一种离线表关联方法与流程
本发明涉及数据处理领域,尤其涉及一种基于spark的elasticsearch离线表关联方法。
背景技术:
实时关联elasticsearch的有已经开源的elasticsearch1_sql进行表关联,其内部是把第一张表的数据放在内存中,然后把第一张表的数据拿到第二张表进行逻辑的关联;离线的elasticsearch表关联主要是通过spark的rdd之间进行join关联。现有技术存在以下缺陷:
1.elasticsearch_sql应用的表关联,由于第一张表数据是放在内存中的,所以对表的数量有10w的限制,故查出来的数据不全,只能针对小表进行关联,且由于其策略是拿第一张表数据去第二张查,所以目前仅支持两张表进行关联,不支持多张;
2.目前离线elasticsearch表关联是通过spark的rdd之间进行join关联的,由于其不同逻辑要写不同的代码进行实现,且很多时候整个程序的dag流程图过于复杂,而且有些不必要的操作,从而影响程序的运行速度。
技术实现要素:
本发明针对现有技术的不足,提出一种基于spark的elasticsearch离线表关联方法,本发明能够实现elasticsearch多张表之间的关联;优化了spark执行任务的流程,减少了一些不必要的操作;通过页面设置参数,生成对应的sql,从而执行表关联;每次运行spark任务不需要进行打包处理,对任务具有管理和调度功能。
本发明的目的通过以下技术方案实现:一种离线表关联方法,该方法包括以下步骤:
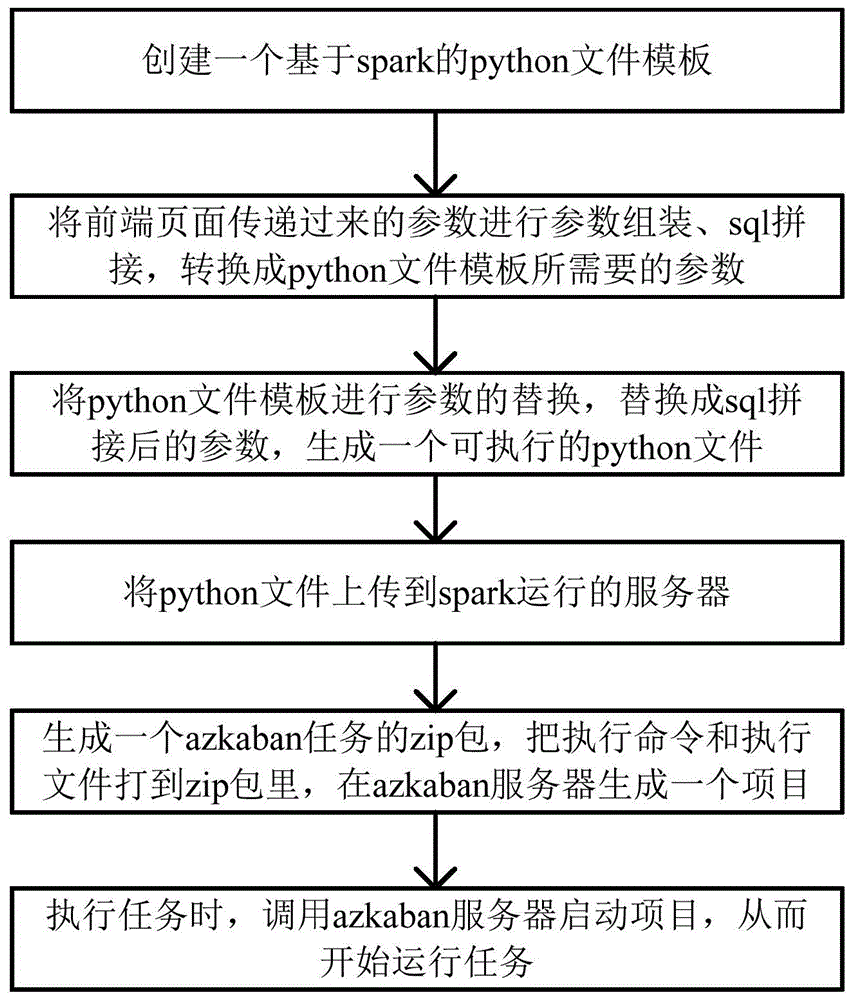
(1)创建一个基于spark的python文件模板,具体包括以下子步骤:
(1.1)创建一个spark实例,将该spark实例连接到elasticsearch,从而获得一个rdd。
(1.2)将rdd转成spark的dateframe注入到内存中,并将dateframe声明成一张临时表。
(1.3)把所有待关联的表均进行(1.1)、(1.2)两个步骤的操作,生成多张临时表;
(1.4)在页面配置待关联的表、查询条件及字段,利用java转换成sql语句,并通过sparksql进行多表之间的关联,得到一张结果表。
(1.5)将结果表回存到elasticsearch中,完成python文件模板的创建。
(2)将前端页面传递过来的参数进行参数组装、sql拼接,转换成python文件模板所需要的参数。
(3)将python文件模板进行参数的替换,替换成步骤(2)sql拼接后的参数,生成一个可执行的python文件。
(4)将python文件上传到spark运行的服务器。
(5)根据python文件生成一个azkaban任务的zip包,把执行命令和执行文件(python文件)打到zip包里,并在azkaban服务器生成一个项目。
(6)执行任务时,调用azkaban服务器启动项目,从而开始运行任务。
进一步地,所述步骤(1.1)中,可以对该rdd进行数据初步处理后再进行后续操作,数据初步处理包括:将id加入到rdd中、nested平铺。
进一步地,所述步骤(1.4)中,该结果表可进一步进行多次关联。
进一步地,所述步骤(6)中,任务结束后,进行邮件的发送,告知页面操作者执行情况,包括表关联是否成功,有无异常等。
本发明的有益效果是:本发明通过模板进行通用化的代码抽象化抽取,可以解决各种关联数据,数据间关联用sql就可以解决,sparksql也可以自己优化dag流程图,且支持多表间的关联,并且操作人员不需要sql知识,只需要知道哪张表,什么条件,通过页面组件配置生成对应的sql语句。为避免java每次执行时要编译,故采用一个python文件模板,应用java生成的python代码进行任务运行。在离线关联中把提供给用户的服务、运行任务服务和管理任务的服务完全分离,减少彼此之间的影响。
附图说明
图1为本发明离线表关联方法流程图;
图2为python文件模板创建流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1所示,本发明提出的一种离线表关联方法,该方法包括以下步骤:
(1)创建一个基于spark的python文件模板,如图2所示,具体包括以下子步骤:
(1.1)创建一个spark实例,将该spark实例连接到elasticsearch,从而获得一个rdd;可以对该rdd进行数据初步处理后再进行后续操作,数据初步处理包括:将id加入到rdd中、nested平铺(如果需要nested平铺,则将该rdd进行数据拆分)等;
(1.2)把步骤(1.1)处理好的rdd转成spark的dateframe并注入到内存中,并将dateframe声明成一张临时表,以供后续使用;
(1.3)把所有待关联的表均进行(1.1)、(1.2)两个步骤的操作,生成多张临时表;
(1.4)在页面配置待关联的表、查询条件及字段,利用java转换成sql语句,并通过sparksql进行多表之间的关联,得到一张结果表(该结果表可进一步进行多次关联);
(1.5)将结果表回存到elasticsearch中,完成python文件模板的创建。
(2)将前端页面传递过来的参数进行参数组装、sql拼接,转换成python文件模板所需要的参数。
(3)将python文件模板进行参数的替换,替换成步骤(2)sql拼接后的参数,生成一个可执行的python文件。
(4)将python文件上传到spark运行的服务器。
(5)根据python文件生成一个azkaban任务的zip包,把执行命令和执行文件(python文件)打到zip包里,并在azkaban服务器生成一个项目。
(6)执行任务时,调用azkaban服务器启动项目,从而开始运行任务;
(7)任务结束后,进行邮件的发送,告知页面操作者执行情况(表关联是否成功,有无异常等)。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
技术特征:
技术总结
本发明公开了一种离线表关联方法,步骤包括:创建一个基于spark的python文件模板;将前端页面传递过来的参数进行参数组装、sql拼接,转换成python文件模板所需要的参数;将python文件模板进行参数的替换,替换成sql拼接后的参数,生成一个可执行的python文件;将python文件上传到spark运行的服务器;根据python文件生成一个azkaban任务的zip包,把执行命令和执行文件打到zip包里,并在azkaban服务器生成一个项目;调用azkaban服务器启动项目,从而开始运行任务。本发明能够实现elasticsearch多张表之间的关联;优化了spark执行任务的流程,减少了一些不必要的操作;每次运行spark任务不需要进行打包处理,对任务具有管理和调度功能。
技术研发人员:金霞
受保护的技术使用者:杭州费尔斯通科技有限公司
技术研发日:2019.02.02
技术公布日:2019.06.07
- 还没有人留言评论。精彩留言会获得点赞!