一种基于深度学习的人脸表情和姿态双模态融合表情识别方法与流程
本发明属于图像识别技术领域,具体涉及一种基于深度学习的人脸表情和姿态双模态融合表情识别方法。
背景技术:
情感有三种基础的表现形式:表情、声音和语言。由于表情独有的非接触性,普适性和真实性,在实际生活中最能体现人类真实情感。因此,通过对表情的识别能够有效实现智能人机交互与对自身情绪波动的预知。表情分为面部表情和姿态表情两类。早期的面部表情识别研究困难大,进展缓慢。随着近几年深度学习在计算机视觉领域获得的杰出成就。深度学习结构以及理论便被迅速引入,使得表情识别技术又有了显著的发展。
技术实现要素:
本发明的目的在于提供一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,其能够识别自然环境与光照条件下的表情。
一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,具体包括如下步骤:
步骤1、建立自然环境下的图像数据库;
步骤2、对获取的图像进行预处理和增强处理;
步骤3、将预处理后的图像进行增强处理后送入se-googlenet网络中进行特征提取;
步骤4、选用基于动作分类的googlenet模型的caffemodel的卷积部分直接进行知识迁移训练;
步骤5、将两个经过预训练之后的卷积神经网络分别输入spp层,然后进行特征融合,最后送入lstm完成最终的分类。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤1具体包括如下步骤:
步骤1.1、搜集现有的自然表情数据库;
步骤1.2、利用关键字从网站上爬取表情动态图片;
步骤1.3、从自然表情数据库中的图片序列中选取表情明显的图片和从网站上爬取的表情动态图片组成新的数据库。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤2具体包括如下步骤:
步骤2.1、将建立的自然表情数据库中的视频或动态图片利用ffmpeg进行分帧处理;
步骤2.2、利用人脸检测算法对人脸区域进行提取;对整幅图像生成光流图和差分图等带时序信息的图像;
步骤2.3、对图像进行0-10度的随机旋转,水平翻转,随机裁剪,对比度变化等图像增强操作。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤3中se-googlenet是googlenet的改进,两者在inception模块上不同,se-googlenet使用senet中block单元的部分结构,增加了同层特征通道间的联系。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤3使用se-googlenet的数据特征提取过程基于se-inception模块,通过增加同层特征图的尺度变化理论上构建表情特征,实现对静态表情识别的分类任务。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤4具体包括如下步骤:
步骤4.1、网络首先通过卷积层对表情图像空间特征进行提取和非线性组合;
步骤4.2、通过reshape层将特征变形为与n,b,s以及上层网络输出个数相关的数据结构送入lstm层,其中n为网络一次接受的图片序列数,b代表进行一次梯度更新的图片间隔数,s指第一个lstm层含有神经元的个数;
步骤4.3、lstm层通过神经元随时间的梯度更新结构和门结构生成基于空间特征的时域特征。
所述一种基于深度学习的人脸表情和姿态双模态融合表情识别方法,步骤5具体包括如下步骤:
步骤5.1、将人脸和肢体轮廓送入不同的卷积神经网络结构对其进行图像维度特征提取;
步骤5.2、将卷积图通过spp层完成特征尺寸的固定;
步骤5.3、将两个网络的特征层进行直接连接;
步骤5.4、输入lstm完成表情分类。
本发明的有益效果在于:
本发明首先使用带有se模块的googlenet结构通过光流输入的形式对静态表情图像进行识别,然后将静态表情识别结构与长短记忆网络结合提出基于迁移学习的视频序列表情识别结构。从而扩展了自然环境下同时带有姿态和人脸的表情库;在进行表情识别时考虑了姿态表情,实现了姿态和人脸表情的双通道融合识别;提高了该模型对各种自然环境的适应能力,对实际应用起到了促进作用。
附图说明
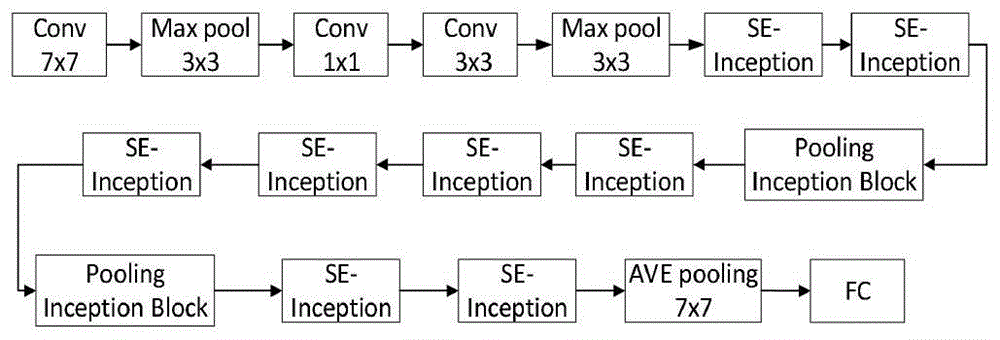
图1为se-googlenet网络结构图像;
图2为inception模块图像;
图3为se-inception模块图像;
图4为poolinginception模块图像;
图5为数据预处理流程图;
图6为双通道网络模型结构图;
图7为基于深度学习的人脸表情和姿态双模态融合表情识别方法流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
如附图7所示,为基于深度学习的人脸表情和姿态双模态融合表情识别方法流程图,具体包括如下步骤:
1、建立人脸-姿态双模态表情数据库;
raf-db数据集:该数据集利用与表情有关的关键词在filckr图片社交网络上下载了三万多张图像,邀请315位接受了表情相关知识训练的志愿者对这些图像进行的标注。实验使用了数据集中给定的12271张图片作为训练集,3068张图片作为测试集。
fer2013数据集:该数据集的主要来源是通过谷歌图片的关键字搜索下载,因此更加接近自然条件下的人脸表情。同时样本的差异性很大,35887张图片里包含了不同的人种、年龄、光照和姿势等。本发明根据比赛的数据集划分进行试验,将28709张图片作为训练集,3589张作为验证集,3589张作为测试集。
afew数据集:视频序列方面本发明选用afew数据集对视频序列表情进行七分类,afew以avi格式视频给出,并通过ffmpeg对其进行视频分帧,删除掉各图像序列前后的不相关帧,以保证数据库的准确性。
为尽可能扩充数据集,本发明还通过对tumblr,google,giphy等网站以关键词形式进行数据爬取。因考虑到视频片段获取的困难性和多数电影片段角色近景较少需要较大的图像处理工程,本发明采用对表情gif分帧的形式实现图像序列的获取。同时,本发明在数据库建立阶段重点对自然,高兴外五类表情进行重点采集,使样本量达到尽量均衡。
2、数据预处理与数据增强
数据预处理:
生成带标签的图像绝对路径文档,其以行为单位,格式为图像路径,空格符,表情类别编号,使caffe框架通过该文档对数据和标签进行读取。
根据训练集,测试集图片个数对网络训练参数如批量大小,迭代次数,学习率衰减间隔等配置参数进行设置。
每次网络训练对训练集进行过依次遍历后,将训练列表随机打乱,从而为训练带来随机扰动,减少训练不充足,过拟合等不良结果。对图像数据进行增强处理也是处于这方面考虑。
最后,将图像减去均值,使其像素值分布尽量在零值附近均匀分布,提升训练速度。
数据增强:
利用基于caffe框架的python接口对输入data层进行了改写,实现了小角度旋转、随机裁剪、对比度变化等功能。在各增强处理的参数确定中,通过生成一定范围内的随机数来为数据输入添加随机扰动,使得每次输入的图片都不完全相同。
3、基于se-googlenet的数据特征提取;
se-googlenet是googlenet的改进,两者结构在inception模块上有所不同。se-googlenet的inception模块中增加了senet中block单元的部分结构,增加了同层特征通道间的联系,并使用poolinginceptionblock模块代替了maxpooling。如此既达到了下采样的目的,又完成了一次特征提取工作,比使用一个inception和一个maxpooling要更高效。
由于se-googlenet网络模型规模较大,因此对每个卷积操作都使用bn层和scale进行归一化,防止梯度弥散,加快训练速度。
使用se-googlenet的数据特征提取过程主要基于se-inception模块,通过增加同层特征图的尺度变化理论上构建表情特征,实现对静态表情识别的分类任务。如图3所示,每一层的输出维度信息表示在方框周围,c代表的是特征图的个数,r的值为c/16。w和h分别为特征图的宽和高。在该模块中,squeeze操作使用了globalaveragepooling,bottleneck结构由2个全连接层组成,目的是建立通道之间的相关性,使输出的权值与输入特征的数目统一。实验中,首先将特征维度降低到输入的1/16,经过relu函数激活后再通过1个全连接层,使其回到原来的维度。
4、迁移学习与多特征融合:双通道输入的表情识别网络模型(two-streamlstmconvolutionnetwork,tslcn);
如图6所示,假设n为网络一次接受的图片序列数,b代表进行一次梯度更新的图片间隔数,s指第一个lstm层含有神经元的个数。网络首先通过卷积层对表情图像空间特征进行提取和非线性组合,然后通过reshape层将特征变形为与n,b,s以及上层网络输出个数相关的数据结构送入lstm层,lstm层通过神经元随时间的梯度更新结构和门结构生成基于空间特征时域特征,最后将其送入softmax和损失函数进行表情分类。
为实现双模态的表情识别,本发明将人脸和肢体送入不同的卷积神经网络结构对其进行图像维度特征提取,再通过多维数组直接连接的方式进行组合。
在人脸的卷积结构上采用微调后的googlenet单帧模型,在身体姿态方面考虑到数据库姿态信息过少难以实现有效单帧建模,则选用基于动作分类的googlenet模型caffemodel的卷积部分直接进行知识迁移,该模型选用多个深度卷积结构实现了自然背景下的动作的分类。再以金字塔池化层(spp)代替传统池化,对卷积图统一尺度变换。然后将变换后特征送入长短记忆网络中去进行时空域信息整合与提取,lstm的门结构也能有效实现特征维数的降低,最后经softmax层实现对面部,姿态的综合表情分类。
- 还没有人留言评论。精彩留言会获得点赞!