鉴定网络用户的方法及系统、网络信息的屏蔽方法及系统与流程
本发明涉及网络信息的识别技术领域,具体地涉及一种鉴定网络用户的方法及系统、网络信息的屏蔽方法及系统。
背景技术:
随着quora、知乎等网络问答社区逐渐渗入大众的生活,社区用户可以在社区中自由提问、评论、转发、点赞,表达自己的观点。与百度知道、yahoo!answers等传统问答社区不同,社会化问答社区更注重进行多元信息交互。随着大量用户生成内容涌现,社区中问题与答案数量累积,社区中出现问答质量良莠不齐,问题无法得到专家即时解答等现象。如何识别社会化网络问答社区中的专家特征,发现可以提供优质答案的专家,也逐渐成为学术界的研究热点。
技术实现要素:
本发明实施方式的目的是提供一种鉴定网络用户的方法及系统、网络信息的屏蔽方法及系统,鉴定网络用户的方法及系统可以对每个网络用户进行评分,屏蔽方法和系统可以屏蔽评分较低的网络用户的信息,从而提高网络问答的效率和准确度。
为了实现上述目的,本发明实施方式提供一种鉴定网络用户的方法,所述方法包括:
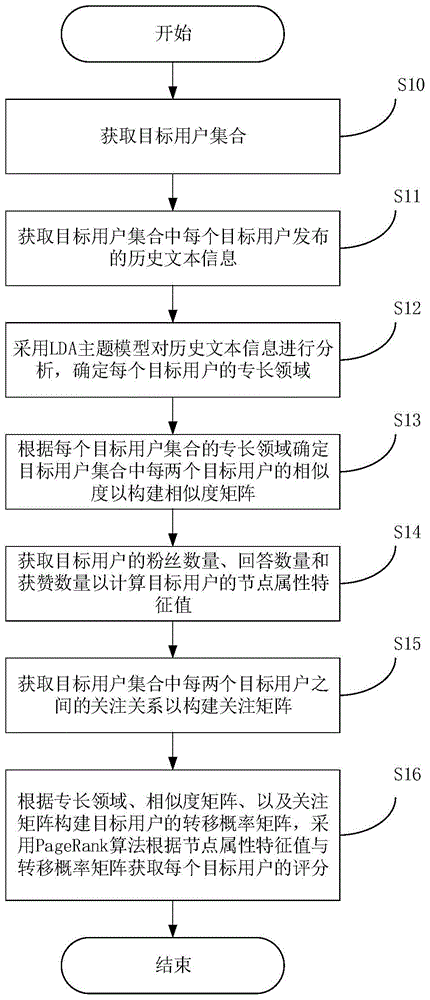
获取目标用户集合;
获取所述目标用户集合中每个所述目标用户发布的历史文本信息;
采用lda主题模型对所述历史文本信息进行分析,确定每个所述目标用户的专长领域;
根据每个目标用户的专长领域确定所述目标用户集合中每两个所述目标用户的相似度以构建相似度矩阵;
获取所述目标用户的粉丝数量、回答数量和获赞数量以计算所述目标用户的节点属性特征值;
获取所述目标用户集合中每两个所述目标用户之间的关注关系以构建关注矩阵;
根据所述专长领域、所述相似度矩阵、以及所述关注矩阵构建所述目标用户的转移概率矩阵,采用pagerank算法根据所述节点属性特征值与所述转移概率矩阵获取每个所述目标用户的评分。
可选地,所述采用lda主题模型对所述历史文本信息进行分析,确定每个所述目标用户的专长领域包括:
将所述历史文本信息转化为目标用户与主题以及主题与词语的概率分布;
根据所述概率分布确定所述目标用户的专长领域。
可选地,所述根据每个目标用户的专长领域确定所述目标用户集合中每两个所述目标用户的相似度以构建相似度矩阵包括:
根据公式(1)计算每两个所述目标用户的相似度,
其中,uit为所述目标用户ui专长领域的分布的值,ujt为所述目标用户uj专长领域的分布的值,sij为所述相似度,k为目标用户ui及目标用户uj的专长领域的值的总数。
可选地,所述获取所述目标用户的粉丝数量、回答数量和获赞数量,对所述粉丝数量、所述回答数量和所述获赞数量以计算所述目标用户的节点属性特征值包括:
对所述粉丝数量、所述回答数量和所述获赞数量进行归一化处理。
可选地,所述归一化处理包括:
采用公式(2)处理所述粉丝数量、所述回答数量和所述获赞数量,
其中,f(ui)为所述目标用户ui的所述粉丝数量、所述回答数量和所述获赞数量中的任一者,f(ui)为对应处理后的所述粉丝数量、所述回答数量或所述获赞数量;
所述获取所述目标用户的粉丝数量、回答数量和获赞数量,对所述粉丝数量、所述回答数量和所述获赞数量以计算所述目标用户的节点属性特征值进一步包括:
根据公式(3)计算所述节点属性特征值,
b(ui)=(f(ui)+a(ui)+l(ui))/3,(3)
其中,b(ui)为所述节点属性特征值,f(ui)为处理后的所述粉丝数量,a(ui)为处理后的所述回答数量,l(ui)为处理后的所述获赞数量。
可选地,所述获取所述目标用户集合中每两个所述目标用户之间的关注关系以构建关注矩阵包括:
根据公式(4)计算所述关注矩阵中每个元素的值,
可选地,所述根据所述专长领域、所述相似度矩阵、以及所述关注矩阵构建所述目标用户的转移概率矩阵,采用pagerank算法根据所述节点属性特征值与所述转移概率矩阵获取每个所述目标用户的评分包括:
根据公式(5)计算每个所述目标用户的评分,
其中,ur(ui)为所述目标用户ui的所述评分,d为预设的阻尼因子;u为所述目标用户集合,aij为所述关注矩阵中的元素;sij为所述相似度;b(ui)为所述节点属性特征值。
本发明的另一方面还提供一种鉴定网络用户的系统,所述系统包括处理器,所述处理器用于执行上述任一所述的方法。
本发明的另一方面还提供一种网络信息的屏蔽方法,所述屏蔽方法包括:
接收网络信息;
获取所述网络信息的目标用户来源以获取目标用户集合;
采用上述任一所述的方法根据所述目标用户集合计算每个所述目标用户的评分;
屏蔽评分低于预设的评分阈值的目标用户的信息。
本发明的再一方面还提供一种网络信息的屏蔽系统,所述屏蔽系统包括处理器,所述处理器用于执行上述所述的方法。
通过上述技术方案,本发明提供的鉴定网络用户的方法通过对每个目标用户(网络用户)发布的历史文本信息以及目标用户本身的信息进行分析,从而计算出每个目标用户的评分,从而为目标用户的评判提供依据;本发明提供的网络信息的屏蔽方法在接收到网络信息后,针对发布网络信息的目标用户计算每个目标用户的评分,再将评分低于预设的评分阈值的目标用户的信息屏蔽掉,从而避免接收低价值、无效的网络信息,提高了网络问答的效率以及答案的有效性。
本发明实施方式的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明实施方式的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施方式,但并不构成对本发明实施方式的限制。在附图中:
图1是根据本发明的一个实施方式的鉴定网络用户的方法的流程图;
图2是根据本发明的一个实施方式的网络信息的屏蔽方法的流程图。
具体实施方式
以下结合附图对本发明实施方式的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施方式,并不用于限制本发明实施方式。
在本申请实施方式中,在未作相反说明的情况下,使用的方位词如“上、下、顶、底”通常是针对附图所示的方向而言的或者是针对竖直、垂直或重力方向上而言的各部件相互位置关系描述用词。
另外,若本申请实施方式中有涉及“第一”、“第二”等的描述,则该“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施方式之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本申请要求的保护范围之内。
如图1所示根据本发明的一个实施方式的鉴定网络用户的方法的流程图。在图1中,该方法可以包括:
在步骤s10中,获取目标用户集合。
在步骤s11中,获取目标用户集合中每个目标用户发布的历史文本信息。
在步骤s12中,采用lda主题模型对历史文本信息进行分析,确定每个目标用户的专长领域。在该实施方式中,对本领域人员而言,采用lda模型对文本信息进行识别的方式可以是多种。在本发明的一个示例中,该步骤s12可以具体为:
采用lda主题模型根据历史文本信息进行主题建模,从而将历史文本信息转化为目标“用户与主题”以及“主题与词语”的概率分布,再根据概率分布确定目标用户的专长领域。
在步骤s13中,根据每个目标用户的专长领域确定目标用户集合中每两个目标用户的相似度以构建相似度矩阵。具体地,针对任意两个目标用户(ui和uj),可以根据公式(1)计算该两个目标用户的相似度,
其中,uit为目标用户ui专长领域的分布的值,ujt为目标用户uj专长领域的分布的值,sij为相似度,k为目标用户ui及目标用户uj的专长领域的值的总数。
在步骤s14中,获取目标用户的粉丝数量、回答数量和获赞数量以计算目标用户的节点属性特征值。在该实施方式中,粉丝数量可以为关注了该目标用户的用户数量,从而表明该目标用户受关注的程度;回答数量可以为该目标用户在一个话题下回答的相关问题的数量,从而反映出该目标用户的专业程度;获赞数量可以为该目标用户的答案受到其他用户的赞同数量,从而反映出其他用户对该目标用户的赞同程度。
此外,由于粉丝数量、回答数量和获赞数量之间并没有一致性的参考价值,因此,为了能够采用一个变量同时体现三者的特点,在本发明的一个实施方式中,可以对该粉丝数量、回答数量和获赞数量进行归一化处理。具体地,可以是采用公式(2)处理粉丝数量、回答数量和获赞数量,
其中,f(ui)为目标用户ui的粉丝数量、回答数量和获赞数量中的任一者,f(ui)为对应处理后的粉丝数量、回答数量或获赞数量。
相应地,对于处理后的粉丝数量、回答数量及获赞数量,可以进一步根据公式(3)计算节点属性特征值(用于同时体现粉丝数量、回答数量和获赞数量的特点),
b(ui)=(f(ui)+a(ui)+l(ui))/3,(3)
其中,b(ui)为节点属性特征值,f(ui)为处理后的粉丝数量,a(ui)为处理后的回答数量,l(ui)为处理后的获赞数量。
在步骤s15中,获取目标用户集合中每两个目标用户之间的关注关系以构建关注矩阵。在网络论坛中,用户之间往往存在一些相互关注的情况,每个用户所关注的用户的类型以及关注自身的其他用户的类型也间接体现出该用户的专业程度。因此,可以针对这一特点构建关注矩阵。具体地,可以是根据公式(4)计算关注矩阵中每个元素的值,
在步骤s16中,根据专长领域、相似度矩阵、以及关注矩阵构建目标用户的转移概率矩阵,采用pagerank算法根据节点属性特征值与转移概率矩阵获取每个目标用户的评分。具体地,该步骤可以是例如根据公式(5)计算每个目标用户的评分,
其中,ur(ui)为目标用户ui的评分,d为预设的阻尼因子;u为目标用户集合,aij为关注矩阵中的元素;sij为相似度;b(ui)为节点属性特征值。
本发明的另一方面还提供一种鉴定网络用户的系统,系统包括处理器,处理器用于执行上述任一的方法。
如图2所示是根据本发明的一个实施方式的网络信息的屏蔽方法的流程图。在图2中,该屏蔽方法可以包括:
在步骤s20中,接收网络信息;
在步骤s21中,获取网络信息的目标用户来源以获取目标用户集合;
在步骤s22中,采用上述任一的方法根据目标用户集合计算每个目标用户的评分;
在步骤s23中,屏蔽评分低于预设的评分阈值的目标用户的信息,从而实现对低价值、无效的网络信息的屏蔽。
本发明的再一方面还提供一种网络信息的屏蔽系统,屏蔽系统包括处理器,处理器用于执行上述的方法。
在本发明的该实施方式中,上述处理器可以是例如通用处理器、专用处理器、常规处理器、数字信号处理器(dsp)、多个微处理器、与dsp核心相关联的一个或多个微处理器、控制器、微控制器、专用集成电路(asic)、现场可编程门阵列(fpga)电路、任何其它类型的集成电路(ic)、状态机、系统级芯片(soc)等。
通过上述技术方案,本发明提供的鉴定网络用户的方法通过对每个目标用户(网络用户)发布的历史文本信息以及目标用户本身的信息进行分析,从而计算出每个目标用户的评分,从而为目标用户的评判提供依据;本发明提供的网络信息的屏蔽方法在接收到网络信息后,针对发布网络信息的目标用户计算每个目标用户的评分,再将评分低于预设的评分阈值的目标用户的信息屏蔽掉,从而避免接收低价值、无效的网络信息,提高了网络问答的效率以及答案的有效性。
以上结合附图详细描述了本发明例的可选实施方式,但是,本发明实施方式并不限于上述实施方式中的具体细节,在本发明实施方式的技术构思范围内,可以对本发明实施方式的技术方案进行多种简单变型,这些简单变型均属于本发明实施方式的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明实施方式对各种可能的组合方式不再另行说明。
本领域技术人员可以理解实现上述实施方式方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
此外,本发明实施方式的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施方式的思想,其同样应当视为本发明实施方式所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!