词嵌入模型的增量生成的制作方法
本申请要求于2018年2月8日提交的美国临时申请第62/628,177号的优先权和权益,其内容全部并入本文。
本申请涉及自然语言处理,并且更具体地涉及将由第一文本语料库产生的第一向量模型和由第二文本语料库产生的第二向量模型合并为新的向量模型。
背景技术:
诸如c++的编程语言是非常明确且准确的。但是,自然语言既不明确也不精确。例如,单词“get”在一个上下文中可能意指获得,但在另一个上下文中意指理解。为了使机器能够处理自然语言,早期的方法尝试了机器试图应用语法规则的语义方法。但是这种方法基本上是行不通的。例如,使用语法规则的机器翻译在翻译的文本中导致几乎滑稽的错误。但是现代自然语言处理更强大,并且导致翻译可能相当准确,并且几乎不需要人工编辑。
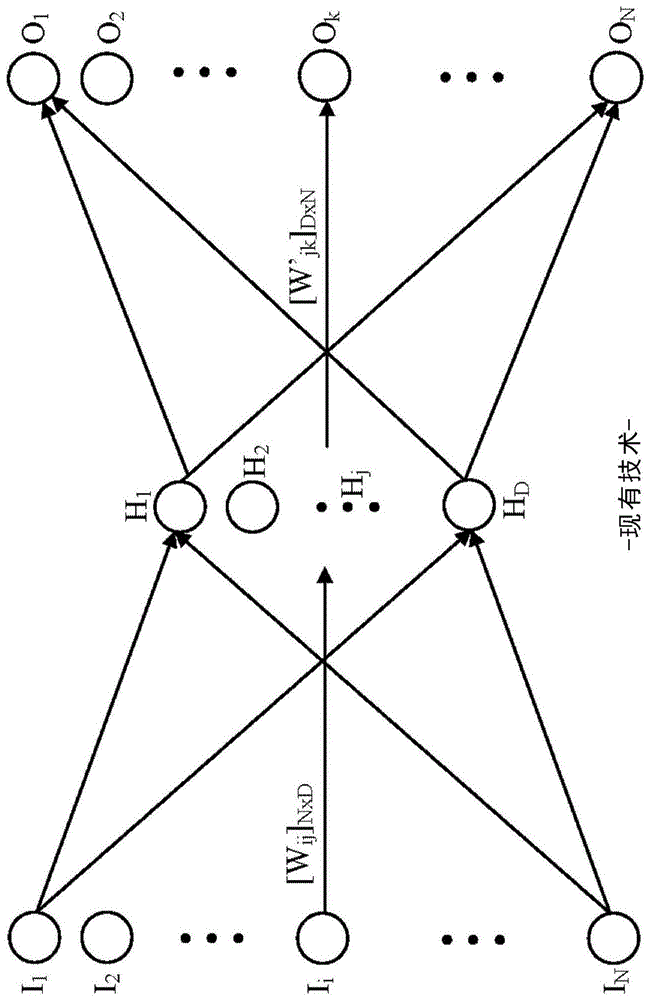
为了获得这样的结果,现代自然语言处理将词或短语表示(嵌入)为向量。由于正在被嵌入的可以是单个词或多个词,因此正在被嵌入的符号可以表示为令牌,其中每个令牌表示至少一个词。例如,假设从文本语料库中正在嵌入n个令牌,n是复数正整数。然后可以将每个令牌分配到n维向量中的维度(独热码(one-hotencoding))。由各种令牌产生的输入向量用于训练神经网络。示例是图1所示的word2vec神经网络100,其由google公司使用具有多个d节点的单隐层所开发的(对于word2vec模型,d约为300)。n个输入节点从第一输入节点i1到第n输入节点in。d个隐藏节点的范围为从第一隐藏节点h1到第d隐藏节点hd。n个输出节点类似于n个输入节点,因此范围为从第一输出节点o1到第n输出节点on。在对语料库进行训练之后,产生的word2vec神经网络系数形成[n×d]矩阵(n行和d列),其被表示为对应语料库的向量模型。n个独热输入向量中的每个映射到形成向量模型的[n×d]矩阵中的d个维向量。感兴趣的不是神经网络本身,而是向量模型中的向量。特别地,具有相似上下文和意义的词将倾向于聚集在由n个d维向量形成的d维空间中。利用这种空间相似性,处理器可以分析文档并以类似人的方式“理解”。例如,处理器可以解析文档的上下文并向用户建议类似的文档,翻译文档,理解用户查询等。
虽然使用词嵌入的自然语言编程(nlp)非常强大,但需要相当大的语料库才能获得准确的结果。例如,word2vec模型是在超过1000亿词的语料库上进行训练的。nlp研究人员无法获得这样相对庞大的第三方语料库。此外,即使语料库被公开,在如此庞大的语料库上训练神经网络也是耗时且昂贵的。此外,语言在不断变化。例如,考虑最近的术语发展,诸如“假新闻(fakenews)”或“寨卡病毒(zikavirus)”。由于产生的语料库的巨大规模,使用无限的新语言流增强原始语料库变得不可行。
因此,本领域需要快速更新或增强用于词嵌入的向量模型的能力。
技术实现要素:
公开了一种方法和系统,其中由原始语料库产生的已有的向量模型可以与来自另一向量模型的向量组合以形成组合的向量模型,而不需要对原始语料库进行任何访问或使用。特别地,提供变换,使得来自已有的模型的向量和来自附加向量模型的向量可以被变换为形成组合向量模型的向量。结果是非常有利的,因为新的语料库可能相对较小,而原始语料库明显较大。将原始语料库与新的语料库组合以形成组合的语料库并在组合的语料库上训练神经网络以产生组合的向量模型将是非常繁琐的。但是,这里公开的变换消除了这种繁琐的训练,并且通过仅将来自已有的向量模型和来自新的向量模型的向量变换为新的向量模型的向量,就能够通过与新的向量模型相对应的新的语料库来增强已有的向量模型。
通过考虑下面的详细描述,可以更好地理解这些有利特征。
附图说明
图1是word2vec神经网络的图示。
图2是根据本公开的方面的计算机化向量变换和合并系统的框图。
图3示出了用于实现图2中所示的模块的示例计算机系统。
具体实施方式
图2中示出了计算机化的向量模型变换和合并系统200。系统200涉及使用诸如由word2vec模型所实践的单隐层神经网络。但是应当理解,本文公开的向量变换技术可以容易地应用于具有多于一个隐藏层的深度神经网络。因此,以下涉及使用word2vec模型的讨论仅是示例性的,使得可以理解可以使用其他词嵌入生成模型。如前所述,word2vec模型是在相对较大的第三方语料库205上进行训练的。这样的第三方语料库205是已有的并且可能非常大。在这种大的语料库上训练神经网络是有利的,但涉及大量的时间和计算资源。此外,nlp研究人员可能无法访问这种第三方语料库。即使被授予访问,在时间和计算成本方面,使用附加的语料库更新这种第三方语料库并且然后在所得到的改进后的语料库上训练相应的神经网络也是令人望而却步的。但是,向量变换系统200不需要对这种大规模的改进语料库进行训练,但是保留了相对较大的第三方语料库205的益处。
已有的第三方语料库205在word2vec向量训练模块210中训练word2vec神经网络以产生已有的预训练向量模型215。在向量模型215中有多个n向量,n是复数正整数。这些n向量对应于从已有的语料库205中选择的n个令牌。每个向量具有维数d,其是word2vec模型中的隐藏节点的数量。产生的向量模型215理想地是公共域。如果不是,则需要获得访问,以便实施本文公开的向量变换。尽管已有的向量模型215受益于大规模的语料库205,但如前所述语言在不断变化。此外,即使时间帧被固定,也没有语料库可以包含所有可用的文本。因此,通过使用新的语料库(或多个新的语料库)220并在新的语料库220上训练新的神经网络训练模块225来产生新的向量模型230,可以改进向量模型215。新的神经网络的输入节点的数量取决于从语料库220嵌入的词(令牌)的数量。在下面的讨论中,该多个输入节点由复数正整数m表示。通常,m将不等于word2vec模型的输入节点的数量n。但是新的神经网络将具有相同数量d的隐藏节点。因此,形成新的向量模型230的m个向量将具有维数d,使得新的向量模型230形成m×d矩阵。
如前所述,预训练向量模型215包括语料库205中被表示在预训练向量模型215中的每个词或短语的向量。例如,词a映射到模型215中的向量a,词b映射到向量b,依此类推。如果有嵌入10,000个词要嵌入,则向量模型215因此包括10,000个相应的向量。向量模型215中的每个向量的维数d取决于相应神经网络中的隐藏节点的数量。在使用word2vec模型的实施例中,向量模型215中的每个向量具有约三百的维数。这种向量空间的每个维度可以通过单位基向量表示。因此,对于word2vec实施例,将有三百个单位基向量跨越向量模型215的向量空间。
新的向量模型230的维数与现有预训练向量模型215的维数相匹配。因此,在word2vec实施例中,新的向量模型230的向量空间也将通过三百个单位基向量来表示。但是申请人发现了关于定义新的向量模型230的单位基向量与预训练(和已有的)向量模型215的单位基向量相对的新奇特征。具体地,申请人发现了新的向量模型230的单位基向量实际上总是与已有的向量模型215的单位基向量正交。虽然申请人没有提供这种正交性的数学证明,但是这在重复测试中被观察到并且因此启发式地被证明是真实的。这种显著结果被认为是由于word2vec的对称神经网络结构及其随机梯度下降(sgd)训练过程的结果,该过程通常根据伪随机播种在局部最小点终止。不管是什么原因导致的,所得到的正交性在向量变换和合并模块235中被利用以创建合并的向量模型240(其还可以被表示为组合向量模型,因为它产生自新的语料库220和第三方语料库205的有效组合)。换言之,合并的向量模型240等同于在由第三方语料库205和新的语料库220的组合产生的组合语料库上训练相应神经网络的结果。但是,考虑到这种组合的语料库的相对大小,这种训练在时间和计算能力方面存在问题。此外,即使给定足够的时间和计算资源,对于给定的nlp研究人员来说,这也是不可能完成的任务,因为第三方语料库205通常不可用于公共访问。向量变换和合并模块235通过对来自向量模型215和230的向量进行变换以使得它们能够被组合以形成合并的向量模型240来解决这些问题。
现在将更详细地讨论这种有利的向量变换和合并。如前所述,在已有的向量模型215中有n个向量,因为从语料库205中选择n个对应的令牌用于神经网络训练210。因此,word2vec模型的神经网络将具有n个输入节点。另外,该神经网络具有多个d隐藏节点,因此向量模型215中的每个向量具有d维。因此,向量模型215的向量空间可通过从第一单位基向量到第d单位基向量的多个d单位基向量来表示。
新的语料库220具有m个向量。通常,由于与新的语料库220相比语料库205较大,m将小于n。关于m个向量,它们中的p个向量指向与从语料库205嵌入到已有的模型中的词相同的词。因此,已有的模型215中的向量可以被细分为涉及与新的模型230共享的词的p个向量和涉及不与新的模型230共享的词的(n-p)个向量。类似地,新的模型230中的向量可以被划分为针对与已有的模型215共享的词的p个向量和针对不与已有的模型215共享的词的(m-p)个向量。因此,已有的向量模型215中的向量可被表示为:
类似地,新的向量模型230中的向量可被表示为:
两个模型的向量空间由多个d单位基向量定义。特别地,已有的模型215的向量空间可被表示为:
而新的模型230的向量空间可被表示为:
考虑到基向量从一个向量模型到下一个向量模型的正交性,对于相同的词,在模型215和230中的p个向量彼此正交,这能够通过点积来表示:
现在将描述在向量变换和合并模块235中应用的变换。关于该变换,存在将新的向量模型230的单位基向量旋转到已有的模型215的单位基向量中的矩阵t,使得:
考虑到基向量在两个模型之间正交性,矩阵[t]具有以下属性:
该属性与以下约束组合:
得到一组通过最小二乘法容易求解的方程,以确定[t]的矩阵元素。替代地,可以从两个模型的p个公共词集中选择d个词,并使用等式(2)以形成维度d2的线性系统,该系统被求解以获得其列通过等式(1)被正交化的矩阵以获得矩阵[t]的系数。
无论如何推导矩阵[t],该变换矩阵然后可用于将两个模型合并成组合或合并的模型240,其可被表示为:
其中
因子r是由已有的语料库205的语料库大小(令牌的数量)与新的语料库220的令牌数量的比率来定义的。注意,如果对于语料库205生成已有的模型215,令牌大小是未知的,则在认为已有的模型215中的公共词(p个共享词)准确率较高的情况下,因子r可以被选择为大数(例如,500)。替代地,如果语料库大小能够进行比较,则可以减少对r的估计。
等式(4)具有直观的意义,因为p个被共享词应各自映射到具有来自已有的模型215和新的模型230的贡献的向量。等式(5)也是直观的,因为由已有的模型215嵌入的未被新的模型230共享的词应没有来自新模型230的贡献。最后,等式(6)也是直观的,因为它解决了由新模型230嵌入的未被已有的模型215共享的词,使得没有来自已有的模型215的向量贡献。
作为示例,使用选自因子r等于500的健康新闻的新的语料库测试系统200。将期望预训练的向量模型与组合模型之间的常用词应映射到类似的向量。因此,测试新模型的准确性的一种方法是针对各种共享词确定已有的向量和组合向量的余弦相似性。为完整性起见,也将仅在已有的模型中的词的向量之间的余弦相似性与组合模型中的相应向量进行比较,尽管从等式(5)可知,在这种已有的向量和组合向量之间应不存在差异。最后,还针对不与旧模型共享的词测试了新的模型中的向量与组合模型中的相应向量之间的余弦相似性,如通过等式(6)所示的那样。产生的余弦相似性的方差如下:
如同所预计的,仅在word2vec模型中发现的词对没有差异。类似地,共享词对的差异也很小,这也如期望的。对于仅在新的模型(在该示例中为健康模型)中发现的词对,余弦相似性方差较大,其由变换矩阵[t]不是严格地正交引起的。
为了示出组合模型中的期望超过原始的word2vec模型的“健康理解”改进,示例将是“医学的”和“健康”之间的余弦相似性。在原始的word2vec模型中,这些词的余弦相似性是0.54。但是组合模型的这种相似性增加到0.67。最后,考虑“寨卡”和“血液”之间的相似性。word2vec模型的语料库不包括寨卡,因此在这种情况下,寨卡和血液之间不存在余弦相似性。对于组合的模型,鉴于血液和寨卡病毒之间的强关联,这种相似性变为0.74。
现在将讨论图3中所示的用于实现模块225和235的计算机系统300。应当理解,这些模块可以使用一个或多个计算机来实现,或者可以使用配置的fpga或asic来实例化。管理员可以使用显示器311、键盘304、和音频/视频i/o305来配置系统300。系统300包括通过总线302耦合到指令的存储器314的至少一个处理器。总线302还通过网络接口306和通信链路318耦合到诸如因特网350之类的网络。以这种方式,系统300可以从网络350容易地接收语料库120。存储在存储器314中由处理器312执行以实现本文所讨论的各种模块的指令可以用java或其他合适的编程语言编写。
前面的描述是示例性的,使得本领域普通技术人员将理解,在不背离本公开的范围的情况下,可以在本公开的材料、装置、配置和设备的使用方法进行各种修改、替换和变化。鉴于此,本公开的范围不应限于本文所示和所描述的具体实施例的范围,因为它们仅仅是通过其中的一些示例,而应与所附权利要求及其功能等同的范围完全相称。
- 还没有人留言评论。精彩留言会获得点赞!