一种性能预测模型与产品研发相结合的方法和装置与流程
本发明涉及冶金技术领域,尤其涉及一种性能预测模型与产品研发相结合的方法和装置。
背景技术:
随着市场发展需要,客户迫切需要具有个性化、高效率、低耗能的硅钢新产品以保证其在市场上的竞争优势,对研发出新创意、低能耗、高磁感的新产品提出更高要求,新产品面临需要进行研发,但原有产品研发方法面临工艺路线长,人工评价体系繁琐,验证成本高,周期长等缺陷,亟需改变传统的产品设计方法,引入智能设计模型,缩短研发周期,满足下游客户对产品个性化、多样化、更新速度快等要求。经过多年生产,生产流程、工艺流程比较稳定,生产过程中产生的数据具有很高的准确性,为数据挖掘与分析提供良好的数据支撑,同时产品研发人员经过多年的生产,已经积累了丰富的经验,具备优秀的数据挖掘与分析业务指导能力。
本申请人发现上述现有技术至少存在如下技术问题:
现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。
技术实现要素:
本发明实施例提供了一种性能预测模型与产品研发相结合的方法和装置,解决了现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。
鉴于上述问题,提出了本申请实施例以便提供一种性能预测模型与产品研发相结合的方法和装置。
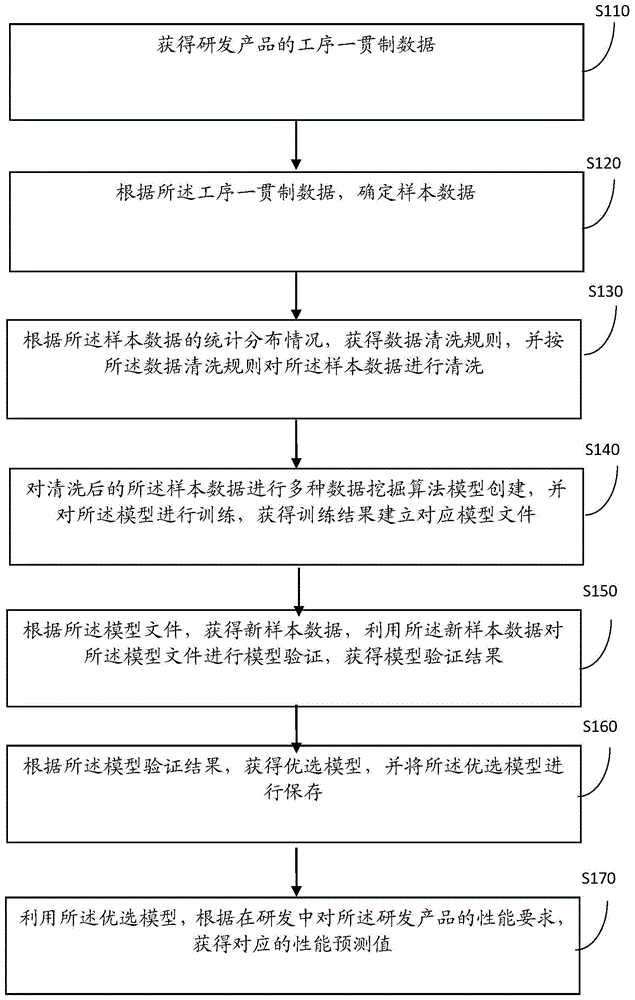
第一方面,本发明提供了一种性能预测模型与产品研发相结合的方法,所述方法包括:获得研发产品的工序一贯制数据;根据所述工序一贯制数据,确定样本数据;根据所述样本数据的统计分布情况,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗;对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件;根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果;根据所述模型验证结果,获得优选模型,并将所述优选模型进行保存;利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。
优选的,所述根据所述工序一贯制数据,确定样本数据,包括:将所述工序一贯制数据通过数据库建立多层数仓;根据所述多层数仓,按照所述研发产品的生成工序进行分层整合,获得整合一贯制数据;根据所述整合一贯制数据,按照预设条件确定所述样本数据。
优选的,所述对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件,包括:选择所述数据挖掘算法,其中,所述数据挖掘算法包括:多云回归算法、随机森林算法、xgb算法;根据所述数据挖掘算法,获得所述数据挖掘算法对应模型;利用所述样本数据对所述模型进行训练,获得第一训练结果;根据所述第一训练结果,按照筛选自变量要求对所述训练结果中的自变量进行筛选,获得关键自变量;利用所述关键自变量对所述模型重新进行模型训练,获得第二训练结果;将所述第二训练结果保存至所述模型文件中,其中,所述模型文件的名称包括产品牌号、算法、创建人、当前时间、流水号。
优选的,所述关键自变量数量不大于30项。
优选的,所述方法还包括:根据公式|预测铁损值-真实铁损值|/样本个数≤n,对所述训练结果、所述模型验证结果中铁损的准确性进行评价,其中,当所述研发产品为中低牌号时,n=0.1,当所述研发产品为高牌号时,n=0.03;根据公式|预测磁感值-真实磁感值|/样本个数≤m,对所述训练结果、所述模型验证结果中磁感的准确性进行评价,其中,当所述研发产品为中低牌号时,m=0.005,当所述研发产品为高牌号时,m=0.003;根据公式|预屈服强度值-真实屈服强度值|/样本个数≤5,对所述训练结果、所述模型验证结果中屈服强度的准确性进行评价。
优选的,所述利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果之后,包括:判断所述模型验证结果是否满足准确度要求;若所述模型验证结果不满足所述准确度要求,重新推导模型,形成闭环优化模型。
优选的,所述根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证之前,包括:获得所述模型的状态,其中,所述模型状态包括计算中状态、已完成状态;当所述模型的状态为已完成状态时,获取所述新样本数据进行所述模型验证。
优选的,所述利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值,包括:根据所述关键自变量,获得输入数据;获得已保存所述优选模型,将所述输入数据输入所述优选模型中;校验所述优选模型的自变量是否与所述输入数据中的自变量相同;当所述优选模型中的自变量与所述输入数据中的自变量相同时,按照所述数据清洗规则对所述输入数据进行清洗;将清洗后的所述输入数据利用所述优选模型进行模型计算,获得所述性能预测值。
优选的,所述利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值,还包括:获得所述研发产品的第一性能、第二性能,其中,所述第一性能与所述第二性能不同;根据所述第一性能,获得第一优选模型;根据所述第二性能,获得第二优选模型;利用所述第一优选模型、所述第二优选模型分别对所述第一性能、所述第二性能同时进行预测,分别获得对应的第一性能预测值、第二性能预测值。
第二方面,本发明提供了一种性能预测模型与产品研发相结合的装置,所述装置包括:
第一获得单元,所述第一获得单元用于获得研发产品的工序一贯制数据;
第一确定单元,所述第一确定单元用于根据所述工序一贯制数据,确定样本数据;
第二获得单元,所述第二获得单元用于根据所述样本数据的统计分布情况,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗;
第三获得单元,所述第三获得单元用于对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件;
第四获得单元,所述第四获得单元用于根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果;
第五获得单元,所述第五获得单元用于根据所述模型验证结果,获得优选模型,并将所述优选模型进行保存;
第一预测单元,所述第一预测单元用于利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。
优选的,所述装置还包括:
第一建立单元,所述第一建立单元用于将所述工序一贯制数据通过数据库建立多层数仓。
第六获得单元,所述第六获得单元用于根据所述多层数仓,按照所述研发产品的生成工序进行分层整合,获得整合一贯制数据。
第二确定单元,所述第二确定单元用于根据所述整合一贯制数据,按照预设条件确定所述样本数据。
优选的,所述装置还包括:
第一选择单元,所述第一选择单元用于选择所述数据挖掘算法,其中,所述数据挖掘算法包括:多云回归算法、随机森林算法、xgb算法。
第七获得单元,所述第七获得单元用于根据所述数据挖掘算法,获得所述数据挖掘算法对应模型。
第八获得单元,所述第八获得单元用于利用所述样本数据对所述模型进行训练,获得第一训练结果。
第九获得单元,所述第九获得单元用于根据所述第一训练结果,按照筛选自变量要求对所述训练结果中的自变量进行筛选,获得关键自变量。
第十获得单元,所述第十获得单元用于利用所述关键自变量对所述模型重新进行模型训练,获得第二训练结果;
第一保存单元,所述第一保存单元用于将所述第二训练结果保存至所述模型文件中,其中,所述模型文件的名称包括产品牌号、算法、创建人、当前时间、流水号。
优选的,所述关键自变量数量不大于30项。
优选的,所述装置还包括:
第一判断单元,所述第一判断单元用于判断所述模型验证结果是否满足准确度要求;
第一执行单元,所述第一执行单元用于若所述模型验证结果不满足所述准确度要求,重新推导模型,形成闭环优化模型。
优选的,所述装置还包括:
第十一获得单元,所述第十一获得单元用于获得所述模型的状态,其中,所述模型状态包括计算中状态、已完成状态。
第一验证单元,所述第一验证单元用于当所述模型的状态为已完成状态时,获取所述新样本数据进行所述模型验证。
优选的,所述装置还包括:
第一评价单元,所述第一评价单元用于根据公式|预测铁损值-真实铁损值|/样本个数≤n,对所述训练结果、所述模型验证结果中铁损的准确性进行评价,其中,当所述研发产品为中低牌号时,n=0.1,当所述研发产品为高牌号时,n=0.03;
第二评价单元,所述第二评价单元用于根据公式|预测磁感值-真实磁感值|/样本个数≤m,对所述训练结果、所述模型验证结果中磁感的准确性进行评价,其中,当所述研发产品为中低牌号时,m=0.005,当所述研发产品为高牌号时,m=0.003;
第三评价单元,所述第三评价单元用于根据公式|预屈服强度值-真实屈服强度值|/样本个数≤5,对所述训练结果、所述模型验证结果中屈服强度的准确性进行评价。
优选的,所述装置还包括:
第十二获得单元,所述第十二获得单元用于根据所述关键自变量,获得输入数据。
第十三获得单元,所述第十三获得单元用于获得已保存所述优选模型,将所述输入数据输入所述优选模型中。
第一校验单元,所述第一校验单元用于校验所述优选模型的自变量是否与所述输入数据中的自变量相同。
第一清洗单元,所述第一清洗单元用于当所述优选模型中的自变量与所述输入数据中的自变量相同时,按照所述数据清洗规则对所述输入数据进行清洗。
第十四获得单元,所述第十四获得单元用于将清洗后的所述输入数据利用所述优选模型进行模型计算,获得所述性能预测值。
优选的,所述装置还包括:
第十五获得单元,所述第十五获得单元用于获得所述研发产品的第一性能、第二性能,其中,所述第一性能与所述第二性能不同。
第十六获得单元,所述第十六获得单元用于根据所述第一性能,获得第一优选模型。
第十七获得单元,所述第十七获得单元用于根据所述第二性能,获得第二优选模型。
第十八获得单元,所述第十八获得单元用于利用所述第一优选模型、所述第二优选模型分别对所述第一性能、所述第二性能同时进行预测,分别获得对应的第一性能预测值、第二性能预测值。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
本发明实施例提供的一种性能预测模型与产品研发相结合的方法和装置,通过研发产品的要求获得研发产品的工序要求,结合所述工序要求相关参数整合获得工艺一贯制数据;根据所述工序一贯制数据,确定样本数据,通过对所述样本数据的统计分布情况分析,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗,在清洗完成后,对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件,并对所生成的模型文件进行新样本数据验证,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果,针对验证结果和多模型评估结果进行最优模型保存,然后在产品研发设计环节可对已保存的模型启动对应模型进行模型应用,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。实现在新产品研制时参照模型中的关键参数进行设计,调用相应性能预测模型,快速预测设计结果,有利于减少设计及试制次数,降低研发成本及缩短研发周期,从而解决了现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。同时本发明的实施,对硅钢取向无取向新产品研发试制有支撑作用。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
图1为本发明实施例中一种性能预测模型与产品研发相结合的方法的流程示意图;
图2为本发明实施例中一种性能预测模型与产品研发相结合的装置的结构示意图。
附图标记说明:第一获得单元11,第一确定单元12,第二获得单元13,第三获得单元14,第四获得单元15,第五获得单元16,第一预测单元17,总线300,接收器301,处理器302,发送器303,存储器304,总线接口306。
具体实施方式
本发明实施例提供了一种性能预测模型与产品研发相结合的方法和装置,用于解决现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。
本发明提供的技术方案总体思路如下:
获得研发产品的工序一贯制数据;根据所述工序一贯制数据,确定样本数据;根据所述样本数据的统计分布情况,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗;对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件;根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果;根据所述模型验证结果,获得优选模型,并将所述优选模型进行保存;利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。达到了调用相应性能预测模型,实现性能预测模型与产品研发的无缝集成,降低研发成本,节省了传统研发过程中每次试制需要数月的生产等待时间,从而减少试制次数,缩短研发周期的技术效果。
应理解,本发明实施例中,所述hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为mapreduce任务进行运行。其优点是学习成本低,可以通过类sql语句快速实现简单的mapreduce统计,不必开发专门的mapreduce应用,十分适合数据仓库的统计分析。hive是建立在hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(etl),这是一种可以存储、查询和分析存储在hadoop中的大规模数据的机制。hive定义了简单的类sql查询语言,称为hql,它允许熟悉sql的用户查询数据。同时,这个语言也允许熟悉mapreduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。hive没有专门的数据格式。hive可以很好的工作在thrift之上,控制分隔符,也允许用户指定数据格式。
应理解,本发明实施例中,所述线程有时被称为轻量进程(lightweightprocess,lwp),是程序执行流的最小单元。一个标准的线程由线程id,当前指令指针(pc),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;运行状态是指线程占有处理机正在运行;阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派cpu的基本单位指令运行时的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
应理解,本发明实施例中,所述多元回归指研究一个因变量、与两个或两个以上自变量的回归。亦称为多元线性回归,是反映一种现象或事物的数量依多种现象或事物的数量的变动而相应地变动的规律。建立多个变量之间线性或非线性数学模型数量关系式的统计方法。
应理解,本发明实施例中,所述xgb算法为计算机算法,所述xgb算法的算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本申请实施例以及实施例中的具体特征是对本申请技术方案的详细的说明,而不是对本申请技术方案的限定,在不冲突的情况下,本申请实施例以及实施例中的技术特征可以相互组合。
本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
实施例一
图1为本发明实施例中一种性能预测模型与产品研发相结合的方法的流程示意图。如图1所示,本发明实施例提供了一种性能预测模型与产品研发相结合的方法,所述方法包括:
步骤110:获得研发产品的工序一贯制数据。
具体而言,在研发新产品时通过用户调研、产品定位分析可明确相近的已生产的产品,并将炼钢、热轧、冷轧前后工序一贯制数据作为初始自变量。
步骤120:根据所述工序一贯制数据,确定样本数据。
进一步的,所述根据所述工序一贯制数据,确定样本数据,包括:将所述工序一贯制数据通过数据库建立多层数仓;根据所述多层数仓,按照所述研发产品的生成工序进行分层整合,获得整合一贯制数据;根据所述整合一贯制数据,按照预设条件确定所述样本数据。
具体而言,所述样本数据的确定为通过样本数据选择模块完成,基于大数据平台,通过hive数据库建立四层数仓贴源层、过度层、准备层、展示层,将炼钢、热轧、冷轧前后工序分层关联整合,形成按照工艺路线整合的一贯制数据,同时每隔预设时间将自动从所述大数据平台的数据库中获得所述整合后的前后工序一贯制数据。按照工艺路线、钢种、内部牌号、时间区间可以确定样本数据,借助大数据平台算力,默认初始选用按工艺路线整合后的一贯制数据,本发明实施例的所述样本数据包括硅钢产品前后工序共5条产线、19个机组,其中工艺参数共414项,按照工艺路线将工艺参数进行整合,获得与所述工艺路线密切关系的工艺参数作为所述样本数据。举例而言,工艺路线1,初始208项自变量,工艺路线2,初始220项自变量,也可以人工根据经验筛减自变量,可导出excel查看样本数据质量及分布情况,便于后续制定数据清洗规则。所有自变量中包含炼钢工艺参数:废钢量,铁水量,总氧耗,转炉终点c,转炉终点o,转炉终渣tfe,转炉终点温度,rh到站c,rh到站si,rh到站渣碱度r,rh结束渣tfe,rh结束渣碱度r,rh结束渣tio2,rh结束渣al2o3,rh结束渣cao,rh结束渣sio2,rh到站温度,rh结束温度,rh吹氧量,rh调废钢量,镇静时间,中包过热度,浇铸拉速1,浇铸拉速2,成品成分c,成品成分si,成品成分mn,成品成分p,成品成分s,成品成分als,成品成分cu,成品成分sb,成品成分sn,成品成分ti,成品成分n,成品成分n1,成品成分ni,成品成分cr,成品成分v,成品成分alt,成品成分mo,成品成分b,成品成分nb,板坯宽度,板坯长度,板坯重量,成品成分ca,转炉渣碱度r,rh到站o2,rh氧化球加入量,rh终渣mgo,rh终渣mno,rh终渣p2o5,rh终渣s,rh循环气体流量平均值;热轧工艺参数:在炉时间charging,在炉时间pre,在炉时间no1,在炉时间no2,在炉时间soaking,总在炉时间,温度charging,温度pre,温度no1,温度no2,温度soaking,钢卷厚度目标,钢卷厚度平均,钢卷宽度目标,钢卷宽度平均,热轧出库重量,热轧卷理论厚度,热轧宽度,热卷下线重量,头尾坯标识,加热炉号,入炉温度,加段上平均炉温,加热段下平均炉温,二加热段上平均炉温,二加热段下平均炉温,终轧温度目标值,终轧温度平均值,终轧温度命中率,卷取温度目标值,卷曲温度平均值,卷取温度命中率,rt2温度,粗轧温度rt2目标值,预热段上平均炉温,预热段下平均炉温,热回收上平均炉温,热回收下平均炉温,均热段上平均炉温,均热段下平均炉温,热轧卷长,pdo热轧卷厚,板坯厚,卷曲温度最大值,卷曲温度最小值,终轧温度最大值,终轧温度最小值,热轧r1r2压下率r1pass1,r1r2压下率r1pass2,热轧r1r2压下率r1pass3,热轧r1r2压下率r2pass1,热轧r1r2压下率r2pass2,热轧r1r2压下率r2pass3,热轧r1r2压下率r2pass4,热轧r1r2压下率r2pass5,热轧r1r2压下率r2pass6,热轧r1r2压下率r2pass7,热轧r1出口厚度pass1,热轧r1出口厚度pass3,热轧精轧道次压下率f1,热轧精轧道次压下率f2,热轧精轧道次压下率f3,热轧精轧道次压下率f4,热轧精轧道次压下率f5,热轧精轧道次压下率f6,热轧精轧道次压下率f7;冷轧工艺参数:连退成品厚度,连退成品宽度,连退下线重量,酸轧卷宽度,酸轧卷重量,酸轧1机架压下率设定值,酸轧2机架压下率设定值,酸轧3机架压下率设定值,酸轧4机架压下率设定值,酸轧5机架压下率设定值,退火炉单位张力,ph1段炉温,ph2段炉温,nof1段炉温,nof2段炉温,nof3段炉温,nof4段炉温,nof2-4段炉温均值,nof5段炉温,rtf1段炉温,rtf2段炉温,rtf3段炉温,rtf4段炉温,rtf2-4段炉温均值,sf1段炉温,sf2段炉温,sf3段炉温,sf4段炉温,sf14段炉温均值,sf5段炉温,sf6段炉温,sf7段炉温,sf8段炉温,sf58段炉温,sf9段炉温,sf10段炉温,sf11段炉温,sf59-11段炉温均值,sf12段炉温,sf13段炉温,sf14段炉温,sf15段炉温,sf51215段炉温均值,dfds1段炉温,dfds2段炉温,dfds3段炉温,dfbs1段炉温,dfbs2段炉温,ctf_1频率百分比,ctf_2频率百分比,ctf_3频率百分比,干保护气体n2流量,干保护气体h2流量,湿保护气体n2流量,湿保护气体h2流量,rjc常用高压氮气流量,sf7段露点,rtf1段h2含量,sf1段h2含量,sf7段h2含量,sf8段h2含量,sf15段h2含量,rjc1段h2含量,rtf1段o2含量,sf1段o2含量,sf7段o2含量,sf8段o2含量,sf15段o2含量,rjc1段o2含量,ph炉压力,nof5段炉压力,出口密封室压力,加湿器主槽内水温,por1单位张力,p2or单位张力,入口活套单位张力,清洗段单位张力,干燥炉单位张力,出口活套单位张力,tr1单位张力,tr2单位张力,入口段速度,工艺段速度,出口段速度,1米处位置的厚度值,厚度平均值,最后一米处位置的厚度值。
步骤130:根据所述样本数据的统计分布情况,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗。
具体而言,通过数据清洗处理模块对所述样本数据进行清洗,支持规则的增加、删除、修改,针对某一规则进行此数据清洗规则下的工艺参数自变量及因变量的过滤范围及默认值的填写。清洗规则的类型分为“[]”、“(]”、“[)”、“()”、“默认值”,举例而言:c的清洗规则:[0.001-0.02],表示:样本数据中保留c介于0.001-0.02之间;终轧温度的清洗规则:默认值869,表示:样本数据中如果终轧温度有空值,则补入869,如果某个变量没有配置清洗规则,则此变量数据为空时整行样本数据剔除。
步骤140:对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件。
进一步的,所述对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件,包括:选择所述数据挖掘算法,其中,所述数据挖掘算法包括:多云回归算法、随机森林算法、xgb算法;根据所述数据挖掘算法,获得所述数据挖掘算法对应模型;利用所述样本数据对所述模型进行训练,获得第一训练结果;根据所述第一训练结果,按照筛选自变量要求对所述训练结果中的自变量进行筛选,获得关键自变量;利用所述关键自变量对所述模型重新进行模型训练,获得第二训练结果;将所述第二训练结果保存至所述模型文件中,其中,所述模型文件的名称包括产品牌号、算法、创建人、当前时间、流水号。
进一步的,所述关键自变量数量不大于30项。
进一步的,所述方法还包括:根据公式|预测铁损值-真实铁损值|/样本个数≤n,对所述训练结果、所述模型验证结果中铁损的准确性进行评价,其中,当所述研发产品为中低牌号时,n=0.1,当所述研发产品为高牌号时,n=0.03;根据公式|预测磁感值-真实磁感值|/样本个数≤m,对所述训练结果、所述模型验证结果中磁感的准确性进行评价,其中,当所述研发产品为中低牌号时,m=0.005,当所述研发产品为高牌号时,m=0.003;根据公式|预屈服强度值-真实屈服强度值|/样本个数≤5,对所述训练结果、所述模型验证结果中屈服强度的准确性进行评价。
具体而言,进行数据挖掘算法的选择,如多元回归、随机森林、xgb算法,进行不同数据挖掘算法的模型创建,系统展示模型预测结果的曲线图形、回归公式、预测值、偏差、自变量因子显著性得分、准确率。系统可根据自变量因子的显著性得分筛选出指定比例的关键因子,并结合专业技术经验调整关键因子,重新进行模型训练。模型名称及模型计算触发时间作为联合主键。本发明实施例通过模型训练模块,采用的数据挖掘建模算法为:多元回归、随机森林和xgboost算法即xgb算法。可按照工艺路线、钢种、内部牌号三种颗粒度进行建模,选择样本数据范围、数据清洗规则、算法后,进行模型训练。模型的输出包括:预测值、偏差、准确率、自变量显著性得分,回归公式。系统给出自变量的得分,人工可按照比例筛减自变量,如:输入80%,则系统按照自变量显著性得分由高到低排序,保留前80%的自变量。并且可以手工筛减或增加自变量。准确率容忍下限均为95%,其计算规则为:针对中低牌号铁损,分子:|预测铁损值-真实铁损值|≤0.1的个数,分母:样本个数;针对中低牌号磁感,分子:|预测磁感值-真实磁感值|≤0.005的个数,分母:样本个数;针对中低牌号屈服强度,分子:|预屈服强度值-真实屈服强度值|≤5的个数,分母:样本个数。针对高牌号铁损,分子:|预测铁损值-真实铁损值|≤0.03的个数,分母:样本个数;针对高牌号磁感,分子:|预测磁感值-真实磁感值|≤0.003的个数,分母:样本个数;针对高牌号屈服强度,分子:|预屈服强度值-真实屈服强度值|≤5的个数,分母:样本个数。对模型训练结果进行准确性评价,当满足上述条件则进行下一步骤,认为该模型合格,若不满足上述条件,则判断其模型准确性不合要求,如准确性预测结果不理想则返回开始步骤重新进行建模,同时该公式同样适用于模型验证环境,对模型验证结果进行评价。举例而言,针对此工艺路线中的s30y、s40、s19钢种进行建模,性能项为:磁感、铁损、屈服强度四种性能进行建立模型,得出预测值、偏差、准确率自变量的显著性得分,按照显著性得分由高到低筛选出20%比例,得出42项关键变量,再人工结合经验筛减自变量,确定最终关键变量20项:rtf2-4段炉温均值,sf7段露点,酸轧3机架压下率设定值,干燥炉单位张力,ca-dfds1炉温,cu,粗轧温度rt2目标值,湿保护气n2流量,卷取温度平均值,sf59-11段炉温均值,入口段速度,n1,sf512-15段炉温均值,预热段上平均炉温,1#sf14,ti,s,rjc常用高压氮气流量,sf14段炉温,预热段下平均炉温,产品工厂师结合经验进行上述关键变量的删除和添加,考虑到实际生产可操作性,最终关键变量控制在30项以内,再重新依据系统和人工筛选的最终关键变量进行建模,实现系统大批量运算与专业技术经验的有效结合。针对多元回归算发得出多元回归公式;针对其他算法直接输出预测值、偏差、准确率、自变量显著得分。模型的命名规则:产品系列(如中低牌号)+算法+创建人+当前日期+流水号,由此可知,钢种或内部牌号和预测模型文件的对应关系,有可能是一个钢种或一个内部牌号对应一个预测模型文件,也有可能是多个钢种或多个内部牌号对应一个预测模型文件。
步骤150:根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果。
进一步的,所述利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果之后,包括:判断所述模型验证结果是否满足准确度要求;若所述模型验证结果不满足所述准确度要求,重新推导模型,形成闭环优化模型。
进一步的,所述根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证之前,包括:获得所述模型的状态,其中,所述模型状态包括计算中状态、已完成状态;当所述模型的状态为已完成状态时,获取所述新样本数据进行所述模型验证。
步骤160:根据所述模型验证结果,获得优选模型,并将所述优选模型进行保存。
具体而言,在触发模型训练后,本方法将开启线程请求后台计算,并同时开启另一线程返回前台模型所处状态:计算中,同时启动定时任务查询模型当前所处状态,包括计算中、已完成。针对状态是“已完成”的模型才可进行模型验证,当确定了模型为已完成状态,利用模型验证模块对模型进行验证,选择钢种、内部牌号、时间范围后重新确定新的样本数据,选择模型名称,自动匹配模型训练时的数据清洗规则,输出验证结果,包括:预测值、偏差及准确率。若验证结果不理想重新返回初始步骤,用一段时间后或者工艺设备进行调整后,需要对模型进行上述评估,发现准确率大幅度下降时需要返回初始步骤重新推导模型,形成闭环优化模型,使模型适应实际生产动态,确保研发与实际生产不脱离。最后将评估不同数据挖掘算法得出的模型训练及验证输出结果,从中择优保存模型。
步骤170:利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。
进一步的,所述利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值,包括:根据所述关键自变量,获得输入数据;获得已保存所述优选模型,将所述输入数据输入所述优选模型中;校验所述优选模型的自变量是否与所述输入数据中的自变量相同;当所述优选模型中的自变量与所述输入数据中的自变量相同时,按照所述数据清洗规则对所述输入数据进行清洗;将清洗后的所述输入数据利用所述优选模型进行模型计算,获得所述性能预测值。
进一步的,所述利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值,还包括:获得所述研发产品的第一性能、第二性能,其中,所述第一性能与所述第二性能不同;根据所述第一性能,获得第一优选模型;根据所述第二性能,获得第二优选模型;利用所述第一优选模型、所述第二优选模型分别对所述第一性能、所述第二性能同时进行预测,分别获得对应的第一性能预测值、第二性能预测值。
具体而言,将保存的优选模型在研发过程中对所述研发产品的各性能目标值进行预测,研发人员通过模型应用模块进行研发产品性能的预测评价,只有已保存的优选模型才能进入模型应用模块进行启动,产品研发工程师设计工艺参数目标值作为模型的输入,通过校验,保证模型输入的工艺参数与模型建立时的工艺参数一致,模型输出性能预测值。可自动根据不同性能匹配相应模型文件,针对一组工艺参数设计目标值,同时进行不同性能的预测。针对不同硅钢产品种类及性能进行区分,所述性能包括磁感、铁损、屈服强度等三类。依据模型名称与当前训练模型的时间确定唯一模型,可按照工艺路线、钢种、内部牌号三种维度进行建模。品种工程师进行产品研发时进行相似产品研发时调用相应的可参考的模型,并且借助多线程并发机制,支持多性能模型进行同时预测。输入是工艺参数的目标值,输出是性能预测值,包括:磁感、铁损、屈服强度。利用模型进行快速预测设计结果,实现性能预测模型与产品研发的无缝集成,从而减少试制次数,缩短研发周期,降低研发成本,节省了传统研发过程中每次试制需要1-2个月的生产等待时间,从而解决了现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。
实施例二
基于与前述实施例中一种性能预测模型与产品研发相结合的方法同样的发明构思,本发明还提供一种性能预测模型与产品研发相结合的装置,如图2所示,所述装置包括:
第一获得单元11,所述第一获得单元11用于获得研发产品的工序一贯制数据;
第一确定单元12,所述第一确定单元12用于根据所述工序一贯制数据,确定样本数据;
第二获得单元13,所述第二获得单元13用于根据所述样本数据的统计分布情况,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗;
第三获得单元14,所述第三获得单元14用于对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件;
第四获得单元15,所述第四获得单元15用于根据所述模型文件,获得新样本数据,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果;
第五获得单元16,所述第五获得单元16用于根据所述模型验证结果,获得优选模型,并将所述优选模型进行保存;
第一预测单元17,所述第一预测单元17用于利用所述优选模型,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。
进一步的,所述装置还包括:
第一建立单元,所述第一建立单元用于将所述工序一贯制数据通过数据库建立多层数仓。
第六获得单元,所述第六获得单元用于根据所述多层数仓,按照所述研发产品的生成工序进行分层整合,获得整合一贯制数据。
第二确定单元,所述第二确定单元用于根据所述整合一贯制数据,按照预设条件确定所述样本数据。
进一步的,所述装置还包括:
第一选择单元,所述第一选择单元用于选择所述数据挖掘算法,其中,所述数据挖掘算法包括:多云回归算法、随机森林算法、xgb算法。
第七获得单元,所述第七获得单元用于根据所述数据挖掘算法,获得所述数据挖掘算法对应模型。
第八获得单元,所述第八获得单元用于利用所述样本数据对所述模型进行训练,获得第一训练结果。
第九获得单元,所述第九获得单元用于根据所述第一训练结果,按照筛选自变量要求对所述训练结果中的自变量进行筛选,获得关键自变量。
第十获得单元,所述第十获得单元用于利用所述关键自变量对所述模型重新进行模型训练,获得第二训练结果;
第一保存单元,所述第一保存单元用于将所述第二训练结果保存至所述模型文件中,其中,所述模型文件的名称包括产品牌号、算法、创建人、当前时间、流水号。
进一步的,所述关键自变量数量不大于30项。
进一步的,所述装置还包括:
第一判断单元,所述第一判断单元用于判断所述模型验证结果是否满足准确度要求;
第一执行单元,所述第一执行单元用于若所述模型验证结果不满足所述准确度要求,重新推导模型,形成闭环优化模型。
进一步的,所述装置还包括:
第十一获得单元,所述第十一获得单元用于获得所述模型的状态,其中,所述模型状态包括计算中状态、已完成状态。
第一验证单元,所述第一验证单元用于当所述模型的状态为已完成状态时,获取所述新样本数据进行所述模型验证。
进一步的,所述装置还包括:
第一评价单元,所述第一评价单元用于根据公式|预测铁损值-真实铁损值|/样本个数≤n,对所述训练结果、所述模型验证结果中铁损的准确性进行评价,其中,当所述研发产品为中低牌号时,n=0.1,当所述研发产品为高牌号时,n=0.03;
第二评价单元,所述第二评价单元用于根据公式|预测磁感值-真实磁感值|/样本个数≤m,对所述训练结果、所述模型验证结果中磁感的准确性进行评价,其中,当所述研发产品为中低牌号时,m=0.005,当所述研发产品为高牌号时,m=0.003;
第三评价单元,所述第三评价单元用于根据公式|预屈服强度值-真实屈服强度值|/样本个数≤5,对所述训练结果、所述模型验证结果中屈服强度的准确性进行评价。
进一步的,所述装置还包括:
第十二获得单元,所述第十二获得单元用于根据所述关键自变量,获得输入数据。
第十三获得单元,所述第十三获得单元用于获得已保存所述优选模型,将所述输入数据输入所述优选模型中。
第一校验单元,所述第一校验单元用于校验所述优选模型的自变量是否与所述输入数据中的自变量相同。
第一清洗单元,所述第一清洗单元用于当所述优选模型中的自变量与所述输入数据中的自变量相同时,按照所述数据清洗规则对所述输入数据进行清洗。
第十四获得单元,所述第十四获得单元用于将清洗后的所述输入数据利用所述优选模型进行模型计算,获得所述性能预测值。
进一步的,所述装置还包括:
第十五获得单元,所述第十五获得单元用于获得所述研发产品的第一性能、第二性能,其中,所述第一性能与所述第二性能不同。
第十六获得单元,所述第十六获得单元用于根据所述第一性能,获得第一优选模型。
第十七获得单元,所述第十七获得单元用于根据所述第二性能,获得第二优选模型。
第十八获得单元,所述第十八获得单元用于利用所述第一优选模型、所述第二优选模型分别对所述第一性能、所述第二性能同时进行预测,分别获得对应的第一性能预测值、第二性能预测值。
前述图1实施例一中的一种性能预测模型与产品研发相结合的方法的各种变化方式和具体实例同样适用于本实施例的一种性能预测模型与产品研发相结合的装置,通过前述对一种性能预测模型与产品研发相结合的方法的详细描述,本领域技术人员可以清楚的知道本实施例中一种性能预测模型与产品研发相结合的装置的实施方法,所以为了说明书的简洁,在此不再详述。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
本发明实施例提供的一种性能预测模型与产品研发相结合的方法和装置,通过研发产品的要求获得研发产品的工序要求,结合所述工序要求相关参数整合获得工艺一贯制数据;根据所述工序一贯制数据,确定样本数据,通过对所述样本数据的统计分布情况分析,获得数据清洗规则,并按所述数据清洗规则对所述样本数据进行清洗,在清洗完成后,对清洗后的所述样本数据进行多种数据挖掘算法模型创建,并对所述模型进行训练,获得训练结果建立对应模型文件,并对所生成的模型文件进行新样本数据验证,利用所述新样本数据对所述模型文件进行模型验证,获得模型验证结果,针对验证结果和多模型评估结果进行最优模型保存,然后在产品研发设计环节可对已保存的模型启动对应模型进行模型应用,根据在研发中对所述研发产品的性能要求,获得对应的性能预测值。实现在新产品研制时参照模型中的关键参数进行设计,调用相应性能预测模型,快速预测设计结果,有利于减少设计及试制次数,降低研发成本及缩短研发周期,从而解决了现有技术中产品研发需经过工艺产线试验和人工评价进行,存在试制成本高,研发周期长的技术问题。同时本发明的实施,对硅钢取向无取向新产品研发试制有支撑作用。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!