城市色调的智能分析与评价方法与流程
本发明属于城市色彩规划技术领域,具体涉及城市色调的智能分析与评价方法。
背景技术:
城市色彩智能分析与评价是城市设计的重要组成部分,对延续城市文脉、提升城市品质、塑造城市精神具有突出作用。然而,城市色彩规划的开展却面临诸多难题,最大的问题便是色彩现状的调研与评估。该类工作需要对城市色彩现状进行系统调研,但色彩体系不了解、技术方法不成熟、现状调研区域大等问题摆在面前,利用人工调研方法费时费力也不全面,难以达到色彩规划工作的要求。
人工智能(artificialintelligence),英文缩写为ai,它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。本研究寄希望借助人工智能,帮助开展城市色彩现状评价。研究中,将积极探索以深度学习为手段的人工智能方法在城市规划中的应用,以色彩评价为落脚点,以图像视觉识别技术为手段,利用计算机代替人工作业,对城市色彩进行现状采集与评估。力求探寻一套快速准确定位城市色彩现状的智能方法。
人工智能技术最具代表性的是深度学习算法,它是深层神经网络的代名词。神经网络技术可以追溯到上世纪40年代,warrenmcculloch和walterpitts模拟人类大脑神经元提出的简化的神经网络模型即mp模型,对输入使用简单的线性加权,并经过一个阈值函数得到一个0或1的输入。上世纪60年代frankrosenblatt提出了单隐层结构的感知机模型,能够对一些简单形状分类。然而mminsky和spapert于1965提出感知机的缺陷,即无法处理异或算法,并且在当时的计算能力下无法处理多层的神经网络,这些局限性导致学界对神经网络的发展持悲观态度。直到上纪80年代末,hinton提出基于感知机的多隐层构造的深层神经网络,分布式表达的提出说明了深度神经网络是可以解决异或问题的。另外rumelhart和hinton提出的深层神经网络使用反向传播算法,大大降低了训练神经网络所需要的时间。
与此同时,传统的机器学习算法也在不断发展,并在上世纪90年代末逐步超越神经网络,成为学界研究的热点,集中在svm、adaboosting、随机森林等分类器上,原因主要有二,首先是相关硬件水平无法满足深度神经网络的巨大计算量,导致当时神经网络深度不够,无法发挥其优势。其次是当时的数据量比较小,无法满足深层网络的需求。
直到本世纪10年代左右云计算、互联网+、gpu、并行计算的出现和发展,使以上问题得以逐渐解决,神经网络又一次迎来了快速发展,2012年imagenet举办的图像分类竞赛ilsvrc中,深度学习系统alexnet赢得了冠军。自此之后,深度学习掀起了神经网络的第二次浪潮,并扩展到了机器学习的各个领域,比如图像识别、语音识别、自然语言理解等。
技术实现要素:
本发明的目的在于提出一种能够高效、准确地对城市色彩进行智能分析与评价的方法。
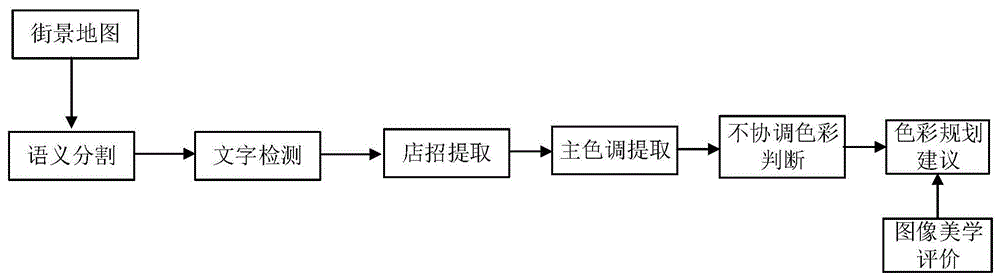
本发明提出的对城市色彩进行智能分析与评价的方法,是基于深度学习方法的,首先提取海量街景数据中城市色彩,并对不协调区域给出整改方案,具体步骤如下:
(1)采用人工智能算法对街景图像数据进行精细分割,提取其中的建筑物;
(2)采用文字智能检测算法与图像处理技术,提取街景中的店招;
(3)基于hsv颜色体系,提取统计建筑物与店招颜色;
(4)分析判断店招与建筑物色调是否与指定区域的主色调协调,并标出不协调区域;
(5)利用图像美学评价算法,评价给出不协调区域的整改方案。
本发明步骤(1)中,所述采用人工智能算法对街景图像数据进行精细分割,提取其中的建筑物,是利用frrn(full-resolutionresidualnetworks)网络[1],先用cityscapes数据集[2]进行训练,利用大量上海地区街景数据集对不同训练迭代次数的结果进行验证,以高精度分割街景数据,这里所述的街景数据包括谷歌、百度、腾讯网络中常见街景图像数据。
大多数先进的语义分割系统都是基于cnn(卷积神经网络),其中较为出名的是使用端对端训练的fcn架构,该工作将预训练网络调整用于语义分割,获得了显著的性能提升。
在fcn中使用连续的池化操作,用于扩张feature的接受野并提升分类性能。但同时会显著降低feature空间分辨率,导致丢失空间细节。为了克服这个问题,有使用skipconnection扩展feature;有使用编码-解码(encoder-decoder)结构的,encoder提取语义,decoder恢复空间细节。
也有许多方案对cnn的输出作平滑操作用于提升预测结果。常见的如deeplab系列使用的crf,也有将crf化为平均场结合整个模型实现端对端训练。一些工作使用域变换或超分辨率平滑结果。
当前先进的语义分割系统都大多采用某种形式的fcn结构,即采用图片作为输入,以每个类别概率图作为输出。许多方案依赖于在分类任务上(imagenet)预训练的网络,例如多种vgg和resnet变体。预训练能够帮助模型预先设置模型权重,与只使用目标数据从头开始训练相比,减少了训练时间且常有更好的性能。然而使用预训练的模型有一个固有的限制,即已存在的预训练网络结构无法改变,这限制了新方法的设计,例如难以添加bn层或新的激活函数。
语义分割系统使用fcn架构时,常见的策略是使用池化或下采样操作降低feature的空间分辨率以获取high-levelfeatures,这么做有两个原因:
(1)可以显著的增加接受野;
(2)让模型鲁棒性更强,能够应对小的图片变换(即内在不变性);
池化操作能够高度描述图片中物体,但是这对定位精度会造成巨大的损耗(池化丢失大量的空间信息)。许多工作想克服这个问题获得精确的分割结果。例如deconvolution-conv、dilated等等。
本发明采用一个新颖的网络架构frrn,整体采用编码-解码(encoder-decoder)架构,基本单元和残差单元类似,不需要额外的后续处理或者预训练模型。新的架构使用两条流:
一条流是(池化流–>语义流):进过一连串的池化操作,用于捕捉图片中的语义信息;
一条流是(残差流–>细节流):携带全分辨率的特征,用于提供精准的边界信息。
两条流通过与全分辨率残差单元(frru)相结合,最后得到预测结果上采样到指定大小。
每个frrus有两个输出和两个输入。如果
采用和resnet相同的优越训练属性的网络,具有两条处理流的full-resolutionresidualnetworks(frrns)。一条数据流称之为残差流(residualstream),通过连续添加残差计算。另一条数据流称之为池化流(poolingstream),是在输入上应用一连串的卷积和池化操作直接得到结果。
先不考虑网络的具体设计,获取high-level需要多个池化操作:
池化操作减少feature的空间分辨率的同时增加了模型接受野,这也是模型应对小型平移具有鲁棒性的根本。多次使用池化操作就很难追踪low-level的feature了(例如边沿,边界等)。这就让识别和准确定位产生了矛盾。
基于上述算法,首先对cityscapes公开数据集进行训练,利用大量上海地区街景数据集对不同训练迭代次数的结果进行验证,进而可对指定区域的街景数据进行高精度语义分割,分割结果主要有天空、建筑、绿化(草地、树木)、桥梁、地面、行人、车辆等目标。
本发明步骤(2)中,所述采用文字智能检测算法与图像处理技术,提取街景中的店招,具体内容介绍如下:
提取店招的思路是提取图片中的文字信息,即通过人工智能的方法进行中英文字体检测,再利用基于hsv体系的多生长点区域生长算法进行区域生长,再利用图像处理中形态学方法作后续处理,得到完整的店招区域。
其中,文本检测的其中一个难点就在于文本行的长度变化是非常剧烈的。如果采用基于fasterrcnn等通用物体检测框架的算法都会面临这怎么生成好的文本问题。因此本发明采用常用的ctpn模型[3]作为基础,通过检测一个一个小的固定宽度的文本段,再通过后处理部分再将这些小的文本段连接起来,得到文本行。具体流程为:
(a)通过vgg16[4]网络提取图像特征,用前五个卷积层;
(b)在特征图的每个位置上预测候选区域(anchor)对应的类别和位置信息;
(c)通过rnn[5]网络结果输出到分类层中,进行判断是否字符及其位置信息;
(d)通过文本线构造算法[3],得到店面招牌的文本信息。
设文本实际高度h,实际中心点坐标
其中
文本检测算法很多,其它还有基于旋转区域候选网络(rrpn)模型,它将旋转因素并入经典区域候选网络;还有使用resnet-101做基础网络的ftsn(fusedtextsegmentationnetworks)模型,它使用了多尺度融合的特征图及分割网络支持倾斜文本检测;dmpnet(deepmatchingpriornetwork)模型使用四边形(非矩形)来更紧凑地标注文本区域边界,其训练出的模型对倾斜文本块检测效果更好;使用全卷积网络(fcn)生成多尺度融合的特征图并进行素级的文本块预测east(efficientandaccuracyscenetextdetectionpipeline)模型;将每个单词切割为更易检测的有方向的小文字块(segment),然后用邻近连接(link)将各个小文字块连接成单词的seglink模型,等等。因为算法主要考虑横向的街景中规则的店招信息,所以采用cptn模型来进行初步的文字提取。
文字提取之后,采用区域生长算法[6],由于某些店面招牌长度较长,颜色并非单一分布,同时也存在植被、电线杆等遮挡的现象,因此采用基于hsv体系的多生长点区域生长算法,尽可能使该算法能覆盖到所有区域。该算法将传统区域生长算法中的阈值修改为hsv体系中若干种色相范围,将与生长点同一色相的像素点归纳到区域中来,同时选取多个生长点,以此提高区域生长的准确性。基本上,在没有像素满足加入某个区域的条件的时候,区域生长就会停止。
最后通过形态学中的闭运算以及去孔洞算法[6]提取出整个店面招牌。
闭运算操作是通过先膨胀后腐蚀的方法,如式所示:
其中
本发明步骤(3)中,所述基于hsv颜色体系,提取统计建筑物与店招颜色,具体如下:
为了能够更准确地划分不同色彩,在原hsv色彩体系的基础上,将整个体系所涵盖的色彩划分为36*20*20=14400份;其中,色相均分为36份,归纳值取范围的中值,例如色相值位于-5°~5°内像素点归纳为0°;明度和饱和度分别均分为20份,一份大小为0.05,归纳值取范围的右端点,例如明度位于0~0.05内的像素点归纳为0.05,以此类推,综合三维信息,一共产生14400种颜色;从而将建筑物墙面中的每个像素点进行分类。
本发明步骤(4)中,所述分析判断店招与建筑物色调是否与指定区域的主色调协调,并标出不协调区域,具体步骤如下:
(a)根据前面分割结果,判断出当前图像中的每块店招、建筑物外墙及其对应的颜色信息;
(b)同时统计当前场景中所有颜色占的比例,判断当前视角下建筑物或城区主色调、色系;
(c)再判断墙面、店招色、调色系是否与主色调、色系协调,如果不协调,则在原图像中标出,并给出对应的位置信息。
本发明步骤(5)中,所述利用图像美学评价算法,评价给出不协调区域的整改方案,是通过人工智能方法分析图像颜色、构图等方面的信息,从而得到整改方案,具体步骤如下:
(a)设计图像美学评价网络,并用ava数据集中建筑数据进行训练;
ava数据集[7]是专门为图像美学评价而设计构建的数据集,共包含25万张照片,覆盖风景、植物、动物、夜景、人像、建筑等各种不同内容的照片,包含了丰富的美学特征。本发明设计的图像美学评价网络,包括:一个输入图像层(imageinputlayer)、四个卷积层(conv)、五个非线性激活层(relu)、三个最大池化层(maxpool)、三个全连接层(fc)、一个防止过拟合的dropout层、一个分类器softmax,如图7所示;利用ava数据集中建筑数据对图像美学评价网络进行训练,该网络利用卷积层、非线性激活层与池化层的组合对图片美学特征进行提取,利用输出为10的全连接层对图片进行标签向量预测;
(b)通过搭建网站让公众参与街景照片的评分,共得到约4000张打分后的街景照片,利用此数据对上述网络进行迁移学习,并通过不断改变不协调区域颜色给出新的评分;根据评分结果给出最适合当前场景的颜色作为推荐颜色。
本发明提出了一种高效、精确的城市色调智能分析与评价方法,首先通过高精度的语义分割,将街景图像分为天空、建筑、树木、草地、道路、桥梁、广告牌等几种目标;再通过文字识别技术识别建筑物外墙上的店面招牌,然后提取建筑物外墙、店招的颜色;通过统计分析方法判断当前视角情况下的主要色调;根据色调对比,判断当前建筑外墙与店招背景色是否与当前主色调协调,如果不协调则给出具体位置;最后利用图像美学评价方法给出不协调区域的推荐改进颜色。
本发明提出的方法能快速高效地处理海量的图像数据,其特点是利用当前迅猛发展的深度学习算法进行图像分割、店招提取、美学评价,随着数据量的增大,算法的精度亦能逐步提高。本发明方法还可以根据一个城市的训练结果迁移到不同的城市。
本发明方法适用于城市图像大数据,鲁棒性高,实时性好,具有推广应用前景。
附图说明
图1是本发明的整体检测算法流程图。
图2是店面招牌检测算法流程图。
图3是街景及其分割结果图。
图4是店面招牌检测结果图。
图5是店面招牌色彩信息提取实例示意图。
图6是不协调区域检测结果图。
图7本发明提出的图像美学评价网络结构图。
具体实施方式
下面结合附图对本发明的实施例作详细说明。本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
本实例采用的是上海市街景图像数据。
图1是本发明的算法流程图,该算法主要包括输入街景图像、语义分割,文字检测、店招提取、颜色提取、主色调分析、不协调区域分析与提取、图像美学智能评价等步骤。
图2是本发明提出的店招提取步骤,包括网络预训练、文本提取、形态学处理、背景分割、区域判断等步骤。
结合实例说明本发明的具体实施过程如下:
步骤1:输入街景图像、进行语义分割,结果如图3所示,可以分割出建筑、树木、行人、甚至车辆;
步骤2:在步骤1得到分割结果的基础上,利用本发明提出的店招检测算法进行店招检测,结果如图4所示,可以将店招精确的提取出来;
步骤3:在步骤2提取到店招结果的基础上,通过形态学处理算法,将店招的文字和背景进行分割,提取店招背景颜色,具体过程如图5所示;
步骤4:根据步骤1的分割结果和步骤3的店招背景分割结果,提取当前视角下所有街景图像的颜色信息,并通过统计得到主色调,进而对所有墙面和店招背景进行判断,得到颜色不协调区域,并给出位置信息,如图6所示;
步骤5:对不协调区域改变色彩,再输入训练出的美学评价网络,根据得分情况给出推荐的整改颜色。
本实例街景图像尺寸为1024*512像素,实验的软硬件配置为intel(r)core(tm)i5-4590处理器、8gb内存、matlabr2018a,处理一幅图像的时间<1s。
参考文献
[1]t.pohlen,a.hermans,andm.mathiasb.leibe.:full-resolutionresidualnetworksforsemanticsegmentationinstreetscenes.incvpr,2017.6
[2]m.cordts,m.omran,s.ramos,t.rehfeld,m.enzweiler,r.benenson,u.franke,s.roth,andb.schiele.thecityscapesdatasetforsemanticurbansceneunderstanding.incvpr,2016.2,6
[3]z.tian,w.huang,t.he,p.he,y.qian.:detectingtextinnaturalimagewithconnectionisttextproposalnetwork(2016).ineuropeanconferenceoncomputervision(eccv)
[4]simonyan,k.,zisserman,a.:verydeepconvolutionalnetworksforlarge-scaleimagerecognition(2015),ininternationalconferenceonlearningrepresentation(iclr)
[5]graves,a.,schmidhuber,j.:framewisephonemeclassificationwithbidirectionallstmandotherneuralnetworkarchitectures.neuralnetworks18(5),602–610(2005)
[6]冈萨雷斯.数字图像处理[m].北京:电子工业出版社,2003.
[7]f.perronnin,l.marchesottiandn.murray,"ava:alarge-scaledatabaseforaestheticvisualanalysis,"2012ieeeconferenceoncomputervisionandpatternrecognition(cvpr),providence,riusa,2012,pp.2408-2415.。
- 还没有人留言评论。精彩留言会获得点赞!