一种文本识别方法和装置与流程
本发明涉及计算机技术,尤指一种文本识别方法和装置。
背景技术:
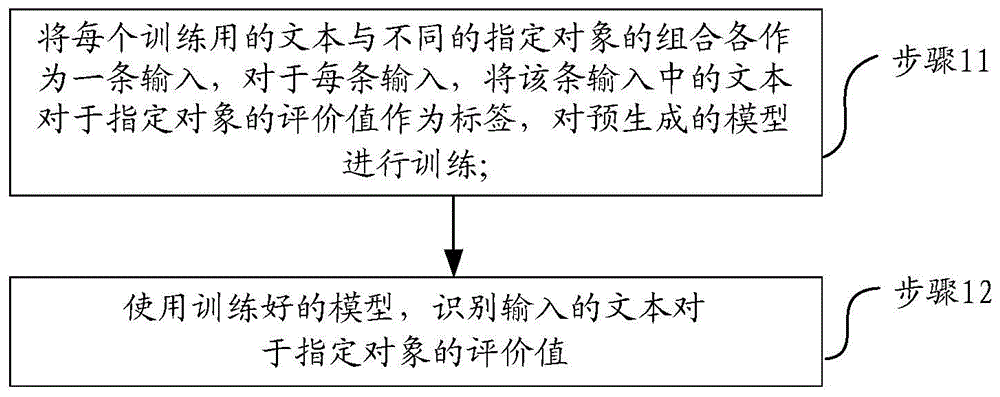
:随着计算机软件、硬件、以及互联网行业的发展,大数据已经成为生活中密不可分的一部分,然而针对非结构化的数据,例如:社会网络舆情,产品意见反馈,酒店餐饮评论等,各行各业的大量非结构化文本的处理都需要人工参与阅读分析总结,最终来确定产品或服务或其他方面需要提高的部分,非常耗时耗力。在传统的情感分类方法中,我们只能大致通过文本整体的极性(积极的或者消极的),来分析对象的特征(如:产品的好坏程度),但是细粒度的区分对象的特征的情感是有所欠缺的。再如,用户反馈:该产品操作非常简单,用户界面设计简洁,但是软件的加载速度耗时比较长。上述反馈信息使用传统的分类方法,仅仅区分区为积极的或者消极,并不能很好的进行情感分类。除了关注整体的情感外,更应该关注细节(指定对象)上的情感分类,例如,操作的分类(简单or复杂),加载速度的分类(快or慢),用户界面的分类(简洁or混乱)等。可见,传统的情感分类只能从句子的整体来区分情感的导向情况,积极或者消极或着多层级的情感分类,但难以针对单一句子中不同实体(指定对象)的情感进行分析。技术实现要素:为了解决上述技术问题,本发明提供了一种文本识别方法和装置,能够高效识别文本中不同实体的评价值。为了达到本发明目的,本发明提供了一种文本识别方法,所述方法包括:将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;使用训练好的模型,识别输入的文本对于指定对象的评价值。一种示例性的实施例中,所述对预生成的模型进行训练前还包括:根据搜集的文本进行无监督的模型训练,在所述无监督的模型的输出层后加上全连接层,作为所述预生成的模型。一种示例性的实施例中,所述根据搜集的文本进行无监督的模型训练,包括:对搜集的文本进行屏蔽词预测和句子连接关系预测,得到所述无监督的模型。一种示例性的实施例中,所述将每个训练用的文本与不同的指定对象的组合各作为一条输入包括:对所述每个训练用的文本进行如下操作:将该训练用的文本和不同的指定对象分别进行组合,组合时将文本和指定对象用预定字符连接;对于每种组合结果分别进行嵌入,所述嵌入包括字嵌入、段落嵌入和位置嵌入;所述字嵌入是指将输入句子拆分成字级别,并对句子中每一个字都做字嵌入;所述段落嵌入是指使用不同字母标识输入中不同的句子或字段;所述位置嵌入是指为输入中的每一个字符标注具体位置信息;对于每种组合结果,分别根据所述进行嵌入后的训练用的文本和进行嵌入后的指定对象获取一条输入。一种示例性的实施例中,所述使用训练好的模型,识别输入的文本对于指定对象的评价值,包括:当所述指定对象为一个时,所述评价值为所述指定对象的分类结果;当所述指定对象为两个或以上时,所述评价值为所述指定对象的分类结果的表格;其中,所述分类结果包括积极、未提及和消极。为了达到本发明目的,本发明还提供了一种文本识别装置,包括:存储器和处理器;所述存储器,用于保存用于性能测试的程序;所述处理器,用于读取执行所述用于性能测试的程序,执行如下操作:将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;使用训练好的模型,识别输入的文本对于指定对象的评价值。一种示例性的实施例中,所述处理器对预生成的模型进行训练前,还执行如下操作:根据搜集的文本进行无监督的模型训练,在所述无监督的模型的输出层后加上全连接层,作为所述预生成的模型。一种示例性的实施例中,所述根据搜集的文本进行无监督的模型训练,包括:对搜集的文本进行屏蔽词预测和句子连接关系预测,得到所述无监督的模型。一种示例性的实施例中,所述处理器读取执行所述用于性能测试的程序,还执行如下操作:在所述将每个训练用的文本以及不同的指定对象分别作为输入之前,对所述每个训练用的文本进行如下操作:将该训练用的文本和不同的指定对象分别进行组合,组合时将文本和指定对象用预定字符连接;对于每种组合结果分别进行嵌入,所述嵌入包括字嵌入、段落嵌入和位置嵌入;所述字嵌入是指将输入句子拆分成字级别,并对句子中每一个字都做字嵌入;所述段落嵌入是指使用不同字母标识输入中不同的句子或字段;所述位置嵌入是指为输入中的每一个字符标注具体位置信息;对于每种组合结果,分别根据所述进行嵌入后的训练用的文本和进行嵌入后的指定对象获取一条输入。一种示例性的实施例中,所述处理器使用训练好的模型,识别输入的文本对于指定对象的评价值,包括:当所述指定对象为一个时,所述评价值为所述指定对象的分类结果;当所述指定对象为两个或以上时,所述评价值为所述指定对象的分类结果的表格;其中,所述分类结果包括积极、未提及和消极。与现有技术相比,本发明包括将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;使用训练好的模型,识别输入的文本对于指定对象的评价值。相较于传统有监督模型,对无监督模型进行训练,得到有监督模型,不需要使用大量的标注数据来确保最终的模型效果,能够节省人力,实现对文本中不同实体的情感进行分析。本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。附图说明附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。图1为本发明实施例一的文本识别方法的流程图;图2为本发明实施例二的文本识别方法文本的输入输出结构定义示意图;图3为本发明实施例三的文本识别装置的结构示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。实施例一本实施例提供了一种文本识别方法,如图1所示,该方法包括s11-s12:s11、将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;s12、使用训练好的模型,识别输入的文本对于指定对象的评价值。本发明实施例中,对预生成的模型进行训练,识别输入的文本对于指定对象的评价值,其中,不同的指定对象可以对应不同实体;相较于传统有监督模型,不需要使用大量的标注数据来确保最终的模型效果,还能够节省人力,实现对文本中不同实体的情感进行分析。一种示例性的实施例中,搜集的文本是指特定领域搜集的,如餐饮服务。当特定领域为餐饮服务时,指定对象可以为环境、味道和服务态度等实体。标签是对于指定对象的评价值;例如,对于文本1“这儿的环境很好”,指定对象环境、味道和服务态度和文本1可以各组成一个输入;当其中一个指定对象和文本1作为输入时,标签是对于该指定对象的评价值,如当“这儿的环境很好”和“环境”作为输入时,标签为“好”,对应的评价值为“1”。评价值可以是“-1、0、1”;标签(评价值)可以为可以为好、未提及和不好,还可以为“-1、0、1”,还可以为字母或单词等。一种示例性的实施例中,所述对预生成的模型进行训练前还包括:根据搜集的文本进行无监督的模型训练,在所述无监督的模型的输出层后加上全连接层,作为所述预生成的模型。搜集的文本是不分领域搜集的。一种示例性的实施例中,预生成的模型指在无监督训练后得到无监督的模型基础上加上全连接层后生成的有监督模型,指定对象即指定的实体词,例如,用于评论餐饮行业的实体词包括:环境、服务态度、味道等。一种示例性的实施例中,所述根据搜集的文本进行无监督的模型训练,包括:对搜集的文本进行屏蔽词预测和句子连接关系预测,得到所述无监督的模型。一种示例性的实施例中,所述将每个训练用的文本与不同的指定对象的组合各作为一条输入,包括:对所述每个训练用的文本进行如下操作:将该训练用的文本和不同的指定对象分别进行组合,组合时将文本和指定对象用预定字符连接;对于每种组合结果分别进行嵌入,所述嵌入包括字嵌入、段落嵌入和位置嵌入;所述字嵌入是指将输入句子拆分成字级别,并对句子中每一个字都做字嵌入;所述段落嵌入是指使用不同字母标识输入中不同的句子或字段;所述位置嵌入是指为输入中的每一个字符标注具体位置信息;一种示例性的实施例中,比如文本1和指定对象a、b、c分别组合,并用预定字符连接,得到的组合结果为:<cls>文本1<sep>a<sep><cls>文本1<sep>b<sep><cls>文本1<sep>c<sep>其中,<cls>用于标识文本起始;第一个<sep>用于标识之前数据为文本、之后数据为指定对象;第二个<sep>用于标识指定对象结束。一种示例性的实施例中,字嵌入是指将输入句子拆分成字级别,并对句子中每一个字都做字嵌入(wordembedding);段落嵌入是指使用不同字母标识输入中不同的句子或字段,从而区分输入是单句还是一对或一组句子或字段,比如用a和b分别标识输入中的不同句子或字段;例如对于文本和指定对象的组合,可以用a标识文本中的每一个字符,用b标识指定对象中的每一个字符;位置嵌入是指为输入中的每一个字符(包括文本、文本和指定对象之间的分隔符、指定对象等)标注具体位置信息,每一个字符对应于一个位置,比如但不限于用序号进行标注。对于每种组合结果,分别根据所述进行嵌入后的训练用的文本和进行嵌入后的指定对象获取一条输入。一种示例性的实施例中,所述使用训练好的模型,识别输入的文本对于指定对象的评价值,包括:当所述指定对象为一个时,所述评价值为所述指定对象的分类结果;当所述指定对象为两个或以上时,所述评价值为所述指定对象的分类结果的表格;其中,所述分类结果包括积极、未提及和消极。本发明实施例中,将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;使用训练好的模型,识别输入的文本对于指定对象的评价值。相较于传统有监督模型,不需要使用大量的标注数据来确保最终的模型效果,能够节省人力,实现对文本中不同实体的情感进行分析。实施例二一种基于实体的情感分类方法中有以下缺点:(1)使用句法规则和实体及情感之间的关联来积累实体词和情感词,但非常依赖于手动定义的规则,并且严格遵循特定的词性规则。(2)将实体词抽取于实体情感分类分为两个不同的任务,即在判断情感时并不考虑针对的实体的信息,这样会导致分类不正确。因为同一个形容词在对不同实体或在不同领域的不同实体使用时,表达的情感是不一样的。所以,需要考虑实体词和情感词之间的信息交互。(3)基于深度学习的基于实体的情感分类中,大多使用rnn模型(lstm,gruetc)或者cnn模型作为模型的基础,前者在训练速度上较后者有着很大的劣势,后者在序列信息上较前者有着很大的劣势,但两种方式都需要大量的有监督训练文本。可见,上述基于实体的情感分类方法需要大量人工去进行结果标注,比较繁琐,效率较低。如何高效的挖掘舆情中的关键信息,提高监控社会态势、提升产品质量等任务的自动化程度,成为了处理非结构化数据过程中必不可少的任务。本实施例文本识别方法包括以下步骤:1、文本(语料信息)搜集所述文本搜集包括两部分,一是搜集无监督预训练神经网络语言模型(即无监督的模型)使用的文本;二是使用上述构建的模型,进行特定领域特定任务的有监督训练时(即有监督模型),搜集有监督训练模型使用的文本。(1)无监督预训练文本的搜集通过搜集不限定领域的文本,构建预训练文本集dpretrain;其中,所述领域包括以下一种或多种:服装、餐饮、酒店等;文本包括:餐馆评论、售后评论、产品反馈、微博舆情等。(2)有监督训练文本的搜集与文本构建1)搜集针对特定领域特定任务的文本,构建领域训练集ddomain;文本包括:餐馆评论、售后评论、产品反馈、微博舆情等;对特定领域是指预进行评价的领域。2)针对特定领域任务,确定需要进行分析的对象数目与名称,初始化文本标签ldomain;3)对数据集中每一条文本,标注面向指定对象的训练标签,具体标签类型可根据需求设定,例如表一所示:表一indexsourcetextaspect1aspect2aspect3aspect4aspect5...1text11-1100…2text2000-11………………………其中,aspect1~aspect5表示想要关注的实体(指定对象),sourcetext列表下的text为不同的文本,标签类型可以使用数字表示,如:“1、-1、0”,其中,“0”表示未提及,“1”表示positive,“-1”表示negative;4)构建监督文本数据例如,表二所示的为有监督文本数据:表二表二中的index为序号;input为输入,target为不同的文本的标签,输入对应的框架为:<cls>+文本+<sep>+指定对象+<sep>;其中,text为不同的文本;aspect为指定对象;<cls>用于标识文本起始;第一个<sep>用于标识之前数据为文本、之后数据为指定对象;第二个<sep>用于标识指定对象结束。2、构建无监督预训练神经网络语言模型(1)模型参数设置所述模型参数设置是指对神经网络语言模型的常规设置,如隐藏层大小、层数等。(2)屏蔽词预训练(mlm-maskedlanguagemodel)屏蔽词预训练即随机的掩盖一定比例的输入token,然后只预测这些被掩盖的token。例如:input:<cls>这家餐厅的<mask1>境非常优雅,味道也很<mask2>错。label:<mask1>=环,<mask2>=不当掩盖了输入中的“环”和“不”时,所述无监督预训练神经网络语言模型能够预测出被掩盖的词。(3)句子关系预训练(nsp-nextsentenceprediction)输入两个有前后关系(1=isnext)或无前后关系(0=notnext)的句子,并用<sep>分隔,对他们进行前后关系预测。inputsentencea:这家餐厅的环境非常优雅,味道也很不错。inputsentenceb:唯独服务员的态度有些爱答不理。input:<cls>这家餐厅的环境非常优雅,味道也很不错。<sep>唯独服务员的态度有些爱答不理。<sep>(4)得到预训练好的语言模型lm(languagemodel)。3、针对特定任务的模型改造与有监督训练(1)迁移学习迁移学习前需加载步骤2中预训练好的模型结构与参数。(2)模型结构改造1)针对特定任务在预训练好的模型基础上进行结构改造,在预训练模型的输出层之后,增加一层全连接层(输出维度为情感分类维度(如上述标签类型包括“1、-1、0”三个维度));2)softmax结果输出(100表示positive,010表示未提及,001表示negative);(3)输入输出文本结构定义输入输出文本结构定义如图2所示,其中:1)输入:该任务输入分为两部分,第一部分为评论文本信息,第二部分为关注的对象信息(指定对象),并用<sep>分隔。i.tokenembedding(字嵌入):将输入句子拆分成字级别,并对句子中每一个字都做字嵌入(wordembedding);ii.segmentembedding(段落嵌入):使用不同字母标识输入中不同的句子或字段,从而区分输入是单句还是一对或一组句子或字段,比如用a和b分别标识输入中的不同句子或字段;iii.positionembedding(位置嵌入):输入中的每一个字符(包括文本、文本和指定对象之间的分隔符、指定对象等)标注具体位置信息,比如但不限于用序号进行标注;iv.modelinput=字嵌入+段落嵌入+位置嵌入;将步骤i~iii进行字嵌入、段落嵌入和位置嵌入后的数据进行矢量求和,可以得到该文本对于某个指定对象的一条输入。其中,步骤i~iii的先后顺序不做具体限定。例如,文本为“这家店也就交通非诚方便,人均消费比较高”,指定对象为“餐馆环境”;用预定字符连接获得:<cls>这家店也就交通非诚方便,人均消费比较高<sep>餐馆环境<sep>;进行字嵌入,“<cls>这家店也就交通非诚方便,人均消费比较高<sep>餐馆环境<sep>”中的每个字均可用向量表示,每个字与与之对应向量预先已存储,可以通过查询获得,即加上“<cls>”和两个“<sep>”后共计25个向量;进行段落嵌入获得:aaaaaaaaaaaaaaaaaaaabbbb;使用字母a表示文本中的一个字,试用字母b表示指定对象的一个字;进行位置嵌入后获得:12345678910111213141516171819202122232425;位置中的1-25与“<cls>这家店也就交通非诚方便,人均消费比较高<sep>餐馆环境<sep>”一一对应;字嵌入、段落嵌入和位置嵌入矢量求和:字嵌入、段落嵌入和位置嵌入后分别为25个向量;将字嵌入、段落嵌入和位置嵌入后的各25个向量进行矢量求和获得输入:e1e2e3e4e5e6e7e8e9e10e11e12e13e14e15e16e17e18e19e20e21e22e23e24e25。2)结果输出:该评论在指定对象上的情感分类结果(positiveor未提及ornegative)例如,文本输入为“这家店也就交通非诚方便,人均消费比较高”,指定对象为“餐馆环境”的结果输出:为010,因为该文本中未提及指定对象“餐馆环境”,因此,此文本的结果输出为010(三位分别表示positive、未提及、negative,positive为0,未提及为1,negative为0)。(4)有监督模型训练有监督模型训练是指将加载步骤(3)中的已定义好的输入输出文,对步骤2中的无监督预训练神经网络语言模型进行训练。1)训练集验证集测试集划分;2)freeze预训练语言模型的参数,只训练网络尾端的全连接层;3)unfreeze预训练语言模型的参数,并针对该任务进行微调(fine-tunning);4)保存validationaccuracy最高的模型以及其参数等信息。4、使用训练好的模型,对下游相关任务进行预测使用步骤3中有监督训练后的模型对下游相关任务进行预测,包括:(1)关注点问答;(2)自动化细粒度情感表格生成。应用示例一本实施例对上述实施例方法进行具体描述,以餐馆评论为例,包括以下步骤:1、文本(语料信息)搜集(1)无监督预训练语料的搜集文本语料搜集(餐馆评论、售后评论、产品反馈、微博舆情etc)。(2)有监督语料的搜集与文本构建1)搜集该特定任务的语料信息(餐馆评论);2)针对该任务,设计需要分类的对象信息,例如:(餐馆环境、服务员态度、地理位置、菜品、价格等);3)样例数据:text1:这家餐厅的环境非常优雅,味道也很不错。唯独服务员的态度有些爱答不理。text2:这家店也就交通非常方便,人均消费比较高。4)有监督数据标注,如表3所示,其中,0表示未提及,1表示情感positive,-1表示情感negative;表三表三为根据输入的文本和关注的对象进行标注后的文本。5)文本生成表四indexinputtarget1<cls>text1<sep>餐馆环境<sep>12<cls>text1<sep>服务员<sep>-13<cls>text1<sep>菜品<sep>14<cls>text1<sep>价格<sep>05<cls>text1<sep>地理位置<sep>06<cls>text2<sep>餐馆环境<sep>07<cls>text2<sep>服务员<sep>08<cls>text2<sep>菜品<sep>09<cls>text2<sep>价格<sep>-110<cls>text2<sep>地理位置<sep>1………input为对每条文本进行字嵌入后的结果,target为不同指定对象的评价值。2、无监督预训练神经网络语言模型3、针对该任务的神经网络模型结构改造与有监督训练(1)模型改造后结构(2)输入输出文本结构定义(3)有监督模型训练4、最终可以根据上述训练好的模型,可适用于多种不同的下游相关任务,例如:(1)关注点问答以下文本输入1、文本输入2、文本输入3中的“评论”为训练用的文本,“关注点”为指定对象时输出的评价值。文本输入1评论:这家店员工非常亲切,而且味道很可口,就是略贵,关键是距离单位只有5分钟路程,非常方便。关注点:地理位置输出1:positive(100);文本输入2评论:这家店员工非常亲切,而且味道很可口,就是略贵,关键是距离单位只有5分钟路程,非常方便。关注点:价钱输出2:negative(001);文本输入3评论:这家店员工非常亲切,而且味道很可口,就是略贵,关键是距离单位只有5分钟路程,非常方便。关注点:可容纳人数输出3:未提及(001);(2)自动化细粒度情感表格生成表五实施例三本实施例提供了一种文本识别装置,上述方法实施例中描述也适用于本实施例中,如图3所示,该装置包括:存储器31和处理器32;所述存储器31,用于保存用于性能测试的程序;所述处理器32,用于读取执行所述用于性能测试的程序,执行如下操作:将每个训练用的文本与不同的指定对象的组合各作为一条输入,对于每条输入,将该条输入中的文本对于指定对象的评价值作为标签,对预生成的模型进行训练;使用训练好的模型,识别输入的文本对于指定对象的评价值。一种示例性的实施例中,所述处理器32读取执行所述用于性能测试的程序,还执行如下操作:根据搜集的文本进行无监督的模型训练,在所述无监督的模型的输出层后加上全连接层,作为所述预生成的模型。一种示例性的实施例中,所述根据搜集的文本进行无监督的模型训练,包括:对搜集的文本进行屏蔽词预测和句子连接关系预测,得到所述无监督的模型。一种示例性的实施例中,所述处理器32读取执行所述用于性能测试的程序,还执行如下操作:在所述将每个训练用的文本以及不同的指定对象分别作为输入之前,对所述每个训练用的文本进行如下操作:将该训练用的文本和不同的指定对象分别进行组合,组合时将文本和指定对象用预定字符连接;对于每种组合结果分别进行嵌入,所述嵌入包括字嵌入、段落嵌入和位置嵌入;所述字嵌入是指将输入句子拆分成字级别,并对句子中每一个字都做字嵌入;所述段落嵌入是指使用不同字母标识输入中不同的句子或字段;所述位置嵌入是指为输入中的每一个字符标注具体位置信息;对于每种组合结果,分别根据所述进行嵌入后的训练用的文本和进行嵌入后的指定对象获取一条输入。一种示例性的实施例中,所述处理器32使用训练好的模型,识别输入的文本对于指定对象的评价值,包括:当所述指定对象为一个时,所述评价值为所述指定对象的分类结果;当所述指定对象为两个或以上时,所述评价值为所述指定对象的分类结果的表格;其中,所述分类结果包括积极、未提及和消极。本领域普通技术人员可以理解,上文中所公开方法中的全部或某些步骤、系统、装置中的功能模块/单元可以被实施为软件、固件、硬件及其适当的组合。在硬件实施方式中,在以上描述中提及的功能模块/单元之间的划分不一定对应于物理组件的划分;例如,一个物理组件可以具有多个功能,或者一个功能或步骤可以由若干物理组件合作执行。某些组件或所有组件可以被实施为由处理器,如数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。这样的软件可以分布在计算机可读介质上,计算机可读介质可以包括计算机存储介质(或非暂时性介质)和通信介质(或暂时性介质)。如本领域普通技术人员公知的,术语计算机存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的任何方法或技术中实施的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于ram、rom、eeprom、闪存或其他存储器技术、cd-rom、数字多功能盘(dvd)或其他光盘存储、磁盒、磁带、磁盘存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质。此外,本领域普通技术人员公知的是,通信介质通常包含计算机可读指令、数据结构、程序模块或者诸如载波或其他传输机制之类的调制数据信号中的其他数据,并且可包括任何信息递送介质。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1