提高众包标注数据质量的可视分析系统及方法与流程
本发明涉及众包标注数据的可视分析技术领域,特别涉及一种提高众包标注数据质量的可视分析系统及方法。
背景技术:
训练数据质量是有监督学习和半监督学习的一个关键因素。然而,标注一个大型数据集的代价非常高,并且对标注者标注能力的要求严苛。
因此,研究人员使用众包方法,即将标注任务划分成若干子任务分发给大众完成,得到大量标注数据。尽管这个方法时间效率高,但是在子任务复杂并且需要专业知识来完成的情况下,所得数据往往充满噪声,质量较低,从而需要提供额外确认信息来帮助提高数据质量。相应的,已有一些初步工作将专家对类标的确认信息引入众包学习算法中。尽管这些方法能够提高众包标注数据质量,但其使用已知类标作为专家确认信息,没有考虑到获取已知类标所需代价。在实践中,数据科学家往往需要花费大量精力和时间来分析类标和标注者的表现,以筛选需要确认的实例和标注者,从而最大化准确率增益。
技术实现要素:
本发明旨在至少在一定程度上解决以上技术问题之一。
为此,本发明的一个目的在于提出一种提高众包标注数据质量的可视分析系统。该系统从不同类别之间的混淆程度、实例的不确定类标、标注者的不可靠程度等方面展示了众包数据以及众包学习模型的结果,帮助用户筛选并确认信息量最大的实例和最不可靠的标注者。
本发明的另一个目的在于提出一种提高众包标注数据质量的可视分析方法。
为达到上述目的,本发明一方面提出了提高众包标注数据质量的可视分析系统,包括:混淆矩阵可视化模块,展示不同类别之间的混淆程度,以根据所述混淆程度选择分析的易混淆类别;实例可视化模块,通过有约束的t-sne降维展示每个实例的不确定类标和实例之间的相互影响信息;标注者行为可视化模块,通过散点图展示每个标注者在所选定类别上的标注准确率与无效标注程度评分,以确定无效标注者;交互递进式确认模块,将用户对实例的类标和标注者可靠度的确认信息进行传播,以推荐另外需要标注的实例和标注者。
本发明实施例的提高众包标注数据质量的可视分析系统,基于用户的确认信息,选择更多需要被确认的实例和标注者;用户对类标和标注者的确认信息的影响通过众包学习模型传播到其他相关的实例和标注者上;通过交互递进式确认方式,可以减少用户寻找需要确认的实例和标注者的时间和精力,并提高众包标注数据质量,同时系统已通过“浏览器-服务器”的形式实现,用户可以便捷地使用该系统。
另外,本发明上述实施例的提高众包标注数据质量的可视分析系统还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述混淆矩阵可视化模块包括:标注者混淆矩阵计算组件,用于获取标注者混淆矩阵,以展示标注者的标注和众包学习模型推测的标注之间的不匹配程度;矩阵重排组件,用于重排所述混淆矩阵,以得到易混淆类别形成的块模式。
进一步地,在本发明的一个实施例中,所述实例可视化模块包括:有约束的t-sne组件,用于获取实例二维布局的坐标,以展示所述每个实例的不确定类标;实例影响流组件,用于展示所述实例之间的相互影响信息。
进一步地,在本发明的一个实施例中,所述标注者行为可视化模块包括:无效标注程度评分计算组件,用于获取标注者无效标注程度的评分;标注者类别刻画组件,用于刻画不同类别的标注者。
进一步地,在本发明的一个实施例中,所述交互递进式确认模块包括:互增强图模型组件,用于在给定用户当前对实例的标注和标注者可靠度的确认信息下,推荐另外需要确认的实例和标注者;标注追踪组件,用于展示用户对实例类标确认信息的记录以及确认信息对其他实例类标带来的影响信息。
为达到上述目的,本发明另一方面提出了一种提高众包标注数据质量的可视分析方法,包括以下步骤:步骤s1,展示不同类别之间的混淆程度,以根据所述混淆程度选择分析的易混淆类别;步骤s2,通过有约束的t-sne降维展示每个实例的不确定类标和实例之间的相互影响信息;步骤s3,通过散点图展示每个标注者在所选定类别上的标注准确率与无效标注程度评分,以确定无效标注者;步骤s4,将用户对实例的类标和标注者可靠度的确认信息进行传播,以推荐另外需要标注的实例和标注者。
本发明实施例的提高众包标注数据质量的可视分析方法,基于用户的确认信息,选择更多需要被确认的实例和标注者;用户对类标和标注者的确认信息的影响通过众包学习模型传播到其他相关的实例和标注者上;通过交互递进式确认方式,可以减少用户寻找需要确认的实例和标注者的时间和精力,并提高众包标注数据质量,同时,方法已通过“浏览器-服务器”的形式实现,用户可以便捷地使用该方法。
另外,本发明上述实施例的提高众包标注数据质量的可视分析方法还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述步骤s1包括:获取标注者混淆矩阵,以展示标注者的标注和众包学习模型推测的标注之间的不匹配程度;重排所述混淆矩阵,以得到易混淆类别形成的块模式。
进一步地,在本发明的一个实施例中,所述步骤s2包括:获取实例二维布局的坐标,以展示所述每个实例的不确定类标;展示所述实例之间的相互影响信息。
进一步地,在本发明的一个实施例中,所述步骤s3包括:获取标注者无效标注程度的评分;刻画不同类别的标注者。
进一步地,在本发明的一个实施例中,所述步骤s4包括:在给定用户当前对实例的标注和标注者可靠度的确认信息下,推荐另外需要确认的实例和标注者;展示用户对实例类标确认信息的记录以及确认信息对其他实例类标带来的影响信息。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的提高众包标注数据质量的可视分析系统结构示意图;
图2为根据本发明实施例的提高众包标注数据质量的可视分析系统模块关系图;
图3为根据本发明实施例的提高众包标注数据质量的可视分析系统实例图;
图4为根据本发明实施例的提高众包标注数据质量的可视分析方法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图描述根据本发明实施例提出的提高众包标注数据质量的可视分析系统及方法,首先将参照附图描述根据本发明实施例提出的提高众包标注数据质量的可视分析系统。
图1是本发明一个实施例的提高众包标注数据质量的可视分析系统结构示意图。
如图1所示,该提高众包标注数据质量的可视分析系统10包括:混淆矩阵可视化模块100、实例可视化模块200、标注者行为可视化模块300和交互递进式确认模块400。
其中,混淆矩阵可视化模块100展示不同类别之间的混淆程度,以根据混淆程度选择分析的易混淆类别。
进一步地,在本发明的一个实施例中,混淆矩阵可视化模块100包括:标注者混淆矩阵计算组件,用于获取标注者混淆矩阵,以展示标注者的标注和众包学习模型推测的标注之间的不匹配程度;矩阵重排组件,用于重排混淆矩阵,以得到易混淆类别形成的块模式。
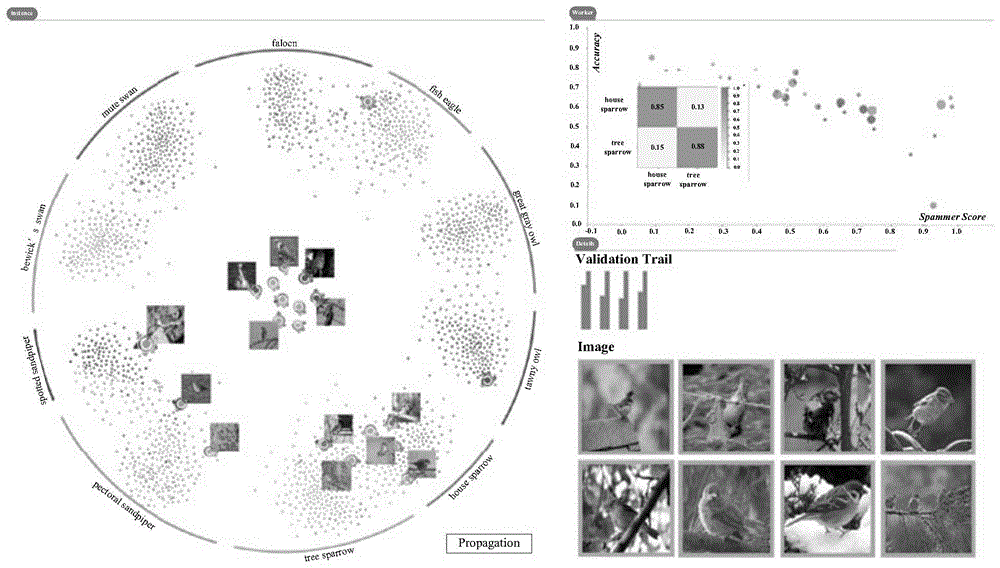
简单来讲,混淆矩阵可视化模块100用于展示不同类别之间的混淆程度。为了更好地展示可能存在的混淆模式,首先计算标注者的混淆矩阵,然后对其进行矩阵重排来展示块模式。每个块模式对应一组易混淆的类。用户通过发现块模式来选择易混淆的类进行进一步分析。具体地说,如图2所示,混淆矩阵可视化模块100包含以下两个子组件:
(1)标注者混淆矩阵计算组件。该组件用于计算标注者混淆矩阵以展示标注者的标注和众包学习模型推测的标注之间的不匹配程度。混淆矩阵是一个m×m的矩阵,m是类的个数。矩阵每一列代表众包学习模型推测的结果,每一行代表标注者标注的结果。
(2)矩阵重排组件。该组件用于揭示标注者混淆矩阵中的块模式。块模式指矩阵对角线上有聚类现象的块。
实例可视化模块200通过有约束的t-sne降维展示每个实例的不确定类标和实例之间的相互影响信息。
进一步地,在本发明的一个实施例中,实例可视化模块200包括:有约束的t-sne组件,用于获取实例二维布局的坐标,以展示每个实例的不确定类标;实例影响流组件,用于展示实例之间的相互影响信息。
也即,实例可视化模块200通过有约束的t-sne降维技术计算每个实例的二维坐标,使得类标确定的实例尽可能按类聚集在一起,而类标不确定的实例分布在不同类中间,以突出展示类标不确定的实例。同时实例之间的相互影响也会以流地图的形式展示。具体地说,实例可视化模块200包含以下两个子组件:
(1)有约束的t-sne投影组件。该组件用于确定实例的二维布局坐标以展示实例的不确定类标。具体地说,对于m个类以及n个实例,该组件最小化以下代价函数fcost:
fcost=α·kl(p||q)+β·kl(pc||qc)+(1-α-β)·kl(ps||qs),
其中,kl(·||·)表示两个分布之间的kullback-leibler(kl)散度。α,β∈[0,1]为两个权值,用于平衡不同kl散度的影响。第一个kl散度和原始t-sne所优化的kl散度相同,用于保持整体布局的可读性。第二个kl散度用于保持布局中类的可读性。为此,引入m个类别限制弧,
其中,
第三个kl散度用于保持交互递进式确认过程中布局的稳定。为此本方法引入n个虚拟限制点。虚拟限制点在高维空间和二维空间的位置分别为对应实例在高维空间的位置以及对应实例上一轮投影在二维空间的位置。
(qs)i=(1+||yi-y′i||2)-1,
其中,y′i是上一轮实例ei在二维空间的坐标。
(2)实例影响流组件。如图3所示,一旦一个实例的类标被确定,互增强图模型会提高该实例的显著性并重新对实例进行排序。此外,本发明实施例对其他实例的影响会以流地图的形式展现(仅展示受影响最大的五个实例)。流地图能够揭露确认传播的内在机制,帮助用户理解传播过程。
标注者行为可视化模块300通过散点图展示每个标注者在所选定类别上的标注准确率与无效标注程度评分,以确定无效标注者。
进一步地,在本发明的一个实施例中,标注者行为可视化模块300包括:无效标注程度评分计算组件,用于获取标注者无效标注程度的评分;标注者类别刻画组件,用于刻画不同类别的标注者。
也就是说,标注者行为可视化模块以散点图形式展示每个标注者在所选定类别上的标注准确率以及无效标注程度评分,以帮助用户找出无效标注者。具体地说,标注者行为可视化模块300包括以下两个子组件:
(1)无效标注程度评分计算组件。该组件用于计算标注者无效标注程度的评分。具体地说,该组件由三个步骤组成:
第一步,计算每个标注者的混淆矩阵并进行矩阵重排。矩阵重排使用bar-joseph等人提出的最优叶节点排序算法。
第二步,检测标注者混淆矩阵中存在的块模式。块模式指矩阵对角线上有聚类现象的块。
首先,定义b(i,j)为矩阵中类ci,ci+1,...,cj-1,cj所形成的块,则块b(i,j)的密度定义为:
其中,l(x,y)表示混淆矩阵第x行第y列的值。块模式检测等价于找到一个c0,c1,...,cm-1的分割,使得所得块的密度总和最大。该优化问题可用动态规划求解。
第三步,计算无效标注程度评分。每个标注者的无效标注程度评分s(w)计算方法为:
其中,k为检测到的块模式的个数,mw是标注者w的混淆矩阵。
(2)标注者类别刻画组件。该组件用于刻画六种不同类别的标注者。可靠标注者有着很高的准确率和很低的无效标注程度评分;其混淆矩阵的对角元素值非常大,而非对角元素值非常小。普通标注者有着相对较高的准确率和相对较低的无效标注程度评分;其混淆矩阵的对角元素值相对较大,而非对角元素值相对较小。草率的标注者有着较低的准确率和中等的无效标注程度评分,并且不存在一个表现较好的类的子集;其混淆矩阵的对角元素值略微高于非对角元素值。部分标注无效的标注者有着中等的准确率和相对较高的无效标注程度评分;其混淆矩阵有着明显的块模式。标注随机的标注者有着非常低的准确率和非常高的无效标注程度评分;其混淆矩阵的对角元素值与非对角元素值差别不大。标注错误一致的标注者有着非常低的准确率和非常高的无效标注程度评分;其混淆矩阵中某一行的值全为1,而其他行的值全为0。
交互递进式确认模块400将用户对实例的类标和标注者可靠度的确认信息进行传播,以推荐另外需要标注的实例和标注者。
在本发明的一个实施例中,交互递进式确认模块400包括:互增强图模型组件,用于在给定用户当前对实例的标注和标注者可靠度的确认信息下,推荐另外需要确认的实例和标注者;标注追踪组件,用于展示用户对实例类标确认信息的记录以及确认信息对其他实例类标带来的影响信息。
具体地,交互递进式确认模块400包括以下两个子组件:
(1)互增强图模型组件。该组件用于在给定用户当前对实例标注和标注者可靠度的确认信息下,推荐更多需要标注的实例和标注者。具体地说,本发明实施例标记re和rw为实例和标注者的排序值,排序值越高表示越需要标注。所有实例和标注者的初始排序值都相等。最终排序值由下式迭代计算得到:
其中mxy表示x和y的关联矩阵,x和y可以是实例和标注者。αxy用于平衡实例和标注者之间的相对增强强度。λ是阻尼系数。ve和vw是实例和标注者的先验显著性。
(2)标注追踪组件。该组件用于展示用户对实例类标确认信息的记录以及确认信息对其他实例类标带来的影响。用户每一轮的确认信息记录以及确认信息对其他实例类标的影响使用两个柱形表示。柱形的高度表示实例的数量。用户可以通过该组件返回到之前某一个确认状态。
根据本发明实施例提出的提高众包标注数据质量的可视分析系统,基于用户的确认信息,选择更多需要被确认的实例和标注者;用户对类标和标注者的确认信息的影响通过众包学习模型传播到其他相关的实例和标注者上;通过交互递进式确认方式,可以减少用户寻找需要确认的实例和标注者的时间和精力,并提高众包标注数据质量,同时,系统已通过“浏览器-服务器”的形式实现,用户可以便捷地使用该系统。
其次参照附图描述根据本发明实施例提出的提高众包标注数据质量的可视分析方法。
图4是本发明一个实施例的提高众包标注数据质量的可视分析方法流程图。
如图4所示,该提高众包标注数据质量的可视分析方法包括以下步骤:
在步骤s1中,展示不同类别之间的混淆程度,以根据混淆程度选择分析的易混淆类别。
进一步地,获取标注者混淆矩阵,以展示标注者的标注和众包学习模型推测的标注之间的不匹配程度;重排混淆矩阵,以得到易混淆类别形成的块模式。
在步骤s2中,通过有约束的t-sne降维展示每个实例的不确定类标和实例之间的相互影响信息。
进一步地,在本发明的一个实施例中,步骤s2包括:获取实例二维布局的坐标,以展示每个实例的不确定类标;展示实例之间的相互影响信息。
在步骤s3中,通过散点图展示每个标注者在所选定类别上的标注准确率与无效标注程度评分,以确定无效标注者。
进一步地,在本发明的一个实施例中,步骤s3包括:获取标注者无效标注程度的评分;刻画不同类别的标注者。
在步骤s4中,将用户对实例的类标和标注者可靠度的确认信息进行传播,以推荐另外需要标注的实例和标注者。
进一步地,在本发明的一个实施例中,步骤s4包括:在给定用户当前对实例的标注和标注者可靠度的确认信息下,推荐另外需要确认的实例和标注者;展示用户对实例类标确认信息的记录以及确认信息对其他实例类标带来的影响信息。
需要说明的是,前述对提高众包标注数据质量的可视分析系统实施例的解释说明也适用于该方法,此处不再赘述。
根据本发明实施例提出的提高众包标注数据质量的可视分析方法,基于用户的确认信息,选择更多需要被确认的实例和标注者;用户对类标和标注者的确认信息的影响通过众包学习模型传播到其他相关的实例和标注者上;通过交互递进式确认方式,可以减少用户寻找需要确认的实例和标注者的时间和精力,并提高众包标注数据质量,同时,方法已通过“浏览器-服务器”的形式实现,用户可以便捷地使用该方法。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本发明中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!