一种实现合同条款位置自动识别实现的方法与流程
本发明涉及计算机
技术领域:
,特别涉及一种实现合同条款位置自动识别实现的方法。
背景技术:
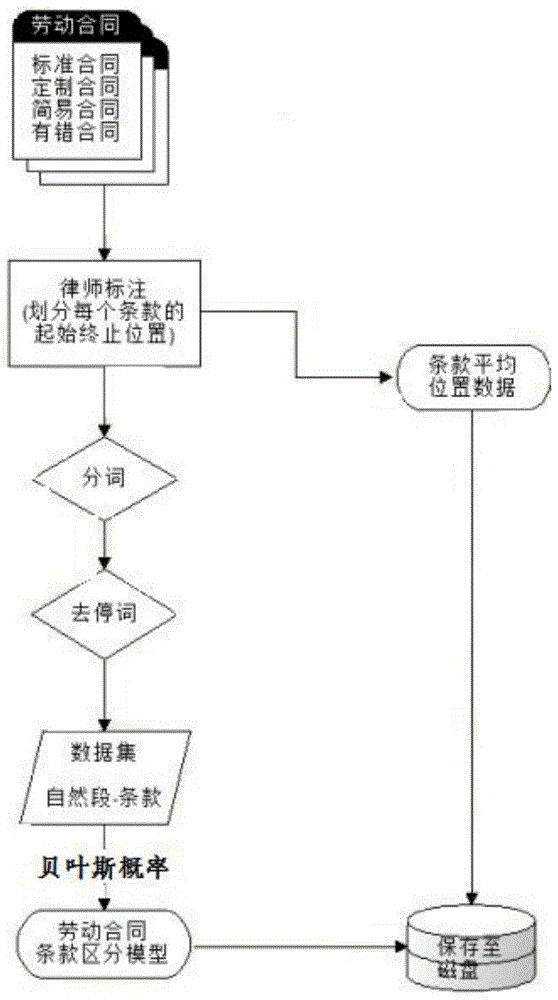
:随着人工智能的不断发展,机器学习、ai不断向各个领域进行渗透。在法律界,合同审批是一个很费时而又枯燥的工作,很多种类的合同像劳动合同、买卖合同都有固定的格式,也有固定的审批规则,这种合同就存在被机器学习的方法进行审批的可能。业内目前在这方面有一些探索,很多都是基于字符串匹配的方式进行审批,但是效果并不是很好,律师们试用后发现效果不好都不再使用,我们分析和调查后发现一个重要原因,字符串匹配的规则不能跨条款使用,很多字符串模式会出现在不同的条款中,但进行审批的标准不同,使用同样的审批规则会导致最后的审批结果出现紊乱。一份标准的合同文件会包含多个组成部分,比如劳动合同里面就有劳动报酬、工作时间、合同期限等多个条款,通常这些条款会包含一个或多个段落,不同条款之间往往是独立的。有经验的法务、律师、合同专家凭经验能轻易区分出每个条款的位置。人工智能算法落地到具体项目时,会发现人凭主观意识能做好的事情计算机常常会碰到问题。在ai和法律结合时,也出现了这个问题,有一些法律条款的内容存在相似之处,而且有一些段落包含的内容信息很少,只有几个字,很容易出现误判,传统计算相似度的方法在这种情况下极容易出现误判,而且上下条款的耦合关系,也会导致一错都错,导致条款区分准确率的下滑。显然要实现智能合同审批或其他与合同+ai相关的项目,准确的定位这些条款在文档中对应内容的位置会提高处理的准确性。现有的一些技术采用标题检索的方式来确定条款的开始和结束位置。由于合同通常是保存在word中,而且格式中有各级标题,给这种标题检索的技术留了发展的空间,但是这种技术对环境的要求比较高,首先必须是word文档,其次作者必须要使用非常规范的word层级标题,最后每个标题的内容要在统一预定的文本范围内。一旦一环出了问题,那么就会影响到前后其他条款的起始终止位置。或者使用多份标准合同和待检测合同每个段落计算相似度,以获取每个段落最近似的条款,这种方法与本文所描述的类似,区别在于一个是先验概率,一个是后验概率。一个段落可能和很多条款的先验概率都高,但后验概率都很低,使用先验概率设置阈值需要对每个条款单独设置,工作量巨大,维护成本很高。如果使用简单平均转化成后验概率,即假设各个条款出现的概率相同,但这种假设也是有问题的,在很多简化合同里面,有一些条款不会出现,更为严重的是,在一些有问题的合同里面,计算先验概率的逻辑都不合预期,后面无法检测到错误。还有一种是使用先验概率和动态时间规整算法的定位方法,这种方法也是先制定多份标准合同,每份标准合同含有的条款不同,或者条款顺不同。拿到测试合同后,依次使用每个模板计算每个段落和条款的相似度,使用dtw算法(即动态时间规整)可以跳过某些条款或段落,也可以用替换的方法来查找错误的段落,最后计算出每个模板的得分,使用得分最高的模板和它对应的计算结果来生成每个条款的内容。这种方法需要大量的模板,运算量也很大,在实际使用时体验不好。技术实现要素:为了克服现有技术的上述缺陷,本发明提供一种实现合同条款位置自动识别实现的方法,该方法自动给合同涉及到的各个条款找到起始、结束位置,便于后续对各个条款的文本进行各种处理。本发明所采用的技术方案为:一种实现合同条款位置自动识别实现的方法,该方法包括以下步骤:a.收集若干某一类型合同,在这些某一类型合同中标注出每个条款的起始结束位置;b.针对每个条款的每份数据进行分词、去停词处理,得到一个词袋模型,并记录下该词袋模型对应的条款序号,使用机器学习方法用词袋模型和条款序号的组合数据进行训练,得到某一类型合同中每个条款的区分模型,并保存在二进制文件中完成训练过程;c.根据保存在二进制文件中对应类型合同的区分模型,确认新合同的合同类型,并加载该区分模型对新合同进行条款定位;d.所述条款定位方法包括把新合同的每一个自然段使用区分模型计算属于每个条款的概率,并对这些概率做归一化处理,得到新合同的概率矩阵,对每个条款,对应概率矩阵中每一列,使用其对应列的数据进行定位起始结束位置。作为本发明的优选方案,所述使用区分模型计算属于每个条款的概率方法包括:采用贝叶斯概率的方法,如果新合同有n个自然段,m个条款,可以得到一个n*m的概率矩阵,该矩阵每行之和为1;接着对概率矩阵每列数据数据加做一个窗口为3的加权平均处理,权重分别为[x,1-2*x,x],即该数据本身上下两行的权重为x,其本身为1-2*x,得到一个平滑过得概率矩阵。作为本发明的优选方案,所述某一类型合同可以是留白合同、标准合同、定制合同、简易合同或者是一些包含少量错误的合同。作为本发明的优选方案,所述机器学习方法包括分类、回归方法,或者多模型融合方法等。作为本发明的优选方案,所述训练过程可以只使用某一类型合同中常用词对词袋模型做一次过滤,让词袋模型中只保留某一类型合同中常用词,也可以使用单字模式而不做分词处理,然后得到每个条款在若干某一类型合同中的位置,取平均值即可得到平均开始位置和平均结束位置。作为本发明的优选方案,所述确认新合同的方法通过文件名和合同标题。作为本发明的优选方案,所述x的取值小于0.2。与现有技术相比,本发明具有以下技术效果:本发明,通过使用事先标准好条款起始结束位置的大量样本合同,通过机器学习的方式建立这类合同下各条款的区分模型,在一个合同文本中,自动给涉及到的各个条款找到起始、结束位置,由于每个条款是单独计算其起始和结束为止的,解除了上下条款间的耦合,提高了系统的健壮性,而且这个方法不依赖于word文档和标题的层级结构,使用机器学习的方法建立模型,更加贴近实际使用场景,还有就是在训练是可以包含错误合同,使用贝叶斯概率也能克服这里先验转后验的问题,并通过算法里面的多个技巧,如平滑、区间预估、上下扩展、位置辅助信息多种措施确保给每个条款区分出正确的段落,因此性能更为准确和鲁棒。附图说明图1是本发明实施例中训练对应条款区分模块的流程示意图;图2是本发明实施例中得到初步的起始终止段落流程示意图;图3是图2中增加平均位置信息辅助流程的流程示意图;图4是本发明实施例中得到开始位置的流程示意图;图5是本发明实施例中得到结束位置的流程示意图。具体实施方式下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。1)该方法是基于机器学习而来,因此它存在一个训练的过程,在这个过程中,我们会把某一类型的合同收集上千份作为训练数据集,这些合同可以是留白合同,标准合同,定制合同,简易合同,甚至可以有一些包含少量错误的合同,让合同专家或者律师根据经验总结出此类合同能区分出的条款,在这些训练数据的每份合同中标注出每个条款的起始结束位置,每个条款也就得到上千份的训练数据;2)针对每个条款的每份训练数据,进行分词、去停词处理,可以得到一个词袋(bagofword),并记录下该词袋对应的条款序号,用(词袋,条款序号)的组合数据进行训练,可以使用分类、回归甚至多模型融合等各种机器学习的方法得到此类合同下各条款的区分模型。此过程可以考虑使用只使用合同常用词对词袋做一次过滤,让词袋中只保留合同常用词,避免无关词对模型形成干扰,也可以使用单字模式而不做分词以加快计算速度,同时也可以得到该条款在每份合同中的位置,取平均即可得到平均开始位置和平均结束位置;3)对每一类合同重复以上过程,可以得到每类合同的条款区分模型,并在二进制文件中保存,以便后面调用的时候节省时间,此时完成了训练的过程;4)拿到一份新的合同后,使用上述区分模型对此合同进行条款定位,首先确定合同的类型,一般通过文件名、合同标题可以确定合同的类型,从保存的二进制文件中加载该类合同对应的区分模型;5)把新合同的每一个自然段使用区分模型计算属于每个条款的概率,并对这些概率做归一化处理,使用区分模型计算属于每个条款的概率方法是采用贝叶斯概率的方法,如果新合同有n个自然段,m个条款,可以得到一个n*m的概率矩阵,该矩阵每行之和为1;接着对概率矩阵每列数据数据加做一个窗口为3的加权平均处理,权重分别为[x,1-2*x,x],即该数据本身上下两行的权重为x,其本身为1-2*x,得到一个平滑过得概率矩阵;6)对概率矩阵每列数据做加一个窗口为3的加权平均处理(均滑),权重分别为[x,1-2*x,x],即该数据本身上下两行的权重为x,其本身为1-2*x,得到一个平滑过得概率矩阵,建议x小于0.2;7)对每个条款,对应概率矩阵中每一列,使用其对应列的数据进行定位起始结束位置;a)取该列中最大的概率值,并记录次概率值对应的段落序号,记为m,b)取第该列中第二大的概率值,其对应的段落序号为i,如果i和m的距离大于0.1*n,则保留i为该条款的疑似起始结束,跳转到d,c)如果第二大的概率值不满足b中的条件,则依次再查找第三大、第四大的概率值,看是否满足条件,一旦满足条件,则在这几个查询过的概率值中,寻找对应段落序号最小和最大的序号,记为s和e,d)如果c中依次查询了前几个(一般前四个)概率值都不满足b中的条件,则s和e都设为m,e)从序号s-1开始,依次递减查找段落,寻找条款真正的开始段落,i.一旦连续两个段落为空行,则认定条款从此空白段落开始,ii.一旦该段落属于此条款的概率低于某阈值,并且字数大于某阈值,则认为条款从此段落的下一段落开始,即如果k段落属于此条款的概率极低,则此条款从k+1段落开始,f)从序号e+1开始,依次递增查找段落,寻找条款真正的结束段落,i.一旦连续两个段落为空行,则认定条款从此空白段落开始,ii.一旦该段落属于此条款的概率低于某阈值,并且字数大于某阈值,则认为条款从此段落的上一段落开始,即如果k段落属于此条款的概率极低,则此条款从k-1段落开始;8)对每个条款都执行第7步中的过程。会发现条款的内容可能会有一些重叠,在此方法中这种情况是允许的,尤其是在训练数据不是非常充足的时候会出现,而且有一些条款本身存在一定的相似性,我们的方法的目标是把属于该条款的内容都框选出来,并且尽可能减少冗余数据,也是系统鲁棒性的体现;9)由于一些条款的内容存在相似性(比如合同主体和合同签名),很容易定位出现错误,针对这些易混肴条款,可以在第7步的计算中使用平均位置信息,比如合同主体通常出现在合同的0%~20%中(在第2步中算出),则在计算合同主体的起始结束位置时只使用这一区间的段落即可,通常会在前后加上容错空间,0%*0.8~20%*1.2,这些易混淆条款可以由合同专家提前给出列表;下面以劳动合同为例说明此过程,参照说明书附图:如图1所示:首先是训练其对应的条款区分模型,律师标注划分每个条款的起始终止位置,然后通过第1和第2的步骤得到条款的区分模型,并保存至二进制的磁盘中;如表一所示:区分模型训练好之后,以后用的时候就可以直接从文件中加载,省去重复训练的过程,加载后得到一个n*m的矩阵,如第4步和第5步所述,得到n个自然段,m个条款;接下来就可以对每个条款逐个定位,无耦合的方案,以一个条款的定位为例,只使用矩阵中对应的那一列数据,得到初步的起始终止段落流程,如图2所示;如果该条款需要平均位置信息辅助时,则需要在图2中的取下一个最大概率对应的段索引和概率在前四大中增加一个索引是否在该条款平均位置附近判别流程,如图3所示;得到初步起始终止位置之后,需要进一步扩展到边界,开始位置的边界流程如图4所示,同理可以得到结束位置的边界流程如图5所示;最后对每个条款都按此流程处理,可以得到所有条款的位置。条款1条款2条款3。。。条款m自然段10.010.140.45。。。0.02自然段20.000.340.23。。。0.10自然段30.010.170.01。。。0.01自然段40.000.000.00。。。0.02。。。。。。。。。。。。。。。。。。自然段n-10.150.010.10。。。0.03自然段n0.000.030.04。。。0.01表一概率矩阵最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1