函数主要完成将执行点的id记录到数组中供分析程序处理,并在数组元素达到最大长度时将数组存入磁盘。
步骤s7,编译被测程序。
步骤s8,执行测试用例。
步骤s9,用例数据导入。
本步骤中,导入插装函数输出的记录文件,对比调用记录文件和工程逻辑模型数据,从而为下一步的分析当次操作中覆盖的函数和代码段作装备。
步骤s10,代码覆盖分析:判断是否存在未覆盖的函数变量和代码,如果不存在,则转入步骤s12;如果存在,则转入步骤s11。
本步骤中,将导入的用例执行数据与源代码模型进行匹配,分析得到用例执行后源代码中被覆盖到的函数和代码,并以图形方式显示于界面上。
步骤s11,对于未覆盖的函数变量和代码,如果开发人员可以给出合理解释,则转入步骤s12;如果开发人员不能给出合理解释,则转入步骤s13。
步骤s12,判断所述代码为自主开发代码。
步骤s13,判断所述代码为非自主开发代码。
其中,所述步骤s2至步骤s5为分析静态对比过程;所述步骤s6至步骤s10为执行动态跟踪过程。
进一步的,所述步骤s2中的源代码分析,用于分析被检测的源代码,在此基础上,生成描述其结构的静态模型,图2所示为步骤s2中所述源代码分析流程示意图。如图2所示,所述源代码分析具体包括如下步骤:
步骤s21,预处理:读取源代码并对代码预先进行翻译,对源程序中的预处理命令(#include,#line等)进行识别,调整源代码文件的分析顺序,识别源代码文件编译指令。
步骤s22,词法分析:在预处理基础上对源代码文件进行解析,收集程序符号信息,包括函数信息、变量信息、作用域信息等,同时生成程序的抽象语法树(ast)。
步骤s23,语法分析:通过迭代遍历语法树,查找函数、变量定义、typedef等节点,为节点生成源代码结构静态模型中的实体。
在迭代遍历语法树的同时,进行控制流分析,查找函数调用节点生成函数调用列表,在迭代完成且全部列表生成后,利用列表中的调用-被调用对中的函数标识与实体模型中的函数元素实体关联。
在迭代遍历语法树的同时,进行数据依赖分析,查找程序中的赋值表达式和带参数传递的函数调用,形成定义-引用对(d-upair)列表。在迭代完成且全部列表生成后,利用变量标识与实体模型中的变量定义实体关联。
步骤s24,模型生成,使用控制流分析和数据依赖分析中的数据填充完整的源代码静态结构模型实例和依赖关系模型实例,形成被测软件静态模型。
其中,步骤s24中,所述静态结构模型用于表示工程逻辑结构及元素间引用关系,图3所示为所述静态结构模型结构示意图。如图3所示,以entities工程为例,entities工程内的实体类对应静态结构中的一个节点或模块,包括:工程版本模块、源代码文件模块、函数定义模块、变量定义模块、typedef定义模块、函数声明模块、块对象模块、函数调用表达式模块、赋值表达式模块及基类模块;其中,所述工程版本模块与源代码文件模块、函数定义模块、变量定义模块、typedef定义模块关联,并构成引用关系,具体为源代码文件模块、函数定义模块、变量定义模块、typedef定义模块引用工程版本模块;函数声明模块和块对象模块引用函数定义模块,变量定义模块和typedef定义模块也引用块对象模块;函数调用表达式模块、赋值表达式模块引用块对象模块;图3中通过箭头表示引用关系,具体的关联集合显示于线上。基类模块entitybase是模型类的共同基类,表示一个语法元素,提供公共方法用于获取语法元素所对应的源代码段、符号流、抽象语法树等信息。
步骤s24中,所述依赖关系模型利用有向图构建文件、函数、变量之间的引用、调用关系,图4所示为所述依赖关系模型结构示意图。如图4所示,所述依赖关系模型中,包括三个模块,即语法元素依赖图、语法元素节点、及节点间的有向边。所述语法元素节点包括函数、变量定义,语法元素对应有向图中的节点;所述节点间的有向边对应于引用、调用关系;所述语法元素依赖图提供数个通用方法用于遍历有向图,通过在所述依赖图上上溯和下溯从而进行查询。即,语法元素节点包括函数、变量定义等,语法元素对应有向图中的节点,引用、调用关系对应于节点间的有向边。以entitygraph类为例,提供数个通用方法用于遍历有向图,通过在图上上溯和下溯查询子图的功能。
进一步的,所述步骤s5中,判断代码与设计说明文档的一致性,是通过代码生成说明文档与提交说明文档的一致性分析来进行的。所述说明文档是软件编码的依据,软件编码是软件设计的具体体现,理论上说,软件编码应该与软件设计保持一致,如果软件编码与软件设计不一致,一种情况是软件设计说明文档不准确,另一种情况是软件编码有问题。本实施例以软件设计说明文档准确无误为前提,通过静态分析源代码并生成说明文档,并与提交的说明文档是否一致,来验证软件代码是否是完全自主编写的。图5所示为本实施例所述代码与设计说明文档一致性分析流程示意图。如图5所示,代码与设计说明文档一致性分析流程如下:对开发人员编写并提交的软件设计说明文档和通过静态分析生成的软件设计说明文档进行比较,首先是“变量定义-引用比较”,如果两者一致,接着进行“函数定义比较”,如果两者一致,接着进行“内外部接口比较”,如果两者一致,接着进行“处理流程比较”,如果上述比较结果两者都一致,则认为代码是自主研发的,否则,则认为代码是非自主研发的。
进一步的,所述步骤s6中,代码插装是通过向被测程序中能够引起程序转移的位置插入特定的标记来获取代码执行信息的一种方法,图6所示为所述代码插装流程示意图。如图6所示,执行代码插装时,首先确定待插装程序段,然后查询所述待插装程序段的静态模型,这里的静态模型对应步骤s2中的源代码分析所形成的静态结构模块。对所查询的静态模型中的被测源代码语法树,遍历语法树插装点,得到插装点列表;再根据预设的插装函数,将包含插装函数头文件写入插装函数调用,从而得到插装后程序,进一步编译并执行测试用例,最后得到并输出执行信息,从而完成函数插装。其中,执行信息每行的格式形如“(±id,flag)”,表示一次函数调用,id对应静态模型中的函数标识,id前无符号代表函数调用,负号代表函数返回。符号flag代表函数返回语句return后是否还有函数调用。
进一步的,所述步骤s10中,代码覆盖分析用于查找未执行到的程序代码,对于这些没有被覆盖到的部分,如果开发人员不能给出合理的解释,则认为这部分代码是非自主开发的。为了实现上述目的,本步骤中的代码覆盖分析包括:语句和分支覆盖方法、数据流覆盖方法。
其中,所述语句和分支覆盖分析,是将插装后的程序在运行时通过插装函数输出程序执行信息,通过在静态模型中查找程序执行信息确定id所表示的函数,并依据程序执行信息的调用返回关系利用堆栈生成函数调用序列;依据调用序列和依赖关系模型对分支覆盖情况进行分析,依据语句执行序列对语句覆盖情况进行分析。图7所示为语句和分支覆盖分析方法流程示意图。如图7所示,语句和分支覆盖分析方法包括:依据程序执行信息在静态结构模型中对执行信息进行解析,根据解析结果,生成函数调用序列、语句执行序列,在此基础上,依据依赖关系模型,进行语句/分支覆盖分析,最后得出语句/分支覆盖结果。
所述数据流覆盖分析,主要用于查找被测试用例所覆盖的变量,包括变量定义、计算引用(c-use)和谓词引用(p-use)。图8所示为数据流覆盖分析流程示意图。如图8所示,进行数据流覆盖分析包括:依据程序执行信息在静态结构模型中对执行信息进行解析,根据解析结果,生成变量定义序列、变量引用序列,在此基础上,依据数据依赖模型,进行数据流覆盖分析,最后得出数据流覆盖结果。
由以上可以看出,本实施例的混源软件自主可控性检测方法,从代码静态分析和动态执行两个方面进行检测,一方面,通过检查软件代码是否与设计说明文档一致,找出软件代码中与软件设计不一致的地方;另一方面,通过检查测试用例所覆盖的软件代码,找出软件代码中的多余代码。对于这些不一致的地方和多余代码,如果软件开发人员不能给出合理的解释,则判定开发人员没有完全理解和掌握软件代码,即该软件不是完全自主开发的。该方法和装置操作简单,实用性强,能够快速、准确地检测软件是否是自主开发的,从而找出那些披着自主可控外衣的软件,有效防范非自主软件带来的潜在风险。
第二实施例
本实施例提供了一种混源软件自主可控性检测系统,图9所示为本实施例的所述混源软件自主可控性检测系统结构示意图。如图9所示,所述混源软件自主可控性检测系统包括:前端、后端及数据访问接口,其中,所述数据访问接口同时与前端和后端相连,用于前端和后端的数据传输;所述前端用于对源代码进行分析形成统一的数据模型,所述后端用于在数据模型的基础上完成自主可控性检测分析。
如图9所示,所述前端包括:源代码分析模块、源代码管理模块、动态执行跟踪模块;其中,
所述源代码管理模块,用于源代码导入。源代码管理模块通过关联被测代码,为代码访问提供服务,定位源代码所在的目录,并将目录中的源代码文件进行编目索引,形成源代码文件结构树。
所述源代码分析模块与源代码管理模块相连,通过加载源代码管理模块导入的源代码,对所导入的源代码进行分析。
进一步的,所述源代码分析模块用于分析源代码的静态逻辑结构,识别出源代码中包含的变量及函数定义、内外部接口,分析各个语法元素之间的调用关系,分析结果以函数调用和数据依赖热点图的形式进行展示。源代码分析主要包括文件依赖分析和逻辑结构分析;其中,文件依赖分析主要用于找出文件间的依赖关系,设定源代码分析的顺序;逻辑结构分析主要对源代码进行语法和词法分析,分析源代码中变量、函数等语法元素的定义和相互间的引用关系,生成源代码逻辑模型。
所述动态执行跟踪模块,与所述源代码管理模块相连,用于跟踪测试用例的执行轨迹,查找其中未执行到的程序代码。所述查找,主要包括代码插装和执行信息输出。
所述后端包括:工程数据模型模块、一致性分析模块、覆盖分析模块、模型可视化模块。其中,
所述工程数据模型模块,包括工程静态结构子模块和用例集子模块,所述工程静态结构子模块,根据所述源代码分析模块的分析结果生成工程静态结构,包括静态结构模型和依赖关系模型。所述用例集子模块,与前端的动态执行跟踪模块相连,用于根据动态执行结果生成并保存用例集。这里的动态执行结果,是动态执行跟踪模块依据静态结构对源代码进行插装,编译完成后设计测试用例实际执行软件,执行完成后加载执行过程中输出的信息。
所述一致性分析模块与所述工程数据模型模块相连,用于根据所述工程数据模型模块中的模型数据,生成混源软件的设计说明文档,并与开发人员编写的设计说明文档进行一致性比较,找出两者之间的差异,从而得出所述混源软件是否具备自主可控性。优选的,所生成的设计说明文档符合gjb438b标准。
所述覆盖分析模块与所述工程数据模型模块中的用例集子模块相连,用于对用例集覆盖源代码的情况进行计算,找出其中未被覆盖的代码。所述覆盖分析模块包括:语句覆盖分析模块、分支覆盖分析模块、数据覆盖分析模块。
模型可视化模块用于展示分析结果,便于用户更加直观、方便地掌握分析结果。例如,通过有向图显示和/或代码着色来进行源代码分析结果的展示。
优选的,本实施例的所述混源软件自主可控性检测系统还可以包括集成用户界面,用于用户与所述系统的交互。
通过本实施例的所述混源软件自主可控性检测系统,可以对开发人员所开发的软件的自主可控性进行检测,实现第一实施例的混源软件自主可控性检测方法。
下面以c语言开发的业务传输设备软件为例来说明,本实施例的混源软件自主可控性检测系统,是如何实现对软件的自主可控性检测的,同时对第一实施例的混源软件自主可控性检测方法进行详细的说明。
所述业务传输设备软件为嵌入式软件,没有图形用户界面。
步骤s101,通过源代码管理模块导入源代码;
步骤s102,通过源代码分析模块对业务传输设备软件源代码进行分析,得到软件的静态结构模型、依赖关系模型,图10所示为本实施例以c语言开发的业务传输设备软件为例所构建的静态模型示意图。如图10所示,所述源代码分析模块分析得出软件的源代码文件结构,源代码的函数、变量组成及文件、函数、变量之间的引用、调用关系,生成所述工程数据模型中的工程静态结构模型。
步骤s103,一致性分析模块根据所生成的工程静态结构模型,通过检查软件编码是否与软件设计说明文档是否一致来验证软件编码是否是完全自主编写的。图11框选显示部分为与提供的设计文档不一致的类成员函数,对比情况分为四类,一致、参数不一致、返回值不一致、文档中未涉及(函数名不一致也归为此类)。
步骤s104,动态执行跟踪。动态执行跟踪模块通过对软件源代码插入特定标记,结合预设插装函数对代码的执行进行跟踪。图12为预设插装函数代码片段,图13为插装后的代码片段。
步骤s105,根据动态执行跟踪的结果,对插装后的源代码进行编译,设计测试用例实际执行软件并加载执行过程中输出的信息,生成所述工程数据模型中的用例集。
步骤s106,代码覆盖分析模块通过运行插装后的源代码,查找未执行到的程序代码。图14框选显示部分为未执行的代码段及其所在的程序位置。由此可以判断所述业务传输设备软件不具备自主可控性。
由以上可以看出,本实施例的所述混源软件自主可控性检测系统,从代码静态分析和动态执行两个方面进行检测,一方面,通过检查软件代码是否与设计说明文档一致,找出软件代码中与软件设计不一致的地方;另一方面,通过检查测试用例所覆盖的软件代码,找出软件代码中的多余代码。对于这些不一致的地方和多余代码,如果软件开发人员不能给出合理的解释,则判定开发人员没有完全理解和掌握软件代码,即该软件不是完全自主开发的。该方法和装置操作简单,实用性强,能够快速、准确地检测软件是否是自主开发的,从而找出那些披着自主可控外衣的软件,有效防范非自主软件带来的潜在风险。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!