一种智能变电站SCD文件并行解析方法与流程
本发明属于电力智能变电站领域,涉及一种智能变电站scd文件并行解析方法。
背景技术:
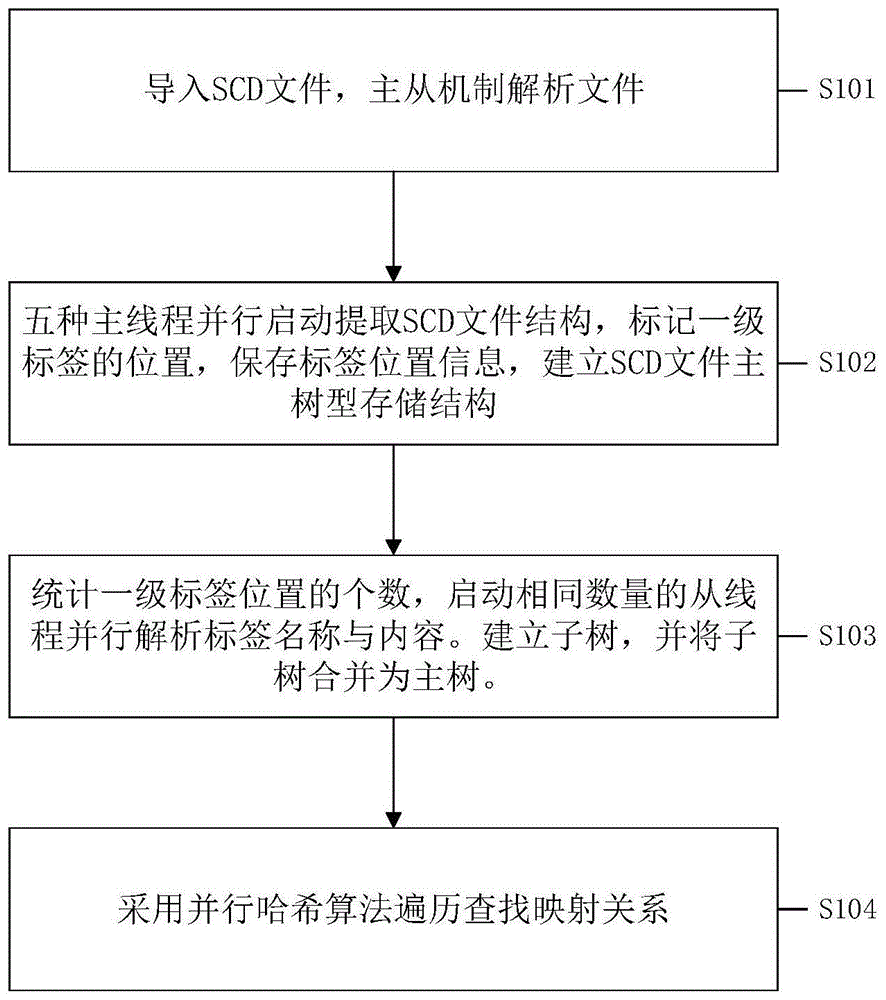
:scd(substationconfigurationdescription)文件,全称为变电站配置文件。scd文件是通过scl语言描述的智能变电站配置文件,将智能变电站一次智能化设备和二次网设备的关系,设备功能和通信服务相关数据模型及控制模型进行了完整的描述。因此,scd文件是智能变电站建设和维护过程中最重要的文件,是智能变电站文本化的设计图纸。由于智能变电站的建设维护,从而常需对scd文件进行查看和修改等操作。scd文件的解析是一个占用系统资源大、消耗时间长的过程。这给现场调试工作带来了巨大挑战,导致耗费了大量的时间和人力。技术实现要素:有鉴于此,本发明的目的在于提供一种智能变电站scd文件并行解析方法,以解决现行解析方法运行时间长,结果查询效率低的问题。为达到上述目的,本发明提供如下技术方案:一种智能变电站scd文件并行解析方法,包括以下步骤:s1:将scd文件导入,采用主从机制,主线程提取scd文件的结构,从线程解析标签的名称与性质;s2:对应scd文件的结构并行启动header、substation、communication、多个ied和datatypetemplates五种类型的主线程提取scd文件结构,标记五种一级标签在scd文件中的位置;建立标签位置信息;依照一级标签的位置信息,建立scd文件主树存储结构;s3:统计一级标签位置信息的个数,并行启动等数量的从线程,从线程从标签起始位置开始解析标签及其包含标签的名称和性质,到标签结束位置结束解析,最后将标签属性加入解析结果中;接着,建立五种类型的子树分别对应scd文件的五种一级标签header、substation、communication、多个ied和datatypetemplates;依照解析结果中加入的标签属性,建立对应属性类型的子树,最后依照步骤s2建立的scd文件主树存储结构,将建立的多棵子树加入到主树结构中;s4:建立子树的过程中,采用并行的哈希算法,建立标签名称与解析结果的映射关系,同时避免子树合并过程中哈希冲突的问题。进一步,步骤s1中,主线程与从线程间是串行关系;主线程与主线线程、从线程与从线程间是并行关系。进一步,步骤s2中,所述标签位置信息包括标签起始位置、标签结束位置和标签属性。进一步,步骤s4中,所述并行的哈希算法采用一致性哈希算法的原理,将哈希函数的值域按照一级标签的个数进行等分,接着将等分后的哈希值范围分配给每个一级标签;既可以并行的在从树建立的过程中完成哈希计算,又可以在整合时发生避免哈希冲突的发生。本发明的有益效果在于:本发明公开了一种智能变电站scd文件并行解析方法,采用主从解析机制,主线程提取scd文件的结构,从线程解析标签的名称与性质。解析过程采用并行哈希算法实现树结构的快速查询。本发明采用并行技术启动设备的多个线程快速完成scd文件的解析,充分利用了设备资源。同时,无需多次解析,将解析结果应并行哈希算法技术存储,提供解析结果查寻接口,这给现场调试工作带来了巨大的便利,减少了大量的时间和人力。附图说明为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:图1为本发明的智能变电站scd文件并行解析方法的流程图;图2为scd文件的结构图。具体实施方式下面将结合附图,对本发明的优选实施例进行详细的描述。图1是本发明的智能变电站scd文件并行解析方法的流程图,如图1所示,包括步骤:步骤s101:将scd文件导入内存中,采用主从机制,主线程提取scd文件的结构,从线程解析标签的名称与性质。主线程与从线程间是串行关系;主线程与主线线程、从线程与从线程间是并行关系。步骤s102:图2是scd文件的结构图,图中省略号为scd文件二级标签下所包含的标签。对应scd文件的结构并行启动header、substation、communication、ied(多个)和datatypetemplates五种类型的主线程提取scd文件结构。标记五种一级标签在scd文件中的位置。建立标签位置信息,包括标签起始位置、标签结束位置和标签属性。依照一级标签的位置信息,建立scd文件主树存储结构。如表1所示表1标签名称标签起始位置标签结束位置标签属性headerstrpos1endpos1headersubstationstrpos2endpos2substationcommunicationstrpos3endpos3communicationied_1strpos4endpos4ied……………………ied_nstrpos(n+3)endpos(n+3)ieddatatypetemplatesstrpos(n+4)endpos(n+4)datatypetemplates步骤s103:统计一级标签位置信息的个数,并行启动等数量的从线程,从线程从标签起始位置开始解析标签及其包含标签的名称和性质,到标签结束位置结束解析,最后将标签属性加入解析结果中。scd文件标签起始标志只有一种形式:<标签名;结束标志有两种形式为:/>或</标签名>,比如:<hitemrevision="3251f87c"version="1.00"what=""when="2013-06-19t11:28:16"who=""why=""/>,其中<hitem为hitem标签的起始标志,/>为hitem标签的结束标志,中间的字段revision="3251f87c"version="1.00"what=""when="2013-06-19t11:28:16"who=""why=""为hitem标签的性质。再比如:省略号为subnetwork相关信息,其中<communication为communication标签的起始标志,</communication>为communication标签的结束标志,中间的字段有communication标签包含subnetwork、connectedap等标签的名称和性质。接着,建立五种类型的子树分别对应header、substation、communication、ied(多个)和datatypetemplates。依照解析结果中加入的标签属性,建立对应属性类型的子树,最后依照步骤2建立的scd文件主树存储结构,将建立的多棵子树加入到主树结构中。步骤s104:建立子树的过程中,采用并行的哈希算法,不仅建立了标签名称与解析结果的映射关系,同时避免了子树合并过程中哈希冲突的问题。并行哈希算法采用一致性哈希算法的原理,将哈希函数的值域按照一级标签的个数进行等分,接着将等分后的哈希值范围分配给每个一级标签。既可以并行的在从树建立的过程中完成哈希计算,又可以在整合时发生避免哈希冲突的发生。最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1