基于语义特性提取位置指示词的位置推断方法与流程
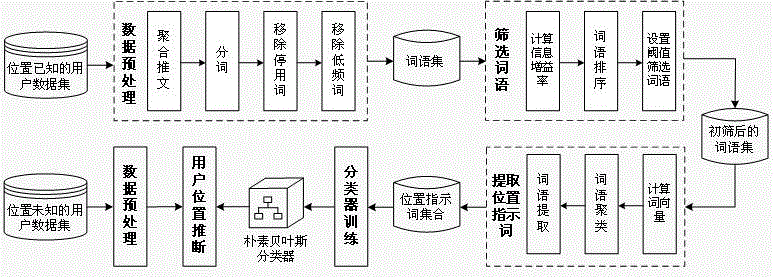
本发明涉及位置推断技术领域,尤其涉及基于语义特性提取指示位置词的位置推断方法。
背景技术:
目前,近年来,以twitter、facebook和新浪微博等为代表的国内外社交媒体,发展十分迅猛,为用户提供了如发布动态、位置签到、评论互动等服务,给人们的生活带来了极大的便利。这些服务形成的数据具有极高的使用价值,其中蕴含的位置信息可以将虚拟用户与现实世界关联起来,应用于监测居民的健康状况、推荐周边活动、识别紧急状况发生地、检测地区性社团、预测各地区的选举结果等方面。然而,由于社交媒体对用户发布的位置数据没有严格的要求,用户可能不提供位置或提供错误的位置。相关文献的统计结果表明,美国的twitter数据集中只有21%的用户在注册资料中提供了位置,而且这些位置也不完全准确。此外,社交媒体用户发布的文本中带有位置签到标签的数据也十分稀疏,ryoo等人观察到其数据集中只有大约0.4%的推文带有位置签到标签,类似的观察结果也出现在文中。然而,用户位置可以通过文本中出现的某些词语,如方言、当地建筑名、特色小吃名、城市名等进行推断。除了文本,其他类型的社交媒体数据,如关注/粉丝、教育信息、职业信息等也可以推断用户位置。如何利用社交媒体数据推断用户位置是一个非常值得研究的问题,也具有重要的理论和现实意义。
目前,社交媒体用户位置推断的粒度一般在城市级,有时在州级或国家级。社交媒体用户位置推断的方法主要有基于朋友关系的位置推断、基于用户文本的位置推断和基于多种社交媒体数据融合的位置推断等。文假设互相关注的用户之间是真实位置邻近的朋友关系,基于用户的关注/粉丝数据推断用户位置。然而,这种假设与事实不完全符合。kong等人发现,两个互相关注的用户如果有一半以上的共同朋友,则距离邻近的概率为83%;如果仅有10%的共同朋友,距离邻近的概率则下降到2.4%。与kong等人的结论相似,研究表明相互关注的用户之间的真实位置不一定邻近。大多数基于朋友关系推断用户位置的方法都依赖于用户的全部关注/粉丝数据的获取。然而,随着隐私保护力度的加强,已经无法获取用户的全部关注/粉丝数据,现有的基于朋友关系推断用户位置的方法受到极大的限制。
由于用户文本的丰富性和可获取性,基于用户文本的位置推断方法一直被广泛研究。cheng等人识别文本中的地标名词,并对词语的地理属性建模推断用户位置。但是,cheng等人的方法需要人工标注构建分类器来识别地标名词;同时,该方法将各城市中心点坐标作为参照点来计算词语与位置的关系,参照点过少且与实际位置的偏差较大。ryoo等人改进了cheng等人的方法,利用推文中签到位置的坐标作为参照点,减少了与实际位置的偏差。但是,ryoo等人的发明仅利用带位置签到标签的推文进行建模,忽略了不带位置签到标签推文中蕴含的位置信息。另一些发明基于用户文本提取能够指示位置的词语进行位置推断。相关文献中通常将这样的词语称为位置指示词或本地词语。一种位置指示词是直接指示位置的词语,如城市名、特有街道名、地标建筑名等;另一种是间接暗示特定位置的词语,如特色小吃名“烩面”,方言词语“合计”。例如,ren等人基于词语的反向位置频率提取位置指示词推断用户位置。但是,提取的词语中仍存在大量反向位置频率较高的干扰词。受信息论的启发,han等人认为位置指示词的分布应该比普通词更有偏向性,他们分别基于词语的信息增益率和最大熵提取位置指示词训练朴素贝叶斯分类器推断用户位置。相比词语的反向位置频率,词语的信息增益率和最大熵能够更好地提取位置指示词。现有研究比较了现有的基于位置指示词的位置推断方法,实验结果表明基于词语的信息增益率推断位置的方法表现最好。然而,现有方法都没有考虑词语上下文的特点,提取的词语中仍存在影响位置推断准确性的干扰词。此外,chi等人将用户文本的特征细分为位置指示词、国家/城市名、#hashtag#、@mention四种,并基于信息增益率提取位置指示词,再基于频次选择特征训练朴素贝叶斯分类器推断位置。然而,chi等人基于频次选择特征不能过滤高频的噪音,会影响位置推断的准确性,即现有的方法基于词语的词频、信息增益率、最大熵等提取位置指示词,没有考虑词语上下文的特点,存在大量干扰词,影响了位置推断的准确性。
基于文本的方法往往将用户位置推断问题看作文本分类问题,将用户位置作为分类标签,从文本中提取位置指示词训练分类器进行位置推断。位置推断的准确性主要依赖于位置指示词提取的好坏。现有的方法基于词语的反向位置频率、最大熵、信息增益率等提取位置指示词。尽管这些方法考虑了位置指示词在统计分布上的特点,能够较好地提取词语实现位置推断。但是,这些方法可能忽略了一些与位置指示词统计分布相似的普通词语,干扰词的存在往往会影响位置推断的准确性。
技术实现要素:
本发明的目的是提供一种基于语义特性提取位置指示词的位置推断方法,能够充分利用word2vec表述词语的语义特性,更准确地提取位置指示词,提高位置推断的准确性。
本发明采用的技术方案为:
基于语义特性提取位置指示词的位置推断方法,包括如下步骤:
a:数据预处理,对所有用户发布的所有推文数据进行预处理;
b:词语筛选,基于信息增益率对词语进行初步筛选;
c:位置指示词提取,利用word2vec构建词向量,基于语义特性提取位置指示词;
d:分类器训练,利用位置指示词训练朴素贝叶斯分类器;
e:用户位置推断,利用训练好的朴素贝叶斯分类器推断用户位置。
所述步骤a中,数据预处理具体包括如下步骤:
a1,聚合推文:将每个用户发布的所有推文聚合为一个文本,有多少个用户就有多少个文本;
a2,对标记后的用户文本进行分词:英文按空格分隔划分词语;中文利用现有的汉语分词工具进行分词;
a3,移除停用词:对于使用不同语言的社交媒体用户文本,需要根据相应的语言构建相应的停用词词表,基于构建的停用词词表,移除停用词:
a4,移除低频词:移除词频小于阈值n1的词语。
所述步骤b中,词语初步筛选具体包括如下步骤:
b1,计算信息增益率;
b2,词语排序:按照词语信息增益率的大小,对词语进行降序排序;
b3,设置阈值筛选词语:设置百分比阈值,选出信息增益率前n2%的词语。
所述步骤c中,词语提取具体包括如下步骤:
c1,计算词向量:将训练集用户的tweets作为语料库,利用word2vec计算语料库中每个词语的词向量;
c2,聚类词语:利用现有的聚类算法基于词向量将筛选得到的词语聚为k个簇,语义相似的词语会被聚到一起,每一个簇内的词语可看作同一类词语;
c3,词语提取:基于聚类形成的k个簇,把每一个簇看作一个整体,将位置指示词提取的过程看作是特征选择的过程;因此,位置指示词的提取过程,就是从k个簇中选出最佳的子集。
所述的步骤c3中,词语提取具体包括如下步骤:
c3.1,从k个簇构成的全集开始搜索簇子集,当前的簇子集记为wo;在训练集上,利用5折交叉验证法估计基于簇子集wo训练的分类器的平均分类错误率,记为eo;
c3.2,从当前的簇子集wo中,依次任意地删除一个簇,得到一个新的簇子集;在训练集上,利用五折交叉验证法估计基于新的簇子集训练的分类器的平均分类错误率;将平均分类错误率最小的新的簇子集记为w#,其平均分类错误率记为e#;
c3.3,如果e#小于或等于eo,那么将当前的簇子集wo更新为w#,eo更新为e#;跳转到步骤c3.2,继续搜索最佳簇子集;
c3.4,否则e#大于eo,停止搜索,算法结束;停止搜索时,当前的簇子集wo中词语构成位置指示词集合。
所述的步骤d中,分类器训练具体包括如下步骤:
d1,计算类先验概率:即,计算位于位置lj的用户占全部用户的比例;
d2,计算条件概率:即,计算位置指示词wi出现在不同位置的用户文本中的条件概率。
所述的步骤e中,用户位置推断具体包括如下步骤:
e1,计算待推断位置的用户位于每个位置的概率:即利用用户的文本中出现的位置指示词wi及词频teufi,计算用户teu位于位置lj的概率:
e2,取概率最大的位置作为推断结果:
本发明首先对文本数据进行预处理,得到词语集;其次,根据信息增益率对词语进行初筛;然后,利用word2vec构建词向量,通过聚类将语义相似的词语聚到一起,并利用序列后向的包裹式特征选择方式从聚类形成的簇中提取位置指示词;接着,利用位置指示词训练朴素贝叶斯分类器;最后,利用训练好的分类器进行用户位置推断。本发明充分利用word2vec来表述词语的语义特性,可有效提升位置指示词提取的准确性,从而提升位置推断的准确性。
附图说明
图1为本发明的流程图;
图2为本发明所述聚类簇数对位置推断准确率的影响示意图;
图3为本发明所述词语相似度计算结果示意图;
图4为本发明所述用户位置推断结果对比示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明包括如下步骤:
a:数据预处理,对所有用户发布的所有推文数据进行预处理;
所述步骤a中,数据预处理具体包括如下步骤:
a1,聚合推文:将每个用户发布的所有推文聚合为一个文本,有多少个用户就有多少个文本;
a2,对标记后的用户文本进行分词:英文按空格分隔划分词语;中文利用现有的汉语分词工具进行分词;
a3,移除停用词。对于使用不同语言的社交媒体用户文本,需要根据相应的语言构建相应的停用词词表。基于构建的停用词词表,移除停用词。
a4,移除低频词。移除词频小于阈值n1的词语。
b:词语筛选,基于信息增益率对词语进行初步筛选;
所述步骤b中,词语筛选具体包括如下步骤:
b1,计算信息增益率。信息增益率的计算过程均为现有的技术,在此不再赘述其具体的计算过程。
b2,词语排序。按照词语信息增益率的大小,对词语进行降序排序。
b3,设置阈值筛选词语。设置百分比阈值,选出信息增益率前n2%的词语c:位置指示词提取,利用word2vec构建词向量,基于语义特性提取位置指示词。
所述步骤c中,词语提取具体包括如下步骤:
c1,计算词向量。将训练集用户的tweets作为语料库,利用word2vec计算语料库中每个词语的词向量。
c2,聚类词语。利用现有的聚类算法基于词向量将筛选得到的词语聚为k个簇。语义相似的词语会被聚到一起,每一个簇内的词语可看作同一类词语。
c3,词语提取。基于聚类形成的k个簇,把每一个簇看作一个整体,将位置指示词提取的过程看作是特征选择的过程。因此,位置指示词的提取过程,就是从k个簇中选出最佳的子集。这个过程类似于文本分类中从k个特征中选出最佳特征子集的过程。
所述步骤c3中,词语提取具体包括如下步骤:
c3.1,从k个簇构成的全集开始搜索簇子集,当前的簇子集记为wo。在训练集上,利用5折交叉验证法估计基于簇子集wo训练的分类器的平均分类错误率,记为eo。
c3.2,从当前的簇子集wo中,依次任意地删除一个簇,得到一个新的簇子集。在训练集上,利用5折交叉验证法估计基于新的簇子集训练的分类器的平均分类错误率。将平均分类错误率最小的新的簇子集记为w#,其平均分类错误率记为e#。
c3.3,如果e#小于或等于eo,那么将当前的簇子集wo更新为w#,eo更新为e#。跳转到c3.2,继续搜索最佳簇子集。
c3.4,否则e#大于eo,停止搜索,算法结束。停止搜索时,当前的簇子集wo中词语构成位置指示词集合。
d:分类器训练,利用位置指示词训练朴素贝叶斯分类器。所述的步骤d中,分类器训练具体包括如下步骤:
d1,计算类先验概率。即,计算位于位置lj的用户占全部用户的比例:
d2,计算条件概率。即,计算位置指示词w_i出现在不同位置的用户文本中的条件概率:
e:用户位置推断,利用训练好的朴素贝叶斯分类器推断用户位置。所述的步骤e中,用户位置推断具体包括如下步骤:
e1,计算待推断位置的用户位于每个位置的概率。即利用用户的文本中出现的位置指示词wi及词频teufi,计算用户teu位于位置lj的概率:
e2,取概率最大的位置作为推断结果:
本发明中,位置指示词提取的基本思想是:利用word2vec计算蕴含了语义信息的词向量,且词向量距离的远近反映了词语的语义相似度。基于词向量聚类词语,将语义相似的词语聚到一起。采用序列向后的包裹式特征选择方式,从聚类形成的簇中选出最佳的簇子集。将选出的簇子集中的词语作为位置指示词。
如表1所示,为了便于算法的描述和方便阅读,定义符号如表1所示:
表1
采用上述方法,以具体的举例进行说明方法的具体使用过程,同时可以在此进行验证word2vec能否将上下文相似的词语映射到向量空间中相近的位置;以及验证基于语义特性是否能够准确地提取位置指示词,提高位置推断的准确性。
具体如下:
目前,由于隐私保护,没有公开可用的社交媒体用户数据集。新浪微博是一个为大规模用户提供位置签到、发布动态、评论互动等服务的中文社交媒体。本文以新浪微博为例,利用新浪微博开放的api接口爬取到274459个中国用户的数据。用户位置信息的统计结果,约48.36%的用户填写了城市级位置,约22.16%的用户填写了省级位置,29.48%的用户没有明确声明自己的位置。为了清洗并移除的异常数据,过滤掉声称位置不正确或不清楚的用户,以及发布推文数量少于5条的用户。此外,删除用户数量少于100的城市,并将用户声称的位置作为本文实验的ground-truth。最终,实验的城市级数据集(city)由179个城市的102735个用户的3085972条微博组成;按用户所在城市所属省级位置确定用户的省级位置,实验的省级数据集(province)由城市级数据集中的全部用户和准确填写了省级位置的51743用户的776145条微博组成。两个数据集的统计信息,在实验中,将每个数据集划分为两部分:从每个位置的全部用户中随机地选择20%的用户作为测试数据,其余的80%作为训练数据。
参数设置
利用现有常用的中文分词工具进行分词。根据3.2中验证性实验的结果,将n1设置为3。按照经验合理地将n2设置为25。
对于中文数据集,从网页上获取哈尔滨工业大学、四川大学机器智能实验室、和百度公式提供的停用词表,并去重合并表中的词语,构成本文实验的中文停用词词表,词语数量共计1893。对于英文数据集,从网页上获取谷歌提供的停用词词表,作为本文实验的英文停用词词表,词语数量共计891个。
设置计算词向量的参数。利用word2vec计算词向量时,将参数size、window、min_count、sg分别设置为200、5、5、1。size是输出词向量的维数,值太小会导致词语与词向量的映射会产生冲突,值太大会导致内存和时间开销过大,一般值取为100到200之间;本文实验中词语数量较多,将size设置为200较为合理。window是句子中当前词与目标词之间的最大距离,window=5表示在目标词前看5-b个词,后面看b个词,其中b是0到3之间的随机数。min_count是词频,表示不计算频率小于min_count的词语的词向量,将min_count设置为3能够很好地满足词向量计算的需求。word2vec包含了两种不同的训练模型,分别是cbow和skip-gram,sg=1表示使用skip-gram模型训练。cbow模型因为window大小的限制,导致无法预测与window以外词语的关系;而skip-gram模型会通过跳跃词语来构建词组,能够避免因window大小限制导致语义信息丢失的问题,比较适合算法的要求。
k-means聚类时,聚类簇数能够影响干扰词过滤的效果,从而影响位置推断的准确性。如图2所示,随着聚类簇数的逐渐增大,位置推断准确率逐渐增加;但是,当聚类簇数大于20以后,位置推断准确率随着聚类簇数增加而增加的趋势变得十分平缓。权衡时间开销和干扰词过滤效果,将聚类簇数设为20较为合理。
将本文算法与以下两种先进的基于用户文本的位置推断方法进行对比:
(1)han’smethod.han等人基于词语的信息增益率提取位置指示词,利用位置指示词训练朴素贝叶斯分类器推断用户位置。
(2)chi’smethod.chi等人将文本特征分为位置指示词、国家/城市名、#hashtag、@mentions四种,利用han等人提出的方法提取位置指示词,基于频次的选择特征训练朴素贝叶斯分类器推断用户位置。
词向量计算结果
本文实验中使用word2vec的skip-gram模型计算词向量,其训练的时间复杂度为o(c×s×|w|)。其中,c是word2vec的skip-gram模型输入层的window大小,s表示词向量的维数,|w|表示训练语料的词语集合w的大小。利用word2vec的skip-gram模型从文本中学习包含了词语上下文的词向量。通过计算词向量之间的距离,得到与“北京”、“寻思”、“烩面”、“清华大学”四个位置指示词最相似的5个词语,如图3所示,与城市名“北京”最相似的词语也都是城市名;与东北地区的方言“寻思”最相似的词语都是各地区方言词汇;与河南地区特色小吃“烩面”最相似的词语都是各地区特色小吃名;与“清华大学”最相似的词语都是一些学校名称。这说明word2vec能够将上下文相似的词语映射到向量空间距离相近的位置,并且词向量之间距离的远近能够反映词语上下文的相似程度。
位置推断结果
由干扰词过滤的位置推断算法可知,利用朴素贝叶斯分类器推断用户位置的时间复杂度为o(|l|×|w*|)。实验中,|l|为数据集中全部候选位置的数量,|w*|为位置指示词集合中词语数量。
在两个数据集上进行实验对比,位置推断结果如图4所示。从如图4可以看出,本文算法的城市级/省级位置的推断准确率分别为52.1%和69.5%,比两种对比方法的位置推断准确率都高。三种方法中,chi等人发明的城市级/省级位置推断准确率都最低。主要原因在于chi等人的方法提取特征中噪音最多。一方面,一些热门话题如#世界杯#、#体育#、#心灵巴士#等并不能像#郑在郑州#、#遵义身边事#、#北京印象#等那样指示位置;另一方面,基于频次选择特征并不能过滤高频的干扰特征。然而,本文算法不仅能够将#郑在郑州#、#遵义身边事#、#北京印象#等热门话题中的位置指示词“郑州”、“遵义”、“北京”等提取出来,而且能够将“世界杯”、“体育”、“心灵巴士”等词语过滤掉。相比han等人的方法,本文算法的城市级/省级位置推断准确率分别提高了4.6%和3.6%。han等人的方法基于词语的信息增益率提取词语,能够根据词语划分类别发挥作用的大小,去除对分类作用较小的词语,即不利于位置推断的词语。然而,这种方法提取的词语中不仅有方言词语“捯饬”、特色小吃名“烩面”和地标名“东方之珠”等能够指示位置的词语,还混合着不能指示位置的干扰词,如“生物”、“计算机”、“感冒”等。
由此可见,本文算法进一步考虑了词语上下文的特点,能够过滤掉“生物”、“计算机”、“感冒”等信息增益率较大的干扰词,提升位置推断准确率。研究了基于文本的位置推断方法,并分析了影响位置推断准确性的主要因素。本发明给出了一种基于语义特性提取位置指示词的推断方法。该方法的创新之处在于考虑了文本中词语的语义差异,基于语义相似度提取位置指示词。利用word2vec计算蕴含了语义信息的词向量,基于词向量聚类将语义相似的词语聚到一起,并利用序列后向的包裹式特征选择的方式从聚类形成的簇中选出最佳的簇子集,实现位置指示词的提取。在微博和twitter两种数据集上进行实验,实验结果验证了提出方法的能够基于语义特性更准确地提取位置指示词,比现有最佳方法的位置推断效果更好。
- 还没有人留言评论。精彩留言会获得点赞!